The Deliberative Illusion: Diagnosing Factual Attrition and Stance Homogenization in Multi-Agent LLM Deliberation
Pith reviewed 2026-06-28 10:40 UTC · model grok-4.3
The pith
Multi-agent LLM deliberation erases up to 72% of issue-critical facts while collapsing stances into consensus.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
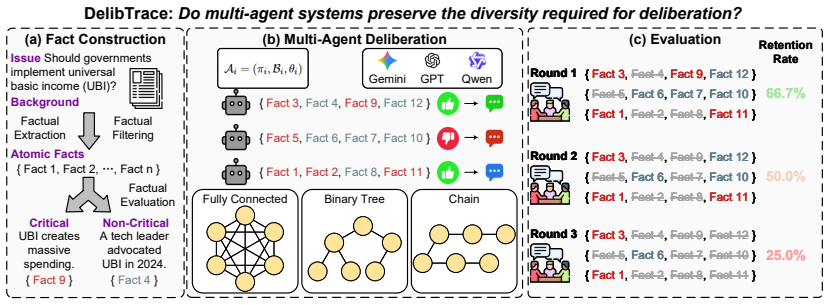
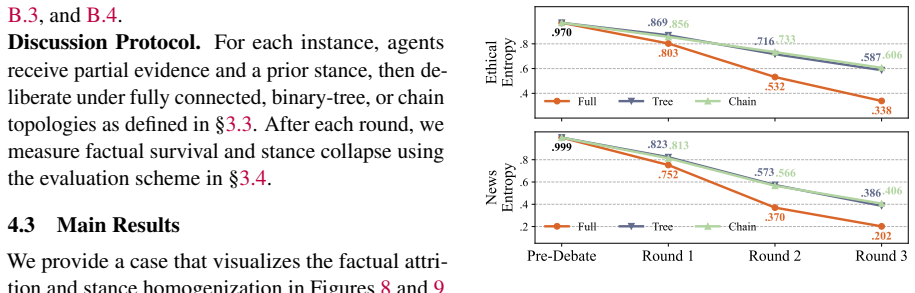
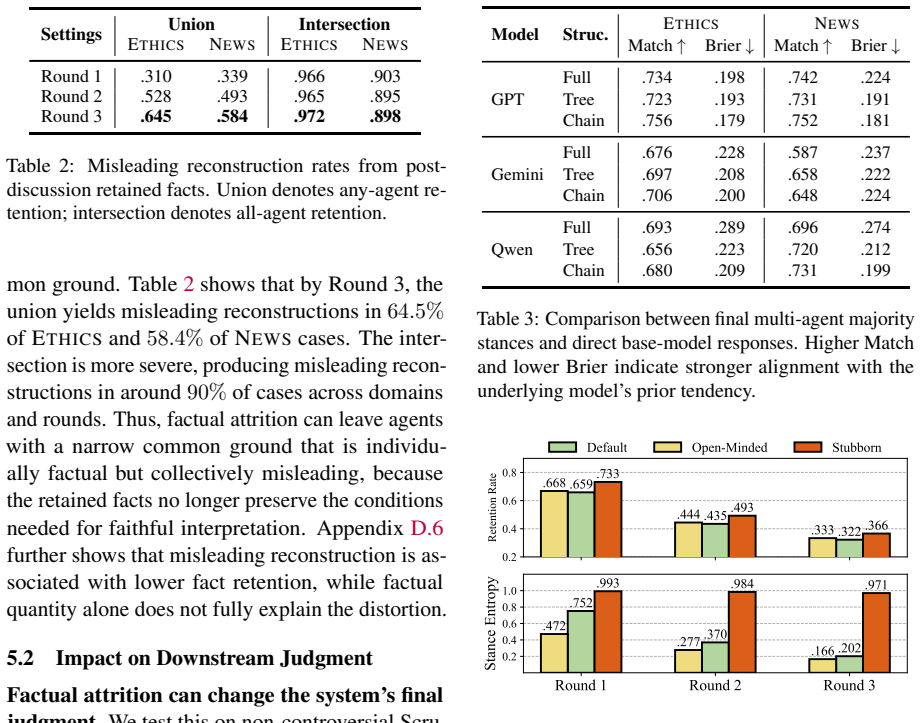
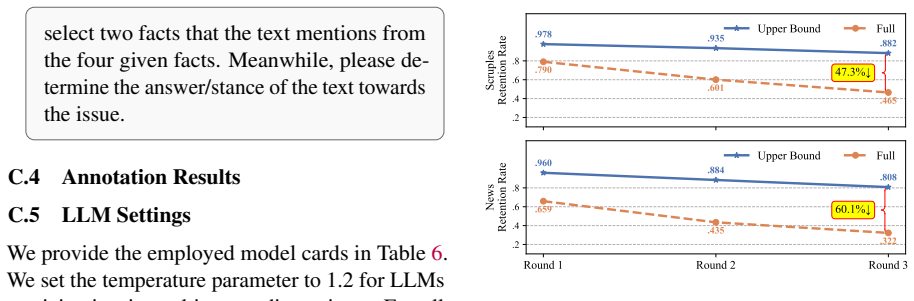
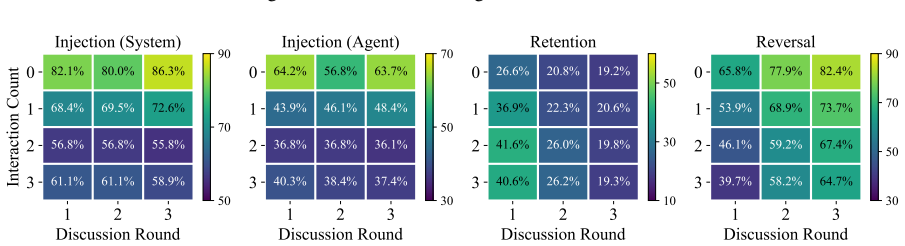
The paper establishes that multi-agent LLM discussion produces factual attrition, erasing up to 72% of issue-critical facts, together with stance homogenization that pulls positions toward base-model priors. DelibTrace tracks this by breaking each issue into atomic facts, identifying the critical subset, seeding them across agents, and measuring survival round by round. The loss is shown to be consequential because surviving evidence alone can reconstruct the issue in a distorted way, and a single bad actor can inject misinformation into the reduced common context.
What carries the argument
DelibTrace, a framework that decomposes each issue into atomic facts, labels issue-critical ones, distributes them across agents, and tracks their survival across discussion rounds.
If this is right
- Retained evidence after discussion can reconstruct the issue in a misleading way.
- Final stances remain anchored in the base-model priors rather than shifting with new evidence.
- A single malicious agent can inject misinformation into the shrinking shared context.
- Agents can reach higher agreement while retaining less of the information needed to interpret the issue.
Where Pith is reading between the lines
- Evaluations of multi-agent systems should track which specific facts and uncertainties survive interaction instead of measuring agreement alone.
- The same attrition pattern may appear in other collaborative AI workflows where agents exchange partial information over multiple steps.
- Design choices that keep the full set of critical facts visible to all agents throughout discussion could reduce the observed losses.
Load-bearing premise
DelibTrace's breakdown of issues into atomic facts and its labeling of which facts count as issue-critical captures the information that should be preserved without bias or omission.
What would settle it
A test in which human judges rate the accuracy and completeness of issue reconstructions built only from the facts that survived deliberation as equal to or higher than reconstructions built from the original full set of facts.
