Spiking Pyramid Wavelet Transformation for High-efficient and Low-energy Image Restoration
Pith reviewed 2026-06-26 21:51 UTC · model grok-4.3
The pith
A spiking neural network with pyramid wavelet blocks performs image restoration at lower computational cost and energy use while keeping output quality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that the SPWM model, centered on the spiking dual pyramid wavelet block, models long-range dependencies and exploits image degradation properties directly in the wavelet domain, enabling spiking neural networks to achieve image restoration with substantially reduced computational costs and energy consumption while preserving quality on multiple benchmarks.
What carries the argument
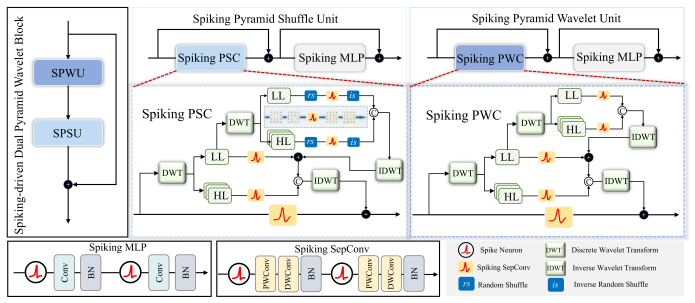
The spiking dual pyramid wavelet (SDPW) block, which performs dependency modeling and degradation analysis inside the wavelet domain for spiking networks.
If this is right
- SPWM produces image restoration results on benchmarks at lower computational cost than prior spiking CNN approaches.
- Energy consumption drops significantly while output quality stays comparable.
- Spiking networks become more practical for image restoration on devices with tight power budgets.
- Wavelet-domain processing offers a route to address receptive-field limits in other spiking vision models.
Where Pith is reading between the lines
- The same block structure could be tested on related tasks such as denoising or super-resolution where degradation modeling matters.
- Hardware measurements on neuromorphic chips would give a clearer picture of real energy savings beyond simulation counts.
- Combining the pyramid levels with additional spiking mechanisms might further reduce operations without new architectural changes.
Load-bearing premise
The spiking dual pyramid wavelet block can capture long-range dependencies and degradation properties in the wavelet domain without incurring major quality losses.
What would settle it
Running the SPWM model on the same benchmarks and observing either higher restoration error or no reduction in energy or operations compared with baseline spiking CNNs would falsify the claim.
Figures



read the original abstract
Spiking neural networks (SNNs) have garnered significant interest in computer vision due to their potential for efficiency and biological inspiration. While spiking CNN-based methods have shown promise for image restoration (IR) tasks, their performance is constrained by the inherent receptive field limitations of CNN operations. In the paper, we explore the benefits of discrete wavelet transformation and propose a spiking pyramid wavelet-based model (SPWM) for high-efficient and low-energy target. Specifically, we develop a spiking dual pyramid wavelet (SDPW) block to model long-range dependency and exploit the properties of the degradation in the wavelet domain. Experimental results on several benchmarks demonstrate that SPWM significantly lowers computational costs and energy consumption while maintaining image quality. Our method showcases the potential of SNNs in the field of IR, offering new insights for future applications of resource-limited devices.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a spiking pyramid wavelet-based model (SPWM) for image restoration. It develops a spiking dual pyramid wavelet (SDPW) block that combines discrete wavelet transformation with spiking neural networks to model long-range dependencies and exploit degradation properties in the wavelet domain. The central claim, stated in the abstract, is that SPWM significantly lowers computational costs and energy consumption on several benchmarks while maintaining image quality, demonstrating the potential of SNNs for resource-limited IR applications.
