CAMF-Det: Closure-Aware Multimodal Fusion for LiDAR-Camera 3D Object Detection on UAV Platforms
Pith reviewed 2026-06-27 17:08 UTC · model grok-4.3
The pith
CAMF-Det improves UAV 3D object detection by modeling dual-modal occlusion from tree canopies with physics-inspired priors and embedding them throughout the pipeline.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
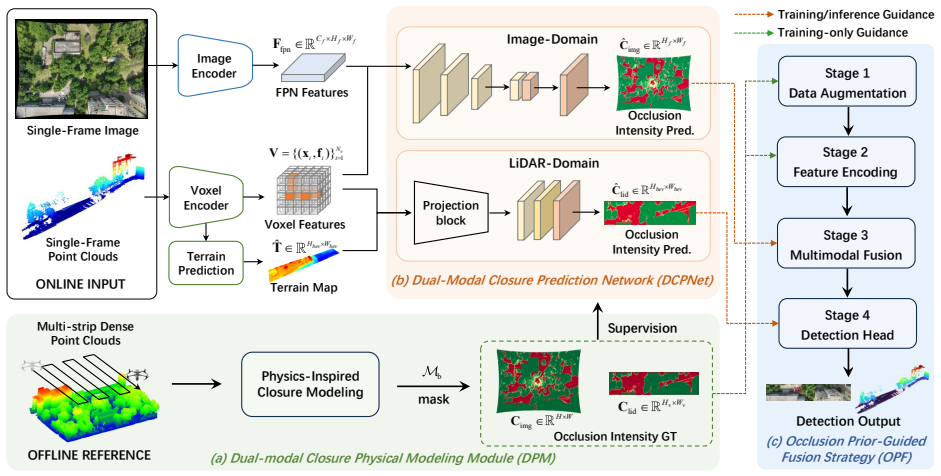
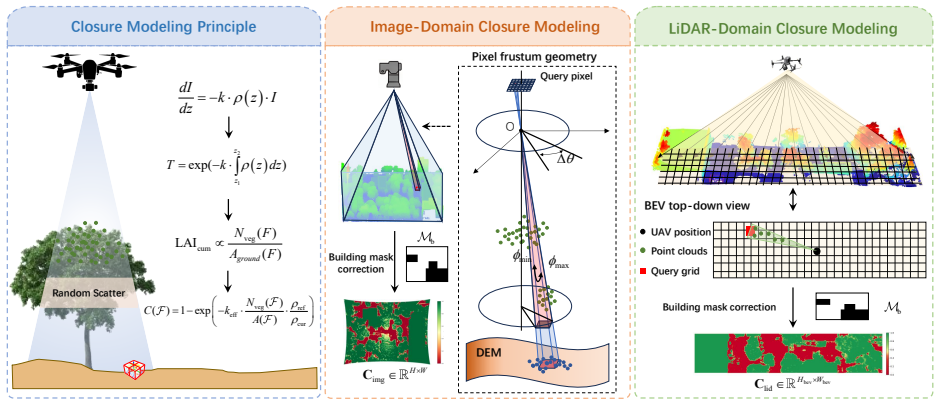
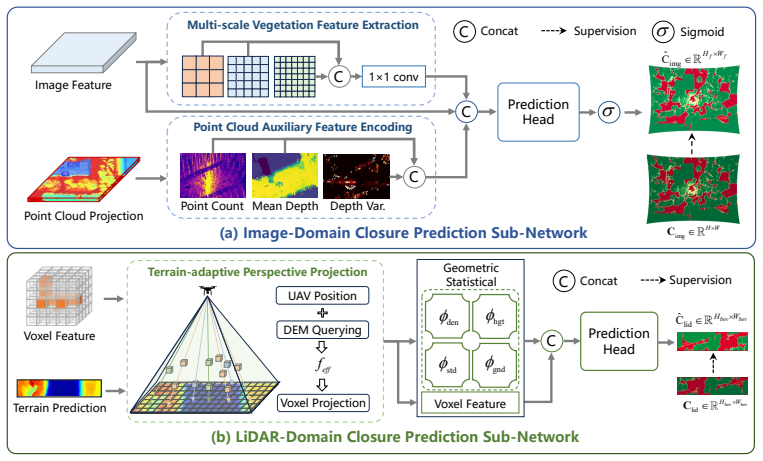
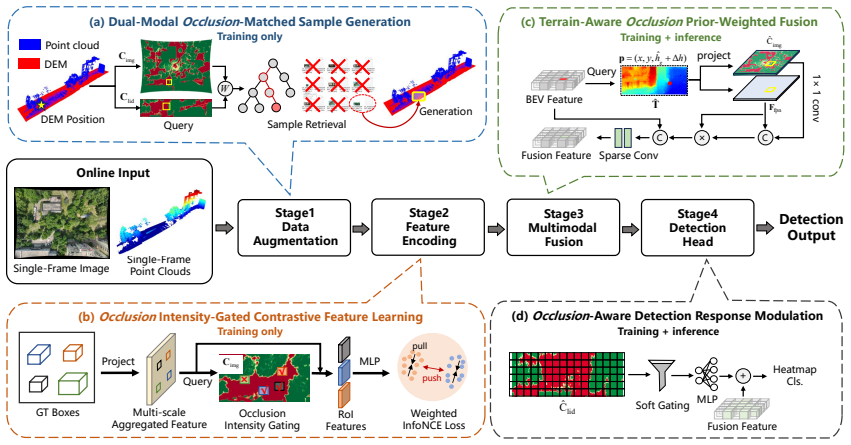
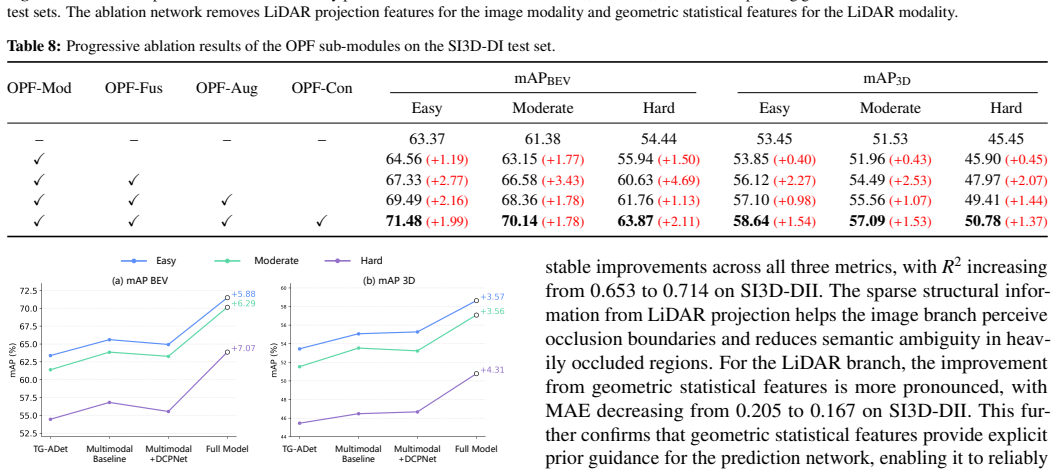
CAMF-Det derives dual-modal occlusion intensity through physics-inspired modeling and embeds them as priors throughout the detection pipeline. First, a dual-modal closure modeling module explicitly constructs occlusion intensity ground truth for both modalities offline via a Beer-Lambert-inspired formulation and building-mask correction. Second, using these ground-truth maps as supervision, a dual-modal prediction network converts the offline modeling results into online occlusion intensity predictions under single-frame inference. Third, both ground-truth and predicted occlusion intensity are injected into data augmentation, feature encoding, multimodal fusion, and detection head, enabling
What carries the argument
Dual-modal closure modeling module that constructs occlusion intensity ground truth offline via a Beer-Lambert-inspired formulation and building-mask correction, then supervises an online prediction network whose outputs are injected at multiple pipeline stages.
If this is right
- The framework enables adaptive detection by injecting occlusion priors at data augmentation, feature encoding, multimodal fusion, and detection head stages.
