Do LLM Embedding Spaces Recover Expert Structure?
Pith reviewed 2026-06-26 08:01 UTC · model grok-4.3
The pith
Pretrained LLM embeddings recover measurable expert symptom structure in mental health language, with fine-tuning and scale strengthening alignment after confound controls.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
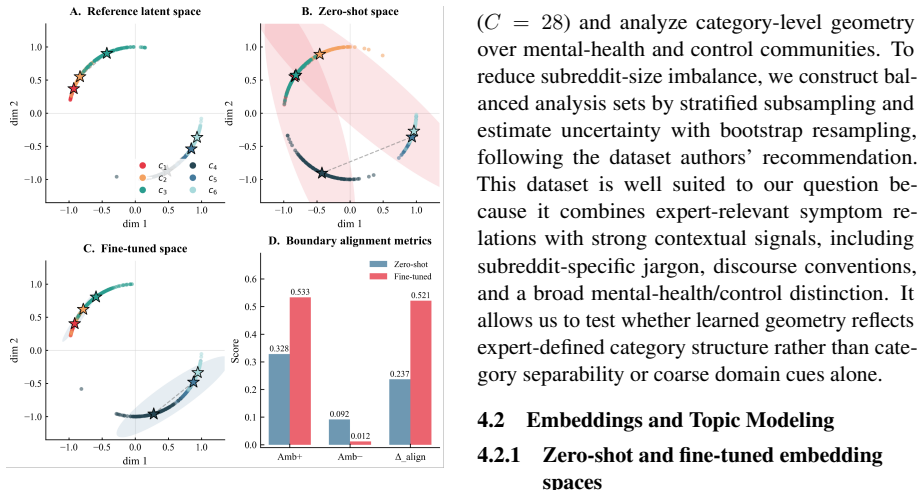
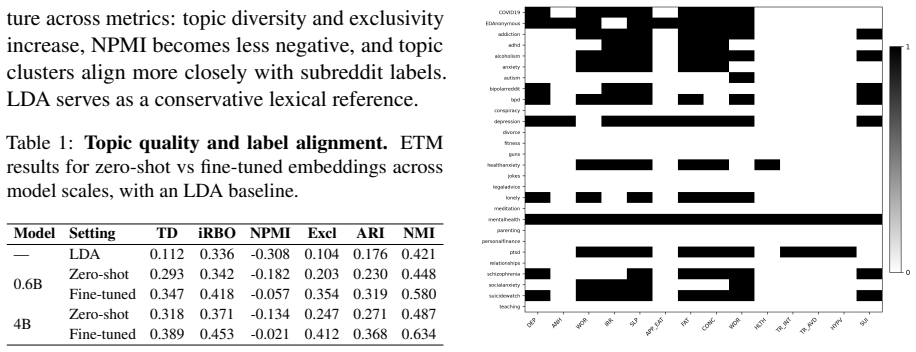
Pretrained embeddings from Qwen3 models exhibit measurable alignment with an expert symptom matrix within mental-health subsets of Reddit data. Fine-tuning strengthens the alignment, with the largest gains appearing at the finest category level. Larger model scale improves zero-shot alignment and amplifies the gains from supervision. Substantial residual alignment remains after statistical controls for VAD, LIWC, lexical style, and topic-distribution structure.
What carries the argument
Category prototypes extracted from embedding spaces, compared to an expert symptom matrix through representational similarity analysis, supplemented by prototype typicality scores and multi-baseline confound regressions.
If this is right
- Fine-tuning produces the greatest improvement in alignment at the most granular category level.
- Larger models deliver both higher zero-shot alignment and larger gains from the same supervision.
- Alignment with expert structure persists after removing variance attributable to valence-arousal-dominance, LIWC features, lexical style, and topic distributions.
- Recovery of expert geometry cannot be inferred from classification accuracy alone and requires explicit external-reference tests.
Where Pith is reading between the lines
- The same prototype-plus-RSA pipeline could be applied to other domains that possess published expert relational matrices, such as legal case categories or biological taxonomies.
- If residual alignment holds across additional controls, embeddings might function as approximate maps of expert knowledge even in settings where labeled expert data are scarce.
- Level-dependent effects imply that downstream applications should select or fine-tune at the granularity matching the intended expert distinctions rather than assuming uniform recovery.
Load-bearing premise
The expert symptom matrix accurately captures the true relational geometry of the categories, and the embedding prototypes reflect that geometry rather than sampling artifacts from the 28 communities.
