Multi-Turn Reasoning When Context Arrives in Pieces: Scalable Sharding and Memory-Augmented RL
Pith reviewed 2026-06-27 06:40 UTC · model grok-4.3
The pith
Training models to maintain compact rolling memory substantially reduces Lost in Conversation degradation in LLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
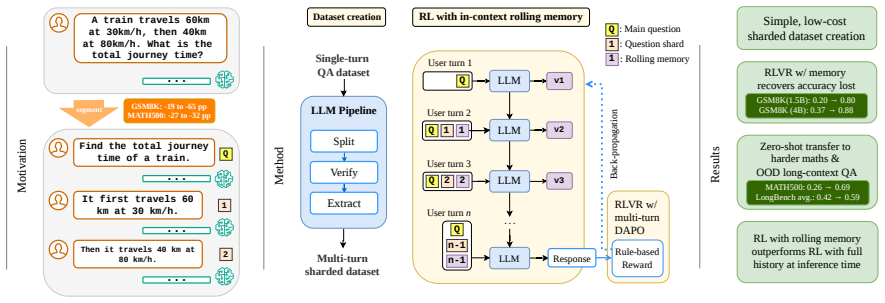
The paper claims that memory-augmented reinforcement learning on automatically sharded single-turn QA datasets yields policies that maintain a compact rolling memory, enabling more robust incremental reasoning when information is revealed piecemeal; these policies outperform standard full-context baselines on multi-turn tasks and retain the advantage even when full history is supplied at inference.
What carries the argument
The memory-augmented policy that learns via RL to compress conversation history into a compact rolling state rather than attending to the full sequence.
If this is right
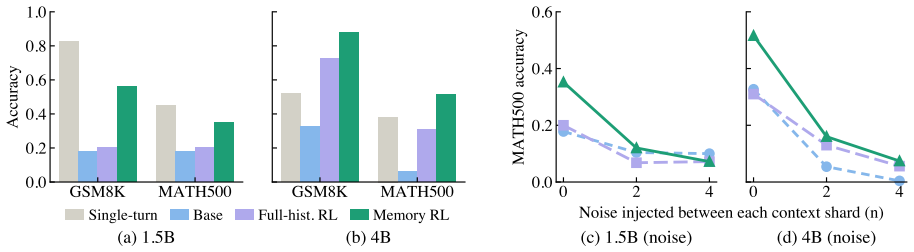
- Memory-trained models achieve higher accuracy on multi-turn episodes derived from GSM8K.
- The same models generalize zero-shot to harder math problems and out-of-domain long-context QA.
- Memory models surpass full-history baselines even when the baselines also receive the complete history at test time.
- Learning to compress history produces more robust incremental reasoning than full-context exposure alone.
Where Pith is reading between the lines
- The memory approach may reduce attention compute in extended conversations by avoiding growth in history length.
- The sharding technique could be applied to other sequential tasks where information arrives incrementally over time.
- Direct tests on human-collected conversations would clarify how well synthetic shards capture real interaction patterns.
Load-bearing premise
The automatically sharded multi-turn episodes match the statistical properties and difficulty of natural fragmented-information conversations well enough for the trained policies to transfer.
What would settle it
Measuring whether the accuracy gains persist when the same models are evaluated on a collection of real human multi-turn conversations that contain naturally fragmented information.
Figures


read the original abstract
When a user reveals task-critical information across several conversation turns, LLM accuracy drops by up to 65% despite full context availability. We show that this Lost in Conversation degradation can be substantially mitigated by training models to maintain a compact rolling memory instead of attending to a growing history. To make such training scalable, we introduce a low-cost sharding pipeline that converts single-turn QA datasets into multi-turn fragmented-information episodes, eliminating the need for hours of manual annotation. Training only on sharded GSM8K, our memory-augmented policy significantly improves multi-turn accuracy and generalises zero-shot to harder math and out-of-domain long-context QA. Moreover, memory-trained models outperform full-history baselines even when given the full history at test time, suggesting that learning to compress induces more robust incremental reasoning than full-context exposure alone.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that Lost in Conversation degradation in LLMs, where accuracy drops when task-critical information is revealed across multiple turns despite full context, can be mitigated by training models to maintain a compact rolling memory. A low-cost automatic sharding pipeline is introduced to convert single-turn QA datasets into multi-turn fragmented episodes, enabling scalable training on sharded GSM8K that leads to improved multi-turn accuracy, zero-shot generalization to harder math and out-of-domain long-context QA, and better performance than full-history baselines even with full context at test time.
Significance. If the empirical results hold and the sharded training distribution is representative, this approach could significantly advance the development of more robust conversational AI systems by inducing better incremental reasoning through memory compression rather than full context exposure, addressing a practical limitation in current LLMs without requiring extensive manual data annotation.
major comments (2)
- [Sharding Pipeline] The claim that policies trained on sharded episodes transfer to real user interactions relies on the synthetic episodes having similar statistical properties (fragmentation order, information dependency, difficulty ramp) to natural conversations. No quantitative validation of this match is provided, such as KL divergence on turn-wise information entropy or human preference ratings, which is load-bearing for the zero-shot generalization results.
- [Abstract and Results] The abstract states quantitative improvements, zero-shot generalization, and outperformance over baselines but supplies no specific numbers, baselines, error bars, ablation details, or statistical tests, preventing evaluation of the central claims from the provided text.
minor comments (1)
- [Abstract] Consider adding key quantitative results to the abstract to better support the claims made.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the sharding pipeline and abstract presentation. We address each major comment below, indicating planned changes where appropriate.
read point-by-point responses
-
Referee: [Sharding Pipeline] The claim that policies trained on sharded episodes transfer to real user interactions relies on the synthetic episodes having similar statistical properties (fragmentation order, information dependency, difficulty ramp) to natural conversations. No quantitative validation of this match is provided, such as KL divergence on turn-wise information entropy or human preference ratings, which is load-bearing for the zero-shot generalization results.
