Towards Root Memories: Benchmarking and Enhancing Implicit Logical Memory Retrieval for Personalized LLMs
Pith reviewed 2026-06-26 08:22 UTC · model grok-4.3
The pith
Root memory distills personalized decision logic from histories to retrieve implicit connections that semantic similarity misses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
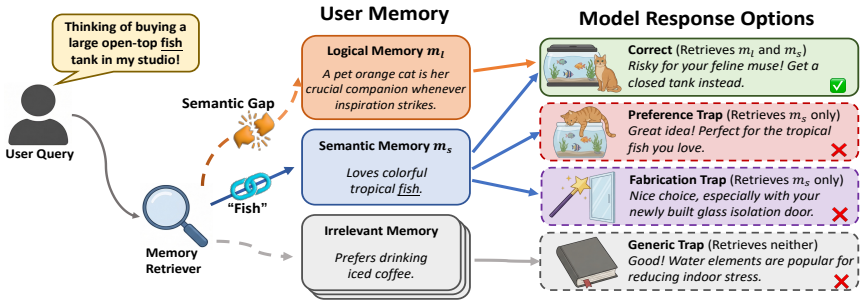
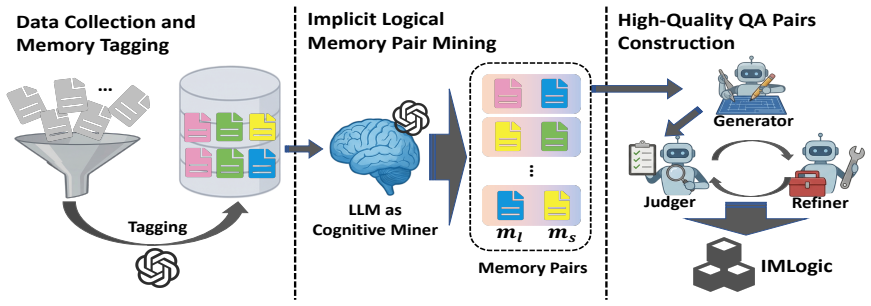
The paper claims that raw user histories can be distilled into root memories, defined as structured decision-preserving representations of personalized logic, and that RootMem activates the logically relevant subset through an LLM-based router, thereby retrieving memories that semantic similarity alone would miss and producing higher accuracy than baseline retrieval methods on the IMLogic benchmark while also improving existing memory agents.
What carries the argument
Root memory, a structured representation that distills reusable personalized logic from long-term user histories while preserving the original decision logic.
If this is right
- RootMem can be added to existing memory systems as a plug-in to increase their accuracy on personalized tasks.
- Logical retrieval becomes measurable and improvable through benchmarks like IMLogic in long-dialogue settings.
- Semantic retrieval is complemented rather than replaced, allowing hybrid systems to handle both surface and logical matches.
- Memory agents gain consistent boosts in accuracy when root memories supply missing decision logic.
Where Pith is reading between the lines
- If the distillation step succeeds at scale, long-term user modeling could shift from storing full histories to maintaining compact structured logic.
- The router mechanism might generalize to other settings where implicit rules must be extracted from sequential interaction data.
- Connections could appear between this structured logic form and graph-based representations of user preferences.
- Efficiency gains in storage and retrieval speed become testable once the distillation process is fixed.
Load-bearing premise
Distilling raw long-term user histories into structured root memories preserves the underlying decision logic without distortion or loss that would harm downstream retrieval.
What would settle it
A controlled test in which agents using root memories achieve lower accuracy on logical inference tasks drawn from user histories than agents with direct access to the raw dialogue data would falsify the central claim.
Figures
read the original abstract
Memory systems are essential for personalized Large Language Models (LLMs). However, existing retrieval methods in these systems primarily rely on semantic similarity, potentially missing logically critical memories with limited semantic overlap. Current benchmarks remain inadequate for evaluating this problem. To address this gap, we construct IMLogic, the first high-quality benchmark targeting implicit logical memory retrieval in long-dialogue scenarios. Motivated by this challenge, we introduce root memory, a structured, decision-preserving representation that distills reusable personalized logic from long-term user histories. We then propose RootMem, a plug-and-play framework that first distills raw histories into structured root memories and then uses an LLM-based router to activate logically relevant ones, complementing semantic retrieval with personalized decision logic. Extensive experiments demonstrate that RootMem significantly outperforms the strongest retrieval baselines and consistently boosts the accuracy of existing memory agents. Our benchmark and codes will be available at https://anonymous.4open.science/r/IMLogic-DBB3.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript constructs IMLogic, the first high-quality benchmark for implicit logical memory retrieval in long-dialogue scenarios. It introduces root memory as a structured, decision-preserving representation that distills reusable personalized logic from long-term user histories. RootMem is proposed as a plug-and-play framework that first distills raw histories into root memories and then employs an LLM-based router to activate logically relevant ones, complementing semantic retrieval. The paper claims that extensive experiments demonstrate RootMem significantly outperforms the strongest retrieval baselines and consistently boosts the accuracy of existing memory agents, with the benchmark and codes to be released.
