VZCrash: A Large-Scale IMU Dataset of Ego-Vehicle Crashes
Pith reviewed 2026-06-28 02:01 UTC · model grok-4.3
The pith
A dataset of more than 31,000 real vehicle crashes with IMU data demonstrates that larger training sets produce better performing crash detection models in real-world settings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
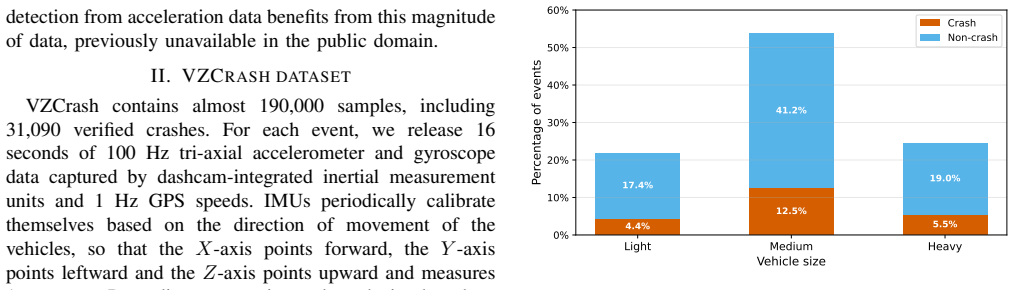
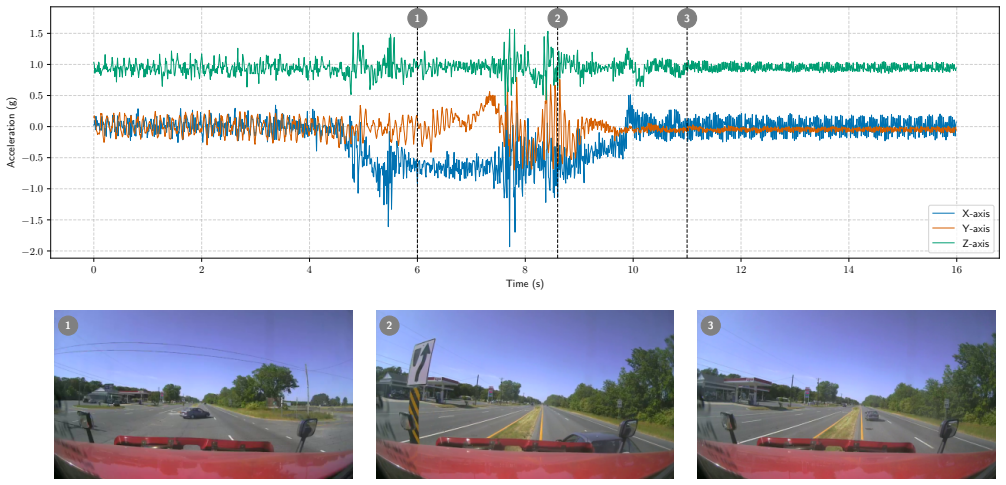
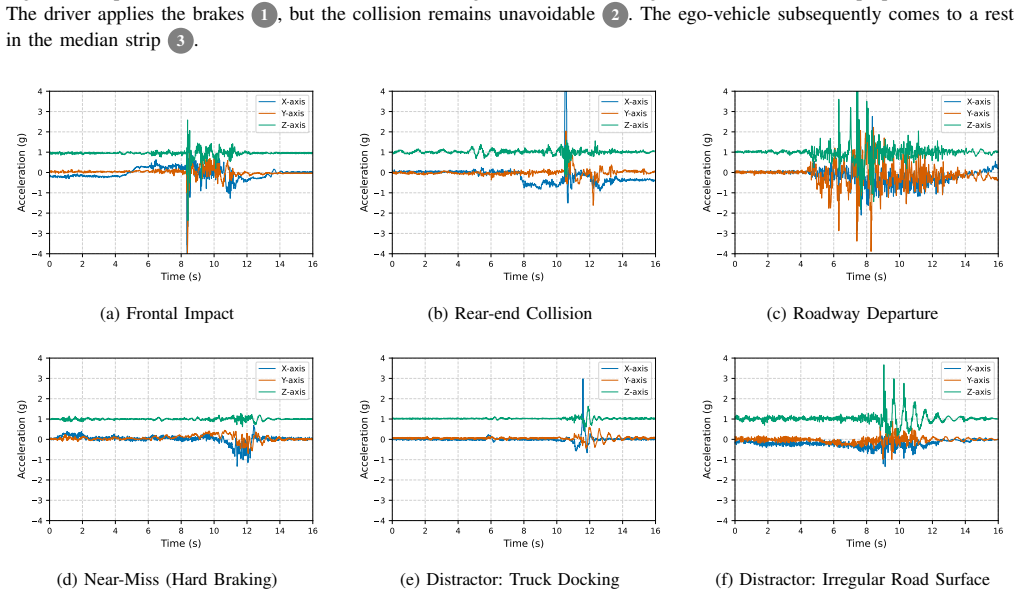
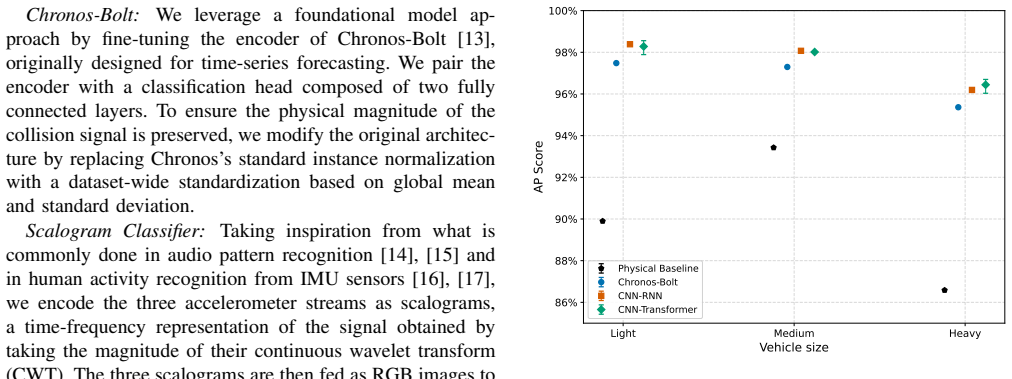
The authors present VZCrash containing over 31,000 validated crashes and 158,000 negative samples from IMU and GPS data collected across 73,010 vehicles. Through extensive benchmarks, they establish