- Performance gains are observed across all difficulty levels and are largest on hard examples dominated by occlusion.
- The method supports single-frame inference once the online prediction network has been trained on offline ground-truth maps.
- Both the ground-truth and the predicted occlusion intensity maps contribute to the final detection accuracy when used as priors.
Where Pith is reading between the lines
- The same offline modeling step could be applied to other elevated sensor platforms that encounter vegetation occlusion.
- Replacing the building-mask correction with a learned semantic segmentation step might extend the approach to scenes without reliable building maps.
- Testing whether the predicted occlusion intensities correlate with actual per-modality feature degradation on held-out UAV flights would provide an independent check on the modeling fidelity.
Load-bearing premise
The offline dual-modal closure modeling that constructs occlusion intensity ground truth via a Beer-Lambert-inspired formulation plus building-mask correction accurately represents real spatially varying and modality-dependent occlusion in UAV top-down scenes.
What would settle it
An ablation experiment in which the modeled occlusion intensity maps are replaced by random values or constant maps while keeping all other components fixed, and the reported mAP_BEV gains disappear, would show that the specific occlusion priors are not responsible for the performance improvements.
Figures


read the original abstract
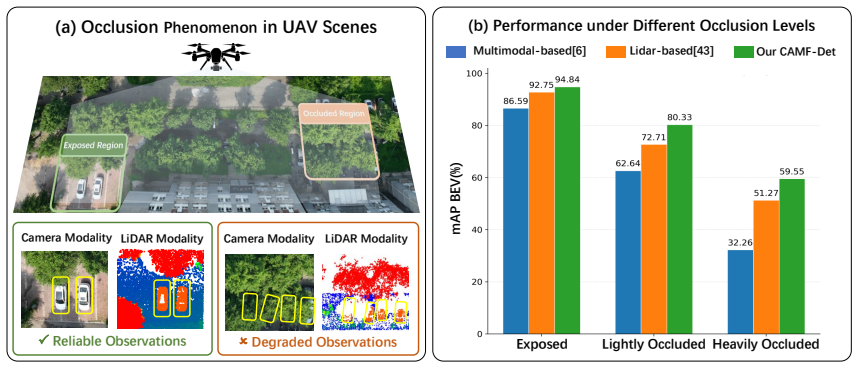
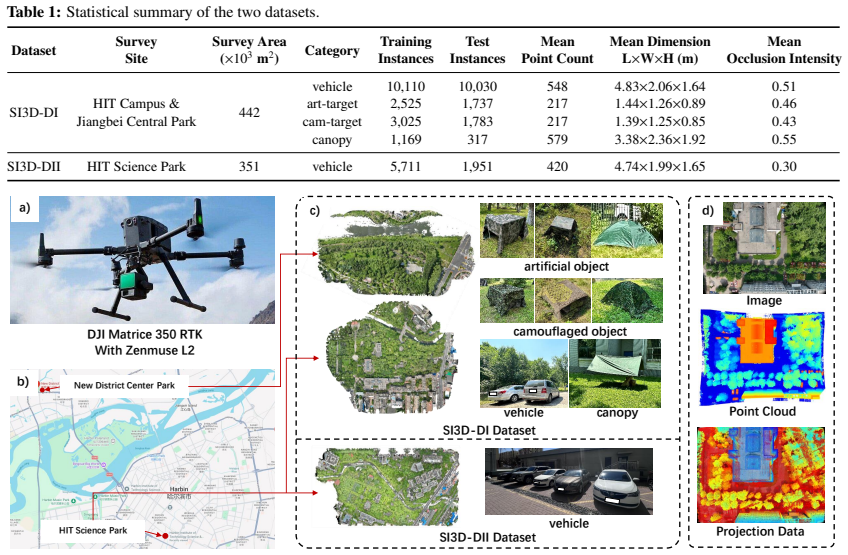
Multimodal 3D object detection based on LiDAR and cameras has demonstrated excellent performance in ground-vehicle scenarios, but has not been explored for Unmanned Aerial Vehicle (UAV) platforms. In UAV top-down scenes, frequent groundobject occlusion dominated by tree canopies causes spatially varying and modality-dependent information degradation. Existing multimodal fusion frameworks neither explicitly model such ground-object occlusion nor embed occlusion awareness into the detection pipeline, limiting their performance in occluded UAV scenes. To address these challenges, we propose CAMF-Det, a closure-aware multimodal fusion framework for LiDAR-camera 3D object detection on UAV platforms, which derives dual-modal occlusion intensity through physics-inspired modeling and embeds them as priors throughout the detection pipeline. First, a dual-modal closure modeling module explicitly constructs occlusion intensity ground truth for both modalities offline via a Beer-Lambert-inspired formulation and building-mask correction. Second, using these ground-truth maps as supervision, a dual-modal prediction network converts the offline modeling results into online occlusion intensity predictions under single-frame inference. Third, both ground-truth and predicted occlusion intensity are injected into data augmentation, feature encoding, multimodal fusion, and detection head, enabling adaptive detection under spatially varying and modality-dependent information degradation. Experiments on two self-built UAV-based multimodal datasets, SI3D-DI and SI3D-DII, demonstrate that CAMF-Det achieves the best performance across all difficulty levels, with hard-level mAP$_{\mathrm{BEV}}$ improvements of 9.43% and 4.88% over the best competing methods, respectively. These results confirm the