VCIFBench: Evaluating Complex Instruction Following for Video Understanding
Pith reviewed 2026-06-28 06:05 UTC · model grok-4.3
The pith
VCIFBench shows that multimodal video models rarely satisfy all constraints in a single instruction at once.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
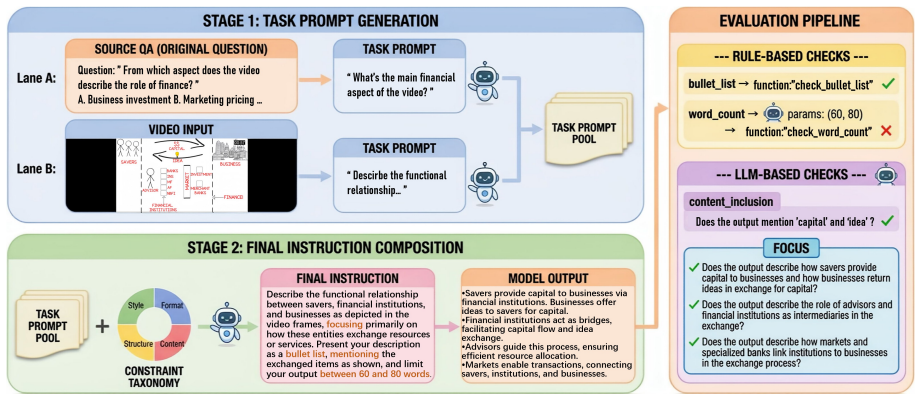
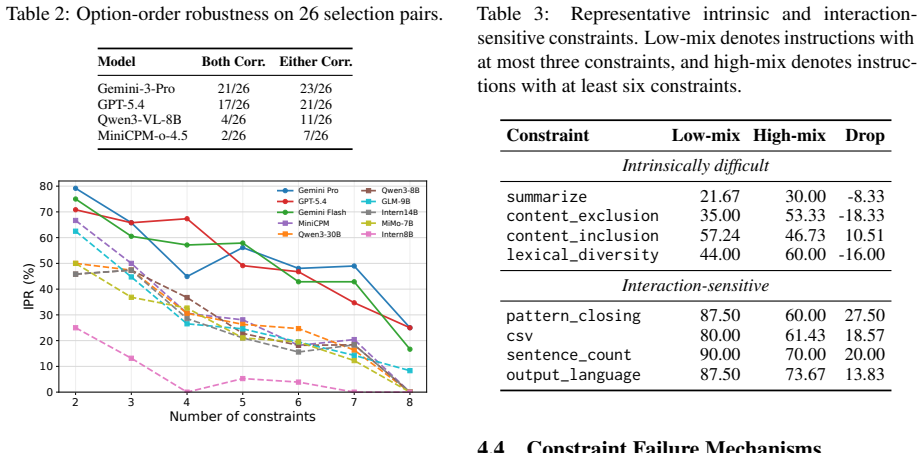
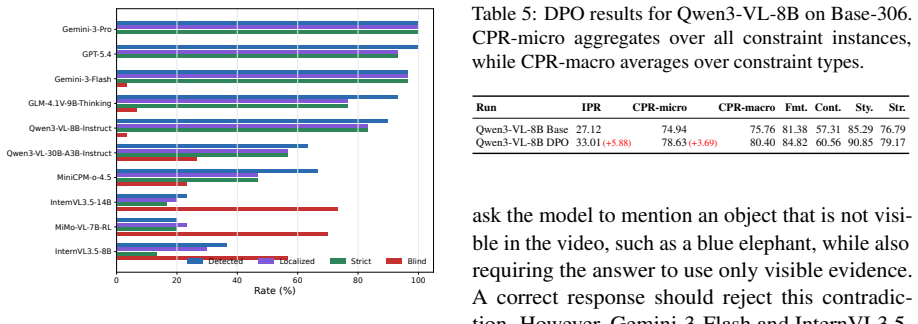
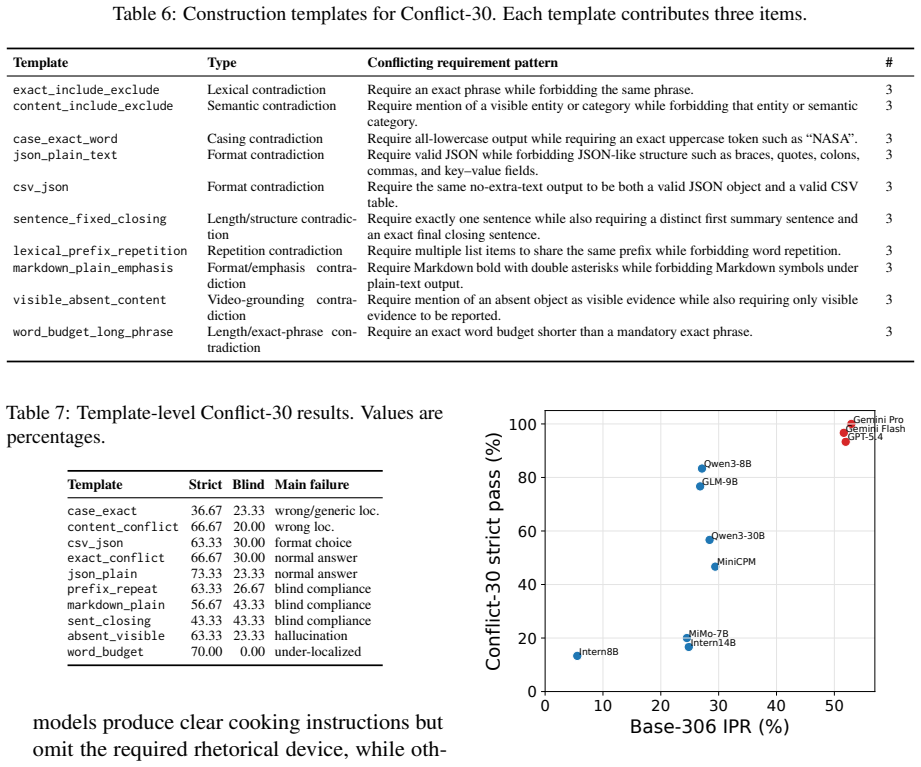
VCIFBench supplies 306 test instructions, each containing multiple explicit constraints drawn from both existing benchmarks and new video-grounded prompts. A hybrid verification pipeline scores whether model responses meet