Embedding Projection for Targeted Cross-Lingual Sentiment: Model Comparisons and a Real-World Study
Pith reviewed 2026-05-25 17:49 UTC · model grok-4.3
The pith
Jointly optimizing bilingual embeddings for semantics and sentiment enables stronger cross-lingual transfer on targeted sentiment tasks than other projection methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
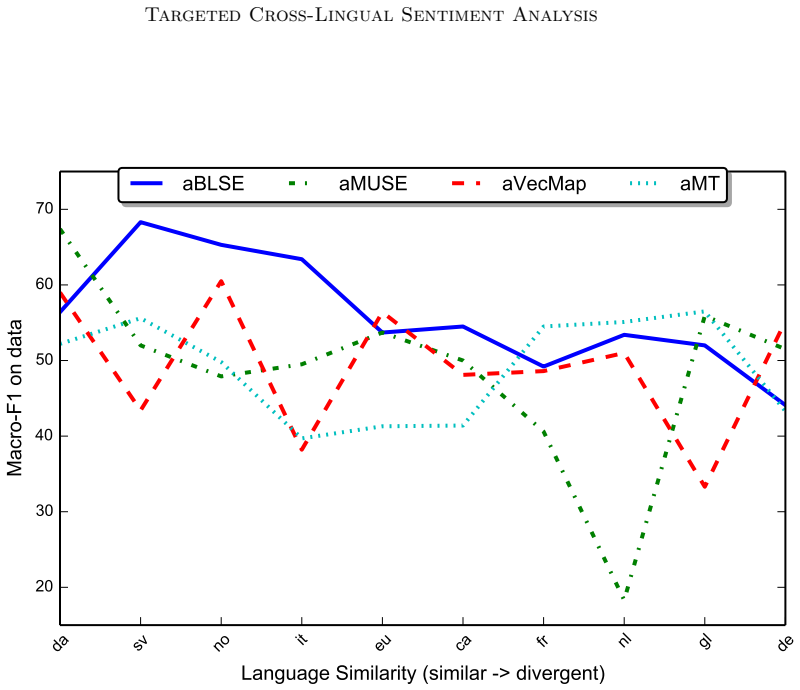
A model that incorporates sentiment information into bilingual distributional representations by jointly optimizing them for semantics and sentiment achieves state-of-the-art performance at sentence-level sentiment analysis when combined with machine translation and outperforms other projection-based bilingual embedding methods on binary targeted sentiment tasks across multiple domains.
What carries the argument
Sentiment-augmented bilingual embedding projection obtained by joint optimization of semantic and sentiment objectives.
If this is right
- Sentence-level cross-lingual sentiment reaches state-of-the-art results when the embeddings are used with machine translation.
- The same embeddings outperform other projection methods on binary targeted sentiment tasks across several domains.
- The quantity of unlabeled monolingual data in the target language has surprisingly little effect on final sentiment accuracy.
- Projection works better when the source and target languages are similar.
- Performance drops when source and target data come from different domains.
Where Pith is reading between the lines
- Creating labeled resources for languages that are dissimilar to English would yield higher returns than adding more data for languages already close to English.
- Source-language datasets should cover multiple domains if they are intended for cross-lingual projection.
- The same joint-optimization idea could be tested on other sequence-labeling tasks that currently rely on projection, such as named-entity recognition.
Load-bearing premise
That the joint optimization of embeddings for semantics plus sentiment will produce representations that transfer reliably to targeted sentiment classification in languages that have no labeled data of their own.
What would settle it
A controlled test on a new source-target language pair that is both linguistically dissimilar and drawn from mismatched domains, measuring whether the jointly optimized embeddings still beat standard projection baselines on binary targeted sentiment accuracy.
Figures












read the original abstract
Sentiment analysis benefits from large, hand-annotated resources in order to train and test machine learning models, which are often data hungry. While some languages, e.g., English, have a vast array of these resources, most under-resourced languages do not, especially for fine-grained sentiment tasks, such as aspect-level or targeted sentiment analysis. To improve this situation, we propose a cross-lingual approach to sentiment analysis that is applicable to under-resourced languages and takes into account target-level information. This model incorporates sentiment information into bilingual distributional representations, by jointly optimizing them for semantics and sentiment, showing state-of-the-art performance at sentence-level when combined with machine translation. The adaptation to targeted sentiment analysis on multiple domains shows that our model outperforms other projection-based bilingual embedding methods on binary targeted sentiment tasks. Our analysis on ten languages demonstrates that the amount of unlabeled monolingual data has surprisingly little effect on the sentiment results. As expected, the choice of annotated source language for projection to a target leads to better results for source-target language pairs which are similar. Therefore, our results suggest that more efforts should be spent on the creation of resources for less similar languages to those which are resource-rich already. Finally, a domain mismatch leads to a decreased performance. This suggests resources in any language should ideally cover varieties of domains.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a cross-lingual sentiment analysis method that jointly optimizes bilingual distributional embeddings for both semantics and sentiment. It reports state-of-the-art sentence-level performance when combined with machine translation and outperformance over other projection-based bilingual embedding methods on binary targeted sentiment tasks across multiple domains. Analysis across ten languages finds little effect from the volume of unlabeled monolingual data, better results for similar source-target language pairs, and degraded performance under domain mismatch.