effectiveness of explicit occlusion prior modeling and exploitation for robust multimodal 3D detection in UAV scenes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CAMF-Det, a closure-aware multimodal fusion framework for LiDAR-camera 3D object detection on UAV platforms. It derives dual-modal occlusion intensity ground truth offline via a Beer-Lambert-inspired transmittance formulation with building-mask correction, trains an online prediction network under this supervision, and injects both ground-truth and predicted occlusion maps as priors into data augmentation, feature encoding, multimodal fusion, and the detection head to handle spatially varying, modality-dependent degradation from tree canopies. Experiments on two self-built datasets (SI3D-DI and SI3D-DII) report state-of-the-art results, including hard-level mAP_BEV gains of 9.43% and 4.88% over the best competing methods.
Significance. If the empirical results hold, the work would be significant for extending multimodal 3D detection to UAV top-down scenes, where occlusion is a dominant issue not addressed by ground-vehicle frameworks. The explicit use of physics-inspired modeling to generate supervision signals for occlusion awareness is a methodological strength that could inspire similar prior-injection approaches in other degraded sensing scenarios.
major comments (3)
- [Abstract and Experiments] Abstract and Experiments section: the headline hard-level mAP_BEV gains of 9.43% and 4.88% are presented without baseline implementation details, error bars, multiple-run statistics, or ablation studies isolating the contribution of the dual-modal closure modeling and prior injection; this makes it impossible to verify whether the central performance claim is attributable to the proposed components.
- [Dual-modal closure modeling module] Dual-modal closure modeling module: the offline construction of occlusion intensity ground truth via Beer-Lambert-inspired formulation plus building-mask correction is treated as faithful supervision for the online network and downstream injection, yet no validation (qualitative comparison to real sensor degradation, alternative modeling baselines, or sensitivity analysis on extinction coefficients) is supplied to confirm it captures modality-dependent, spatially varying occlusion in UAV canopy scenes.
- [Experiments] Experiments section: the two datasets are self-built with no public release or access stated, and no cross-validation or external dataset results are reported; this directly undermines reproducibility of the load-bearing empirical claim.
minor comments (1)
- [Abstract] Notation for mAP_BEV and difficulty levels should be defined at first use and cross-referenced to standard 3D detection metrics.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below, committing to revisions that strengthen clarity, validation, and reproducibility where possible without misrepresenting the current work.
read point-by-point responses
-
Referee: [Abstract and Experiments] Abstract and Experiments section: the headline hard-level mAP_BEV gains of 9.43% and 4.88% are presented without baseline implementation details, error bars, multiple-run statistics, or ablation studies isolating the contribution of the dual-modal closure modeling and prior injection; this makes it impossible to verify whether the central performance claim is attributable to the proposed components.