Significance. If the experimental claims hold with proper controls, the integration of wavelet-domain processing with spiking mechanisms could offer a meaningful route to low-energy IR models. The work would then contribute to the growing literature on efficient SNN architectures for vision tasks. However, the provided text supplies no quantitative metrics, baselines, energy figures, or ablation results, so the significance cannot be assessed from the manuscript as presented.
major comments (2)
- [Abstract] Abstract: the claim that 'experimental results on several benchmarks demonstrate that SPWM significantly lowers computational costs and energy consumption while maintaining image quality' is unsupported; no tables, no energy metrics (e.g., spike counts or mJ/image), no baseline comparisons, no dataset details, and no error bars or ablation studies are supplied anywhere in the text.
- [Abstract] Abstract: the assumption that the SDPW block successfully models long-range dependency and exploits wavelet-domain degradation properties without major trade-offs cannot be evaluated, because no equations, architecture diagrams, or implementation details for the SDPW block are given.
minor comments (1)
- The title refers to 'Spiking Pyramid Wavelet Transformation' while the abstract uses 'spiking pyramid wavelet-based model (SPWM)'; ensure consistent nomenclature throughout.
Simulated Author's Rebuttal
We thank the referee for the detailed review and for identifying areas where the manuscript requires stronger support for its claims. We address each major comment below and commit to revisions that will incorporate the requested details without altering the core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'experimental results on several benchmarks demonstrate that SPWM significantly lowers computational costs and energy consumption while maintaining image quality' is unsupported; no tables, no energy metrics (e.g., spike counts or mJ/image), no baseline comparisons, no dataset details, and no error bars or ablation studies are supplied anywhere in the text.
Authors: The referee is correct that the current manuscript text does not contain these supporting elements. We will revise the experimental section to add tables reporting PSNR/SSIM, FLOPs, parameters, spike counts, and energy estimates (mJ/image) on standard benchmarks (e.g., BSD68, Set5, Urban100), with direct comparisons to both SNN and ANN baselines, error bars from multiple runs, and ablation studies on the wavelet and spiking components. This will fully substantiate the abstract claim. revision: yes
-
Referee: [Abstract] Abstract: the assumption that the SDPW block successfully models long-range dependency and exploits wavelet-domain degradation properties without major trade-offs cannot be evaluated, because no equations, architecture diagrams, or implementation details for the SDPW block are given.
Authors: We agree that the abstract alone provides insufficient detail for evaluation. The revised manuscript will include the explicit equations governing the discrete wavelet transform integrated with spiking neurons, a clear architecture diagram of the dual-pyramid structure, and implementation specifics (neuron model, threshold, pyramid levels, and how long-range dependencies are captured via multi-scale wavelet coefficients). This will allow readers to assess the modeling of dependencies and degradation properties. revision: yes
Circularity Check
No significant circularity; claims rest on external experiments
full rationale
