ViBE: Co-Optimizing Workload Skew and Hardware Variability for MoE Serving
Pith reviewed 2026-06-28 18:05 UTC · model grok-4.3
The pith
ViBE assigns experts to GPUs by pairing token activation profiles with per-device speed measurements to reduce layer stragglers in MoE serving.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
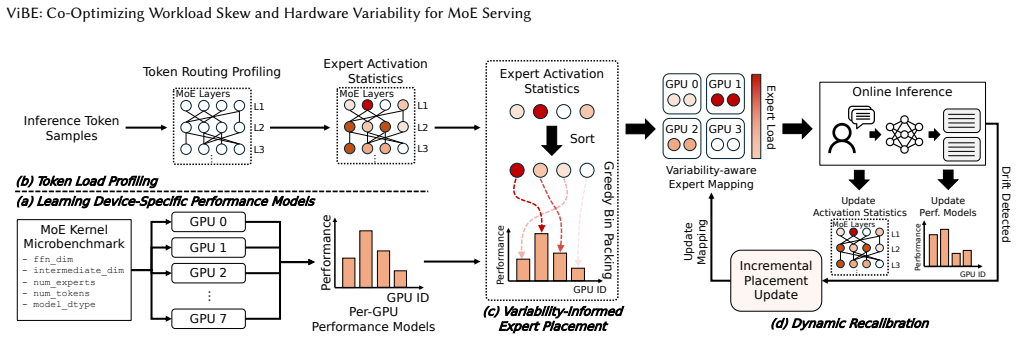
ViBE is a hardware-aware expert placement framework that minimizes execution-time imbalance across GPUs by assigning high-load experts to faster devices and low-load experts to slower ones using per-GPU performance modeling combined with expert activation profiling, while supporting recalibration under drift.
What carries the argument
Variability-Informed Binning of Experts (ViBE), which maps expert activation frequencies to device-specific throughput models so that actual layer execution time rather than token count is balanced.
Load-bearing premise
That per-GPU performance models built from profiling remain accurate enough under serving conditions to produce reliable expert-to-device assignments without introducing new stragglers or requiring model changes.
