Fast Wireless Foundation Models with Early-Exits
Pith reviewed 2026-06-30 01:41 UTC · model grok-4.3
The pith
Early-exit heads on intermediate layers of a frozen wireless foundation model cut computation by up to 93 percent while improving accuracy on unseen tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
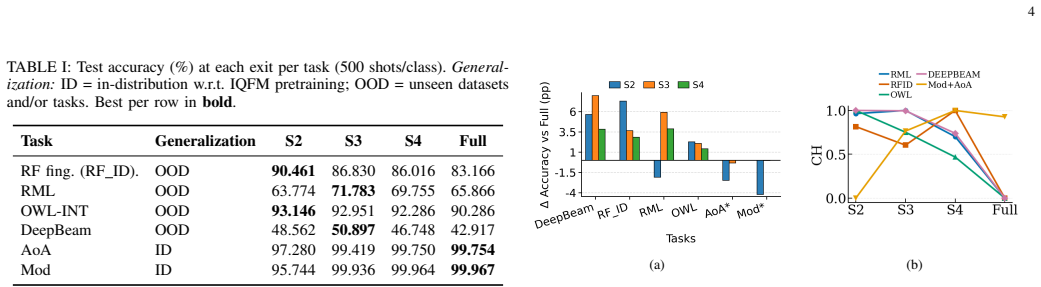
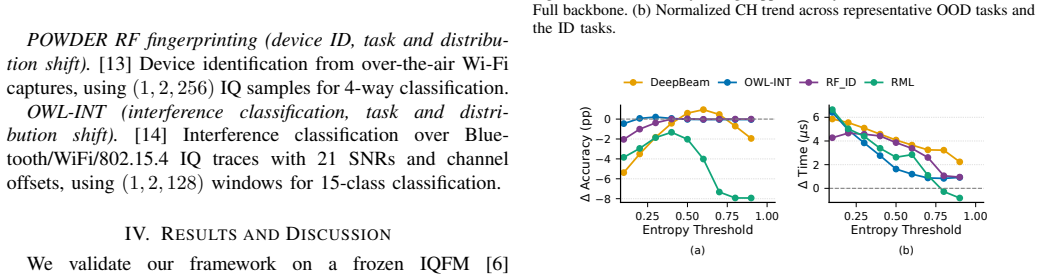
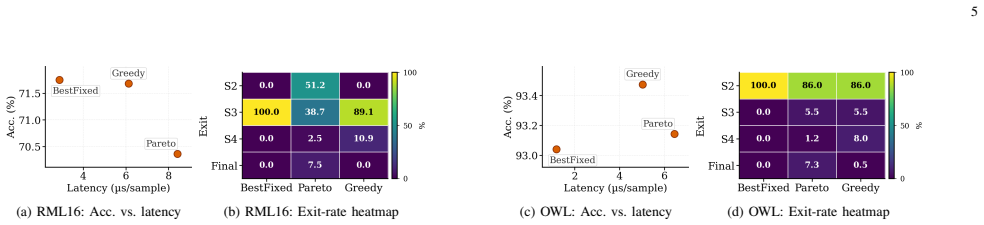
The paper establishes that intermediate-layer features from a pre-trained wireless FM encoder, paired with lightweight per-task heads, support variable-depth inference that is both faster and more accurate on unseen tasks than full-depth execution. Up to 93% fewer FLOPs are achieved, and a simple fixed-exit strategy per task outperforms traditional dynamic early-exiting policies.
What carries the argument
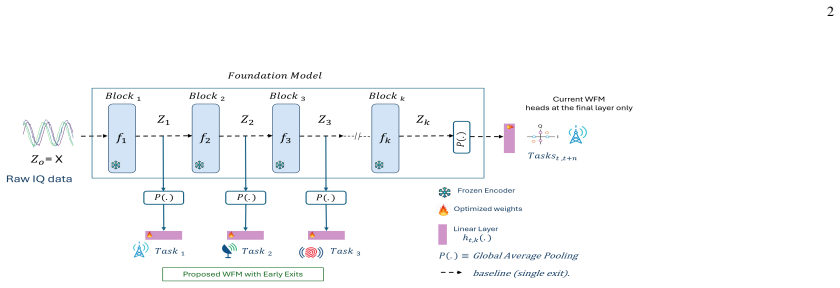
The early-exit framework attaching lightweight per-task heads at selected stages of a frozen wireless FM encoder for variable-depth inference.
If this is right
- Each task can use a representation depth matched to its needs without retraining the backbone.
- Significant reductions in inference cost make deployment of wireless FMs more practical.
- Intermediate features provide better transfer to out-of-distribution tasks than full encoder outputs.
- Fixed per-task exits are more effective than dynamic sample-by-sample routing.
Where Pith is reading between the lines
- Similar early-exit designs could apply to foundation models in other domains to improve efficiency.