The paper proposes an architectural model (SPWM with SDPW block) combining spiking networks and wavelet transforms for image restoration. Its central claims concern empirical performance on benchmarks (lower costs/energy while preserving quality). No equations, fitted parameters, or derivation steps are shown that reduce by construction to inputs, self-definitions, or self-citations. The load-bearing elements are external experimental comparisons, which are independent of any internal redefinition and therefore do not trigger circularity under the specified criteria.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Jiang, B
H. Jiang, B. Guan, Z. Liu, X. Liu, J. Yu, Z. Liu, S. Han, S. Liu, Learning to see in the extremely dark, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 7676–7685
2025
-
[2]
R. Wang, Y . Zheng, Z. Zhang, C. Li, S. Liu, G. Zhai, X. Liu, Learning hazing to dehazing: Towards realistic haze generation for real-world image dehazing, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025, pp. 23091–23100
2025
-
[3]
X. Liu, Y . Ma, Z. Shi, J. Chen, Griddehazenet: Attention-based multi-scale net- work for image dehazing, in: Proceedings of the IEEE/CVF international confer- ence on computer vision, 2019, pp. 7314–7323
2019
-
[4]
C. Zhao, W. Cai, C. Hu, Z. Yuan, Cycle contrastive adversarial learning with structural consistency for unsupervised high-quality image deraining transformer, Neural Networks (2024) 106428
2024
-
[5]
Y . Tai, R. Xie, C. Zhao, K. Zhang, Z. Zhang, J. Zhou, J. Yang, Addsr: Accelerat- ing diffusion-based blind super-resolution with adversarial diffusion distillation, Pattern Recognition (2026) 113012
2026
-
[6]
Y . Tai, J. Yang, X. Liu, Image super-resolution via deep recursive residual net- work, in: Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 3147–3155
2017
-
[7]
Liang, J
J. Liang, J. Cao, G. Sun, K. Zhang, L. Van Gool, R. Timofte, Swinir: Image restoration using swin transformer, in: Proceedings of the IEEE/CVF interna- tional conference on computer vision, 2021, pp. 1833–1844
2021
-
[8]
C. Zhao, C. Dong, W. Cai, Y . Wang, Learning a physical-aware diffusion model based on transformer for underwater image enhancement, IEEE Transactions on Geoscience and Remote Sensing 64 (2026) 1–14. 21
2026
-
[9]
Z. Zeng, C. Zhao, W. Cai, Y . Guo, Semantic-guided coarse-to-fine diffusion model for self-supervised image shadow removal, in: International Conference on Computational Visual Media, Springer, 2025, pp. 271–293
2025
-
[10]
Zhao, W.-L
C. Zhao, W.-L. Cai, Z. Yuan, C.-W. Hu, Multi-cropping contrastive learning and domain consistency for unsupervised image-to-image translation, IET Image Pro- cessing 19 (1) (2025) e70006
2025
-
[11]
S. W. Zamir, A. Arora, S. Khan, M. Hayat, F. S. Khan, M.-H. Yang, L. Shao, Multi-stage progressive image restoration, in: Proceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, 2021, pp. 14821–14831
2021
-
[12]
X. Chen, H. Li, M. Li, J. Pan, Learning a sparse transformer network for effec- tive image deraining, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 5896–5905
2023
-
[13]
M. Yao, J. Hu, T. Hu, Y . Xu, Z. Zhou, Y . Tian, B. XU, G. Li, Spike-driven transformer v2: Meta spiking neural network architecture inspiring the design of next-generation neuromorphic chips, in: The Twelfth International Conference on Learning Representations, 2024
2024
-
[14]
Q. Su, Y . Chou, Y . Hu, J. Li, S. Mei, Z. Zhang, G. Li, Deep directly-trained spiking neural networks for object detection, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 6555–6565
2023
-
[15]