What would settle it
A side-by-side run of token-balanced placement versus ViBE placement that measures whether the maximum per-layer GPU execution time drops and whether predicted versus observed runtimes stay within a small error band.
Figures
read the original abstract
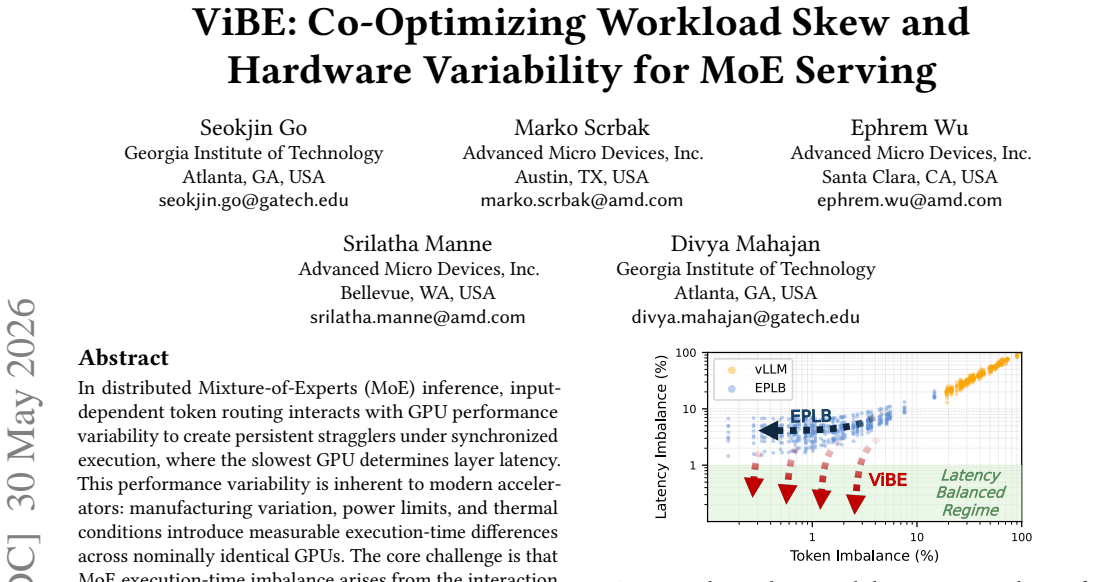
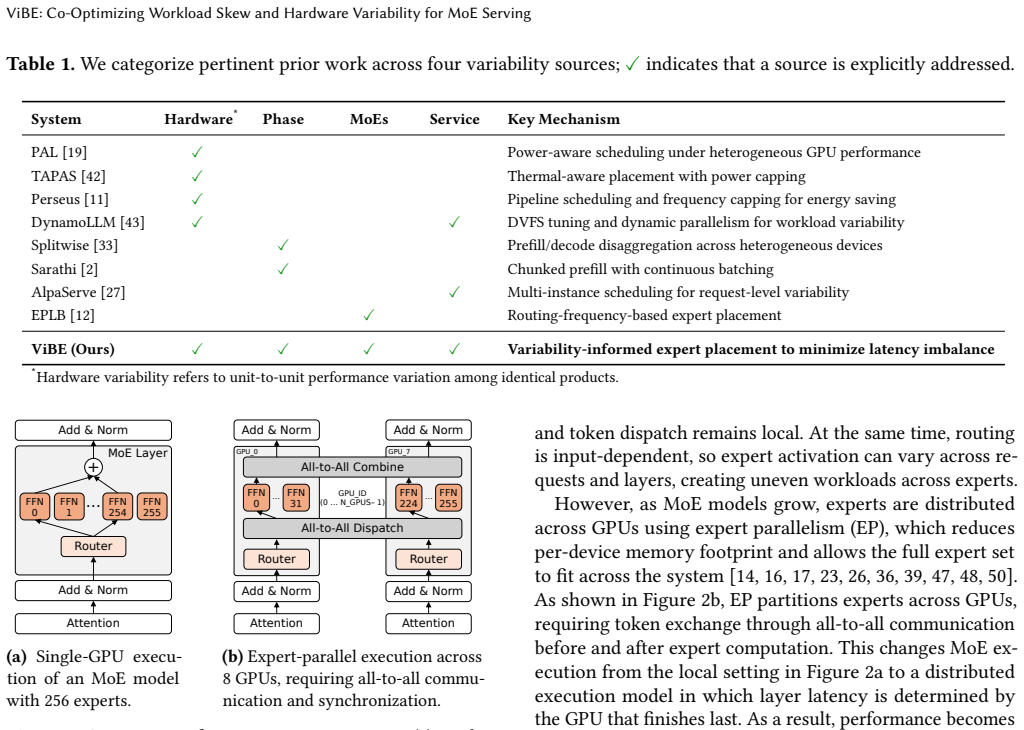
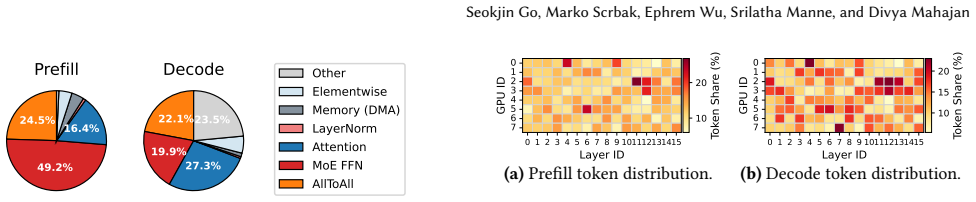
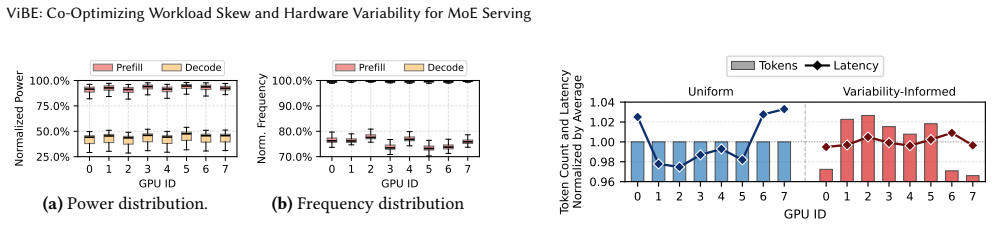
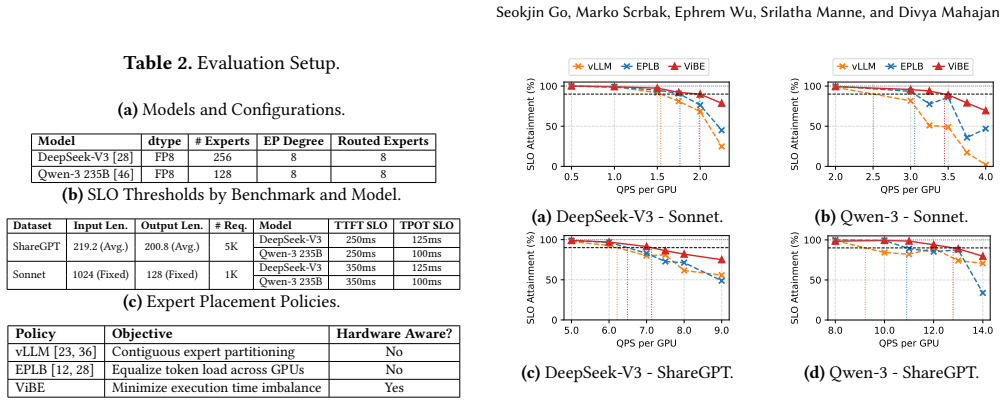
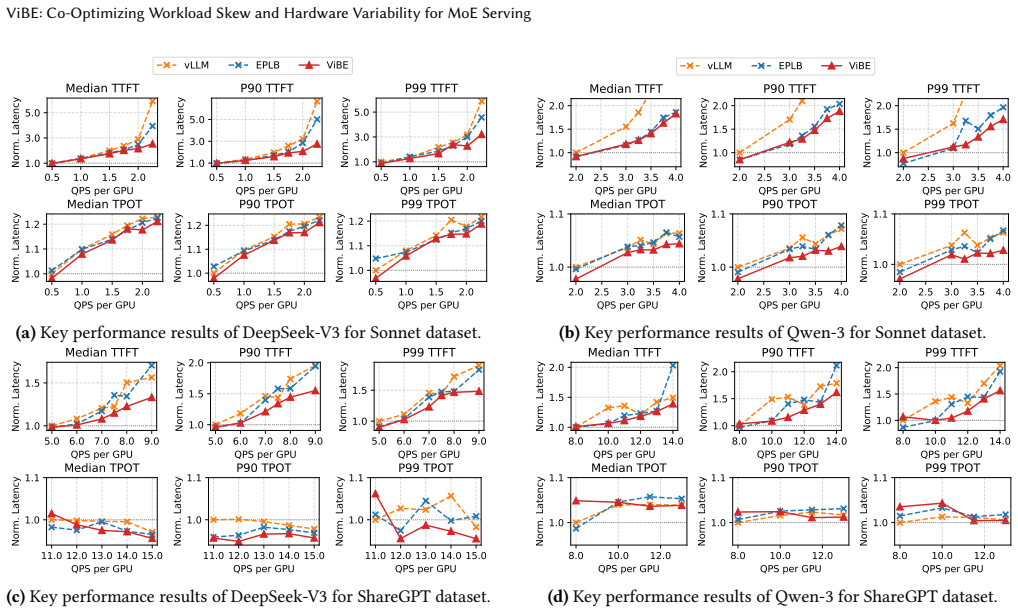
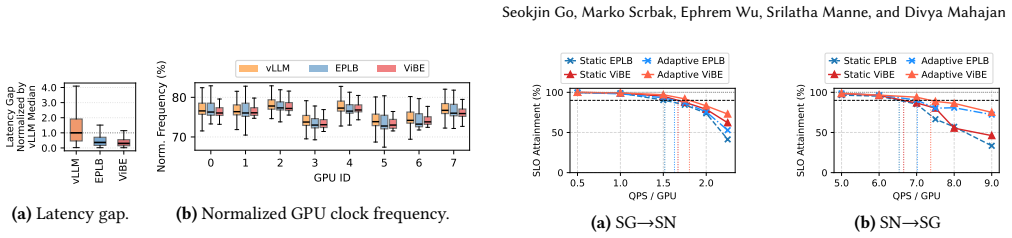
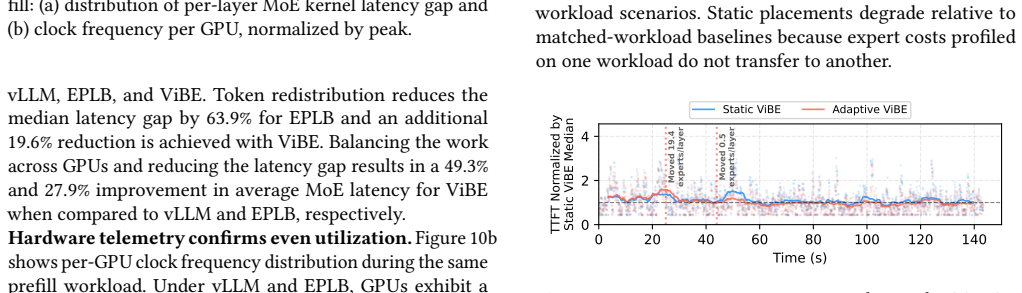
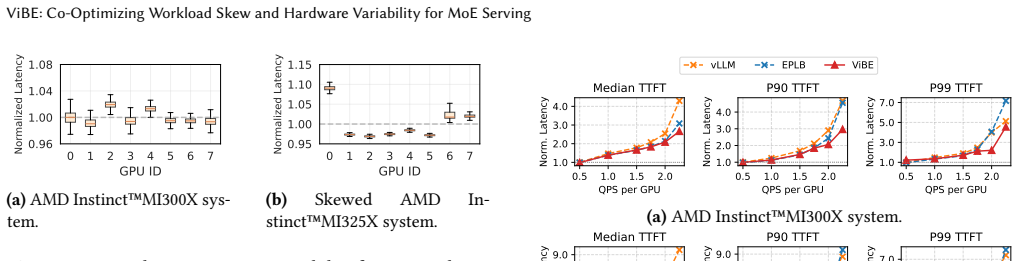
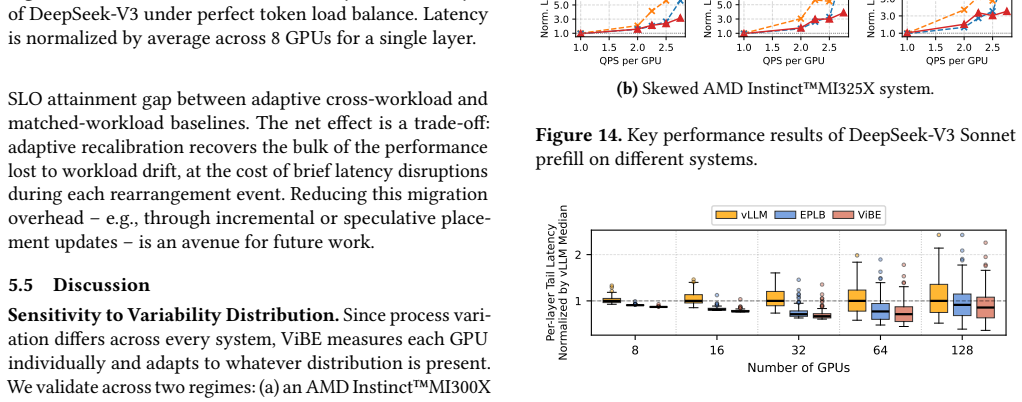
In distributed Mixture-of-Experts (MoE) inference, input-dependent token routing interacts with GPU performance variability to create persistent stragglers under synchronized execution, where the slowest GPU determines layer latency. This performance variability is inherent to modern accelerators: manufacturing variation, power limits, and thermal conditions introduce measurable