Authors: We acknowledge that the manuscript does not include direct quantitative metrics (e.g., KL divergence on turn-wise entropy or human ratings) comparing synthetic sharded episodes to natural conversations. The transfer claims rest on the observed zero-shot generalization to harder math and out-of-domain QA tasks. In revision we will expand the discussion section to explicitly address this gap, note the reliance on empirical generalization as indirect support, and outline the suggested metrics as directions for future validation work. revision: partial
-
Referee: [Abstract and Results] The abstract states quantitative improvements, zero-shot generalization, and outperformance over baselines but supplies no specific numbers, baselines, error bars, ablation details, or statistical tests, preventing evaluation of the central claims from the provided text.
Authors: We agree that the current abstract lacks the specific numerical results needed for immediate assessment. We will revise the abstract to include key quantitative outcomes (accuracy deltas, baseline comparisons, and any reported error bars or statistical details) while preserving conciseness. revision: yes
Circularity Check
No circularity; empirical training result with no definitional or fitted-input reductions
full rationale
The paper describes an empirical pipeline: an automatic sharding method converts single-turn QA into multi-turn episodes, models are trained with memory augmentation on sharded GSM8K, and performance is measured on held-out and out-of-domain tasks. No equations, parameters fitted to a subset then renamed as predictions, self-citation load-bearing premises, or ansatzes smuggled via prior work appear in the provided text. The central claim rests on observed accuracy gains and zero-shot generalization, which are falsifiable experimental outcomes rather than identities or statistical artifacts by construction. The unverified match between synthetic shards and natural conversations is a validity concern, not a circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Philippe Laban and Hiroaki Hayashi and Yingbo Zhou and Jennifer Neville , booktitle=
-
[2]
2025 , eprint=
MemAgent: Reshaping Long-Context LLM with Multi-Conv RL-based Memory Agent , author=. 2025 , eprint=
2025
-
[3]
2021 , eprint=
Training Verifiers to Solve Math Word Problems , author=. 2021 , eprint=
2021
-
[4]
NeurIPS , year=
Measuring Mathematical Problem Solving With the MATH Dataset , author=. NeurIPS , year=
-
[5]
arXiv preprint arXiv:2305.20050 , year=
Let's Verify Step by Step , author=. arXiv preprint arXiv:2305.20050 , year=
-
[6]
2024 , eprint=
LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding , author=. 2024 , eprint=
2024
-
[7]
2023 , eprint=
Lost in the Middle: How Language Models Use Long Contexts , author=. 2023 , eprint=
2023
-
[8]
2020 , eprint=
Constructing A Multi-hop QA Dataset for Comprehensive Evaluation of Reasoning Steps , author=. 2020 , eprint=
2020
-
[9]
2018 , eprint=
HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering , author=. 2018 , eprint=
2018
-
[10]
2021 , eprint=
A Dataset of Information-Seeking Questions and Answers Anchored in Research Papers , author=. 2021 , eprint=
2021
-
[11]
2017 , eprint=
TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension , author=. 2017 , eprint=
2017
-
[12]
2025 , eprint=
DAPO: An Open-Source LLM Reinforcement Learning System at Scale , author=. 2025 , eprint=
2025
-
[13]
2023 , eprint=
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena , author=. 2023 , eprint=
2023
-
[14]
2024 , eprint=
MT-Eval: A Multi-Turn Capabilities Evaluation Benchmark for Large Language Models , author=. 2024 , eprint=
2024
-
[15]
2026 , eprint=
Mitigating Lost in Multi-turn Conversation via Curriculum RL with Verifiable Accuracy and Abstention Rewards , author=. 2026 , eprint=
2026
-
[16]
2025 , eprint=
Understanding R1-Zero-Like Training: A Critical Perspective , author=. 2025 , eprint=
2025
-
[17]
2025 , eprint=
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning , author=. 2025 , eprint=
2025
-
[18]
2021 , eprint=
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks , author=. 2021 , eprint=
2021
-
[19]
2024 , eprint=
Retrieval-Augmented Generation for Large Language Models: A Survey , author=. 2024 , eprint=
2024
-
[20]
2025 , eprint=
VAPO: Efficient and Reliable Reinforcement Learning for Advanced Reasoning Tasks , author=. 2025 , eprint=
2025
-
[21]
2025 , eprint=
Reinforcement Learning with Verifiable Rewards Implicitly Incentivizes Correct Reasoning in Base LLMs , author=. 2025 , eprint=
2025
-
[22]
2023 , eprint=
Efficient Memory Management for Large Language Model Serving with PagedAttention , author=. 2023 , eprint=
2023
-
[23]
Sheng, Guangming and Zhang, Chi and Ye, Zilingfeng and Wu, Xibin and Zhang, Wang and Zhang, Ru and Peng, Yanghua and Lin, Haibin and Wu, Chuan , year=. HybridFlow: A Flexible and Efficient RLHF Framework , url=. doi:10.1145/3689031.3696075 , booktitle=
-
[24]
2016 , eprint=
Pointer Sentinel Mixture Models , author=. 2016 , eprint=
2016
-
[25]
2024 , eprint=
Qwen2.5-Math Technical Report: Toward Mathematical Expert Model via Self-Improvement , author=. 2024 , eprint=
2024
-
[26]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[27]
2017 , eprint=
Proximal Policy Optimization Algorithms , author=. 2017 , eprint=
2017
-
[28]
2024 , eprint=
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models , author=. 2024 , eprint=
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.