Authors: We agree that additional implementation details and isolation of contributions would improve verifiability. In the revised manuscript, we will expand the Experiments section with full baseline implementation descriptions (including any UAV-specific adaptations), and we will augment the existing ablation studies to explicitly quantify the isolated effects of the dual-modal closure modeling module and the prior injection strategy. For error bars and multiple-run statistics, we will report averaged results over multiple random seeds where computational resources permit. revision: partial
-
Referee: [Dual-modal closure modeling module] Dual-modal closure modeling module: the offline construction of occlusion intensity ground truth via Beer-Lambert-inspired formulation plus building-mask correction is treated as faithful supervision for the online network and downstream injection, yet no validation (qualitative comparison to real sensor degradation, alternative modeling baselines, or sensitivity analysis on extinction coefficients) is supplied to confirm it captures modality-dependent, spatially varying occlusion in UAV canopy scenes.
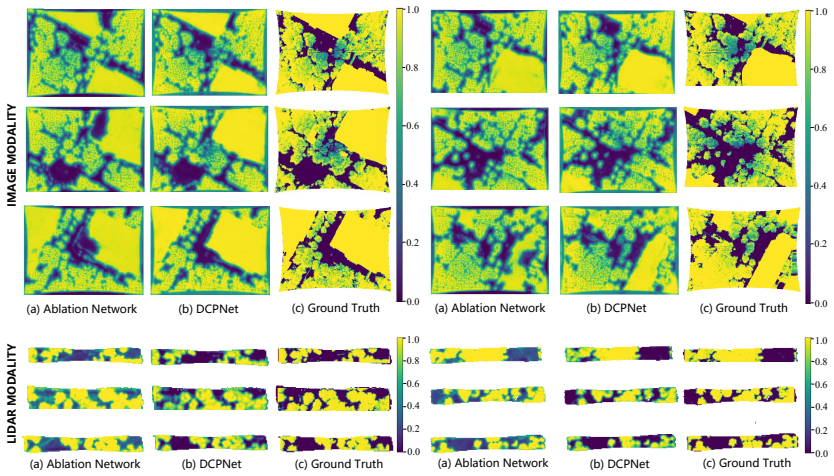
Authors: We acknowledge that explicit validation of the offline modeling would strengthen the claim. The Beer-Lambert formulation is a physically grounded model for transmittance, with the building-mask correction tailored to UAV canopy scenes. In the revision, we will add qualitative side-by-side comparisons of the derived occlusion intensity maps against observed LiDAR point density drops and camera visibility degradation in sample scenes. We will also include sensitivity analysis on extinction coefficients and comparisons to alternative modeling baselines. revision: yes
-
Referee: [Experiments] Experiments section: the two datasets are self-built with no public release or access stated, and no cross-validation or external dataset results are reported; this directly undermines reproducibility of the load-bearing empirical claim.
Authors: We understand the reproducibility concern. The SI3D-DI and SI3D-DII datasets were purpose-built for UAV top-down canopy occlusion scenarios. In the revised manuscript, we will provide substantially more detail on acquisition setup, sensor parameters, flight trajectories, and annotation methodology. We will explicitly discuss the difficulty of cross-validation against ground-vehicle datasets (due to fundamentally different occlusion patterns) and will explore options for releasing a subset of the data or providing generation scripts where feasible. revision: partial
Circularity Check
No circularity: external physics-based supervision and standard supervised prediction
full rationale
The paper constructs occlusion intensity GT offline using a Beer-Lambert-inspired formulation plus building-mask correction (external physical model, not derived from detection outputs or fitted to task results). The dual-modal prediction network is then trained to predict these GT maps from single-frame inputs; this is ordinary supervised learning, not a prediction that reduces to its own inputs by construction. No self-citations, uniqueness theorems, or ansatzes smuggled via prior work appear in the derivation chain. Performance claims rest on empirical results on held-out test sets rather than any definitional equivalence. The chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- extinction coefficients
