Visored: A Controlled-Natural-Language Prover for LLM-Generated Mathematics
Pith reviewed 2026-06-26 22:21 UTC · model grok-4.3
The pith
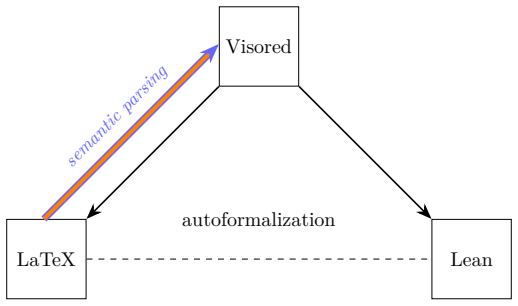
Visored lets LLMs write proofs in controlled natural language that convert automatically to verified Lean files.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
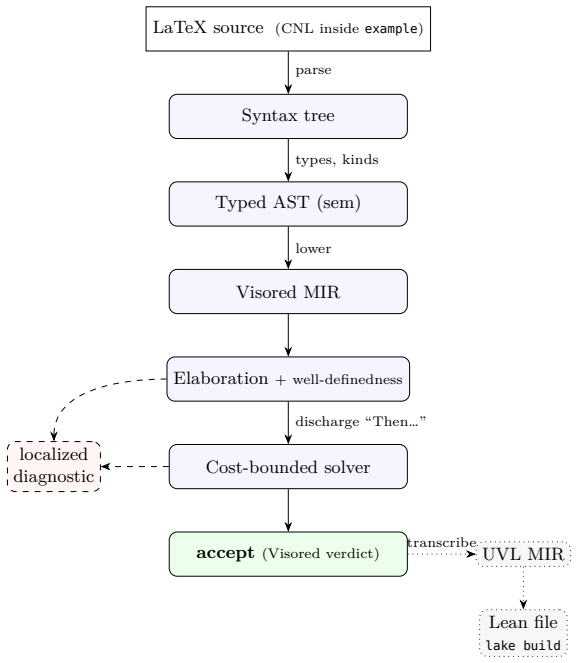
Visored is built around a controlled-natural-language surface and a rule-driven automation layer that together let an LLM-generated proof be accepted and then exported as a fully checked Lean file; the same LLMs succeed at using the system on miniF2F problems even when given no examples of the prover's own syntax or commands.
What carries the argument
The combination of a natural-language-like surface syntax with a rule-driven automation layer that closes omitted routine steps.
If this is right
- LLMs can produce formally verified mathematics without any training on the prover's command language.
- Proofs written in the natural-language surface can be turned into Lean-verifiable artifacts automatically.
- Routine textbook omissions no longer require the user to supply every detail by hand.
Where Pith is reading between the lines
- The same surface might serve as a bridge between informal mathematical writing and multiple formal back-ends beyond Lean.
- If the automation layer scales, it could lower the cost of checking LLM outputs on larger problem sets than miniF2F.
- Success without prover-specific data suggests the natural-language surface already aligns with patterns LLMs have learned from ordinary text.
Load-bearing premise
The automation layer can close routine steps correctly without introducing undetected errors or forcing users to supply manual fixes.
What would settle it
An instance on miniF2F where the automation layer produces an incorrect Lean file that passes the prover's internal checks yet fails when re-verified in Lean itself.
Figures
read the original abstract
We present a dependent-type-based prover designed around the way LLMs (and humans) tend to write mathematics, complementing existing systems such as Lean and Rocq. Its core design choices are a surface that imitates mathematical natural language and a rule-driven automation layer that closes the routine steps a textbook would omit, so that an accepted proof can be re-emitted as a checked Lean file. Early experiments suggest that, even without any prover-specific training data, LLMs can learn to use it effectively on the miniF2F benchmark. Lean output excerpts: https://github.com/xiyuzhai-husky-lang/visored/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Visored, a dependent-type-based prover featuring a controlled natural language surface that mimics textbook mathematical writing and a rule-driven automation layer to close routine steps typically omitted in informal proofs. Accepted proofs are re-emitted as Lean-checked files. The central claim, based on early experiments, is that LLMs can learn to use Visored effectively on the miniF2F benchmark without any prover-specific training data.