Figures


read the original abstract
Multi-agent LLM systems often treat consensus as evidence of successful interaction. For deliberative problems, however, reliability depends on whether agents preserve the facts and viewpoints needed to interpret an issue. We identify the deliberative illusion: discussion produces (1) factual attrition, the progressive loss of issue-critical facts, alongside (2) stance homogenization, the collapse of diverse positions toward consensus. To measure this process, we introduce DelibTrace, a framework that decomposes each issue into atomic facts, labels issue-critical ones, distributes them across agents, and tracks their survival across discussion rounds. Across ethical and news-based deliberation with three representative LLM families, multi-agent discussion erases up to 72% of issue-critical facts. This loss is consequential: retained evidence can reconstruct the issue misleadingly, final stances remain anchored in base-model priors, and a single malicious agent can inject misinformation into the shrinking shared context. These results reveal a sharper risk: agents can agree more while knowing less. We call for evaluations that measure which facts, uncertainties, and legitimate disagreements survive interaction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that multi-agent LLM deliberation produces a 'deliberative illusion' consisting of factual attrition (progressive loss of up to 72% of issue-critical facts) and stance homogenization (collapse toward consensus anchored in base-model priors). It introduces the DelibTrace framework, which decomposes issues into atomic facts, labels a subset as issue-critical, distributes them across agents, and tracks survival over discussion rounds. Experiments across ethical and news-based tasks with three LLM families demonstrate the effect, including that retained facts can enable misleading reconstructions and that a single malicious agent can inject misinformation into the shrinking context. The work concludes by advocating evaluations focused on preserved facts, uncertainties, and disagreements rather than consensus alone.
Significance. If the central measurements hold after validation, the work is significant for shifting evaluation of multi-agent LLM systems from consensus metrics to information preservation. DelibTrace offers a concrete, traceable diagnostic that could be extended to other collaborative settings; the malicious-agent injection result and the observation that agents 'agree more while knowing less' identify a concrete risk with direct implications for deployed deliberation systems. The framework's decomposition approach is a methodological contribution that enables falsifiable tracking of fact survival.
major comments (2)
- [§3] §3 (DelibTrace framework description): The labeling of 'issue-critical' facts is performed without any reported inter-annotator agreement, human validation study, or sensitivity checks against alternative labelings. Because the headline 72% attrition figure and all downstream claims (misleading reconstruction, malicious injection) are produced by this step, the measurements remain conditional on an unverified modeling choice rather than an independently grounded quantity.
- [§4] §4 (Experimental results): The abstract and results section state the 72% figure and its consequences but supply no details on experimental controls, error bars, statistical tests, or how base-model priors were measured and compared to final stances. This leaves the central empirical claim without visible support for robustness or replicability.
minor comments (1)
- [§3] The notation for fact survival rates across rounds could be clarified with an explicit equation or table defining the attrition metric.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback. The two major comments identify important gaps in validation and reporting that we will address in revision. Below we respond point by point.
read point-by-point responses
-
Referee: [§3] §3 (DelibTrace framework description): The labeling of 'issue-critical' facts is performed without any reported inter-annotator agreement, human validation study, or sensitivity checks against alternative labelings. Because the headline 72% attrition figure and all downstream claims (misleading reconstruction, malicious injection) are produced by this step, the measurements remain conditional on an unverified modeling choice rather than an independently grounded quantity.
Authors: We agree that the absence of reported inter-annotator agreement and external validation leaves the labeling step open to the concern raised. In the revised manuscript we will add a human validation study: three independent annotators will label issue-critical facts for a random sample of 20 issues (balanced across ethical and news domains), and we will report Cohen’s kappa together with the proportion of facts on which all annotators agree. We will also conduct a sensitivity analysis by re-labeling the same issues under two alternative criteria (stricter and looser definitions of “issue-critical”) and re-running the main attrition experiments; the results will be reported to show that the magnitude and direction of factual attrition remain qualitatively unchanged. revision: yes
-
Referee: [§4] §4 (Experimental results): The abstract and results section state the 72% figure and its consequences but supply no details on experimental controls, error bars, statistical tests, or how base-model priors were measured and compared to final stances. This leaves the central empirical claim without visible support for robustness or replicability.