- The finding suggests that full-depth inference may capture task-specific noise rather than general features.
- Selecting the optimal exit stage might be automated in future systems to further reduce overhead.
Load-bearing premise
A pre-trained wireless foundation model encoder already contains useful intermediate representations for many different tasks without needing any fine-tuning of the encoder itself.
What would settle it
A test showing that on multiple unseen wireless tasks the full encoder always matches or exceeds the accuracy of any intermediate exit, or that the claimed FLOP savings do not hold under realistic hardware measurements.
Figures
read the original abstract
While wireless foundation models (FMs) are demonstrating strong potential to enable AI-Native 6G networks, their high computational cost remains a critical barrier to deployment. The large computational cost stems from the rigid, full-depth execution of the FM backbone for every task, a process we show is not only inefficient but can also degrade performance on unseen out-of-distribution (OOD) tasks. In this paper, we propose a novel early-exit FM framework that attaches lightweight, per-task heads, at the most appropriate exit-stage of a frozen wireless FM encoder, enabling variable-depth inference tailored to each task's preferred representation depth. Our results demonstrate that these intermediate-layer features not only speed-up inference significantly (up to 93% fewer FLOPs), but also provide more transferable representations that exceed the full encoder accuracy on unseen tasks. We further demonstrate that a simple fixed-exit strategy per task is more effective than traditional early-exiting policies that route different samples to different exits based on their perceived difficulty levels.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an early-exit framework for wireless foundation models that attaches lightweight per-task heads to intermediate layers of a frozen encoder backbone. This enables task-specific variable-depth inference, with claims that intermediate features yield up to 93% FLOPs reduction while exceeding full-encoder accuracy on OOD tasks, and that fixed per-task exits outperform dynamic routing policies based on sample difficulty.
Significance. If the empirical claims hold, the work could lower deployment barriers for wireless FMs in 6G by trading depth for both efficiency and improved transferability on unseen tasks without backbone fine-tuning. The proposal of a simple fixed-exit strategy as superior to conventional early-exit routing is a potentially useful practical insight.
major comments (2)
- [Abstract] Abstract: the central quantitative claims (93% FLOPs reduction and OOD accuracy superiority over the full encoder) are stated without reference to any datasets, baselines, architectures, or error bars, rendering the headline results impossible to evaluate.
- [Abstract] Abstract (and implied § on method): the claim that intermediate-layer features are more transferable than the final representation for OOD tasks without any backbone fine-tuning is load-bearing but unsupported; no analysis of the pre-training objective, dataset distribution, or layer-wise feature properties is supplied to explain why this property should hold for wireless tasks.
minor comments (1)
- [Abstract] The abstract would be strengthened by a one-sentence description of the FM architecture depth or pre-training task to allow readers to assess plausibility of the intermediate-layer advantage.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and the need for supporting analysis. We address each major comment below, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central quantitative claims (93% FLOPs reduction and OOD accuracy superiority over the full encoder) are stated without reference to any datasets, baselines, architectures, or error bars, rendering the headline results impossible to evaluate.
Authors: We agree that the abstract would benefit from additional context to make the claims more evaluable. In the revised manuscript, the abstract will be updated to reference the specific wireless datasets and OOD tasks used in the experiments, the FM backbone architectures, the baselines compared against, and to include error bars or standard deviations for the reported FLOPs reductions and accuracy improvements. revision: yes
-
Referee: [Abstract] Abstract (and implied § on method): the claim that intermediate-layer features are more transferable than the final representation for OOD tasks without any backbone fine-tuning is load-bearing but unsupported; no analysis of the pre-training objective, dataset distribution, or layer-wise feature properties is supplied to explain why this property should hold for wireless tasks.
