DiffRetriever: Parallel Representative Tokens for Retrieval with Diffusion Language Models
Pith reviewed 2026-05-11 01:38 UTC · model grok-4.3
The pith
Diffusion language models generate multiple representative tokens for retrieval in a single parallel pass, improving over single-token and autoregressive methods on BEIR-7 after fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DiffRetriever appends K masked positions to the input prompt of a diffusion language model and reads out all K representative tokens in one bidirectional forward pass, enabling parallel multi-token retrieval that improves substantially over single-token decoding on every tested diffusion backbone while autoregressive multi-token variants remain flat or degrade and incur K-dependent latency.
What carries the argument
Appending K masked positions to prompts for simultaneous bidirectional decoding of multiple representative tokens in diffusion language models.
Load-bearing premise
The observed retrieval gains come from the parallel multi-token mechanism enabled by diffusion rather than from backbone capacity, fine-tuning procedure, or other unstated implementation differences.
What would settle it
A side-by-side experiment on identical diffusion and autoregressive backbones, with matched parameter counts, identical supervised fine-tuning schedules, and the same number of representative tokens, that shows no performance difference between parallel and sequential multi-token decoding.
Figures








read the original abstract
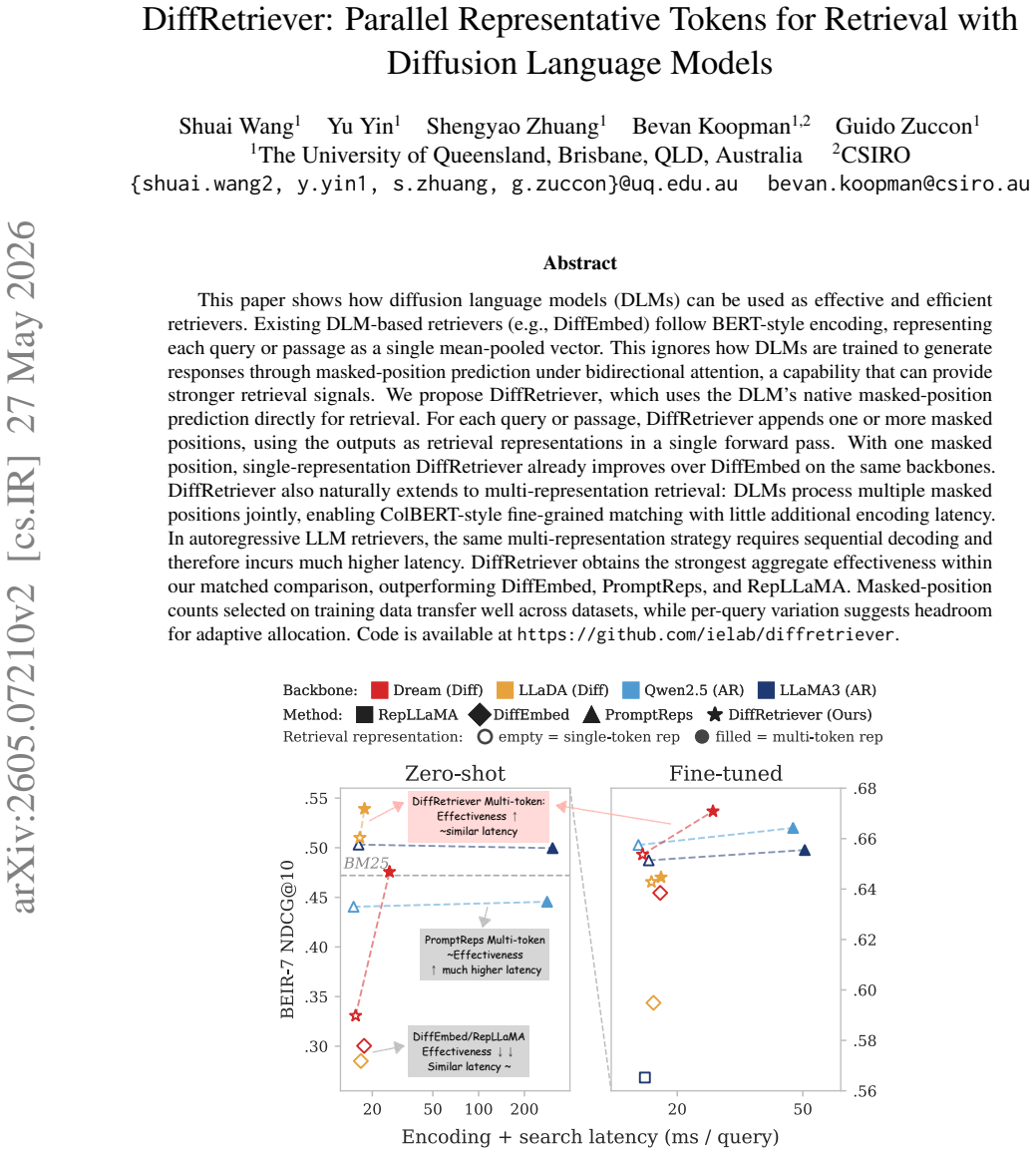
This paper shows how diffusion language models (DLMs) can be used as effective and efficient retrievers. Existing DLM-based retrievers (e.g., DiffEmbed) follow BERT-style encoding, representing each query or passage as a single mean-pooled vector. This ignores how DLMs are trained to generate responses through masked-position prediction under bidirectional attention, a capability that can provide stronger retrieval signals. We propose DiffRetriever, which uses the DLM's native masked-position prediction directly for retrieval. For each query or passage, DiffRetriever appends one or more masked positions, using the outputs as retrieval representations in a single forward pass. With one masked position, single-representation DiffRetriever already improves over DiffEmbed on the same backbones. DiffRetriever also naturally extends to multi-representation retrieval: DLMs process multiple masked positions jointly, enabling ColBERT-style fine-grained matching with little additional encoding latency. In autoregressive LLM retrievers, the same multi-representation strategy requires sequential decoding and therefore incurs much higher latency. DiffRetriever obtains the strongest aggregate effectiveness within our matched comparison, outperforming DiffEmbed, PromptReps, and RepLLaMA. Masked-position counts selected on training data transfer well across datasets, while per-query variation suggests headroom for adaptive allocation. Code is available at https://github.com/ielab/diffretriever.