axioms (1)
- domain assumption Beer-Lambert law applies to light and laser attenuation through tree canopies in top-down UAV views
Reference graph
Works this paper leans on
-
[1]
L. Wang, X. Zhang, Z. Song, J. Bi, G. Zhang, H. Wei, L. Tang, L. Yang, J. Li, C. Jia, Multi-modal 3D object detection in autonomous driving: A survey and taxonomy, IEEE Transactions on Intelligent Vehicles, 8 (2023) 3781-3798
2023
-
[2]
Y . Wang, Q. Mao, H. Zhu, J. Deng, Y . Zhang, J. Ji, H. Li, Y . Zhang, Multi- modal 3d object detection in autonomous driving: a survey, International Journal of Computer Vision, 131 (2023) 2122-2152
2023
-
[3]
Z. Song, L. Liu, F. Jia, Y . Luo, C. Jia, G. Zhang, L. Yang, L. Wang, Robustness-aware 3d object detection in autonomous driving: A review and outlook, IEEE Transactions on Intelligent Transportation Systems, 25 (2024) 15407-15436
2024
-
[4]
V ora, A.H
S. V ora, A.H. Lang, B. Helou, O. Beijbom, Pointpainting: Sequential fu- sion for 3d object detection, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 4604-4612
2020
-
[5]
C. Wang, C. Ma, M. Zhu, X. Yang, Pointaugmenting: Cross-modal augmentation for 3d object detection, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 11794- 11803
2021
-
[6]
Z. Liu, H. Tang, A. Amini, X. Yang, H. Mao, D.L. Rus, S. Han, Bevfusion: Multi-task multi-sensor fusion with unified bird’s-eye view representa- tion, in: 2023 IEEE international conference on robotics and automation (ICRA), IEEE, 2023, pp. 2774-2781. 14
2023
-
[7]
Z. Ning, Z. Liu, X. Gao, Y . Zuo, J. Yang, Y . Fang, W. Liu, CMF-IoU: Multi-Stage Cross-Modal Fusion 3D Object Detection with IoU Joint Pre- diction, IEEE Transactions on Circuits and Systems for Video Technology, (2025)
2025
-
[8]
B. Ding, J. Xie, J. Nie, J. Cao, SSLFusion: Scale and Space Aligned La- tent Fusion Model for Multimodal 3D Object Detection, in: Proceedings of the AAAI Conference on Artificial Intelligence, 2025, pp. 2735-2743
2025
-
[9]
X. Bai, Z. Hu, X. Zhu, Q. Huang, Y . Chen, H. Fu, C.-L. Tai, Transfusion: Robust lidar-camera fusion for 3d object detection with transformers, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 1090-1099
2022
-
[10]
Y . Tian, F. Lin, Y . Li, T. Zhang, Q. Zhang, X. Fu, J. Huang, X. Dai, Y . Wang, C. Tian, UA Vs meet LLMs: Overviews and perspectives towards agentic low-altitude mobility, Information Fusion, 122 (2025) 103158
2025
-
[11]
J. Su, X. Zhu, S. Li, W.-H. Chen, AI meets UA Vs: A survey on AI empow- ered UA V perception systems for precision agriculture, Neurocomputing, 518 (2023) 242-270
2023
-
[12]
H. Ye, R. Sunderraman, S. Ji, Uav3d: A large-scale 3d perception bench- mark for unmanned aerial vehicles, Advances in Neural Information Processing Systems, 37 (2024) 55425-55442
2024
-
[13]
Y . Hu, Y . Lu, R. Xu, W. Xie, S. Chen, Y . Wang, Collaboration helps camera overtake lidar in 3d detection, in: Proc. IEEE/CVF CVPR, 2023, pp. 9243-9252
2023
-
[14]
Meier, L
J. Meier, L. Scalerandi, O. Dhaouadi, J. Kaiser, N. Araslanov, D. Cremers, CARLA Drone: monocular 3d object detection from a different perspec- tive, in: DAGM German Conference on Pattern Recognition, Springer, 2024, pp. 137-152
2024
-
[15]
Hayton, T