Significance. If the gains from joint optimization can be shown to hold after controlling for language and domain similarity, the approach would offer a useful route for targeted sentiment analysis in under-resourced languages. The reported insensitivity to monolingual data volume is a noteworthy empirical observation that could shift priorities in resource creation. The dependence on source-target similarity, however, limits the strength of the generalizability claim.
major comments (2)
- [Abstract] Abstract: the central empirical claims of SOTA sentence-level performance and outperformance on targeted binary tasks are stated without any equations, training details, statistical tests, or error bars, so the soundness of the results cannot be assessed from the provided description.
- [Analysis on ten languages] Analysis on ten languages: the observation that results improve for similar source-target pairs and degrade under domain mismatch directly challenges the assumption that gains are driven by the proposed joint optimization rather than post-hoc selection of favorable pairs; without a pre-specified protocol or exhaustive cross-pair reporting, the outperformance claim is at risk of being an artifact of similarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and clarify how the empirical claims are supported in the full paper while acknowledging areas where additional clarification can strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claims of SOTA sentence-level performance and outperformance on targeted binary tasks are stated without any equations, training details, statistical tests, or error bars, so the soundness of the results cannot be assessed from the provided description.
Authors: We agree that the abstract is concise by design and omits technical details such as equations, training hyperparameters, and statistical tests. These elements are fully detailed in the manuscript: the joint optimization objective is formalized in Section 3, the experimental protocol and baselines in Section 4, and the results (including comparisons, significance testing where applicable, and error analysis) in Section 5. The abstract's role is to summarize the contribution at a high level; readers are directed to the body for reproducibility. We can revise the abstract to briefly reference the joint semantic-sentiment objective and note that full statistical details appear in the paper. revision: partial
-
Referee: [Analysis on ten languages] Analysis on ten languages: the observation that results improve for similar source-target pairs and degrade under domain mismatch directly challenges the assumption that gains are driven by the proposed joint optimization rather than post-hoc selection of favorable pairs; without a pre-specified protocol or exhaustive cross-pair reporting, the outperformance claim is at risk of being an artifact of similarity.
Authors: The outperformance claims are based on head-to-head comparisons against prior projection baselines using identical language pairs, domains, and evaluation protocols; the joint model shows consistent relative gains on the same test conditions. The ten-language analysis is presented separately as an exploratory study of external factors (monolingual data volume, language similarity, domain match), not as the primary evidence for the method's superiority. We report results across a range of similarity levels rather than only favorable pairs, and the paper explicitly notes that absolute performance drops for dissimilar languages while the relative advantage over baselines remains. A pre-specified exhaustive cross-pair protocol was not part of the original design, but the reported pairs were chosen to cover multiple domains and similarity degrees; we can add a clarifying paragraph in the analysis section to emphasize that relative gains hold after controlling for pair selection. revision: partial
Circularity Check
No circularity; empirical comparisons independent of inputs
full rationale
The paper describes an empirical method for jointly optimizing bilingual embeddings for semantics and sentiment, then evaluates via machine translation and projection on targeted sentiment tasks across languages and domains. No equations, derivations, or fitted parameters are presented that reduce to self-definition or self-citation by construction. Results are framed as experimental outcomes compared to baselines, with explicit discussion of domain and language similarity effects. This matches the default case of a self-contained empirical study with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Bilingual word embeddings can be aligned across languages while preserving both semantic and sentiment properties.