execution-time differences across nominally identical GPUs. The core challenge is that MoE execution-time imbalance arises from the interaction of workload skew and hardware asymmetry. Token routing produces uneven and layer-varying expert loads, while GPU throughput depends on device-specific operating characteristics and workload intensity. Prior work mitigates routing skew but assumes homogeneous hardware, optimizing token balance rather than execution latency. As a result, even balanced token assignments can leave hardware-induced stragglers unaddressed. Thus, we propose Variability-Informed Binning of Experts (ViBE), a hardware-aware expert placement framework that minimizes execution-time imbalance across GPUs. ViBE combines per-GPU performance modeling with expert activation profiling to assign high-load experts to faster devices and low-load experts to slower ones, reducing layer-level stragglers without modifying model semantics or hardware. Because both workload characteristics and effective GPU throughput can shift across serving conditions, ViBE supports lightweight recalibration under workload/performance drift to refresh its routing and performance estimates when needed. Results show that ViBE consistently reduces execution-time imbalance and improves SLO attainment by 14%, while lowering P90 TTFT by up to 45%. We further show that the impact of hardware variability increases at scale, making variability-aware placement important for efficient, high-utilization LLM serving.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ViBE, a hardware-aware expert placement framework for distributed MoE inference. It models per-GPU performance variability (from manufacturing, power, and thermal effects) alongside token-routing-induced workload skew to assign high-load experts to faster devices and low-load experts to slower ones, thereby reducing layer-level stragglers. The framework includes lightweight recalibration for workload or performance drift. Empirical results are reported as consistent reductions in execution-time imbalance, a 14% improvement in SLO attainment, and up to 45% reduction in P90 TTFT, with the impact of variability noted to increase at scale.
