Minimalist Preprocessing Approach for Image Synthesis Detection
Pith reviewed 2026-06-25 21:39 UTC · model grok-4.3
The pith
Computing the gradient of grayscale intensity between neighboring pixels detects synthesized images at accuracy levels comparable to complex methods but with far lower computational cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
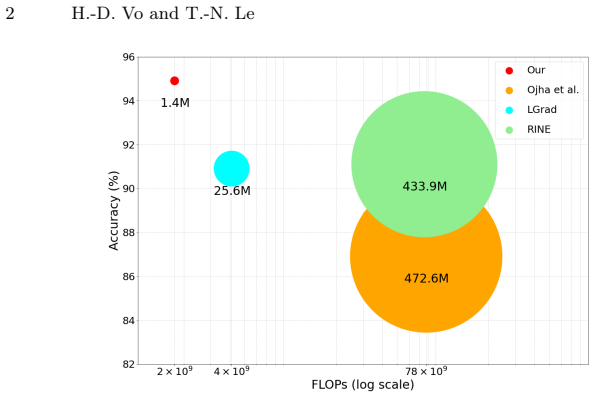
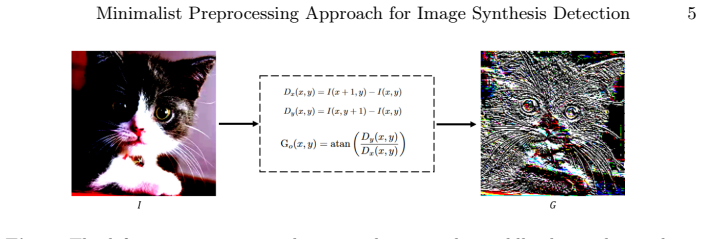
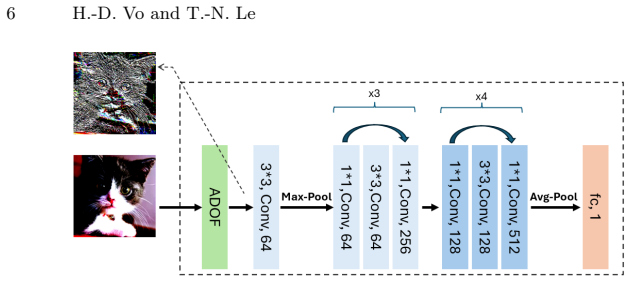
The central claim is that calculating the gradient of grayscale intensity between neighboring pixels produces discriminative features sufficient to distinguish synthesized images from authentic ones. This computation acts as a high-pass filter that emphasizes pixel variations while minimizing color influence, allowing the method to reach accuracy levels comparable to state-of-the-art techniques across multiple datasets and generative models while requiring only minimal computational resources.
What carries the argument
The gradient of grayscale intensity between neighboring pixels, used as a high-pass filter to highlight local fluctuations and reduce color influence.
If this is right
- Detection becomes feasible on smartphones and other resource-constrained devices.
- The preprocessing step can be applied before feeding images into lightweight classifiers.
- Color channels can be ignored without major loss of detection performance.
- The approach scales to new generative models if local pixel fluctuations remain a reliable signal.
Where Pith is reading between the lines
- Mobile apps could integrate the filter for on-device screening of shared images before upload.
- The finding implies that many synthesis artifacts manifest in local intensity changes rather than global statistics.
- Similar gradient-based filters might be tested on video frames or other modalities for forgery detection.
Load-bearing premise
That the gradient of grayscale intensity between neighboring pixels alone yields features that remain discriminative across datasets and different generative models without color or semantic information.
What would settle it
A new dataset of images generated by advanced models that preserve local grayscale gradients closely, where the method's reported accuracy falls substantially below current state-of-the-art detectors.