every constraint. Tests on ten multimodal models indicate low rates of full constraint satisfaction. Fine-tuning with direct preference optimization on the accompanying 540-pair dataset measurably improves performance on the same instructions.
What carries the argument
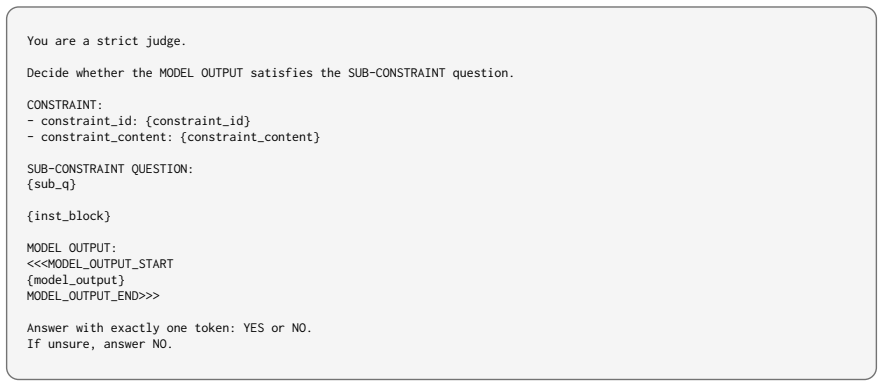
The hybrid verification pipeline that combines rule-based checks and model-based judgment to determine whether outputs satisfy all specified constraints in an instruction.
If this is right
- Models that pass simple prompts can still fail when multiple constraints must be met simultaneously.
- Training with DPO on VCIFBench data raises the fraction of fully compliant outputs.