Significance. If the empirical claims hold under realistic serving conditions, the work identifies a practical and previously under-addressed interaction between dynamic expert activation and static hardware asymmetry in large-scale MoE deployments. The approach requires no model changes and targets production constraints, which strengthens its potential utility for high-utilization LLM serving.
major comments (2)
- [Abstract] Abstract: the central claims of 14% SLO attainment improvement and up to 45% P90 TTFT reduction are presented without any description of experimental setup, model sizes, number of GPUs, workload traces, baselines (e.g., token-balance-only placement), or statistical measures such as error bars or number of runs. This prevents assessment of whether the per-GPU performance models remain predictive when experts execute concurrently under real token distributions.
- [Abstract] Abstract: the description of 'lightweight recalibration' to handle drift is stated but supplies no quantitative data on recalibration frequency, overhead, or residual prediction error after drift. If model error exceeds a few percent, the resulting expert-to-device assignments risk creating new stragglers rather than eliminating them, directly undermining the load-bearing assumption that profiled throughput models transfer to serving conditions.
minor comments (1)
- [Abstract] The abstract would be clearer if it briefly indicated the scale (number of GPUs or experts) at which the reported increase in variability impact was observed.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We address the points below and will revise the manuscript to better contextualize the claims while respecting abstract length constraints.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claims of 14% SLO attainment improvement and up to 45% P90 TTFT reduction are presented without any description of experimental setup, model sizes, number of GPUs, workload traces, baselines (e.g., token-balance-only placement), or statistical measures such as error bars or number of runs. This prevents assessment of whether the per-GPU performance models remain predictive when experts execute concurrently under real token distributions.
Authors: The abstract prioritizes brevity. The full manuscript details the experimental setup (model sizes, GPU scale, production-derived workload traces, token-balance-only baselines, and multi-run statistics with error bars) in the Evaluation section, along with validation showing the per-GPU models remain predictive under concurrent execution and realistic token distributions. We will revise the abstract to briefly note the experimental scale and primary baseline. revision: yes
-
Referee: [Abstract] Abstract: the description of 'lightweight recalibration' to handle drift is stated but supplies no quantitative data on recalibration frequency, overhead, or residual prediction error after drift. If model error exceeds a few percent, the resulting expert-to-device assignments risk creating new stragglers rather than eliminating them, directly undermining the load-bearing assumption that profiled throughput models transfer to serving conditions.
Authors: We agree quantitative support for recalibration is needed to substantiate the transfer assumption. The abstract omits these metrics for length reasons, but the manuscript describes the mechanism; we will expand the relevant section with measured frequency, overhead, and residual error to confirm errors stay low enough to avoid new stragglers. Additional experiments will be added if required. revision: yes
Circularity Check
No circularity: empirical results from measured framework outcomes
full rationale
The paper describes a systems framework (ViBE) for expert placement based on per-GPU profiling and workload characterization, with claimed gains (14% SLO improvement, 45% P90 TTFT reduction) presented explicitly as experimental measurements rather than derived predictions. No equations, first-principles derivations, fitted parameters renamed as outputs, or self-citation chains appear in the abstract or described content. The central claims rest on runtime observations under the proposed placement, which are independent of any internal reduction to inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- per-GPU performance model parameters
axioms (1)
- domain assumption GPU throughput differences due to manufacturing, power, and thermal variation are measurable and can be profiled without altering model semantics.