What would settle it
Recomputing the representational similarity after randomly shuffling the entries of the expert symptom matrix; if the measured alignment drops to chance levels, the claim of specific recovery would be falsified.
Figures



read the original abstract
Pretrained text embeddings are increasingly used as representational maps, yet high category separability does not imply that their geometry recovers expert-defined structure. We study this problem in mental-health-related language, where symptom relations provide an external reference and online communities introduce strong domain, affective, stylistic, and discourse confounds. Using 28 Reddit communities, we compare pretrained and supervised fine-tuned Qwen3 embedding spaces at two scales (0.6B and 4B). We construct category prototypes, evaluate their representational dissimilarity matrices against an expert symptom matrix with representational similarity analysis, and complement this global test with prototype-based typicality and multi-baseline confound controls. Pretrained embeddings show measurable alignment with expert structure within the mental-health subset; fine-tuning strengthens this alignment most at the finest category level; and larger scale improves both zero-shot alignment and supervision-induced gains. Residual alignment remains substantial after controlling for VAD, LIWC, lexical style, and topic-distribution structure. These results suggest that LLM embeddings can recover expert-relevant category geometry, but this recovery is level-dependent and should be tested against explicit confounds rather than inferred from classification alone.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript examines whether pretrained and fine-tuned LLM embedding spaces recover expert-defined symptom structures in mental-health language drawn from 28 Reddit communities. It constructs category prototypes from Qwen3 embeddings (0.6B and 4B scales), compares their representational dissimilarity matrices to an external expert symptom matrix via representational similarity analysis (RSA), and evaluates alignment after controlling for VAD, LIWC, lexical style, and topic-distribution confounds. Reported results indicate measurable zero-shot alignment that strengthens with fine-tuning (especially at fine-grained levels) and model scale, with substantial residual alignment persisting after confound controls.
Significance. If the central claims hold after addressing methodological gaps, the work supplies concrete evidence that embedding geometry can recover expert structure beyond surface confounds in a high-stakes domain, supporting cautious use of embeddings for mental-health analysis and underscoring the value of explicit RSA-based testing over classification accuracy alone. The multi-baseline confound design and external reference matrix are positive features that distinguish the study from purely correlational embedding evaluations.
major comments (3)
- [Abstract / Methods (confound controls)] Abstract and Methods (confound controls paragraph): The claim that 'residual alignment remains substantial' after controlling for VAD, LIWC, lexical style, and topic-distribution structure is load-bearing for the central claim, yet the manuscript provides no description of the partialling procedure (e.g., whether controls are applied to the RDMs before RSA, the exact regression or residualization method, or whether controls are global or per-comparison). Without this, it is impossible to verify that the reported residual correlation isolates expert geometry rather than unmodeled lexical or sampling overlap.
- [Abstract / Methods (expert matrix)] Abstract and Results (expert matrix and prototype construction): The expert symptom matrix is treated as an independent geometric reference, but its construction (source texts, symptom descriptors, dimensionality) is unspecified. If the matrix entries derive from descriptions that lexically overlap with the Reddit communities, the RSA alignment and residual after controls could be driven by shared surface features rather than expert structure; a concrete test (e.g., lexical overlap statistics between matrix and corpus) is needed.
- [Results] Results (RSA correlations and scale/fine-tuning effects): No error bars, exact correlation values, statistical tests (e.g., permutation tests for RSA), data exclusion rules, or sample sizes per community are reported. This absence makes it impossible to assess whether the reported improvements from fine-tuning and scale are reliable or whether the 'measurable alignment' in the pretrained case exceeds what would be expected from the confound baselines alone.
minor comments (2)
- [Abstract] The abstract states results from 'prototype-based typicality' but the main text does not clarify how typicality scores are computed or whether they are used only for visualization or as a quantitative test.
- [Methods] Notation for the four confound controls should be introduced consistently (e.g., define RDM_VAD, RDM_LIWC) to aid readability when describing the partial correlation steps.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments correctly identify gaps in methodological description and statistical reporting that require clarification. We address each point below and commit to revisions that improve transparency without altering the core claims or analyses.
read point-by-point responses
-
Referee: [Abstract / Methods (confound controls)] Abstract and Methods (confound controls paragraph): The claim that 'residual alignment remains substantial' after controlling for VAD, LIWC, lexical style, and topic-distribution structure is load-bearing for the central claim, yet the manuscript provides no description of the partialling procedure (e.g., whether controls are applied to the RDMs before RSA, the exact regression or residualization method, or whether controls are global or per-comparison). Without this, it is impossible to verify that the reported residual correlation isolates expert geometry rather than unmodeled lexical or sampling overlap.