K. Roy, A. Jaiswal, P. Panda, Towards spike-based machine intelligence with neuromorphic computing, Nature 575 (7784) (2019) 607–617
2019
-
[16]
T. Song, G. Jin, P. Li, K. Jiang, X. Chen, J. Jin, Learning a spiking neural network for efficient image deraining, in: Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, 2024, pp. 1254–1262
2024
-
[17]
J. Xiao, X. Fu, Y . Zhu, D. Li, J. Huang, K. Zhu, Z.-J. Zha, Homoformer: Homog- enized transformer for image shadow removal, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 25617– 25626. 22
2024
-
[18]
W. Luo, Y . Li, R. Urtasun, R. Zemel, Understanding the effective receptive field in deep convolutional neural networks, Advances in neural information processing systems 29 (2016)
2016
-
[19]
M. Yao, G. Zhao, H. Zhang, Y . Hu, L. Deng, Y . Tian, B. Xu, G. Li, Attention spiking neural networks, IEEE transactions on pattern analysis and machine in- telligence 45 (8) (2023) 9393–9410
2023
-
[20]
W. Dong, H. Zhou, Y . Zhang, X. Liu, J. Chen, Ecmamba: Consolidating selective state space model with retinex guidance for efficient multiple exposure correction, Advances in Neural Information Processing Systems 37 (2024) 53438–53457
2024
-
[21]
C. Zhao, W. Cai, C. Dong, Z. Zeng, Toward sufficient spatial-frequency inter- action for gradient-aware underwater image enhancement, in: ICASSP 2024- 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), IEEE, 2024, pp. 3220–3224
2024
-
[22]
H. Zhou, W. Dong, X. Liu, S. Liu, X. Min, G. Zhai, J. Chen, Glare: Low light image enhancement via generative latent feature based codebook retrieval, in: European Conference on Computer Vision, Springer, 2024, pp. 36–54
2024
-
[23]
H. Zhou, W. Dong, X. Liu, Y . Zhang, G. Zhai, J. Chen, Low-light image enhance- ment via generative perceptual priors, in: Proceedings of the AAAI Conference on Artificial Intelligence, V ol. 39, 2025, pp. 10752–10760
2025
-
[24]
Zhao, W.-L
C. Zhao, W.-L. Cai, Z. Yuan, Spectral normalization and dual contrastive regular- ization for image-to-image translation, The Visual Computer 41 (2025) 129–140
2025
-
[25]
S. Lu, Z. Lian, Z. Zhou, S. Zhang, C. Zhao, A. W.-K. Kong, Does flux already know how to perform physically plausible image composition?, arXiv preprint arXiv:2509.21278 (2025)
arXiv 2025
-
[26]
C. Dong, C. Zhao, W. Cai, B. Yang, Y . Guo, O-mamba: O-shape state-space model for underwater image enhancement, in: Chinese Conference on Pattern Recognition and Computer Vision (PRCV), Springer, 2025, pp. 168–182. 23
2025
-
[27]
X. Zhao, C. Zhao, X. Hu, H. Zhang, Y . Tai, J. Yang, Learning multi-scale spatial- frequency features for image denoising, Pattern Recognition (2025) 112300
2025
-
[28]
C. Dong, C. C. Loy, K. He, X. Tang, Image super-resolution using deep convolu- tional networks, IEEE transactions on pattern analysis and machine intelligence 38 (2) (2015) 295–307
2015
-
[29]
Zhang, W
K. Zhang, W. Zuo, Y . Chen, D. Meng, L. Zhang, Beyond a gaussian denoiser: Residual learning of deep cnn for image denoising, IEEE transactions on image processing 26 (7) (2017) 3142–3155
2017
-
[30]
D. Ren, W. Zuo, Q. Hu, P. Zhu, D. Meng, Progressive image deraining networks: A better and simpler baseline, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 3937–3946
2019
-
[31]
S. W. Zamir, A. Arora, S. Khan, M. Hayat, F. S. Khan, M.-H. Yang, Restormer: Efficient transformer for high-resolution image restoration, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 5728–5739
2022
-
[32]
Z. Wang, Y . Fang, J. Cao, Q. Zhang, Z. Wang, R. Xu, Masked spiking transformer, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 1761–1771