Reference graph
Works this paper leans on
-
[1]
Sandhini Agarwal, Lama Ahmad, Jason Ai, Sam Altman, Andy Apple- baum, Edwin Arbus, Rahul K Arora, Yu Bai, Bowen Baker, Haiming Bao, et al. 2025. gpt-oss-120b & gpt-oss-20b model card.arXiv preprint arXiv:2508.10925(2025)
Pith/arXiv arXiv 2025
-
[2]
Gulavani, Alexey Tumanov, and Ramachandran Ramjee
Amey Agrawal, Nitin Kedia, Ashish Panwar, Jayashree Mohan, Nipun Kwatra, Bhargav S. Gulavani, Alexey Tumanov, and Ramachandran Ramjee. 2024. Taming Throughput-Latency Tradeoff in LLM Inference with Sarathi-Serve. arXiv:2403.02310 [cs.LG]https://arxiv.org/abs/ 2403.02310
arXiv 2024
-
[3]
AMD. 2023. AMD Instinct™MI300X Accelerators.https://www.amd. com/en/products/accelerators/instinct/mi300/mi300x.html
2023
-
[4]
AMD. 2024. AMD Instinct™MI325X Accelerators.https://www.amd. com/en/products/accelerators/instinct/mi300/mi325x.html
2024
-
[5]
AMD. 2025. AITER: AI Tensor Engine For ROCm.https: //rocm.blogs.amd.com/software-tools-optimization/aiter-ai-tensor- engine/README.html
2025
-
[6]
AMD. 2025. AMD “Helios”: Advancing Openness in AI In- frastructure Built on Meta’s 2025 OCP Open Rack for AI De- sign.https://www.amd.com/en/blogs/2025/amd-helios-ai-rack-built- on-metas-2025-ocp-design.html
2025
-
[7]
AMD. 2026. AMD University Program AI & HPC Cluster.https://www. amd.com/en/corporate/university-program/ai-hpc-cluster.html
2026
-
[8]
AMD. 2026. ROCm Software.https://www.amd.com/en/products/ software/rocm
2026
-
[9]
AMD. 2026. ROCm System Management Interface (ROCm SMI) library. https://rocm.docs.amd.com/projects/rocm_smi_lib/en/latest/
2026
-
[10]
AMD. 2026. ROCprofiler-SDK documentation.https://rocm.docs.amd. com/projects/rocprofiler-sdk/en/latest/index.html
2026
-
[11]
Jae-Won Chung, Yile Gu, Insu Jang, Luoxi Meng, Nikhil Bansal, and Mosharaf Chowdhury. 2024. Reducing energy bloat in large model training. InProceedings of the ACM SIGOPS 30th Symposium on Oper- ating Systems Principles. 144–159
2024
-
[12]
DeepSeek. 2025. EPLB: Expert Paralllelism Load Balancer.https: //github.com/deepseek-ai/EPLB
2025
-
[13]
William Fedus, Barret Zoph, and Noam Shazeer. 2022. Switch trans- formers: scaling to trillion parameter models with simple and efficient sparsity.J. Mach. Learn. Res.23, 1, Article 120 (Jan. 2022), 39 pages
2022
-
[14]
Seokjin Go and Divya Mahajan. 2025. Moetuner: Optimized mixture of expert serving with balanced expert placement and token routing. arXiv preprint arXiv:2502.06643(2025)
arXiv 2025
-
[15]
Seokjin Go, Joongun Park, Spandan More, Hanjiang Wu, Irene Wang, Aaron Jezghani, Tushar Krishna, and Divya Mahajan. 2025. Charac- terizing the Efficiency of Distributed Training: A Power, Performance, and Thermal Perspective. InProceedings of the 58th IEEE/ACM Inter- national Symposium on Microarchitecture. 626–642
2025
-
[16]
Jiaao He, Jiezhong Qiu, Aohan Zeng, Zhilin Yang, Jidong Zhai, and Jie Tang. 2021. Fastmoe: A fast mixture-of-expert training system.arXiv preprint arXiv:2103.13262(2021)
arXiv 2021
-
[17]
Jiaao He, Jidong Zhai, Tiago Antunes, Haojie Wang, Fuwen Luo, Shangfeng Shi, and Qin Li. 2022. Fastermoe: modeling and optimizing training of large-scale dynamic pre-trained models. InProceedings of the 27th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming. 120–134
2022
-
[18]
Yanping Huang, Youlong Cheng, Ankur Bapna, Orhan Firat, Dehao Chen, Mia Chen, HyoukJoong Lee, Jiquan Ngiam, Quoc V Le, Yonghui Wu, et al. 2019. Gpipe: Efficient training of giant neural networks using pipeline parallelism.Advances in neural information processing systems32 (2019)
2019
-
[19]
Rutwik Jain, Brandon Tran, Keting Chen, Matthew D Sinclair, and Shiv- aram Venkataraman. 2024. PAL: A variability-aware policy for sched- uling ML workloads in GPU clusters. InSC24: International Conference for High Performance Computing, Networking, Storage and Analysis. IEEE, 1–18
2024
-
[20]
Albert Q. Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Men- sch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, Gianna Lengyel, Guillaume Bour, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Sandeep Subramanian, Sophia Yang, Szymon Antoniak, Tev...