Figures
read the original abstract
Generative models have significantly advanced image generation, resulting in synthesized images that are increasingly indistinguishable from authentic ones. However, the creation of fake images with malicious intent is a growing concern. Low-configured smart devices have become highly popular, making it easier for deceptive images to reach users. Consequently, the demand for effective detection methods is increasingly urgent. In this paper, we introduce a simple yet efficient method that captures pixel fluctuations between neighboring pixels by calculating the gradient, which highlights variations in grayscale intensity. This approach functions as a high-pass filter, emphasizing key features for accurate image distinction while minimizing color influence. Our experiments on multiple datasets demonstrate that our method achieves accuracy levels comparable to state-of-the-art techniques while requiring minimal computational resources. Therefore, it is suitable for deployment on low-end devices such as smartphones. The code is available at https://github.com/vohoaidanh/adof.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a minimalist preprocessing technique for image synthesis detection that computes the gradient of grayscale intensity between neighboring pixels, functioning as a high-pass filter to highlight fluctuations while reducing color influence. It asserts that experiments on multiple datasets achieve accuracy comparable to state-of-the-art methods with low computational cost, making the approach suitable for deployment on low-end devices such as smartphones. Code is provided via GitHub.
Significance. If the performance claims are substantiated, the work could contribute a practical, resource-efficient preprocessing step for on-device synthetic image detection, addressing accessibility needs in combating deepfakes on consumer hardware. The focus on simplicity and the public code release support reproducibility.
major comments (2)
- [Abstract] Abstract: The central claim that experiments 'achieve accuracy levels comparable to state-of-the-art techniques' on 'multiple datasets' is unsupported by any reported quantitative metrics, baseline comparisons, dataset names, or error analysis, rendering the empirical generalization claim unevaluable.
- [Method] Method section: The grayscale-only gradient is presented as sufficient without any ablation restoring color channels or testing generators with known chromatic artifacts (e.g., hue/saturation inconsistencies), directly undermining the sufficiency assumption for the claimed cross-generator performance.
minor comments (1)
- [Abstract] The abstract references 'our experiments' without even high-level details on datasets or models, which should be summarized for clarity even if full results appear later.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comments point by point below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that experiments 'achieve accuracy levels comparable to state-of-the-art techniques' on 'multiple datasets' is unsupported by any reported quantitative metrics, baseline comparisons, dataset names, or error analysis, rendering the empirical generalization claim unevaluable.
Authors: We agree that the abstract would be strengthened by including specific quantitative support for the claim. The manuscript reports results across multiple datasets with accuracy figures comparable to referenced SOTA methods; we will revise the abstract to explicitly state key accuracy values, name the datasets, and reference the baseline comparisons from the experimental section. revision: yes
-
Referee: [Method] Method section: The grayscale-only gradient is presented as sufficient without any ablation restoring color channels or testing generators with known chromatic artifacts (e.g., hue/saturation inconsistencies), directly undermining the sufficiency assumption for the claimed cross-generator performance.