that scaling the training data volume is critical for achieving high-quality crash detection models that work well when deployed in real-world environments.
What carries the argument
The VZCrash dataset itself, which supplies large-scale real crash IMU telemetry at 100 Hz for acceleration and angular velocity along with GPS speed, serving as the foundation for benchmarking detection methods and scaling experiments.
If this is right
- Simple threshold heuristics can be compared directly to deep learning models using the same large set of real events.
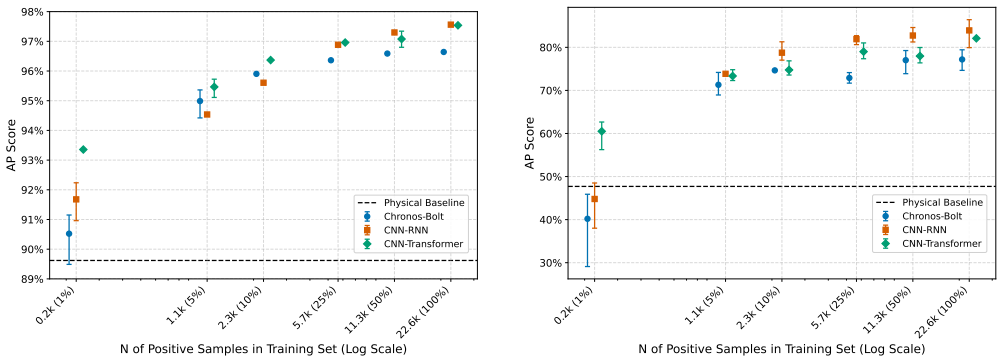
- Training crash detectors on increasing fractions of the dataset shows consistent gains in performance metrics.