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DiffRetriever, a representative-token retriever for diffusion language models that appends K masked positions to a prompt and decodes all K tokens in one bidirectional forward pass. It claims that this parallel multi-token approach yields consistent gains over single-token decoding on every tested diffusion backbone, while autoregressive multi-token variants show no improvement and incur K-dependent latency; after supervised fine-tuning, DiffRetriever on the Dream backbone outperforms PromptReps, the same-backbone DiffEmbed encoder baseline, and contrastively fine-tuned RepLLaMA on BEIR-7, with a frozen-model oracle exceeding contrastive fine-tuning at fixed budget.
Significance. If the empirical gains are attributable to the parallel multi-token mechanism rather than confounding factors, the work provides concrete evidence that diffusion LMs can overcome the sequential-generation bottleneck that limits multi-representative retrieval in autoregressive models, while preserving latency independence from K. The oracle result on the frozen base model is a notable strength, as it supplies a falsifiable upper bound and points to adaptive budget selection as a concrete next step. Reproducible code is released, which strengthens verifiability.
major comments (3)
- [Abstract and §4] Abstract and §4 (Experiments): the headline claim that DiffRetriever on Dream is the strongest BEIR-7 retriever after SFT rests on comparisons whose causal attribution to the parallel K-token diffusion mechanism is not yet load-bearing. The manuscript does not report identical parameter counts, pre-training corpora, or exact SFT recipes (data, epochs, learning-rate schedule) for the RepLLaMA contrastive baseline versus the diffusion SFT runs; without these controls the performance delta cannot be isolated from backbone or training differences.
- [§4.2 and Table 2] §4.2 (Ablations) and Table 2: while multi-token diffusion is reported to improve over single-token on every backbone, the paper does not present an ablation that holds total compute or total representation dimensionality fixed when increasing K (e.g., by comparing K=4 at hidden size d versus K=1 at hidden size 4d). This leaves open whether the observed gains are due to parallelism per se or simply to increased representational capacity.