Reference graph
Works this paper leans on
-
[1]
Agerri, R., Bermudez, J., & Rigau, G. (2014). Ixa pipeline: Efficient and ready to use multilingual nlp tools. In Proceedings of the Ninth International Conference on Lan- guage Resources and Evaluation (LREC’14) (1.0 edition)., pp. 3823–3828. European Language Resources Association (ELRA). Agerri, R., Cuadros, M., Gaines, S., & Rigau, G. (2013). OpeNER: Op...
work page 2014
-
[2]
42 Targeted Cross-Lingual Sentiment Analysis Asch, S. E. (1955). Opinions and social pressure. Scientific American, 193(5), 31–35. Atrio, `A. R., Badia, T., & Barnes, J. (2019). On the effect of word order in cross-lingual sentiment analysis. Procesamiento del Lenguaje Natural, 63(0), To Appear. Bakliwal, A., Foster, J., van der Puil, J., O’Brien, R., Touns...
work page 1955
-
[3]
, pp. 28–36. Banea, C., Mihalcea, R., & Wiebe, J. (2013). Porting multilingual subjectivity resources across languages. IEEE Transactions on Affective Computing , 99(PrePrints). Banea, C., Mihalcea, R., Wiebe, J., & Hassan, S. (2008). Multilingual subjectivity analysis using machine translation. In Proceedings of the 2008 Conference on Empirical Meth- ods ...
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[4]
Cotterell, R., Mielke, S. J., Eisner, J., & Roark, B. (2018). Are all languages equally hard to language-model?. In Proceedings of the 2018 Conference of the North American Chap- ter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers) , pp. 536–541. Association for Computational Linguistics. Das, A., Goll...
work page 2018
-
[5]
Fang, A. C., & Cao, J. (2010). Enhanced genre classification through linguistically fine- grained pos tags. In Proceedings of the 24th Pacific Asia Conference on Language, Information and Computation . Felbo, B., Mislove, A., Søgaard, A., Rahwan, I., & Lehmann, S. (2017). Using millions of emoji occurrences to learn any-domain representations for detecting s...
work page 2010
-
[6]
, pp. 168–177. Iyyer, M., Manjunatha, V., Boyd-Graber, J., & Daum´ e III, H. (2015). Deep unordered composition rivals syntactic methods for text classification. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th Inter- national Joint Conference on Natural Language Processing (Volume 1: Long Papers) , pp....
work page 2015
-
[7]
312–320, At- lanta, Georgia, USA
, pp. 312–320, At- lanta, Georgia, USA. Association for Computational Linguistics. Padr´ o, L., Collado, M., Reese, S., Lloberes, M., & Castell´ on, I. (2010). Freeling 2.1: Five years of open-source language processing tools. In Proceedings of 7th Language Re- sources and Evaluation Conference (LREC’10) , La Valletta, Malta. Pagolu, V. S., Reddy, K. N., ...
work page 2010
-
[8]
, pp. 486–495. Pontiki, M., Galanis, D., Pavlopoulos, J., Papageorgiou, H., Androutsopoulos, I., & Man- andhar, S. (2014). Semeval-2014 task 4: Aspect based sentiment analysis. In Proceed- ings of the 8th International Workshop on Semantic Evaluation (SemEval
work page 2014
-
[9]
, pp. 27–35. Prettenhofer, P., & Stein, B. (2011). Cross-lingual adaptation using structural correspon- dence learning. ACM Transactions on Intelligent Systems and Technology, 3(1), 1–22. Rasooli, M. S., Farra, N., Radeva, A., Yu, T., & McKeown, K. (2017). Cross-lingual senti- ment transfer with limited resources. Machine Translation, 32(1-2), 143–165. Re...
work page 2011
-
[10]
Tang, D., Wei, F., Qin, B., Yang, N., Liu, T., & Zhou, M. (2016). Sentiment embeddings with applications to sentiment analysis. IEEE Trans. on Knowl. and Data Eng. , 28(2), 496–509. Tang, D., Wei, F., Yang, N., Zhou, M., Liu, T., & Qin, B. (2014). Learning sentiment- specific word embedding for twitter sentiment classification. In Proceedings of the 52nd An...
work page 2016
-
[11]
Association for Computational Linguistics. Welch, C., & Mihalcea, R. (2016). Targeted sentiment to understand student comments. In Proceedings of COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers, pp. 2471–2481. The COLING 2016 Organizing Com- mittee. Wiebe, J., Wilson, T., & Cardie, C. (2005). Annotating expres...
work page 2016
-
[12]
, pp. 993–1000. Coling 2008 Organizing Committee. Xiao, M., & Guo, Y. (2012). Multi-view adaboost for multilingual subjectivity analysis. In Proceedings of COLING 2012, pp. 2851–2866. Xue, W., & Li, T. (2018). Aspect based sentiment analysis with gated convolutional net- works. In Proceedings of the 56th Annual Meeting of the Association for Computational...
work page 2008
-
[13]
Zhou, X., Wan, X., & Xiao, J. (2012). Cross-language opinion target extraction in review texts. In IEEE 12th International Conference on Data Mining , pp. 1200 – 1205, Brussels, Belgium. Zhu, X., Guo, H., Mohammad, S., & Kiritchenko, S. (2014). An empirical study on the effect of negation words on sentiment. In Proceedings of the 52nd Annual Meeting of the...
work page 2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.