Bridging Creative Intent and Visual Quality: Creator-Driven Recurrent Video Generation with Agentic Feedback Loops
Pith reviewed 2026-06-26 21:59 UTC · model grok-4.3
The pith
CHIEF lets creators drive iterative AI video generation by supplying persona-conditioned LLM critiques that self-evaluation cannot provide.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
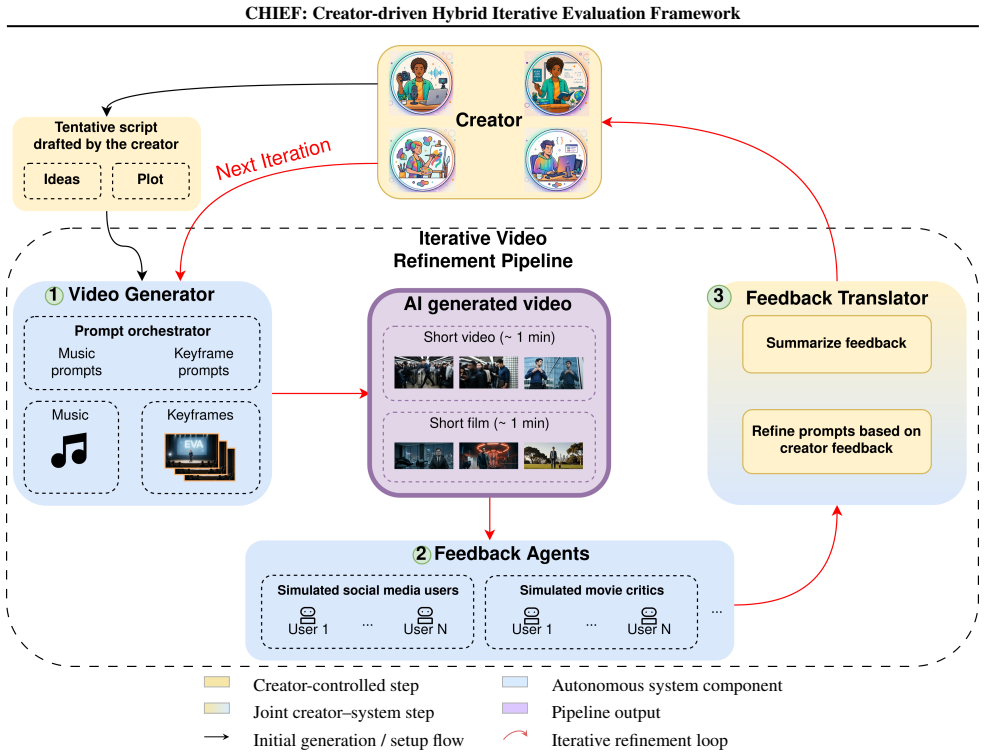
CHIEF enables recurrent video generation in which the creator directs each iteration and persona-conditioned multimodal LLMs supply subjective critiques from audience perspectives, yielding better narrative coherence and creative direction than self-evaluation by the generation model alone.
What carries the argument
The CHIEF framework of creator-driven iterations supported by a specialized refiner agent and persona-conditioned multimodal LLM feedback loops.
If this is right
- Creators can steer long-form video output through repeated human-in-the-loop cycles without needing filmmaking expertise.
- Feedback generated from audience-simulating personas surfaces plot and scene problems that internal model evaluation overlooks.
- The method supports production of complete short films with complicated plots up to ten minutes long.
- Each iteration incorporates explicit creator revisions through the refiner agent rather than relying solely on automatic improvement.
Where Pith is reading between the lines
- The same persona-feedback structure could be adapted to other generative tasks such as script writing or interactive story branching.
- Results may vary with the choice and diversity of personas used to condition the feedback LLMs.
- Adding the feedback step earlier in the generation pipeline rather than only after full video output could reduce total iteration count.
Load-bearing premise
Persona-conditioned multimodal LLMs can reliably produce subjective audience critiques that improve narrative coherence and creative direction beyond what the video model can achieve by self-evaluation.
What would settle it
Run a controlled comparison in which the same starting prompts generate videos refined only by model self-evaluation versus videos refined with CHIEF's persona-LLM feedback, then have independent viewers rate narrative coherence and creative fit.
Figures


read the original abstract
Generative AI has made content creation increasingly accessible, but many AI-generated videos lack narrative coherence and creative direction, issues that become more substantial at longer durations. Unlike coding, where AI generation benefits from reliable feedback and techniques such as recurrent self-improvement, video generation requires subjective feedback about plot, scenes, and narrative, which naturally motivates approaches that incorporate human creative direction. We introduce CHIEF, a human-AI co-creation video generation framework that places the creator at the center of human-in-the-loop iterative video refinement, and supports them by providing automatic subjective feedback. The creator incorporates their creative direction by driving each iteration, while their revisions are incorporated by a specialized refiner agent. The feedback loop is generated by persona-conditioned multimodal LLMs that watch generated videos and produce subjective critique from the audience perspectives, providing feedback that self-evaluation alone cannot capture. To test the effectiveness of our proposed framework, we work with high school and college students with no prior filmmaking experience to create videos, from short 1-minute videos to a complete short 10-minute film with a complicated plot.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CHIEF, a human-AI co-creation framework for recurrent video generation that centers the creator in iterative refinement loops. Creator intent drives each iteration while a refiner agent incorporates revisions; persona-conditioned multimodal LLMs generate automatic subjective critiques from audience perspectives to address narrative coherence and creative direction issues that self-evaluation cannot capture. Effectiveness is tested via a user study in which high-school and college students with no filmmaking experience produce videos ranging from 1-minute clips to a complete 10-minute short film with a complicated plot.