2023
-
[33]
Z. Zhou, Y . Zhu, C. He, Y . Wang, Y . Shuicheng, Y . Tian, L. Yuan, Spikformer: When spiking neural network meets transformer, in: The Eleventh International Conference on Learning Representations, 2023
2023
-
[34]
C. Zhao, Z. Chen, Y . Xu, E. Gu, J. Li, Z. Yi, Q. Wang, J. Yang, Y . Tai, From zero to detail: Deconstructing ultra-high-definition image restoration from progressive spectral perspective, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025, pp. 17935–17946
2025
-
[35]
C. Zhao, W. Cai, C. Dong, C. Hu, Wavelet-based fourier information interaction with frequency diffusion adjustment for underwater image restoration, in: Pro- 24 ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recog- nition, 2024, pp. 8281–8291
2024
-
[36]
C. Zhao, J. Chen, H. Li, Z. Kang, S. Lu, X. Wei, K. Zhang, J. Yang, Y . Tai, Luve: Latent-cascaded ultra-high-resolution video generation with dual frequency ex- perts, arXiv preprint arXiv:2602.11564 (2026)
Pith/arXiv arXiv 2026
-
[37]
Jiang, A
H. Jiang, A. Luo, H. Fan, S. Han, S. Liu, Low-light image enhancement with wavelet-based diffusion models, ACM Transactions on Graphics (TOG) 42 (6) (2023) 1–14
2023
-
[38]
C. Zhao, Y . Xu, Z. Chen, E. Gu, K. Zhang, X. Liu, J. Yang, Y . Tai, From zero to detail: A progressive spectral decoupling paradigm for uhd image restoration with new benchmark, IEEE Transactions on Pattern Analysis and Machine Intelligence (2026) 1–18
2026
-
[39]
C. Zhao, E. Ci, Y . Xu, T. Fan, S. Guan, Y . Ge, J. Yang, Y . Tai, Ultrahr-100k: Enhancing uhr image synthesis with a large-scale high-quality dataset, Advances in Neural Information Processing Systems 38 (2026) 3373–3393
2026
-
[40]
Y . Zhou, C. Zhao, D. Peng, F. Ji, X.-T. Yuan, Learning to refine: Spectral- decoupled iterative refinement framework for precipitation nowcasting, arXiv preprint arXiv:2606.02661 (2026)
Pith/arXiv arXiv 2026
-
[41]
W. Fang, Y . Chen, J. Ding, Z. Yu, T. Masquelier, D. Chen, L. Huang, H. Zhou, G. Li, Y . Tian, Spikingjelly: An open-source machine learning infrastructure plat- form for spike-based intelligence, Science Advances 9 (40) (2023) eadi1480
2023
-
[42]
H. Wang, Q. Xie, Q. Zhao, D. Meng, A model-driven deep neural network for single image rain removal, in: CVPR, 2020, pp. 3103–3112
2020
-
[43]
Q. Guo, J. Sun, F. Juefei-Xu, L. Ma, X. Xie, W. Feng, Y . Liu, J. Zhao, Efficient- derain: Learning pixel-wise dilation filtering for high-efficiency single-image de- raining, in: AAAI, V ol. 35, 2021, pp. 1487–1495. 25
2021
-
[44]
Y . Cui, Y . Tao, Z. Bing, W. Ren, X. Gao, X. Cao, K. Huang, A. Knoll, Selective frequency network for image restoration, in: ICLR, 2023
2023
-
[45]
Liang, S
Y . Liang, S. Anwar, Y . Liu, Drt: A lightweight single image deraining recursive transformer, in: CVPRw, 2022, pp. 589–598
2022
-
[46]
Jiang, Z
K. Jiang, Z. Wang, C. Chen, Z. Wang, L. Cui, C.-W. Lin, Magic elf: Image deraining meets association learning and transformer, in: ACM MM, 2022, pp. 827–836
2022
-
[47]
Q. Wang, K. Jiang, J. Lai, Z. Wang, J. Zhang, Hpcnet: A hybrid progressive coupled network for image deraining, in: 2023 IEEE International Conference on Multimedia and Expo (ICME), IEEE, 2023, pp. 2747–2752
2023
-
[48]
Y . Wang, C. Ma, J. Liu, Smartassign: Learning a smart knowledge assignment strategy for deraining and desnowing, in: CVPR, 2023, pp. 3677–3686
2023
-
[49]
C. Wei, W. Wang, W. Yang, J. Liu, Deep retinex decomposition for low-light enhancement, arXiv preprint arXiv:1808.04560 (2018)
Pith/arXiv arXiv 2018
-
[50]