Authors: The empirical results in the experiments section demonstrate the OOD accuracy gains from intermediate layers over the full encoder across multiple tasks and datasets. We acknowledge that an explanatory analysis would strengthen the interpretation. The revised manuscript will include a new discussion subsection that analyzes the pre-training objective (multi-task wireless signal modeling), dataset characteristics, and layer-wise properties (e.g., through feature similarity or activation statistics) to provide insight into the observed transferability, drawing on the existing experimental data. revision: yes
Circularity Check
No significant circularity; empirical proposal with independent experimental claims
full rationale
The paper proposes an early-exit framework for frozen wireless foundation models and reports empirical speedups and accuracy gains on OOD tasks. No equations, derivations, or parameter-fitting steps appear in the abstract or described claims that reduce results to inputs by construction. Performance assertions rest on experimental outcomes rather than self-definitional mappings, fitted-input predictions, or load-bearing self-citations. The central assumption (intermediate layers of a pre-trained encoder being more transferable) is an empirical hypothesis open to falsification, not a tautology. This is the expected self-contained case for an applied systems paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Deep learning for B5G open radio access network: Evolution, survey, case studies, and challenges,
B. Brik, K. Boutiba, and A. Ksentini, “Deep learning for B5G open radio access network: Evolution, survey, case studies, and challenges,” IEEE Open J. Commun. Soc., vol. 3, pp. 228–250, 2022
2022
-
[2]
6G WavesFM: A foundation model for sensing, communication, and localization,
A. Aboulfotouh, E. Mohammed, and H. Abou-Zeid, “6G WavesFM: A foundation model for sensing, communication, and localization,”IEEE Open J. Commun. Soc., vol. 6, pp. 6792–6807, 2025
2025
-
[3]
A MIMO wireless channel foundation model via CIR-CSI consistency,
J. Jiang, W. Yu, Y . Li, Y . Gao, and S. Xu, “A MIMO wireless channel foundation model via CIR-CSI consistency,”arXiv preprint arXiv:2502.11965, 2025
-
[4]
WirelessGPT: A generative pre-trained multi-task learning framework for wireless communication,
T. Yang, P. Zhang, M. Zheng, Y . Shi, L. Jing, J. Huang, and N. Li, “WirelessGPT: A generative pre-trained multi-task learning framework for wireless communication,”IEEE Network, vol. 39, no. 5, pp. 58–65, 2025
2025
-
[5]
Self-supervised radio representation learning: Can we learn multiple tasks?
O. Kanu, A. Eshaghbeigi, and H. Abou-Zeid, “Self-supervised radio representation learning: Can we learn multiple tasks?” inProc. IEEE Int. Conf. Commun. (ICC), 2025, pp. 511–517
2025
-
[6]
IQFM: A wireless foundational model for I/Q streams in AI-native 6G,
O. Mashaal and H. Abou-Zeid, “IQFM: A wireless foundational model for I/Q streams in AI-native 6G,”arXiv preprint arXiv:2506.06718, 2025
-
[7]
BranchyNet: Fast inference via early exiting from deep neural networks,
S. Teerapittayanon, B. McDanel, and H. Kung, “BranchyNet: Fast inference via early exiting from deep neural networks,” inProc. 23rd Int. Conf. Pattern Recognit. (ICPR), 2016, pp. 2464–2469
2016
-
[8]
Using early exits for fast inference in automatic modulation classification,
E. Mohammed, O. Mashaal, and H. Abou-Zeid, “Using early exits for fast inference in automatic modulation classification,” inProc. IEEE GLOBECOM, 2023, pp. 291–296
2023
-
[9]
Deep learning with width- wise early exiting and rejection for computationally efficient and trust- worthy modulation classification,
D. Verbruggen, H. Sallouha, and S. Pollin, “Deep learning with width- wise early exiting and rejection for computationally efficient and trust- worthy modulation classification,”IEEE Trans. Mach. Learn. Commun. Netw., vol. 3, pp. 1143–1159, 2025
2025
-
[10]
Adaptive early exiting for collaborative inference over noisy wireless channels,
M. Jankowski, D. G ¨und¨uz, and K. Mikolajczyk, “Adaptive early exiting for collaborative inference over noisy wireless channels,” inProc. IEEE Int. Conf. Mach. Learn. Commun. Netw. (ICMLCN), 2024, pp. 126–131
2024
-
[11]
Deepbeam: Deep waveform learning for coordination-free beam management in mmwave networks,
M. Polese, F. Restuccia, and T. Melodia, “Deepbeam: Deep waveform learning for coordination-free beam management in mmwave networks,” inProc. ACM MobiHoc, 2021, pp. 61–70
2021
-
[12]
Radio machine learning dataset generation with gnu radio,
T. J. O’Shea and N. West, “Radio machine learning dataset generation with gnu radio,” inProc. GNU Radio Conference, vol. 1, no. 1, 2016
2016
-
[13]
Trust in 5g open RANs through machine learning: RF fingerprinting on the POWDER PAWR platform,
G. Reus-Muns, D. Jaisinghani, K. Sankhe, and K. R. Chowdhury, “Trust in 5g open RANs through machine learning: RF fingerprinting on the POWDER PAWR platform,” inProc. IEEE GLOBECOM, 2020, pp. 1–6
2020
-
[14]
Owl-int wireless interference dataset,
M. Schmidt, D. Block, and U. Meier, “Owl-int wireless interference dataset,” IEEE Dataport, 2022
2022
-
[15]
Intermediate layer classifiers for ood general- ization,
A. Uselis and S. J. Oh, “Intermediate layer classifiers for ood general- ization,” inProc. Int. Conf. Learn. Representations (ICLR), 2025
2025
-
[16]
Layer by Layer: Uncovering Hidden Representations in Language Models
O. Skean, M. R. Arefin, D. Zhao, N. Patel, J. Naghiyev, Y . LeCun, and R. Shwartz-Ziv, “Layer by layer: Uncovering hidden representations in language models,” arXiv:2502.02013 [cs.LG], 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.