- The benchmark distinguishes between content, format, style, and structure constraints.
- A conflict diagnostic subset helps identify when constraints cannot be jointly satisfied.
Where Pith is reading between the lines
- Better verification methods could be developed by comparing the hybrid pipeline against human judgments on the same outputs.
- The approach could be extended to other modalities such as image or audio understanding.
- Scaling the benchmark size might reveal whether performance gaps persist across larger model families.
Load-bearing premise
The hybrid verification pipeline accurately determines whether model outputs satisfy all the specified constraints in the instructions.
What would settle it
A direct comparison in which human annotators judge the same model outputs and find substantially different satisfaction rates than the pipeline would falsify the benchmark's reliability.
Figures




read the original abstract
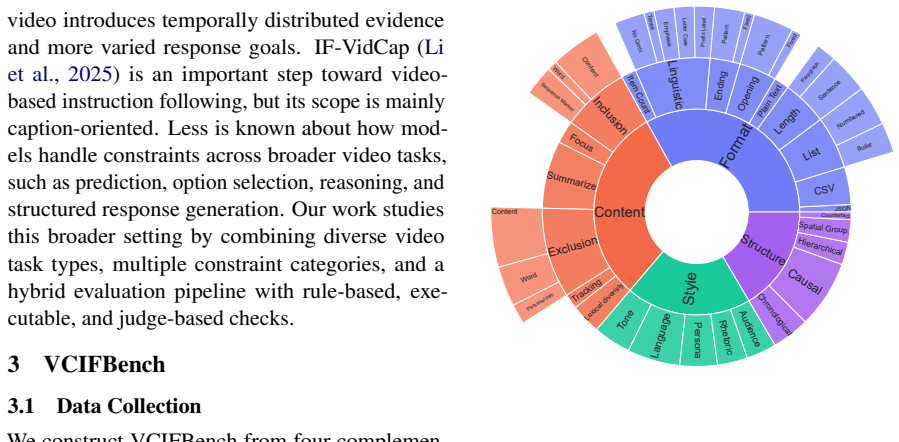
Multimodal large language models have made rapid progress in video understanding, yet existing benchmarks largely rely on simple prompts and provide limited evidence about whether models can satisfy explicit output constraints. We introduce VCIFBench, a benchmark for evaluating complex instruction following in video understanding. VCIFBench constructs constraint-rich instructions from both benchmark-adapted and directly video-grounded prompts, covering content, format, style, and structure requirements, and evaluates model outputs with a hybrid verification pipeline. The benchmark contains 306 satisfiable test instructions, a 540-pair DPO preference dataset, and a 30-item conflict diagnostic subset. Experiments on 10 MLLMs show that joint constraint satisfaction remains challenging. We further show that DPO training on VCIFBench data can improve instruction-following performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces VCIFBench, a benchmark with 306 satisfiable test instructions for complex instruction following in video understanding. Instructions incorporate content, format, style, and structure constraints derived from benchmark-adapted and video-grounded prompts. Model outputs are assessed via a hybrid verification pipeline. Experiments across 10 MLLMs demonstrate that joint constraint satisfaction is challenging, and DPO training on an accompanying 540-pair preference dataset improves performance; a 30-item conflict diagnostic subset is also provided.
Significance. If the hybrid verification pipeline proves reliable, VCIFBench would address a clear gap in video-understanding benchmarks by focusing on multi-constraint instruction following rather than simple prompts. The provision of both an evaluation set and DPO preference data, plus a conflict diagnostic, would make the resource directly usable for both assessment and training of MLLMs.
major comments (2)
- [Verification pipeline description] Verification pipeline (construction and evaluation sections): The headline claims—that joint constraint satisfaction remains challenging for 10 MLLMs and that DPO on VCIFBench data improves it—rest entirely on the hybrid verifier correctly labeling satisfaction of every constraint. No inter-annotator agreement, no error-rate breakdown by constraint type, and no ablation of the LLM-judge component are reported, so the quantitative difficulty rankings and DPO gains cannot be interpreted.