Significance. If the automation layer proves reliable and the experimental results hold under scrutiny, the work could offer a practical bridge between LLM-generated informal mathematics and formal verification, reducing the syntactic burden of systems like Lean while preserving machine-checkable output.
major comments (2)
- [Abstract and §4] Abstract and §4 (Experiments): the claim that LLMs 'can learn to use it effectively' on miniF2F is load-bearing but unsupported by any reported success rates, automation closure percentages, failure modes, or direct comparison to baseline Lean generation; without these metrics the central claim cannot be evaluated.
- [§3.2] §3.2 (Automation layer): the rule-driven component is asserted to close textbook-omitted steps autonomously, yet no description of the rule set, termination guarantees, or handling of ambiguous natural-language steps is given; this directly affects whether the system reduces LLM burden or merely shifts it to post-hoc fixes.
minor comments (2)
- The GitHub link is referenced but the manuscript contains no analysis or statistics drawn from the provided Lean excerpts.
- [§2] Notation for the dependent-type surface language is introduced without a small self-contained example that a reader could type-check mentally.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): the claim that LLMs 'can learn to use it effectively' on miniF2F is load-bearing but unsupported by any reported success rates, automation closure percentages, failure modes, or direct comparison to baseline Lean generation; without these metrics the central claim cannot be evaluated.
Authors: We agree that the central claim requires quantitative support to be fully evaluable. The current experiments are preliminary and demonstrate feasibility via successful Lean outputs on selected miniF2F problems without prover-specific training. However, aggregate metrics such as success rates, automation closure percentages, failure modes, and baseline comparisons are not reported. We will revise the abstract and §4 to include these metrics along with a direct comparison to baseline Lean generation. revision: yes
-
Referee: [§3.2] §3.2 (Automation layer): the rule-driven component is asserted to close textbook-omitted steps autonomously, yet no description of the rule set, termination guarantees, or handling of ambiguous natural-language steps is given; this directly affects whether the system reduces LLM burden or merely shifts it to post-hoc fixes.
Authors: We acknowledge that §3.2 provides only a high-level description of the automation layer. We will expand this section with a concrete description of the rule set (including examples for common omissions such as variable binding and simple inferences), a termination argument based on strictly decreasing proof obligation size, and an explanation of how ambiguous natural-language steps are handled (by requiring explicit LLM phrasing or falling back to user clarification). This will clarify that the design reduces rather than shifts the LLM burden. revision: yes
Circularity Check
No circularity: system description and experimental suggestion contain no fitted predictions or self-referential derivations
full rationale
The paper describes a controlled-natural-language prover with a rule-driven automation layer and reports that early experiments suggest LLMs can use it on miniF2F without prover-specific training data. No equations, parameters, or quantitative predictions appear that could reduce to fitted inputs by construction. No self-citations, uniqueness theorems, or ansatzes are invoked in the provided text to support load-bearing claims. The central suggestion rests on experimental outcomes rather than any definitional or self-referential chain, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Visored prover
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Claude Code: An agentic coding tool that lives in your terminal
Anthropic. Claude Code: An agentic coding tool that lives in your terminal. https://github. com/anthropics/claude-code, 2025
2025
-
[2]
Cursor: The AI code editor
Anysphere. Cursor: The AI code editor. https://cursor.com/, 2025
2025
-
[3]
Jiang, Jia Deng, Stella Biderman, and Sean Welleck