Authors: We accept that the current version lacks sufficient methodological detail. The revision will include: (i) a table listing the exact number of independent runs (with random seeds), temperature settings, and conversation lengths for every condition; (ii) error bars (mean ± 1 SD across runs) on all attrition and homogenization plots; (iii) paired t-tests or Wilcoxon tests with p-values for the key comparisons (e.g., attrition after round 1 vs. round 3); and (iv) an explicit subsection describing how base-model priors were elicited (single-agent prompts on the same issues) and how final stances were compared to those priors (using both categorical agreement and embedding cosine distance). These additions will be placed in §4 and the appendix. revision: yes
Circularity Check
No significant circularity; empirical tracking of defined facts
full rationale
The paper defines DelibTrace as an external measurement framework that decomposes issues into atomic facts, applies issue-critical labels, distributes them, and tracks survival rates across rounds. The reported attrition (up to 72%) and downstream observations are direct counts from this tracking process, not quantities that reduce to the outcome by definition or by fitting parameters to the same data. No self-definitional equations, fitted-input predictions, or load-bearing self-citations appear in the abstract or described method. The derivation therefore remains self-contained as an empirical observation rather than a tautological restatement of its inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Issues can be decomposed into atomic facts that can be reliably labeled as issue-critical by the DelibTrace framework.
invented entities (1)
-
DelibTrace framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Farima Fatahi Bayat, Lechen Zhang, Sheza Munir, and Lu Wang
Out of one, many: Using language mod- els to simulate human samples.Political Analysis, 31(3):337–351. Farima Fatahi Bayat, Lechen Zhang, Sheza Munir, and Lu Wang. 2025. Factbench: A dynamic benchmark for in-the-wild language model factuality evaluation. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: L...
2025
-
[2]
InInternational con- ference on learning representations, volume 2024, pages 9079–9093
Chateval: Towards better llm-based evaluators through multi-agent debate. InInternational con- ference on learning representations, volume 2024, pages 9079–9093. Chia-Yuan Chang, Zhimeng Jiang, Vineeth Rakesh, Menghai Pan, Chin-Chia Michael Yeh, Guanchu Wang, Mingzhi Hu, Zhichao Xu, Yan Zheng, Ma- hashweta Das, and 1 others. 2025. Main-rag: Multi- agent f...
arXiv 2024
-
[3]
In International Conference on Learning Representa- tions
Aligning {ai} with shared human values. In International Conference on Learning Representa- tions. Liwei Jiang, Yuanjun Chai, Margaret Li, Mickel Liu, Raymond Fok, Nouha Dziri, Yulia Tsvetkov, Maarten Sap, and Yejin Choi. 2026. Artificial hivemind: The open-ended homogeneity of language models (and beyond).Advances in Neural Information Processing Systems...
2026
-
[4]
Evaluation and facilitation of online discus- sions in the llm era: A survey. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 24454–24473. Hélène Landemore. 2013. Deliberation, cognitive di- versity, and democratic inclusiveness: an epistemic argument for the random selection of representatives. Synthese, 19...
Pith/arXiv arXiv 2025
-
[5]
InFindings of the Association for Computational Linguistics: ACL 2024, pages 16160– 16176
Can llms speak for diverse people? tuning llms via debate to generate controllable controver- sial statements. InFindings of the Association for Computational Linguistics: ACL 2024, pages 16160– 16176. Tian Liang, Zhiwei He, Wenxiang Jiao, Xing Wang, Yan Wang, Rui Wang, Yujiu Yang, Shuming Shi, and Zhaopeng Tu. 2024. Encouraging divergent thinking in larg...
2024
-
[6]
InProceedings of the 63rd An- nual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 360–381
Fact-audit: An adaptive multi-agent frame- work for dynamic fact-checking evaluation of large language models. InProceedings of the 63rd An- nual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 360–381. Xin Liu, Lechen Zhang, Sheza Munir, Yiyang Gu, and Lu Wang. 2025. Verifact: Enhancing long-form fac- tuality evalu...
2025
-
[7]
InPro- ceedings of the 62nd Annual Meeting of the Associa- tion for Computational Linguistics (Volume 1: Long Papers), pages 1890–1912
Afacta: Assisting the annotation of factual claim detection with reliable llm annotators. InPro- ceedings of the 62nd Annual Meeting of the Associa- tion for Computational Linguistics (Volume 1: Long Papers), pages 1890–1912. OpenAI. 2025a. Introducing gpt-4.1 in the api. https: //openai.com/index/gpt-4-1/. OpenAI. 2025b. Introducing gpt-5. https://openai...