- [Data construction] § on data construction: The abstract states that the 306 test items are satisfiable and that a 540-pair DPO dataset was built, yet supplies no details on the verification pipeline, quantitative metrics used to confirm satisfiability, model selection criteria, or the exact process for generating preference pairs. These omissions are load-bearing for reproducibility and for assessing whether the reported improvements are attributable to the benchmark.
minor comments (2)
- [Abstract] Abstract: The 10 MLLMs are not named and no per-model or aggregate metrics (e.g., exact satisfaction rates before/after DPO) are provided, making the experimental claims harder to assess at a glance.
- [Benchmark description] The 30-item conflict diagnostic subset is mentioned but its construction criteria and how it differs from the main 306-item set are not elaborated in the provided summary.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below and will revise the manuscript to improve transparency and reproducibility.
read point-by-point responses
-
Referee: [Verification pipeline description] Verification pipeline (construction and evaluation sections): The headline claims—that joint constraint satisfaction remains challenging for 10 MLLMs and that DPO on VCIFBench data improves it—rest entirely on the hybrid verifier correctly labeling satisfaction of every constraint. No inter-annotator agreement, no error-rate breakdown by constraint type, and no ablation of the LLM-judge component are reported, so the quantitative difficulty rankings and DPO gains cannot be interpreted.
Authors: We agree that the absence of inter-annotator agreement statistics, per-constraint error rates, and an ablation of the LLM-judge component limits the strength of the claims. In the revised manuscript we will add a dedicated reliability analysis subsection that reports (i) agreement between the hybrid verifier and two human annotators on a random sample of 100 model outputs, (ii) error rates broken down by constraint category (content, format, style, structure), and (iii) an ablation comparing end-to-end accuracy when the LLM-judge component is removed. These additions will allow readers to assess the verifier’s reliability directly. revision: yes
-
Referee: [Data construction] § on data construction: The abstract states that the 306 test items are satisfiable and that a 540-pair DPO dataset was built, yet supplies no details on the verification pipeline, quantitative metrics used to confirm satisfiability, model selection criteria, or the exact process for generating preference pairs. These omissions are load-bearing for reproducibility and for assessing whether the reported improvements are attributable to the benchmark.
Authors: We acknowledge that the current data-construction section is insufficiently detailed for full reproducibility. The revised version will expand this section to specify: (1) the exact quantitative thresholds and verification steps used to certify that all 306 test instructions are satisfiable, (2) the model-selection criteria and prompting templates employed during verification, and (3) the precise procedure for constructing the 540 preference pairs, including how chosen and rejected responses were generated and filtered. These additions will make the benchmark construction transparent and allow independent assessment of the DPO gains. revision: yes
Circularity Check
No circularity; benchmark construction and evaluation are independent of fitted results
full rationale
The paper introduces VCIFBench as an external evaluation set with 306 test instructions and a separate 540-pair DPO dataset. Model performance is measured by applying the described hybrid verification pipeline to outputs from 10 MLLMs; the DPO improvement is shown by retraining on the preference pairs and re-evaluating on the same held-out test set. Neither step reduces a claimed prediction to a fitted parameter by construction, nor does any load-bearing claim rest on a self-citation chain or an ansatz imported from prior work by the same authors. The verification pipeline is presented as a methodological component rather than a derived result, and the reported outcomes are direct measurements against that pipeline. This is the standard non-circular structure for a new benchmark paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A survey on evaluation of large language mod- els.ACM Trans. Intell. Syst. Technol., 15(3). Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Mar- cel Blistein, Ori Ram, Dan Zhang, Evan Rosen, Luke Marris, Sam Petulla, Colin Gaffney, Asaf Aharoni, Nathan Lintz, Tiago Cardal Pais, Henrik Jacobs- son, Idan Sz...