Pith/arXiv arXiv 2024
-
[21]
Andreas Kosmas Kakolyris, Dimosthenis Masouros, Petros Vavarout- sos, Sotirios Xydis, and Dimitrios Soudris. 2025. throttll’em: Predictive gpu throttling for energy efficient llm inference serving. In2025 IEEE International Symposium on High Performance Computer Architecture (HPCA). IEEE, 1363–1378
2025
-
[22]
Marco Kurzynski, Shaizeen Aga, and Di Wu. 2025. Lit Silicon: A Case Where Thermal Imbalance Couples Concurrent Execution in Multiple GPUs. arXiv:2511.09861 [cs.DC]https://arxiv.org/abs/2511.09861
Pith/arXiv arXiv 2025
-
[23]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica
-
[24]
InProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles
Efficient Memory Management for Large Language Model Serving with PagedAttention. InProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles
-
[25]
Jan Karel Lenstra, David B Shmoys, and Éva Tardos. 1990. Approxi- mation algorithms for scheduling unrelated parallel machines.Math- ematical programming46, 1 (1990), 259–271
1990
-
[26]
Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, Dehao Chen, Orhan Firat, Yanping Huang, Maxim Krikun, Noam Shazeer, and Zhifeng Chen. 2020. Gshard: Scaling giant models with conditional computation and automatic sharding.arXiv preprint arXiv:2006.16668 (2020)
Pith/arXiv arXiv 2020
-
[27]
Jiamin Li, Yimin Jiang, Yibo Zhu, Cong Wang, and Hong Xu. 2023. Accelerating distributed {MoE} training and inference with lina. In 2023 USENIX Annual Technical Conference (USENIX ATC 23). 945–959
2023
-
[28]
Zhuohan Li, Lianmin Zheng, Yinmin Zhong, Vincent Liu, Ying Sheng, Xin Jin, Yanping Huang, Zhifeng Chen, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. 2023. AlpaServe: Statistical Multiplexing with Model Parallelism for Deep Learning Serving. arXiv:2302.11665 [cs.LG] https://arxiv.org/abs/2302.11665
arXiv 2023
-
[29]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al . 2024. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437(2024)
Pith/arXiv arXiv 2024
-
[30]
Meta, Inc. 2025. The Llama 4 herd: The beginning of a new era of natively multimodal AI innovation.https://ai.meta.com/blog/llama- 4-multimodal-intelligence/. 12 ViBE: Co-Optimizing Workload Skew and Hardware Variability for MoE Serving
2025
-
[31]
Deepak Narayanan, Aaron Harlap, Amar Phanishayee, Vivek Seshadri, Nikhil R Devanur, Gregory R Ganger, Phillip B Gibbons, and Matei Zaharia. 2019. PipeDream: Generalized pipeline parallelism for DNN training. InProceedings of the 27th ACM symposium on operating sys- tems principles. 1–15
2019
-
[32]
NVIDIA. 2025. NVIDIA GB200 NVL72.https://www.nvidia.com/en- us/data-center/gb200-nvl72/
2025
-
[33]
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. 2019. Pytorch: An imperative style, high-performance deep learning library.Advances in neural informa- tion processing systems32 (2019)
2019
-
[34]
Pratyush Patel, Esha Choukse, Chaojie Zhang, Aashaka Shah, Íñigo Goiri, Saeed Maleki, and Ricardo Bianchini. 2024. Split- wise: Efficient generative LLM inference using phase splitting. arXiv:2311.18677 [cs.AR]https://arxiv.org/abs/2311.18677
arXiv 2024
-
[35]
PyTorch. 2023. PyTorch Profiler.https://pytorch.org/tutorials/recipes/ recipes/profiler_recipe.html
2023
-
[36]
Tawfik Rahal-Arabi, Paul Van der Arend, Ashish Jain, Mehdi Saidi, Rashad Oreifej, Sriram Sundaram, Srilatha Manne, Indrani Paul, Rajit Seahra, Frank Helms, Esha Choukse, Nithish Mahalingam, Brijesh Warrier, and Ricardo Bianchini. 2024. Optimizing GPU Data Center Power. In2024 IEEE Asia Pacific Conference on Circuits and Systems (APCCAS). IEEE, 358–362. do...