Authors: The method is intentionally minimalist and uses grayscale conversion to minimize color influence, as color statistics can differ across generators; the gradient computation is argued to capture intensity fluctuations that are generator-agnostic. We acknowledge that an explicit ablation would provide stronger evidence for sufficiency. We will add an ablation study comparing grayscale versus full-color input in the revised manuscript. revision: yes
Circularity Check
No circularity: fixed preprocessing with external empirical support
full rationale
The paper describes a fixed, non-learned preprocessing step (grayscale gradient computation) without equations, parameter fitting, or derivations. Claims of comparable accuracy rest on reported experiments across datasets rather than any self-referential reduction. No self-citations, ansatzes, or uniqueness theorems are invoked to justify the method. This is the common case of an empirical method whose validity is tested externally.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Gradient of grayscale intensity between neighboring pixels produces features that distinguish synthesized from authentic images
Reference graph
Works this paper leans on
-
[1]
New J Chem35(5) (2013)
Arunachalam, S., Khairnar, S., Desale, B.: The fast fourier transform algorithm and its application in digital image processing. New J Chem35(5) (2013)
2013
-
[2]
Bauer, L.A., Bindschaedler, V.: Generative models for security: Attacks, defenses, and opportunities. arXiv:2107.10139 (2021)
arXiv 2021
-
[3]
Cara Curtis: California makes deepfakes illegal to curb revenge porn and doctored political videos (2019),https://bit.ly/4f40oaX, accessed: 2024-09-24
2019
-
[4]
Digital4(2), 316– 332 (2024)
Casteleiro-Pitrez, J.: Generative artificial intelligence image tools among future designers: A usability, user experience, and emotional analysis. Digital4(2), 316– 332 (2024)
2024
-
[5]
Chai, L., Bau, D., Lim, S.N., Isola, P.: What makes fake images detectable? un- derstanding properties that generalize. In: Eur. Conf. on Computer Vision. (2020)
2020
-
[6]
Chen, Z., Wang, X.: Application of ai technology in interior design179(2020)
2020
-
[7]
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., Houlsby, N.: An image is worth 16x16 words: Transformers for image recognition at scale. CoRR abs/2010.11929(2020)
Pith/arXiv arXiv 2010
-
[8]
Durall, R., Keuper, M., Pfreundt, F.J., Keuper, J.: Unmasking deepfakes with simple features. ArXivabs/1911.00686(2019)
arXiv 1911
-
[9]
7890–7899 (2020)
Durall, R., Keuper, M., Keuper, J.: Watch your up-convolution: Cnn based gen- erative deep neural networks are failing to reproduce spectral distributions pp. 7890–7899 (2020)
2020
-
[10]
ArXiv (2020)
Frank, J.C., Eisenhofer, T., Schönherr, L., Fischer, A., Kolossa, D., Holz, T.: Lever- aging frequency analysis for deep fake image recognition. ArXiv (2020)
2020
-
[11]
Communications of the ACM63, 139–144 (2014)
Goodfellow, I.J., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A.C., Bengio, Y.: Generative adversarial networks. Communications of the ACM63, 139–144 (2014)
2014
-
[12]
Gu, S., Chen, D., Bao, J., Wen, F., Zhang, B., Chen, D., Yuan, L., Guo, B.: Vector quantized diffusion model for text-to-image synthesis. CVPR pp. 10696– 10706 (2022)
2022
-
[13]
770–778 (2016)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition pp. 770–778 (2016)
2016
-
[14]
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. ArXiv abs/2006.11239(2020)
Pith/arXiv arXiv 2006
-
[15]
Jeong, Y., Kim, D., Ro, Y., Choi, J.: Frepgan: Robust deepfake detection using frequency-levelperturbations.In:AAAIConferenceonArtificialIntelligence(2022)
2022
-
[16]
Jeong, Y., Kim, D., Min, S., Joe, S., Gwon, Y., Choi, J.: Bihpf: Bilateral high-pass filters for robust deepfake detection. WACV pp. 48–57 (2022)
2022
-
[17]
In: ICIP
Ju, Y., Jia, S., Ke, L., Xue, H., Nagano, K., Lyu, S.: Fusing global and local features for generalized ai-synthesized image detection. In: ICIP. pp. 3465–3469 (2022)
2022
-
[18]