Pith/arXiv arXiv 2025
-
[2]
If-vidcap: Can video caption models follow instructions?Preprint, arXiv:2510.18726. Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paran- jape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2024a. Lost in the middle: How language models use long contexts.Transactions of the Asso- ciation for Computational Linguistics, 12:157–173. Yuan Liu, Haodong Du...
arXiv 2024
-
[3]
In2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 13691–13701
Mlvu: Benchmarking multi-task long video understanding. In2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 13691–13701. Luowei Zhou, Chenliang Xu, and Jason J. Corso. 2017. Towards automatic learning of procedures from web instructional videos.Preprint, arXiv:1703.09788. Wangchunshu Zhou, Yuchen Eleanor Jiang, Ethan Wilcox...
Pith/arXiv arXiv 2017
-
[4]
as a news report
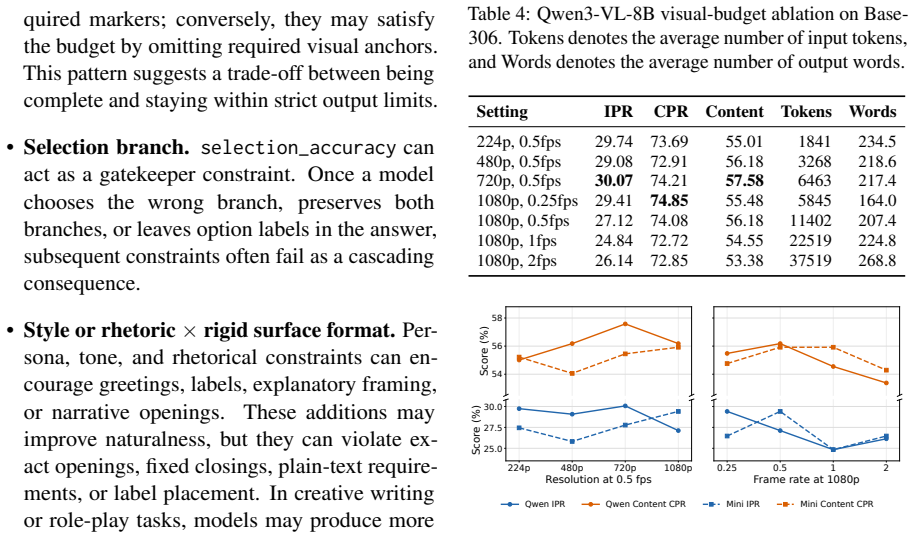
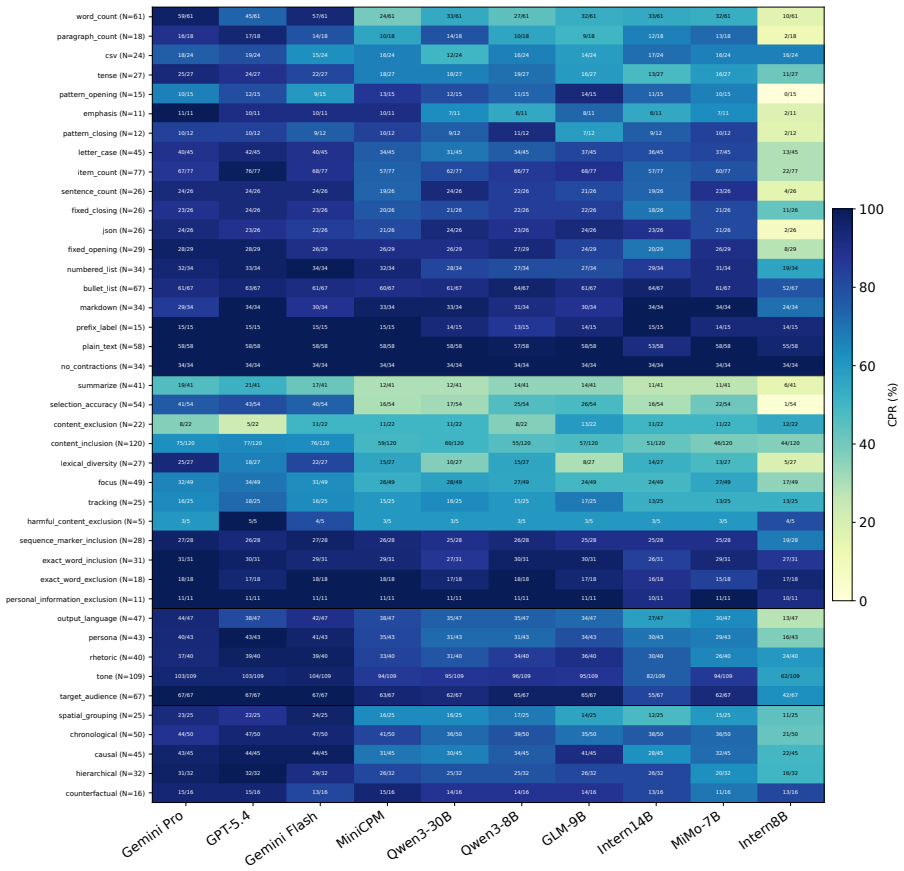
Most items contain four to seven constraints, which makes instruction-level success substantially stricter than satisfying any single constraint in iso- lation. Figure 7 reports the full constraint-type heatmap. Rows are constraint types, grouped by dimension 11 and sorted by average CPR within each group. Cell text gives the number of passed model at- te...