Significance. If the framework's agentic feedback loop can be shown to produce measurable gains in narrative coherence and creative direction beyond direct human input or model self-evaluation, the work would offer a concrete advance in human-in-the-loop generative video systems. The emphasis on persona-conditioned MLLM critiques as a scalable substitute for audience feedback is a distinctive technical contribution that could influence future co-creation pipelines.
major comments (2)
- [Abstract] Abstract: the description of the user study with inexperienced students states that videos from 1 to 10 minutes were produced, yet reports no quantitative metrics (coherence scores, A/B preference rates, iteration-gain statistics), no baseline comparisons (e.g., against non-LLM feedback or self-refinement), and no outcome data. This absence leaves the central claim that the persona-conditioned MLLM loop improves narrative coherence unsupported.
- [Abstract] Abstract: the value proposition rests on the assertion that persona-conditioned MLLM critiques supply feedback 'that self-evaluation alone cannot capture' and thereby enhance creative direction. No ablation, inter-rater reliability measure, or controlled comparison is described that would allow attribution of any observed improvements to the agentic loop rather than to the human creator's direct revisions.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and the evidence supporting our claims. We agree that the abstract would benefit from clearer indication of study outcomes and will revise it accordingly while preserving the manuscript's focus on the CHIEF framework. Point-by-point responses follow.
read point-by-point responses
-
Referee: [Abstract] Abstract: the description of the user study with inexperienced students states that videos from 1 to 10 minutes were produced, yet reports no quantitative metrics (coherence scores, A/B preference rates, iteration-gain statistics), no baseline comparisons (e.g., against non-LLM feedback or self-refinement), and no outcome data. This absence leaves the central claim that the persona-conditioned MLLM loop improves narrative coherence unsupported.
Authors: We agree that the abstract does not report quantitative metrics, baseline comparisons, or outcome statistics. The full manuscript presents the user study as a feasibility demonstration with qualitative descriptions of the videos produced (including the 10-minute film), but does not include numerical coherence scores or controlled baselines. We will revise the abstract to summarize key study outcomes and add quantitative metrics plus baseline comparisons (e.g., against self-refinement) to the methods/results sections in the revised manuscript. revision: yes
-
Referee: [Abstract] Abstract: the value proposition rests on the assertion that persona-conditioned MLLM critiques supply feedback 'that self-evaluation alone cannot capture' and thereby enhance creative direction. No ablation, inter-rater reliability measure, or controlled comparison is described that would allow attribution of any observed improvements to the agentic loop rather than to the human creator's direct revisions.
Authors: The framework's design uses persona-conditioned MLLMs specifically to generate audience-perspective critiques unavailable to model self-evaluation. We acknowledge the absence of explicit ablations or inter-rater measures in the current version. We will revise the manuscript to include a clearer discussion of this distinction and add any available inter-rater analysis or limited comparisons from the existing user study data to support attribution of improvements to the agentic loop. revision: yes
Circularity Check
No circularity; framework description without equations or self-referential predictions
full rationale
The paper introduces the CHIEF framework for human-AI video co-creation with persona-conditioned MLLM feedback loops. The abstract and description contain no equations, fitted parameters, predictions of derived quantities, or mathematical derivations. Claims rest on framework design and an informal user study with students; no load-bearing self-citations, ansatzes, or reductions of outputs to inputs by construction are present. The work is self-contained as a conceptual and empirical proposal.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
URL https://api.semanticscholar. org/CorpusID:252280474. Buz, T., Frost, B., Genchev, N., Schneider, M., Kaf- fee, L.-A., and de Melo, G. Investigating wit, creativity, and detectability of large language mod- els in domain-specific writing style adaptation of reddit’s showerthoughts.ArXiv, abs/2405.01660,
-
[2]
URL https://api.semanticscholar. org/CorpusID:269588087. Cheng, J., Lyu, R., Gu, X., Liu, X., Xu, J., Lu, Y ., Teng, J., Yang, Z., Dong, Y ., Tang, J., Wang, H., and Huang, M. Vpo: Aligning text-to-video generation mod- els with prompt optimization.ArXiv, abs/2503.20491,
-
[3]
URL https://api.semanticscholar. org/CorpusID:277321582. Hao, Y ., Chi, Z., Dong, L., and Wei, F. Optimizing prompts for text-to-image generation.ArXiv, abs/2212.09611,
-
[4]
org/CorpusID:254853701
URL https://api.semanticscholar. org/CorpusID:254853701. Huang, Z., He, Y ., Yu, J., Zhang, F., Si, C., Jiang, Y ., Zhang, Y ., Wu, T., Jin, Q., Chanpaisit, N., Wang, Y ., Chen, X., Wang, L., Lin, D., Qiao, Y ., and Liu, Z. Vbench: Comprehensive benchmark suite for video generative models.2024 IEEE/CVF Conference on Computer Vi- sion and Pattern Recogniti...