- Models trained at larger scales exhibit better results specifically in real-world deployment scenarios compared to smaller datasets.
- Negative samples including hard cases and distractors help in training more robust detectors.
Where Pith is reading between the lines
- Future work could combine this IMU data with video or other modalities to further improve detection accuracy.
- Such a dataset might enable development of on-device models for immediate crash response in vehicles.
- Insights on data scaling could apply to other rare event detection tasks in transportation safety.
Load-bearing premise
The more than 31,000 events are accurately validated as true crashes using the IMU and GPS telemetry from the commercial fleet.
What would settle it
Training a model on a random 10% subset of the crashes and finding it matches or exceeds the performance of a model trained on the full set when evaluated on independent real-world test data would falsify the importance of scale.
Figures

read the original abstract
We introduce VZCrash, the largest publicly available dataset of real-world vehicle collision data featuring Inertial Measurement Unit (IMU) telemetry. The dataset contains more than 31,000 validated crashes and 158,000 negative samples, including hard cases and distractors. Each sample includes acceleration and angular velocity at 100 Hz, and GPS speed at 1 Hz. Events in VZCrash were captured by devices installed on a fleet of 73,010 commercial vehicles of different sizes driving in the United States over the span of several years. We also present an extensive experimental study enabled by the volume of the dataset. We first benchmark several different approaches, from a simple threshold-based heuristic to state-of-the-art deep learning models. Then, we present an experiment demonstrating the importance of scaling data to train high-quality crash detection models, and we show that scale is especially important when these models need to be deployed into a real-world environment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces VZCrash, the largest public IMU dataset for real-world ego-vehicle crashes, containing more than 31,000 validated crash events and 158,000 negative samples (including hard cases and distractors) collected at 100 Hz from a fleet of 73,010 commercial vehicles over several years. It benchmarks threshold heuristics against deep learning models and presents scaling experiments arguing that larger data volumes are especially critical for real-world deployment performance.
Significance. If the positive-class labels are reliable, the release would be a valuable resource for training and evaluating crash-detection systems, with the scaling study offering practical insight into data requirements for deployment. The scale and inclusion of distractors address a gap in existing public IMU crash data.
major comments (1)
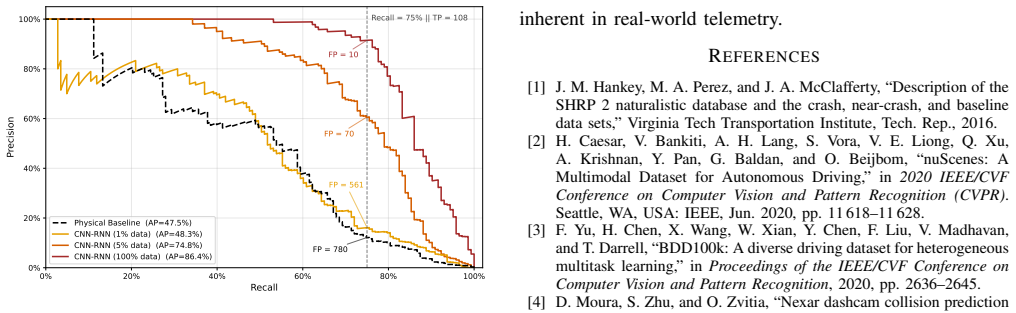
- [Section 3.2] Section 3.2: Crash validation is performed via fixed thresholds on peak acceleration (>0.5 g), angular velocity, GPS speed drop, followed by manual review of only a subset; no false-positive rate is quantified against external ground truth (video, telematics, or insurance records) for the full set of 31k events. This is load-bearing for the dataset utility claim and for the conclusion that scale improves real-world deployment.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback emphasizing the importance of reliable positive-class labels. We address the concern on crash validation in Section 3.2 below, providing additional context on our process while acknowledging practical constraints.
read point-by-point responses
-
Referee: [Section 3.2] Section 3.2: Crash validation is performed via fixed thresholds on peak acceleration (>0.5 g), angular velocity, GPS speed drop, followed by manual review of only a subset; no false-positive rate is quantified against external ground truth (video, telematics, or insurance records) for the full set of 31k events. This is load-bearing for the dataset utility claim and for the conclusion that scale improves real-world deployment.