Significance. If the experimental claims hold, the work addresses a meaningful gap in memory systems for personalized LLMs by moving beyond pure semantic similarity to incorporate logical connections. The new benchmark could become a useful evaluation resource for the community, and the commitment to release the benchmark and codes is a clear strength for reproducibility and follow-on research.
major comments (1)
- [Root memory and distillation procedure] The central claim that RootMem improves retrieval rests on the assumption that distilling raw long-term user histories into structured root memories preserves decision logic without introducing distortion or loss affecting downstream accuracy. The manuscript provides no formal definition, human validation, or controlled comparison (e.g., decision equivalence before/after distillation) to substantiate this preservation property.
minor comments (2)
- [Abstract] The abstract states that 'extensive experiments' were conducted but supplies no quantitative metrics, baseline names, or error analysis; the full results section should be cross-referenced in the abstract for clarity.
- [Abstract] The anonymous release link is provided, but the manuscript should specify exactly which artifacts (full IMLogic dataset, router code, evaluation scripts, seed values) will be included to support reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential value of IMLogic and RootMem. We address the single major comment below.
read point-by-point responses
-
Referee: [Root memory and distillation procedure] The central claim that RootMem improves retrieval rests on the assumption that distilling raw long-term user histories into structured root memories preserves decision logic without introducing distortion or loss affecting downstream accuracy. The manuscript provides no formal definition, human validation, or controlled comparison (e.g., decision equivalence before/after distillation) to substantiate this preservation property.
Authors: We agree that the manuscript would be strengthened by explicit substantiation of the preservation property. Root memory is introduced in Section 3 as an explicit, rule-based extraction of reusable decision logic (e.g., conditional preferences and constraints) rather than a lossy compression; the downstream gains reported in Tables 3–5 are consistent with this design. Nevertheless, the current version lacks a formal definition of preservation, human fidelity ratings, and a controlled before/after equivalence study. In the revision we will add (i) a precise definition of decision equivalence, (ii) a controlled experiment measuring logical consistency on a held-out subset, and (iii) human validation results on a sample of 200 distilled memories. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper constructs a new benchmark (IMLogic) for implicit logical memory retrieval and proposes RootMem as a plug-and-play framework that distills user histories into structured root memories followed by an LLM-based router. No equations, fitted parameters, or derivation steps are present in the provided text that reduce by construction to inputs. No self-citation chains, uniqueness theorems, or ansatzes are invoked as load-bearing elements. The central claims rest on the independent creation of the benchmark and the distillation/router components, which do not reference or depend on prior self-authored results in a circular manner.
Axiom & Free-Parameter Ledger
invented entities (1)
-
root memory
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Evaluating very long-term conversational memory of llm agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13851– 13870. Thang Nguyen, Peter Chin, and Yu-Wing Tai. 2025. Ma-rag: Multi-agent retrieval-augmented generation via collaborative chain-of-thought reasoning.arXiv preprint...
arXiv 2025
-
[2]
Hongjin Qian, Zheng Liu, Peitian Zhang, Kelong Mao, Defu Lian, Zhicheng Dou, and Tiejun Huang
On memory construction and retrieval for personalized conversational agents.arXiv preprint arXiv:2502.05589. Hongjin Qian, Zheng Liu, Peitian Zhang, Kelong Mao, Defu Lian, Zhicheng Dou, and Tiejun Huang. 2025. Memorag: Boosting long context processing with global memory-enhanced retrieval augmentation. In Proceedings of the ACM on Web Conference 2025, pag...
arXiv 2025
-
[3]
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Jun- tao Tan, and Yongfeng Zhang
Alpsbench: An llm personalization bench- mark for real-dialogue memorization and preference alignment.arXiv preprint arXiv:2603.26680. Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Jun- tao Tan, and Yongfeng Zhang. 2025a. A-mem: Agentic memory for llm agents.arXiv preprint arXiv:2502.12110. Yiyan Xu, Wenjie Wang, Yang Zhang, Biao Tang, Peng Yan, Fuli Feng, ...