-
[37]
Samyam Rajbhandari, Conglong Li, Zhewei Yao, Minjia Zhang, Reza Yazdani Aminabadi, Ammar Ahmad Awan, Jeff Rasley, and Yux- iong He. 2022. Deepspeed-moe: Advancing mixture-of-experts infer- ence and training to power next-generation ai scale. InInternational conference on machine learning. PMLR, 18332–18346
2022
-
[38]
Chaoyi Ruan, Yinhe Chen, Dongqi Tian, Yandong Shi, Yongji Wu, Jialin Li, and Cheng Li. 2025. DynaServe: Unified and Elastic Execution for Dynamic Disaggregated LLM Serving. arXiv:2504.09285 [cs.DC] https://arxiv.org/abs/2504.09285
arXiv 2025
-
[39]
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. 2017. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer.arXiv preprint arXiv:1701.06538(2017)
Pith/arXiv arXiv 2017
-
[40]
Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. 2019. Megatron-lm: Training multi-billion parameter language models using model parallelism. arXiv preprint arXiv:1909.08053(2019)
Pith/arXiv arXiv 2019
-
[41]
Prasoon Sinha, Akhil Guliani, Rutwik Jain, Brandon Tran, Matthew D Sinclair, and Shivaram Venkataraman. 2022. Not all GPUs are cre- ated equal: characterizing variability in large-scale, accelerator-rich systems. InSC22: International Conference for High Performance Com- puting, Networking, Storage and Analysis. IEEE, 01–15
2022
-
[42]
Platon Slynko, Jay Lu, Jason Cornick, Laksh Sharma, Shou-Kai Cheng, Benjamin Cornick, Arthur O Dias dos Santos, Caique Sobral, Carmen Li, Daoxuan Xu, et al. [n. d.]. Did You Win the GPU Cloud Lottery? Benchmarking from TFLOPS to Tokens. ([n. d.])
-
[43]
Jovan Stojkovic, Chaojie Zhang, Íñigo Goiri, Esha Choukse, Haoran Qiu, Rodrigo Fonseca, Josep Torrellas, and Ricardo Bianchini. 2025. Tapas: Thermal-and power-aware scheduling for LLM inference in cloud platforms. InProceedings of the 30th ACM International Confer- ence on Architectural Support for Programming Languages and Operat- ing Systems, Volume 2. ...
2025
-
[44]
Jovan Stojkovic, Chaojie Zhang, Íñigo Goiri, Josep Torrellas, and Esha Choukse. 2025. Dynamollm: Designing llm inference clusters for per- formance and energy efficiency. In2025 IEEE International Symposium on High Performance Computer Architecture (HPCA). IEEE, 1348–1362
2025
-
[45]
Irene Wang, Jakub Tarnawski, Amar Phanishayee, and Divya Mahajan. 2024. Integrated Hardware Architecture and Device Placement Search. In2024 International Conference on Machine Learning.https://www.microsoft.com/en-us/research/publication/ integrated-hardware-architecture-and-device-placement-search/
2024
-
[46]
Irene Wang, Vishnu Varma Venkata, Arvind Krishnamurthy, and Di- vya Mahajan. 2026. NEST: Network- and Memory-Aware Device Placement For Distributed Deep Learning. arXiv:2603.06798 [cs.LG] https://arxiv.org/abs/2603.06798
Pith/arXiv arXiv 2026
-
[47]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 technical report.arXiv preprint arXiv:2505.09388(2025)
Pith/arXiv arXiv 2025
-
[48]
Jinghan Yao, Quentin Anthony, Aamir Shafi, Hari Subramoni, and Dhabaleswar K DK Panda. 2024. Exploiting inter-layer expert affinity for accelerating mixture-of-experts model inference. In2024 IEEE International Parallel and Distributed Processing Symposium (IPDPS). IEEE, 915–925
2024
-
[49]
Shulai Zhang, Ningxin Zheng, Haibin Lin, Ziheng Jiang, Wen- lei Bao, Chengquan Jiang, Qi Hou, Weihao Cui, Size Zheng, Li- Wen Chang, Quan Chen, and Xin Liu. 2025. Comet: Fine-grained Computation-communication Overlapping for Mixture-of-Experts. arXiv:2502.19811 [cs.DC]https://arxiv.org/abs/2502.19811
arXiv 2025
-
[50]
Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xu- anzhe Liu, Xin Jin, and Hao Zhang. 2024. DistServe: Disaggregating Prefill and Decoding for Goodput-optimized Large Language Model Serving. arXiv:2401.09670 [cs.DC]https://arxiv.org/abs/2401.09670
arXiv 2024
-
[51]
Ruidong Zhu, Ziheng Jiang, Chao Jin, Peng Wu, Cesar A. Stuardo, Dongyang Wang, Xinlei Zhang, Huaping Zhou, Haoran Wei, Yang Cheng, Jianzhe Xiao, Xinyi Zhang, Lingjun Liu, Haibin Lin, Li-Wen Chang, Jianxi Ye, Xiao Yu, Xuanzhe Liu, Xin Jin, and Xin Liu. 2025. MegaScale-Infer: Serving Mixture-of-Experts at Scale with Disaggre- gated Expert Parallelism. arXiv...
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.