Authors: We agree that the partialling procedure requires explicit description. The current manuscript omits these details. In revision we will add a dedicated Methods subsection specifying that control RDMs are residualized from the embedding RDMs via multiple linear regression on the vectorized upper triangles, applied globally across all pairwise comparisons prior to RSA computation. revision: yes
-
Referee: [Abstract / Methods (expert matrix)] Abstract and Results (expert matrix and prototype construction): The expert symptom matrix is treated as an independent geometric reference, but its construction (source texts, symptom descriptors, dimensionality) is unspecified. If the matrix entries derive from descriptions that lexically overlap with the Reddit communities, the RSA alignment and residual after controls could be driven by shared surface features rather than expert structure; a concrete test (e.g., lexical overlap statistics between matrix and corpus) is needed.
Authors: The expert matrix was assembled from independent clinical symptom descriptors. The manuscript does not currently report its exact source texts, descriptors, or dimensionality, nor any lexical overlap statistics. We will expand the Methods section with these specifications and add a quantitative lexical overlap analysis (e.g., token overlap and embedding similarity) between the symptom descriptors and the Reddit corpus, reporting the results and discussing any implications for interpretation. revision: yes
-
Referee: [Results] Results (RSA correlations and scale/fine-tuning effects): No error bars, exact correlation values, statistical tests (e.g., permutation tests for RSA), data exclusion rules, or sample sizes per community are reported. This absence makes it impossible to assess whether the reported improvements from fine-tuning and scale are reliable or whether the 'measurable alignment' in the pretrained case exceeds what would be expected from the confound baselines alone.
Authors: We acknowledge the absence of these reporting elements. In the revised manuscript we will include exact Pearson r values with 95% confidence intervals, permutation-based significance tests for all RSA correlations (including against confound baselines), per-community sample sizes, and any data exclusion criteria applied during prototype construction. revision: yes
Circularity Check
No significant circularity; derivation relies on external expert matrix and independent controls.
full rationale
The paper constructs category prototypes from embedding spaces, computes representational dissimilarity matrices, and compares them via RSA to an external expert symptom matrix drawn from symptom relations. It further applies confound controls using standard external lexicons (VAD, LIWC) plus topic distributions. No equation or step defines a quantity in terms of itself, renames a fitted parameter as a prediction, or invokes self-citations for uniqueness. The alignment result is therefore not forced by construction from the input data alone and remains testable against the stated external reference.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Expert symptom matrix accurately represents true relational structure among symptoms
- domain assumption Category prototypes constructed from embeddings faithfully capture the relevant geometry
Reference graph
Works this paper leans on
-
[1]
Probing Classifiers: Promises, Shortcomings, and Advances
Probing Classifiers: Promises, Shortcomings, and Advances , author =. Computational Linguistics , volume =. 2022 , month = mar, publisher =. doi:10.1162/coli_a_00422 , url =
work page internal anchor Pith review doi:10.1162/coli_a_00422 2022
-
[2]
Frontiers in Neuroscience , volume =
The topology of representational geometry , author =. Frontiers in Neuroscience , volume =. 2025 , month = jun, pages =. doi:10.3389/fnins.2025.1597899 , url =
-
[3]
Language, Cognition and Neuroscience , volume =
Experientially-grounded and distributional semantic vectors uncover dissociable representations of conceptual categories , author =. Language, Cognition and Neuroscience , volume =. 2023 , month = jul, doi =
2023
-
[4]
What you can cram into a single
Conneau, Alexis and Kruszewski, German and Lample, Guillaume and Barrault, Lo. What you can cram into a single. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =. 2018 , month = jul, address =. doi:10.18653/v1/P18-1198 , url =
-
[5]
Brain and Language , volume =
Sentence-level embeddings reveal dissociable word- and sentence-level cortical representation across coarse- and fine-grained levels of meaning , author =. Brain and Language , volume =. 2024 , month = mar, doi =
2024
-
[6]
Nature Human Behaviour , volume =
Semantic projection recovers rich human knowledge of multiple object features from word embeddings , author =. Nature Human Behaviour , volume =. 2022 , month = apr, doi =
2022
-
[7]