Authors: We agree that external ground-truth validation (e.g., via video or insurance records) for the entire set of 31k events would further strengthen the claims. However, given the scale (73k vehicles over multiple years) and commercial fleet privacy constraints, obtaining such records for every candidate event is not feasible. Our process applies conservative multi-signal thresholds to generate candidates, followed by manual review of a representative subset to confirm crashes; this is documented in Section 3.2. We have revised the manuscript to (1) report the exact fraction of events that received manual review, (2) provide rationale and sensitivity analysis for the chosen thresholds, and (3) add an explicit limitations paragraph discussing the absence of full external FPR quantification. The scaling experiments remain valid because they compare models trained on the same validation protocol; the distractor negatives further stress-test real-world robustness. We believe these changes address the core concern without overstating label certainty. revision: partial
Circularity Check
No circularity: dataset release with empirical benchmarks only
full rationale
The paper presents a new IMU crash dataset and reports benchmark results on detection models. No derivations, equations, fitted parameters renamed as predictions, or self-citation chains appear in the load-bearing claims. Validation relies on described heuristics plus manual review of a subset, but this is an empirical process rather than a self-referential reduction. The contribution is self-contained as a data resource plus scaling experiments whose results are not forced by construction from the inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Commercial vehicle fleet IMU and GPS data can be used to collect and validate representative real-world crash events
Reference graph
Works this paper leans on
-
[1]
Description of the SHRP 2 naturalistic database and the crash, near-crash, and baseline data sets,
J. M. Hankey, M. A. Perez, and J. A. McClafferty, “Description of the SHRP 2 naturalistic database and the crash, near-crash, and baseline data sets,” Virginia Tech Transportation Institute, Tech. Rep., 2016
2016
-
[2]
nuScenes: A Multimodal Dataset for Autonomous Driving,
H. Caesar, V . Bankiti, A. H. Lang, S. V ora, V . E. Liong, Q. Xu, A. Krishnan, Y . Pan, G. Baldan, and O. Beijbom, “nuScenes: A Multimodal Dataset for Autonomous Driving,” in2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, W A, USA: IEEE, Jun. 2020, pp. 11 618–11 628
2020
-
[3]
BDD100k: A diverse driving dataset for heterogeneous multitask learning,
F. Yu, H. Chen, X. Wang, W. Xian, Y . Chen, F. Liu, V . Madhavan, and T. Darrell, “BDD100k: A diverse driving dataset for heterogeneous multitask learning,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 2636–2645
2020
-
[4]
Nexar dashcam collision prediction dataset and challenge,
D. Moura, S. Zhu, and O. Zvitia, “Nexar dashcam collision prediction dataset and challenge,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, 2025, pp. 2583–2591
2025
-
[5]
Cognitive accident prediction in driving scenes: A multimodality benchmark,
J. Fang, L.-L. Li, K. Yang, Z. Zheng, J. Xue, and T.-S. Chua, “Cognitive accident prediction in driving scenes: A multimodality benchmark,”arXiv preprint arXiv:2212.09381, 2022
-
[6]
Accident risk prediction based on heterogeneous sparse data: New dataset and insights,
S. Moosavi, M. H. Samavatian, S. Parthasarathy, R. Teodorescu, and R. Ramnath, “Accident risk prediction based on heterogeneous sparse data: New dataset and insights,” inProceedings of the 27th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, 2019, pp. 33–42
2019
-
[7]