2025
-
[5]
Determine which parameters (excluding model_output) are needed to evaluate this constraint
-
[6]
Produce parameter values ONLY, separated by the exact delimiter: |||
-
[7]
The first argument is ALWAYS model_output and is implicit; you MUST NOT output it
-
[8]
Prefer key=value format for safety, especially for optional parameters
-
[9]
For List values, output JSON arrays; for numbers output plain numbers
-
[10]
Now output the parameters line: Figure 10: Prompt used forhybrid verification
Output must be a SINGLE LINE with no extra text. Now output the parameters line: Figure 10: Prompt used forhybrid verification. Given a natural-language constraint, a local checking function, and its parameter documentation, the model extracts the required function arguments so that the final checker can be executed programmatically. You are a strict mult...
-
[11]
No markdown, no extra text
Output MUST be a single valid JSON object ONLY. No markdown, no extra text
-
[12]
You MUST include EVERY constraint_id key listed below
-
[13]
NOT true/false
Each value MUST be exactly 0 or 1 (integer). NOT true/false
-
[14]
If unsure, output 0 for that constraint_id
-
[15]
Additional constraints:
Keys must match the given constraint_id strings exactly. CONSTRAINT_ID LIST (MUST respond to ALL of them): {json.dumps(cids, ensure_ascii=False)} ORIGINAL INSTRUCTION: <<<INSTRUCTION_START {instruction} INSTRUCTION_END>>> CANDIDATE ANSWER (MODEL OUTPUT): <<<MODEL_OUTPUT_START {model_output} MODEL_OUTPUT_END>>> CONSTRAINTS (id + content): {json.dumps(const...
-
[16]
Additional constraints:
Extract constraints from any constraint-list section (e.g., "Additional constraints:"), regardless of bullet style. Treat each bullet line as one constraint candidate, even if it contains ":" or ";" internally
-
[17]
normalized_instruction
Rewrite everything into ONE natural instruction string called "normalized_instruction": - remove headings such as "Additional constraints:" - remove bullet markers or numbering - merge all requirements into one coherent instruction
-
[18]
Selection
If composition_type is "Selection", rewrite normalized_instruction in fluent ENGLISH using this structure: - first, write 1--2 sentences introducing the task, condition, and options - then, write one paragraph in the following form: "If Option A: <task requirement + Option A constraints>. If Option B: <task requirement + Option B constraints>."
-
[19]
constraint_id
Align and clean up constraint IDs: - map each extracted constraint to one or more IDs from CONSTRAINT_ID_DEFINITION - if multiple IDs apply, output "constraint_id" as a list - correct misspelled IDs in constraint_dimensions by mapping them to the closest valid key - add missing IDs only when they are directly supported by the extracted constraint text - d...
-
[20]
revisions
Perform a final consistency check: - detect conflicts or non-executable constraints - revise them minimally to make them executable and non-conflicting - record each change in "revisions" with a short reason Output STRICT JSON ONLY: { "normalized_instruction": "<ONE merged natural instruction>", "composition_type": "And" | "Chain" | "Selection", "constrai...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.