2024
-
[5]
URL https://api.semanticscholar. org/CorpusID:265506207. Ji, Y ., Zhang, J., Wu, J., Zhang, S., Chen, S., Ge, C., Sun, P., Chen, W., Shao, W., Xiao, X., Huang, W., and Luo, P. Prompt-a-video: Prompt your video diffusion model via preference-aligned llm.ArXiv, abs/2412.15156,
-
[6]
URL https://api.semanticscholar. org/CorpusID:274859339. Jones, C. R. and Bergen, B. K. Large language mod- els pass the turing test.ArXiv, abs/2503.23674,
-
[7]
URL https://api.semanticscholar. org/CorpusID:277451766. Kapwing. Ai slop report: The global rise of low-quality ai videos, 2025. URL https://www.kapwing.com/blog/ ai-slop-report-the-global-rise-of-low-quality-ai-videos/ . Accessed: 2026-04-25. Langley, P. Crafting papers on machine learning. In Langley, P. (ed.),Proceedings of the 17th International Conf...
Pith/arXiv arXiv 2025
-
[8]
URL https://api.semanticscholar. org/CorpusID:275820437. Long, D. X., Wan, X., Nakhost, H., Lee, C.-Y ., Pfister, T., and Arik, S. ¨O. Vista: A test-time self-improving video generation agent.ArXiv, abs/2510.15831,
-
[9]
URL https://api.semanticscholar. org/CorpusID:282203607. Madaan, A., Tandon, N., Gupta, P., Hallinan, S., Gao, L., Wiegreffe, S., Alon, U., Dziri, N., Prabhumoye, S., Yang, Y ., Welleck, S., Majumder, B. P., Gupta, S., Yaz- danbakhsh, A., and Clark, P. Self-refine: Iterative re- finement with self-feedback.ArXiv, abs/2303.17651,
-
[10]
URL https://api.semanticscholar. org/CorpusID:257900871. Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wain- wright, C. L., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., Schulman, J., Hilton, J., Kelton, F., Miller, L. E., Simens, M., Askell, A., Welinder, P., Christiano, P. F., Leike, J., and Lowe, 9 CHIEF: Creator-driven Hybrid Iterative Evalua...
-
[11]
URL https://api.semanticscholar. org/CorpusID:246426909. Venkatesh, K., Dunlop, C., and Yanardag, P. Crea: A collab- orative multi-agent framework for creative content gen- eration with diffusion models.ArXiv, abs/2504.05306,
-
[12]
URL https://api.semanticscholar. org/CorpusID:277627064. Wu, W., Zhu, Z., and Shou, M. Z. Automated movie genera- tion via multi-agent cot planning.ArXiv, abs/2503.07314,
-
[13]
URL https://api.semanticscholar. org/CorpusID:276929150. Xie, Z., Tang, D., Tan, D., Klein, J., Bissyand, T. F., and Ezzini, S. Dreamfactory: Pioneering multi-scene long video generation with a multi-agent frame- work.ArXiv, abs/2408.11788, 2024. URL https: //api.semanticscholar.org/CorpusID: 271915831. Xu, J., Huang, Y ., Cheng, J., Yang, Y ., Xu, J., Wa...
arXiv 2024
-
[14]
URL https://api.semanticscholar. org/CorpusID:275133577. Zeng, Q., Cai, K., Chen, R., Lv, Q., and Wang, K. Co- agent: Collaborative planning and consistency agent for coherent video generation.ArXiv, abs/2512.22536,
-
[15]
URL https://api.semanticscholar. org/CorpusID:284311738. Zheng, D., Huang, Z., Liu, H., Zou, K., He, Y ., Zhang, F., Zhang, Y ., He, J., Zheng, W.-S., Qiao, Y ., and Liu, Z. Vbench-2.0: Advancing video generation benchmark suite for intrinsic faithfulness.ArXiv, abs/2503.21755,
-
[16]
simulate
URL https://api.semanticscholar. org/CorpusID:277350030. 10 CHIEF: Creator-driven Hybrid Iterative Evaluation Framework A. Persona Generation Details A.1. Pipeline Overview Persona generation operates in two stages. In the first stage, a sample of 30 comments from a single user is passed through the base persona LLM, which produces a textual persona card ...
-
[17]
Emotional Expression
-
[18]
emotional_expression
Representative Quote User comments: {comments} Self-refinement critic. System: You are evaluating how accurately a persona card captures a user’s genuine personality - their values, interests, emotional tendencies, and patterns of thought and expression. Be specific, critical, and actionable. User: Persona card: {persona_card} User’s comments: {comments} ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.