Pith/arXiv arXiv 2025
-
[4]
arXiv preprint arXiv:2601.12034
Don’t start over: A cost-effective framework for migrating personalized prompts between llms. arXiv preprint arXiv:2601.12034. Wanjun Zhong, Lianghong Guo, Qiqi Gao, He Ye, and Yanlin Wang. 2024. Memorybank: Enhancing large language models with long-term memory. InPro- ceedings of the AAAI conference on artificial intelli- gence, volume 38, pages 19724–19...
arXiv 2024
-
[5]
Contextual Activation: Consider L as a genuine background circuit within the cognitive miner system
-
[6]
conflict
Competition Monitoring: When in- 14 tention S attempts to load or execute, the cognitive miner the interaction be- tween S and L. 3.Conflict Signal Output: • If S and L cannot be smoothly concurrent, it is determined as Conflict. • If the situation described by L is clearly a an optimal alternative of S, this value dimension competi- tion must also be ext...
-
[7]
2.Semantic & Zero Leakage: • The query must be strongly re- lated to Memory_s
Logic: Is the reasoning logical? Mem- ory_s should be correctly blocked or constrained by Memory_l. 2.Semantic & Zero Leakage: • The query must be strongly re- lated to Memory_s. • The query must not contain any keywords, hints, or direct refer- ences to Memory_l
-
[8]
Naturalness: The query and options must sound natural and realistic
-
[9]
Option Bias Avoidance: The 4 op- tions must not have obvious differ- ences in length or style
-
[10]
status
Accuracy: The ’Correct’ option must be the best response when knowing both Memory_s and Memory_l. Output Format (JSON Only): { " status " : " PASS " or " NOT PASS " , " error_category " : " Query Error " or " Answer Error " or " Other Option Error " or " None " , " reason " : " Provide a brief reason if not pass . " } Prompt for Question Refinement You ar...
-
[11]
[Query_Time], [Direct Question]?
Query Format: Query must strictly be formatted as "[Query_Time], [Direct Question]?"
-
[12]
Semantic Constraint: Query must re- flect Memory_s, but must completely hide Memory_l
-
[13]
Option Balance: The 4 options must have similar lengths and formatting to avoid selection bias
-
[14]
type " :
Logical Consistency: The ’Correct’ option must refuse or pivot based on Memory_l. Output Format (JSON Only): { " type " : " Recommendation / Advice / Conversation " , " query " : " Fixed concise query strictly starting with Query_Time ... " , " options " : { " Correct " : " ... " , " Trap_Preference " : " ... " , " Tra p_Fabric ation " : " ... " , " Trap_...
2020
-
[15]
Evaluate the user’s query to identify not only its literal needs but also the po- tential implications the request might trigger
-
[16]
Compare the analyzed intent against each of the provided available root memory units
-
[17]
Rreturn a valid JSON object contain- ing only the list of selected Mem- ory_Domain names
-
[18]
act iv at ed _do ma in s
You are encouraged to recall multiple relevant memory domains to ensure a comprehensive response. Output Format (JSON Only): { " act iv at ed _do ma in s " : [ " Memory_Domain_1 " , " Memory_Domain_2 " , ...] } D.3 Prompts for Answer Generation and Evaluation Prompts for Multiple-Choice Question Answering Role: Cognitive Evaluation Agent You are an advanc...
-
[20]
Output Format: Output only the letter of the best option (e.g., A, B, C, or D)
Evidence-Grounded Alignment: Se- lect the response that maximally aligns with the user’s actual needs, relying on the provided evidence. Output Format: Output only the letter of the best option (e.g., A, B, C, or D). Do not provide any explanation. Prompt for Open-Ended Question An- swering Role: Cognitive Generative Agent You are an advanced conversation...
-
[21]
Logic-Aware Personalization: Incor- porate the Execution_Rules and Per- sonalized_Logical_Evidences defined in Active_Root_Memory_Units to con- textualize and tailor the response
-
[22]
Output Format: Output ONLY a single, well-structured sen- tence (not more than 50 words)
Evidence-Grounded Alignment: Se- lect the response that maximally aligns with the user’s actual needs, relying on the provided evidence. Output Format: Output ONLY a single, well-structured sen- tence (not more than 50 words). Do not provide any internal reasoning or explana- tion. Prompt for Evaluating Open-Ended An- swers Role: Expert Memory Evaluator Y...
-
[23]
Specific Grounding: The prediction MUST incorporate the specific fact or 18 constraint from [Memory l]
-
[24]
is_correct
Logical Alignment: The core rec- ommendation must match the logical direction of the [Reference Answer]. It must use [Memory l] to appropri- ately constrain, guide, or warn the user against conflicting actions. JUDGING Rules: • Be strict about the inclusion of the spe- cific constraint from [Memory l]. The model must prove it retrieved the right memory. •...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.