Fatality analy- sis reporting system (FARS),
National Highway Traffic Safety Administration, “Fatality analy- sis reporting system (FARS),” https://www.nhtsa.gov/research-data/ fatality-analysis-reporting-system-fars, 2023, accessed: 2026-02-24
2023
-
[8]
Deep crash detection from vehicular sensor data with multimodal self-supervision,
L. Kubin, T. Bianconcini, D. C. de Andrade, M. Simoncini, L. Taccari, and F. Sambo, “Deep crash detection from vehicular sensor data with multimodal self-supervision,”IEEE Transactions on Intelligent Transportation Systems, vol. 23, no. 8, pp. 12 480–12 489, 2021
2021
-
[9]
Classification of crash and near-crash events from dashcam videos and telematics,
L. Taccari, F. Sambo, L. Bravi, S. Salti, L. Sarti, M. Simoncini, and A. Lori, “Classification of crash and near-crash events from dashcam videos and telematics,” in2018 21st International Conference on intelligent transportation systems (ITSC). IEEE, 2018, pp. 2460– 2465
2018
-
[10]
Learning phrase representations using rnn encoder–decoder for statistical machine translation,
K. Cho, B. Van Merri ¨enboer, C ¸ . Gulc ¸ehre, D. Bahdanau, F. Bougares, H. Schwenk, and Y . Bengio, “Learning phrase representations using rnn encoder–decoder for statistical machine translation,” inProceed- ings of the 2014 Conference on Empirical Methods in Natural Lan- guage Processing (EMNLP), 2014, pp. 1724–1734
2014
-
[11]
Dust: Dual swin transformer for multi-modal video and time-series modeling,
L. Shi, Y . Chen, M. Liu, and F. Guo, “Dust: Dual swin transformer for multi-modal video and time-series modeling,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 4537–4546
2024
-
[12]
Swin transformer: Hierarchical vision transformer using shifted windows,
Z. Liu, Y . Lin, Y . Cao, H. Hu, Y . Wei, Z. Zhang, S. Lin, and B. Guo, “Swin transformer: Hierarchical vision transformer using shifted windows,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 10 012–10 022
2021
-
[13]
Chronos: Learning the Language of Time Series
A. F. Ansari, L. Stella, C. Turkmen, X. Zhang, P. Mercado, H. Shen, O. Shchur, S. S. Rangapuram, S. P. Arango, S. Kapooret al., “Chronos: Learning the language of time series,”arXiv preprint arXiv:2403.07815, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Panns: Large-scale pretrained audio neural networks for audio pattern recognition,
Q. Kong, Y . Cao, T. Iqbal, Y . Wang, W. Wang, and M. D. Plumb- ley, “Panns: Large-scale pretrained audio neural networks for audio pattern recognition,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 28, pp. 2880–2894, 2020
2020
-
[15]
Ast: Audio spectrogram transformer,
Y . Gong, Y .-A. Chung, and J. Glass, “Ast: Audio spectrogram trans- former,”arXiv preprint arXiv:2104.01778, 2021
-
[16]
Bi-deepvit: Binarized transformer for efficient sensor-based human activity recognition,
F. Luo, A. Li, S. Khan, K. Wu, and L. Wang, “Bi-deepvit: Binarized transformer for efficient sensor-based human activity recognition,” IEEE Transactions on Mobile Computing, vol. 24, no. 5, pp. 4419– 4433, 2025
2025
-
[17]
Driver activity recognition with vision transformer using time–frequency rep- resentations derived from wrist-worn sensors,
Y . Sakai, T. Akiduki, M. Meyer-Conde, and H. Takahashi, “Driver activity recognition with vision transformer using time–frequency rep- resentations derived from wrist-worn sensors,”IEEE Access, vol. 13, pp. 188 839–188 854, 2025
2025
-
[18]
Searching for mo- bilenetv3,
A. Howard, M. Sandler, G. Chu, L.-C. Chen, B. Chen, M. Tan, W. Wang, Y . Zhu, R. Pang, V . Vasudevanet al., “Searching for mo- bilenetv3,” inProceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 1314–1324
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.