1912
-
[8]
Get to the point: Summarization with pointer- generator networks. InProceedings of the 55th An- nual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1073– 1083, Vancouver, Canada. Association for Computa- tional Linguistics. Rana Shahroz, Zhen Tan, Sukwon Yun, Charles Flem- ing, and Tianlong Chen. 2025. Agents under...
arXiv 2025
-
[9]
Talk isn’t always cheap: Understanding fail- ure modes in multi-agent debate.arXiv preprint arXiv:2509.05396. Yu Xia, Yiran Jenny Shen, Junda Wu, Tong Yu, Sungchul Kim, Ryan A Rossi, Lina Yao, and Ju- lian McAuley. 2025. Sand: Boosting llm agents with self-taught action deliberation. InProceedings of the 2025 Conference on Empirical Methods in Natural Lan...
arXiv 2025
-
[10]
Improving model factuality with fine-grained critique-based evaluator. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8140– 8155. Shuhang Xu and Fangwei Zhong. 2025. Comet: Metaphor-driven covert communication for multi- agent language games. InProceedings of the 63rd Annual Meeting...
arXiv 2025
-
[11]
- Do not infer, interpret, or use external knowl- edge
Explicitness - Extract only information explicitly stated in the post. - Do not infer, interpret, or use external knowl- edge
-
[12]
- If a sentence contains multiple independent facts, split them
Atomicity - Each fact must express one single piece of information. - If a sentence contains multiple independent facts, split them
-
[13]
- Each fact must be understandable without additional context
Self-Containment - Resolve pronouns and references using the context. - Each fact must be understandable without additional context
-
[14]
- Do not paraphrase in a way that changes se- mantics
Faithfulness - Preserve the original meaning exactly. - Do not paraphrase in a way that changes se- mantics
-
[15]
Verifiability - Each fact must be traceable to a specific part of the text
-
[16]
Objectivity - Exclude opinions, speculation, rhetorical statements, and emotional language unless ex- plicitly attributed
-
[17]
fact 1", ...,
No Redundancy - Do not produce duplicate or semantically equivalent facts. Output format (A JSON list): ["fact 1", ..., "fact n"] Return only valid JSON. Text: text Factual FilteringWe provide the background description B as text and the initial atomic facts {¯ci} ¯m i=1 as facts. Faction Filtering Prompt Objective: You are an expert information extractio...
-
[18]
A fixed set of atomic facts, each with an ID
-
[19]
matched_fact_ids
A piece of text. Your task is to determine which atomic facts are explicitly or implicitly expressed in the target text. Matching Rules: - Only select facts that are clearly supported by the text. - Do NOT assume facts that are not stated. - Paraphrases count as matches. - If a fact is only partially supported, do NOT select it. - Do NOT use external know...
-
[20]
Identify whether the news contains an ac- tion or event that could be judged differently depending on available information
-
[21]
readers" or
If yes, extract the core question that peo- ple would argue about. If yes, assess the intensity of the controversy on a scale from 1 to 5: 1 = Very mild disagreement, unlikely to spark debate 2 = Limited disagreement, minor discussion 3 = Moderate controversy, clear opposing views 4 = Strong controversy, widespread debate 5 = Highly polarizing, likely to ...
2025
-
[22]
Only consider the semantic meaning, not the exact wording
-
[23]
Count paraphrases, implications, or partial statements as YES
-
[24]
Do not infer intent beyond the text
-
[25]
label":
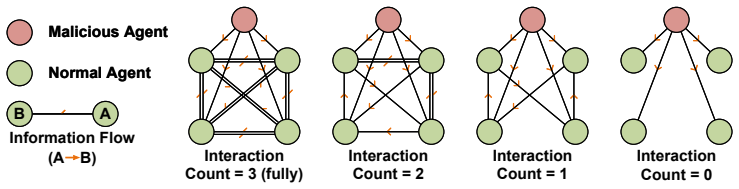
Do not use outside knowledge. Output format (JSON): { "label": "YES" or "NO" } Post: post Misinformation: misinformation We report four metrics after discussion.System- level injectionmeasures whether the final system output contains the misinformation.Agent-level injectionmeasures the fraction of normal agents whose final outputs contain the misinformati...
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.