J.N. Hayton, T. Barros, C. Premebida, M.J. Coombes, U.J. Nunes, CNN- based human detection using a 3D LiDAR onboard a UA V , in: 2020 IEEE international conference on autonomous robot systems and competitions (ICARSC), IEEE, 2020, pp. 312-318
2020
-
[16]
Cherif, H
B. Cherif, H. Ghazzai, A. Alsharoa, Lidar from the sky: Uav integration and fusion techniques for advanced traffic monitoring, IEEE Systems Journal, 18 (2024) 1639-1650
2024
-
[17]
Cherif, H
B. Cherif, H. Ghazzai, A. Alsharoa, H. Besbes, Y . Massoud, Aerial LiDAR-based 3D object detection and tracking for traffic monitoring, in: 2023 IEEE International symposium on circuits and systems (ISCAS), IEEE, 2023, pp. 1-5
2023
-
[18]
Y . Zhou, O. Tuzel, V oxelnet: End-to-end learning for point cloud based 3d object detection, in: Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 4490-4499
2018
-
[19]
A.H. Lang, S. V ora, H. Caesar, L. Zhou, J. Yang, O. Beijbom, Pointpillars: Fast encoders for object detection from point clouds, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 12697-12705
2019
-
[20]
Y . Yan, Y . Mao, B. Li, SECOND: Sparsely embedded convolutional detection, Sensors, 18 (10) (2018) 3337
2018
-
[21]
S. Shi, L. Jiang, J. Deng, Z. Wang, C. Guo, J. Shi, X. Wang, H. Li, PV-RCNN++: Point-voxel feature set abstraction with local vector rep- resentation for 3D object detection, International Journal of Computer Vision, 131 (2023) 531-551
2023
-
[22]
Zhang, C
G. Zhang, C. Junnan, G. Gao, J. Li, X. Hu, Hednet: A hierarchical encoder-decoder network for 3d object detection in point clouds, Ad- vances in Neural Information Processing Systems, 36 (2023) 53076- 53089
2023
-
[23]
Y . Chen, J. Liu, X. Zhang, X. Qi, J. Jia, V oxelnext: Fully sparse voxelnet for 3d object detection and tracking, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 21674- 21683
2023
-
[24]
Zhang, J
G. Zhang, J. Chen, G. Gao, J. Li, S. Liu, X. Hu, Safdnet: A simple and effective network for fully sparse 3d object detection, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 14477-14486
2024
-
[25]
L. Fan, F. Wang, N. Wang, Z. Zhang, Fsd v2: Improving fully sparse 3d object detection with virtual voxels, IEEE Transactions on Pattern Analysis and Machine Intelligence, 47 (2024) 1279-1292
2024
-
[26]
L. Fan, Z. Pang, T. Zhang, Y .-X. Wang, H. Zhao, F. Wang, N. Wang, Z. Zhang, Embracing single stride 3d object detector with sparse transformer, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 8458-8468
2022
-
[27]
Z. Liu, X. Yang, H. Tang, S. Yang, S. Han, Flatformer: Flattened window attention for efficient point cloud transformer, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 1200-1211
2023
-
[28]
H. Wang, C. Shi, S. Shi, M. Lei, S. Wang, D. He, B. Schiele, L. Wang, Dsvt: Dynamic sparse voxel transformer with rotated sets, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion, 2023, pp. 13520-13529
2023
-
[29]
Zhang, L
G. Zhang, L. Fan, C. He, Z. Lei, Z. Zhang, L. Zhang, V oxel mamba: Group-free state space models for point cloud based 3d object detection, Advances in Neural Information Processing Systems, 37 (2024) 81489- 81509
2024
-
[30]
J. Yin, J. Shen, R. Chen, W. Li, R. Yang, P. Frossard, W. Wang, Is-fusion: Instance-scene collaborative fusion for multimodal 3d object detection, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 14905-14915
2024
-
[31]
Zhang, C