- [§3.2] §3.2 (Aggregation): the method for collapsing the K parallel tokens into a single retrieval score (or set of scores) is described only at a high level. If the aggregation involves learned parameters or additional fine-tuning, this must be stated explicitly so that readers can assess whether the reported gains are still “parameter-free” relative to the single-token baseline.
minor comments (2)
- [Figure 1 and §3.1] Figure 1 caption and §3.1: the notation for the masked positions (e.g., whether they are appended after the [EOS] token or replace existing tokens) is not fully consistent between text and diagram; a single clarifying sentence would remove ambiguity.
- [§4.3] §4.3 (Oracle analysis): the per-query oracle is an interesting result, but the manuscript does not report the distribution of optimal K per query or the correlation between optimal K and query difficulty; adding this would strengthen the motivation for future adaptive-budget work.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below, clarifying the scope of our claims, the design of our ablations, and the aggregation procedure. Where appropriate, we indicate revisions that will be incorporated in the next version of the manuscript.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): the headline claim that DiffRetriever on Dream is the strongest BEIR-7 retriever after SFT rests on comparisons whose causal attribution to the parallel K-token diffusion mechanism is not yet load-bearing. The manuscript does not report identical parameter counts, pre-training corpora, or exact SFT recipes (data, epochs, learning-rate schedule) for the RepLLaMA contrastive baseline versus the diffusion SFT runs; without these controls the performance delta cannot be isolated from backbone or training differences.
Authors: We agree that cross-family comparisons to RepLLaMA cannot fully isolate the contribution of the parallel diffusion mechanism from differences in pre-training data and contrastive versus supervised fine-tuning recipes. Our primary evidence for the value of parallel multi-token decoding is therefore the within-family comparisons on the same Dream (and other diffusion) backbones: DiffRetriever consistently outperforms both the single-token diffusion baseline and the DiffEmbed encoder baseline under identical SFT conditions. In the revised manuscript we will add an explicit subsection in §4 detailing the SFT data, epochs, learning-rate schedule, and batch size used for all diffusion runs, and we will qualify the headline claim to emphasize that the strongest result is obtained by applying the parallel mechanism to a diffusion backbone rather than claiming strict superiority over every possible autoregressive training recipe. revision: partial
-
Referee: [§4.2 and Table 2] §4.2 (Ablations) and Table 2: while multi-token diffusion is reported to improve over single-token on every backbone, the paper does not present an ablation that holds total compute or total representation dimensionality fixed when increasing K (e.g., by comparing K=4 at hidden size d versus K=1 at hidden size 4d). This leaves open whether the observed gains are due to parallelism per se or simply to increased representational capacity.
Authors: The ablations in §4.2 hold model architecture (including hidden dimension d) fixed while varying only K; this isolates the effect of parallel decoding at constant per-token capacity and constant forward-pass compute. The suggested capacity-matched ablation (K=1 with 4d hidden size) would require retraining models with altered architecture and is outside the scope of the present study. The practical contribution of DiffRetriever is precisely that K can be increased without any increase in inference latency or model size, a property that cannot be replicated by simply widening a single-token model. We will add a short discussion paragraph in the revised §4.2 that explicitly contrasts the two forms of capacity increase and reiterates that all reported gains occur at fixed hidden dimension. revision: partial
-
Referee: [§3.2] §3.2 (Aggregation): the method for collapsing the K parallel tokens into a single retrieval score (or set of scores) is described only at a high level. If the aggregation involves learned parameters or additional fine-tuning, this must be stated explicitly so that readers can assess whether the reported gains are still “parameter-free” relative to the single-token baseline.
Authors: The aggregation step in §3.2 consists of mean-pooling the K decoded token embeddings to obtain the final dense representation; the same mean-pooling is applied to the single-token case (trivially). No learned parameters, projection layers, or additional fine-tuning are introduced by the aggregation. We will revise the text of §3.2 to state this procedure explicitly, including the mathematical definition of the pooled vector, thereby confirming that the multi-token gains remain parameter-free relative to the single-token baseline. revision: yes
Circularity Check
No circularity: empirical method and benchmark comparisons
full rationale
The paper proposes DiffRetriever, a multi-token retrieval approach for diffusion LMs that appends K masked positions and decodes in one bidirectional pass. All central claims (multi-token gains on diffusion backbones but not AR, and top BEIR-7 rank after SFT) are supported by direct experimental comparisons to external baselines (PromptReps, DiffEmbed on same backbones, RepLLaMA). No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text; the work is self-contained against external benchmarks and code release.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.