W. Yang, S. Wang, Y . Fang, Y . Wang, J. Liu, From fidelity to perceptual quality: A semi-supervised approach for low-light image enhancement, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 3063–3072
2020
-
[51]
Jiang, X
Y . Jiang, X. Gong, D. Liu, Y . Cheng, C. Fang, X. Shen, J. Yang, P. Zhou, Z. Wang, Enlightengan: Deep light enhancement without paired supervision, IEEE trans- actions on image processing 30 (2021) 2340–2349
2021
-
[52]
W. Wang, C. Wei, W. Yang, J. Liu, Gladnet: Low-light enhancement network with global awareness, in: 2018 13th IEEE international conference on automatic face & gesture recognition (FG 2018), IEEE, 2018, pp. 751–755
2018
-
[53]
Zhang, J
Y . Zhang, J. Zhang, X. Guo, Kindling the darkness: A practical low-light image enhancer, in: Proceedings of the 27th ACM international conference on multime- dia, 2019, pp. 1632–1640. 26
2019
-
[54]
Zhang, X
Y . Zhang, X. Guo, J. Ma, W. Liu, J. Zhang, Beyond brightening low-light images, International Journal of Computer Vision 129 (2021) 1013–1037
2021
-
[55]
Z. Wang, X. Cun, J. Bao, W. Zhou, J. Liu, H. Li, Uformer: A general u-shaped transformer for image restoration, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 17683–17693
2022
-
[56]
T. Wang, K. Zhang, T. Shen, W. Luo, B. Stenger, T. Lu, Ultra-high-definition low-light image enhancement: A benchmark and transformer-based method, in: Proceedings of the AAAI Conference on Artificial Intelligence, V ol. 37, 2023, pp. 2654–2662
2023
-
[57]
Shakibania, S
H. Shakibania, S. Raoufi, H. Khotanlou, Cdan: convolutional dense attention- guided network for low-light image enhancement, Digital Signal Processing 156 (2025) 104802
2025
-
[58]
Y . Gou, P. Hu, J. Lv, J. T. Zhou, X. Peng, Multi-scale adaptive network for single image denoising, Advances in Neural Information Processing Systems 35 (2022) 14099–14112
2022
-
[59]
C. Ren, X. He, C. Wang, Z. Zhao, Adaptive consistency prior based deep network for image denoising, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 8596–8606
2021
-
[60]
W. Wu, S. Liu, Y . Xia, Y . Zhang, Dual residual attention network for image de- noising, Pattern Recognition 149 (2024) 110291
2024
-
[61]
Zhang, Y
J. Zhang, Y . Zhang, J. Gu, J. Dong, L. Kong, X. Yang, Xformer: Hybrid x-shaped transformer for image denoising, in: The Twelfth International Conference on Learning Representations, 2024
2024
-
[62]
W. Yang, R. T. Tan, J. Feng, J. Liu, Z. Guo, S. Yan, Deep joint rain detection and removal from a single image, in: CVPR, 2017, pp. 1357–1366
2017
-
[63]
Zhang, V
H. Zhang, V . M. Patel, Density-aware single image de-raining using a multi- stream dense network, in: CVPR, 2018, pp. 695–704. 27
2018
-
[64]
C. O. Ancuti, C. Ancuti, M. Sbert, R. Timofte, Dense-haze: A benchmark for im- age dehazing with dense-haze and haze-free images, in: 2019 IEEE international conference on image processing (ICIP), IEEE, 2019, pp. 1014–1018
2019
-
[65]
X. Qin, Z. Wang, Y . Bai, X. Xie, H. Jia, Ffa-net: Feature fusion attention network for single image dehazing, in: Proceedings of the AAAI conference on artificial intelligence, V ol. 34, 2020, pp. 11908–11915
2020
-
[66]
H. Dong, J. Pan, L. Xiang, Z. Hu, X. Zhang, F. Wang, M.-H. Yang, Multi- scale boosted dehazing network with dense feature fusion, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 2157–2167
2020
-
[67]
M. Zhou, J. Huang, C.-L. Guo, C. Li, Fourmer: An efficient global modeling paradigm for image restoration, in: International conference on machine learning, PMLR, 2023, pp. 42589–42601. 28
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.