Zhangir Azerbayev, Hailey Schoelkopf, Keiran Paster, Marco Dos Santos, Stephen McAleer, Al- bert Q. Jiang, Jia Deng, Stella Biderman, and Sean Welleck. Llemma: An open language model for mathematics. In International Conference on Learning Representations (ICLR) , 2024
2024
-
[4]
Division by zero in type theory: a F AQ
Kevin Buzzard. Division by zero in type theory: a F AQ. Xena Project blog, https:// xenaproject.wordpress.com/2020/07/05/division-by-zero-in-type-theory-a-faq/ , 2020
2020
-
[5]
The LLM era demands natural-language-aligned theo- rem provers for mathematics
Qinxiang Cao, Lihan Xie, and Junchi Yan. The LLM era demands natural-language-aligned theo- rem provers for mathematics. In Proc. 1st ACM SIGPLAN International Workshop on Language Models and Programming Languages (LMPL ’25) , Singapore, 2025
2025
-
[6]
Seed-Prover: Deep and broad reasoning for automated theorem proving
Luoxin Chen et al. Seed-Prover: Deep and broad reasoning for automated theorem proving. arXiv preprint arXiv:2507.23726 , 2025. ByteDance Seed
arXiv 2025
-
[7]
Training verifiers to solve math word problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 , 2021
Pith/arXiv arXiv 2021
-
[8]
useful for writing readable ab- stracts
Adrian De Lon, Peter Koepke, and Anton Lorenzen. Interpreting mathematical texts in Naproche- SAD. In Intelligent Computer Mathematics (CICM) , 2020. Describes a generic parsing mechanism that generates Lean code from ForTheL statements; framed as “useful for writing readable ab- stracts” rather than as production-quality proof emission
2020
-
[9]
STP: Self-play LLM theorem provers with iterative conjecturing and proving
Kefan Dong and Tengyu Ma. STP: Self-play LLM theorem provers with iterative conjecturing and proving. arXiv preprint arXiv:2502.00212 , 2025
arXiv 2025
-
[10]
Mathematical exploration and discovery at scale
Bogdan Georgiev, Javier Gómez-Serrano, Terence Tao, and Adam Zsolt Wagner. Mathematical exploration and discovery at scale. arXiv preprint arXiv:2511.02864 , 2025
Pith/arXiv arXiv 2025
-
[11]
AI achieves silver-medal standard solving international mathematical olympiad problems
Google DeepMind. AI achieves silver-medal standard solving international mathematical olympiad problems. DeepMind Blog , 2024. AlphaProof and AlphaGeometry 2; full system paper later published in Nature (2025), https://www.nature.com/articles/s41586-025-09833-y
2024
-
[12]
Advanced version of Gemini with Deep Think of- ficially achieves gold-medal standard at the international mathemat- ical olympiad
Google DeepMind. Advanced version of Gemini with Deep Think of- ficially achieves gold-medal standard at the international mathemat- ical olympiad. DeepMind Blog, https://deepmind.google/blog/ advanced-version-of-gemini-with-deep-think-officially-achieves-gold-medal-standard-at-the-international-mathematical-olympiad/ , 2025
2025
-
[13]
Measuring mathematical problem solving with the MATH dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the MATH dataset. In NeurIPS Datasets and Benchmarks Track , 2021
2021
-
[14]
AI just solved an 80-year-old ‘Erdős problem,’ and mathematicians are amazed
Joseph Howlett. AI just solved an 80-year-old ‘Erdős problem,’ and mathematicians are amazed. Scientific American , https://www.scientificamerican.com/article/ ai-just-solved-an-80-year-old-erdos-problem-and-mathematicians-are-amazed/ ,
-
[15]
Gowers’s recommendation for Annals of Math- ematics reported by Wells, https://www.technology.org/2026/05/21/ openai-erdos-unit-distance-proof-second-attempt/
May 21, 2026. Gowers’s recommendation for Annals of Math- ematics reported by Wells, https://www.technology.org/2026/05/21/ openai-erdos-unit-distance-proof-second-attempt/
2026
-
[16]
A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions
Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qianglong Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, and Ting Liu. A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions. ACM Transactions on Information Systems , 2023. 10
2023
-
[17]
proof generation was the most challenging aspect
Mikoláš Janota and Mirek Olšák. LLM2SMT: Building an SMT solver with zero human-written code. arXiv preprint arXiv:2603.06931 , 2026. Conducted entirely inside Claude Code with the Claude Sonnet 4.6 model; reports that “proof generation was the most challenging aspect”, with Lean proof emission requiring significant human guidance and still failing on a n...