ArXivabs/1710.10196(2017) Minimalist Preprocessing Approach for Image Synthesis Detection 11
Karras, T., Aila, T., Laine, S., Lehtinen, J.: Progressive growing of gans for im- proved quality, stability, and variation. ArXivabs/1710.10196(2017) Minimalist Preprocessing Approach for Image Synthesis Detection 11
Pith/arXiv arXiv 2017
-
[19]
8110–8119 (2020)
Karras, T., Laine, S., Aittala, M., Hellsten, J., Lehtinen, J., Aila, T.: Analyzing and improving the image quality of stylegan pp. 8110–8119 (2020)
2020
-
[20]
Korosec, K.: Deepfake revenge porn is now illegal in virginia (2019),https://techcrunch.com/2019/07/01/ deepfake-revenge-porn-is-now-illegal-in-virginia/, accessed: 24 Sep
2019
-
[21]
Koutlis, C., Papadopoulos, S.: Leveraging representations from intermediate encoder-blocks for synthetic image detection. arXiv:2402.19091 (2024)
arXiv 2024
-
[22]
Communications of the ACM60, 84 – 90 (2012)
Krizhevsky, A., Sutskever, I., Hinton, G.E.: Imagenet classification with deep con- volutional neural networks. Communications of the ACM60, 84 – 90 (2012)
2012
-
[23]
In: CVPR
Liu, H., Tan, Z., Tan, C., Wei, Y., Wang, J., Zhao, Y.: Forgery-aware adaptive transformer for generalizable synthetic image detection. In: CVPR. pp. 10770– 10780 (2024)
2024
-
[24]
In: CVPR
Liu, Z., Qi, X., Torr, P.H.: Global texture enhancement for fake face detection in the wild. In: CVPR. pp. 8060–8069 (2020)
2020
-
[25]
In: ICCAIS
Lomov, I., Makarov, I.: Generative models for fashion industry using deep neural networks. In: ICCAIS. pp. 1–6. IEEE (2019)
2019
-
[26]
3091–3095 (2022)
Mandelli, S., Bonettini, N., Bestagini, P., Tubaro, S.: Detecting gan-generated im- ages by orthogonal training of multiple cnns pp. 3091–3095 (2022)
2022
-
[27]
Mickens,R.E.:Differenceequations:theory,applicationsandadvancedtopics.CRC Press (2015)
2015
-
[28]
24480–24489 (2023)
Ojha, U., Li, Y., Lee, Y.J.: Towards universal fake image detectors that generalize across generative models pp. 24480–24489 (2023)
2023
-
[29]
Qian,Y.,Yin,G.,Sheng,L.,Chen,Z.,Shao,J.:Thinkinginfrequency:Faceforgery detection by mining frequency-aware clues. ArXivabs/2007.09355(2020)
arXiv 2007
-
[30]
8748–8763 (2021)
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision pp. 8748–8763 (2021)
2021
-
[31]
for Schools, B.: Spotting ai: Knowing how to recognise real vs ai images.https: //elearn.eb.com/real-vs-ai-images/(2024), accessed: 2024-08-21
2024
-
[32]
18720–18729 (2022)
Shiohara, K., Yamasaki, T.: Detecting deepfakes with self-blended images pp. 18720–18729 (2022)
2022
-
[33]
Tan, C., Zhao, Y., Wei, S., Gu, G., Liu, P., Wei, Y.: Frequency-aware deepfake de- tection: Improving generalizability through frequency space domain learning38(5), 5052–5060 (2024)
2024
-
[34]
28130–28139 (2024)
Tan, C., Zhao, Y., Wei, S., Gu, G., Liu, P., Wei, Y.: Rethinking the up-sampling operations in cnn-based generative network for generalizable deepfake detection pp. 28130–28139 (2024)
2024
-
[35]
12105–12114 (2023)
Tan, C., Zhao, Y., Wei, S., Gu, G., Wei, Y.: Learning on gradients: Generalized artifacts representation for gan-generated images detection pp. 12105–12114 (2023)
2023
-
[36]
for now pp
Wang, S.Y., Wang, O., Zhang, R., Owens, A., Efros, A.A.: Cnn-generated images are surprisingly easy to spot... for now pp. 8695–8704 (2020)
2020
-
[37]
22445–22455 (2023)
Wang, Z., Bao, J., Zhou, W., Wang, W., Hu, H., Chen, H., Li, H.: Dire for diffusion- generated image detection pp. 22445–22455 (2023)
2023
-
[38]
Wikipedia Contributors: Finite difference (2024),https://en.wikipedia.org/ wiki/Finite_difference, accessed: 2024-08-21
2024
-
[39]
arXiv e-prints (2024)
Wootaek Shin, P., Ahn, J.J., Yin, W., Sampson, J., Narayanan, V.: Can prompt modifiers control bias? a comparative analysis of text-to-image generative models. arXiv e-prints (2024)
2024
-
[40]
Zhong, N., Xu, Y., Li, S., Qian, Z., Zhang, X.: Patchcraft: Exploring texture patch for efficient ai-generated image detection (2024)
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.