G. Zhang, C. He, L. Chen, L. Zhang, BEVDilation: LiDAR-Centric Multi-Modal Fusion for 3D Object Detection, in: Proceedings of the AAAI Conference on Artificial Intelligence, 2026, pp. 12448-12456
2026
-
[32]
Y . Li, Y . Yang, Z. Lei, CoreNet: Conflict Resolution Network for point- pixel misalignment and sub-task suppression of 3D LiDAR-camera object detection, Information Fusion, 118 (2025) 102896
2025
-
[33]
B. Wang, C. Xia, X. Gao, Y . Yang, B. Ge, K.-C. Li, Y . Zhang, PV-MM3D: Point-voxel parallel dual-stream framework with dual-attention region adaptive fusion for multimodal 3D object detection, Information Fusion, (2025) 103983
2025
-
[34]
H. Wu, C. Wen, S. Shi, X. Li, C. Wang, Virtual sparse convolution for multimodal 3d object detection, in: Proceedings of the IEEE/CVF CVPR, 2023, pp. 21653-21662
2023
-
[35]
Z. Chen, Z. Li, S. Zhang, L. Fang, Q. Jiang, F. Zhao, Deformable feature aggregation for dynamic multi-modal 3D object detection, in: European conference on computer vision, Springer, 2022, pp. 628-644
2022
-
[36]
Z. Song, G. Zhang, J. Xie, L. Liu, C. Jia, S. Xu, Z. Wang, V oxelNext- Fusion: A Simple, Unified, and Effective V oxel Fusion Framework for Multimodal 3-D Object Detection, IEEE Transactions on Geoscience and Remote Sensing, 61 (2023) 1-12
2023
-
[37]
Zhang, L
H. Zhang, L. Liang, P. Zeng, X. Song, Z. Wang, SparseLIF: High- performance sparse LiDAR-camera fusion for 3D object detection, in: European conference on computer vision, Springer, 2024, pp. 109-128
2024
-
[38]
Y . Hu, S. Fang, W. Xie, S. Chen, Aerial monocular 3d object detection, IEEE Robotics and Automation Letters, 8 (2023) 1959-1966
2023
-
[39]
P. Tian, Z. Wang, P. Cheng, Y . Wang, Z. Wang, L. Zhao, M. Yan, X. Yang, X. Sun, Ucdnet: Multi-uav collaborative 3-d object detection network by reliable feature mapping, IEEE Transactions on Geoscience and Remote Sensing, 63 (2024) 1-16
2024
-
[40]
Y . Wang, Z. Wang, P. Cheng, P. Tian, Z. Yuan, J. Tian, W. Wang, L. Zhao, Uvcpnet: A uav-vehicle collaborative perception network for 3d object detection, IEEE Transactions on Geoscience and Remote Sensing, (2025)
2025
-
[41]
Shrout, O
O. Shrout, O. Nizan, Y . Ben-Shabat, A. Tal, WiSAR3D-Aerial LiDAR Dataset for 3D Object Detection, in: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2026, pp. 6580-6589
2026
-
[42]
Liang, L
A. Liang, L. Kong, D. Lu, Y . Liu, J. Fang, H. Zhao, W.T. Ooi, Perspective- invariant 3D object detection, in: Proceedings of the IEEE/CVF Interna- tional Conference on Computer Vision, 2025, pp. 27725-27738
2025
-
[43]
Jiang, X
Y . Jiang, X. Li, Y . Gu, TG-ADet: Terrain-Guided Network for 3D Object Detection in ALS Point Clouds, IEEE Transactions on Geoscience and Remote Sensing, (2025)
2025
-
[44]
J. Wang, X. Cao, J. Zhong, Y . Zhang, Z. Han, H. Yu, C. Zhang, L. He, S. Xu, J. Wang, Griffin: Aerial-ground cooperative detection and tracking dataset and benchmark, in: Proceedings of the AAAI Conference on Artificial Intelligence, 2026, pp. 9867-9875
2026
-
[45]
Monsi, T
M. Monsi, T. Saeki, On the factor light in plant communities and its importance for matter production, Annals of botany, 95 (2005) 549-567
2005
-
[46]
Korhonen, I
L. Korhonen, I. Korpela, J. Heiskanen, M. Maltamo, Airborne discrete- return LIDAR data in the estimation of vertical canopy cover, angular canopy closure and leaf area index, Remote Sensing of Environment, 115 (2011) 1065-1080. 15
2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.