Explaining Black Box Predictions and Unveiling Data Artifacts through Influence Functions , author =. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , pages =. 2020 , month = jul, address =. doi:10.18653/v1/2020.acl-main.492 , url =
-
[8]
Psychiatry Research , volume =
Navigating the semantic space: Unraveling the structure of meaning in psychosis using different computational language models , author =. Psychiatry Research , volume =. 2024 , month = mar, doi =
2024
-
[9]
Khattab, Omar and Zaharia, Matei , booktitle =. ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over. 2020 , address =. doi:10.1145/3397271.3401075 , url =
-
[10]
International Conference on Learning Representations (ICLR) , year =
Representational Similarity via Interpretable Visual Concepts , author =. International Conference on Learning Representations (ICLR) , year =
-
[11]
Journal of Medical Internet Research , year =
Natural Language Processing Reveals Vulnerable Mental Health Support Groups and Heightened Health Anxiety on Reddit During COVID-19: Observational Study , author =. Journal of Medical Internet Research , year =. doi:10.2196/22635 , url =
-
[12]
Scientific Reports , volume =
Large language models predict human sensory judgments across six modalities , author =. Scientific Reports , volume =. 2024 , doi =
2024
-
[13]
MTEB : Massive Text Embedding Benchmark
Muennighoff, Niklas and Tazi, Nouamane and Magne, Loic and Reimers, Nils , booktitle =. 2023 , month = may, address =. doi:10.18653/v1/2023.eacl-main.148 , url =
-
[14]
Investigating Semantic Subspaces of Transformer Sentence Embeddings through Linear Structural Probing , author =. Proceedings of the 6th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP , pages =. 2023 , month = dec, address =. doi:10.18653/v1/2023.blackboxnlp-1.11 , url =
-
[15]
2024 , eprint =
Turing Representational Similarity Analysis (RSA): A Flexible Method for Measuring Alignment Between Human and Artificial Intelligence , author =. 2024 , eprint =
2024
-
[16]
2022 , address =
Opitz, Juri and Frank, Anette , booktitle =. 2022 , address =
2022
-
[17]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , year =
Interpretable Text Embeddings and Text Similarity Explanation: A Survey , author =. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , year =
2025
-
[18]
Schizophrenia , volume =
Approximating the semantic space: word embedding techniques in psychiatric speech analysis , author =. Schizophrenia , volume =. 2024 , month = dec, doi =
2024
-
[19]
Sentence-
Reimers, Nils and Gurevych, Iryna , booktitle =. Sentence-. 2019 , month = nov, address =
2019
-
[20]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
Development of Cognitive Intelligence in Pre-trained Language Models , author =. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
2024
-
[21]
Proceedings of the 34th International Conference on Machine Learning , pages =
Axiomatic attribution for deep networks , author =. Proceedings of the 34th International Conference on Machine Learning , pages =. 2017 , address =
2017
-
[22]
How Well Do Deep Learning Models Capture Human Concepts? The Case of the Typicality Effect , author =. 2024 , journal =. doi:10.48550/arXiv.2405.16128 , url =. 2405.16128 , archivePrefix=
-
[23]
Nature Human Behaviour , volume =
Large language models without grounding recover non-sensorimotor but not sensorimotor features of human concepts , author =. Nature Human Behaviour , volume =. 2025 , month = jun, doi =
2025
-
[24]
and Artzi, Yoav , booktitle =
Zhang, Tianyi and Kishore, Varsha and Wu, Felix and Weinberger, Kilian Q. and Artzi, Yoav , booktitle =. 2020 , url =
2020
-
[25]
2013 , doi =
Diagnostic and Statistical Manual of Mental Disorders , edition =. 2013 , doi =
2013
-
[26]
and Quinn, Kevin and Sanislow, Charles and Wang, Philip , title =
Insel, Thomas and Cuthbert, Bruce and Garvey, Marjorie and Heinssen, Robert and Pine, Daniel S. and Quinn, Kevin and Sanislow, Charles and Wang, Philip , title =. American Journal of Psychiatry , volume =. 2010 , doi =
2010
-
[27]
, booktitle =
Mohammad, Saif M. , booktitle =. Obtaining Reliable Human Ratings of Valence, Arousal, and Dominance for 20,000. 2018 , address =
2018
-
[28]
and Ashokkumar, Ashwini and Seraj, Sarah and Pennebaker, James W
Boyd, Ryan L. and Ashokkumar, Ashwini and Seraj, Sarah and Pennebaker, James W. , institution =. The Development and Psychometric Properties of
-
[29]
Journal of the American Society for Information Science and Technology , volume =
A Survey of Modern Authorship Attribution Methods , author =. Journal of the American Society for Information Science and Technology , volume =
-
[30]
Transactions of the Association for Computational Linguistics , volume =
Topic Modeling in Embedding Spaces , author =. Transactions of the Association for Computational Linguistics , volume =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.