arXiv 2026
-
[18]
Survey of hallucination in natural language generation
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. Survey of hallucination in natural language generation. ACM Computing Surveys , 55(12):Article 248, 2023
2023
-
[19]
Jiang, Sean Welleck, Jin Peng Zhou, Wenda Li, Jiacheng Liu, Mateja Jamnik, Timothée Lacroix, Yuhuai Wu, and Guillaume Lample
Albert Q. Jiang, Sean Welleck, Jin Peng Zhou, Wenda Li, Jiacheng Liu, Mateja Jamnik, Timothée Lacroix, Yuhuai Wu, and Guillaume Lample. Draft, sketch, and prove: Guiding formal theorem provers with informal proofs. In International Conference on Learning Representations (ICLR) , 2023
2023
-
[20]
Towards solving the Gilbert-Pollak conjecture via large language models
Yisi Ke, Tianyu Huang, Yankai Shu, Di He, Jingchu Gai, and Liwei Wang. Towards solving the Gilbert-Pollak conjecture via large language models. arXiv preprint arXiv:2601.22365 , 2026
Pith/arXiv arXiv 2026
-
[21]
Solving quantitative reasoning problems with lan- guage models
Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, Yuhuai Wu, Behnam Neyshabur, Guy Gur-Ari, and Vedant Misra. Solving quantitative reasoning problems with lan- guage models. In Advances in Neural Information Processing Systems (NeurIPS) , 2022
2022
-
[22]
Goedel-Prover: A frontier model for open-source automated theorem proving
Yong Lin, Shange Tang, Bohan Lyu, Jiayun Wu, Hongzhou Lin, Kaiyu Yang, Jia Li, Mengzhou Xia, Danqi Chen, Sanjeev Arora, and Chi Jin. Goedel-Prover: A frontier model for open-source automated theorem proving. arXiv preprint arXiv:2502.07640 , 2025
arXiv 2025
-
[23]
Yong Lin, Shange Tang, Bohan Lyu, Ziran Yang, Jui-Hui Chung, Haoyu Zhao, Lai Jiang, Yihan Geng, Jiawei Ge, Jingruo Sun, Jiayun Wu, Jiri Gesi, Ximing Lu, David Acuna, Kaiyu Yang, Hongzhou Lin, Yejin Choi, Danqi Chen, Sanjeev Arora, and Chi Jin. Goedel-Prover-V2: Scal- ing formal theorem proving with scaffolded data synthesis and self-correction. arXiv prep...
Pith/arXiv arXiv 2025
-
[24]
Le Miz s’approche: Informalization and autoformalization with Mizar and Naproche
Adrian De Lon et al. Le Miz s’approche: Informalization and autoformalization with Mizar and Naproche. In Conference on Artificial Intelligence and Theorem Proving (AITP) , 2025. Slides: http://aitp-conference.org/2025/slides/ADL.pdf
2025
-
[25]
The Isabelle/Naproche natural language proof assistant
Adrian De Lon, Peter Koepke, Anton Lorenzen, Adrian Marti, Marcel Schütz, and Makarius Wenzel. The Isabelle/Naproche natural language proof assistant. In Conference on Automated Deduction (CADE) , 2021
2021
-
[26]
Verbose Lean 4: Tactics and commands for Lean in a controlled natural lan- guage
Patrick Massot. Verbose Lean 4: Tactics and commands for Lean in a controlled natural lan- guage. https://github.com/PatrickMassot/verbose-lean4, 2024. Software; ITP 2024 pa- per: https://drops.dagstuhl.de/entities/document/10.4230/LIPIcs.ITP.2024.27
-
[27]
AlphaEvolve: A coding agent for scientific and algorithmic discovery
Alexander Novikov et al. AlphaEvolve: A coding agent for scientific and algorithmic discovery. arXiv preprint arXiv:2506.13131 , 2025. Google DeepMind
Pith/arXiv arXiv 2025
-
[28]
Codex CLI: A lightweight coding agent that runs in your terminal
OpenAI. Codex CLI: A lightweight coding agent that runs in your terminal. https://github. com/openai/codex, 2025
2025
-
[29]
Rushby, and Natarajan Shankar
Sam Owre, John M. Rushby, and Natarajan Shankar. PVS: A prototype verification system. In Conference on Automated Deduction (CADE) , 1992
1992
-
[30]
GFLean: An autoformalisation framework for Lean via GF
Shashank Pathak. GFLean: An autoformalisation framework for Lean via GF. arXiv preprint arXiv:2404.01234, 2024
arXiv 2024
-
[31]
Lawrence C. Paulson. The de Bruijn criterion vs the LCF architecture. https:// lawrencecpaulson.github.io/2022/01/05/LCF.html, 2022
2022
-
[32]
The de Bruijn criterion
PLS Lab. The de Bruijn criterion. https://www.pls-lab.org/en/de_Bruijn_criterion,
-
[33]
Small, auditable kernels for proof assistants. 11
-
[34]
Z. Z. Ren et al. DeepSeek-Prover-V2: Advancing formal mathematical reasoning via reinforcement learning for subgoal decomposition. arXiv preprint arXiv:2504.21801 , 2025
Pith/arXiv arXiv 2025
-
[35]
Subtypes for specifications: Predicate subtyping in PVS
John Rushby, Sam Owre, and Natarajan Shankar. Subtypes for specifications: Predicate subtyping in PVS. IEEE Transactions on Software Engineering , 24(9):709–720, 1998
1998
-
[36]
PVS language reference: Types and TCC generation
SRI-CSL. PVS language reference: Types and TCC generation. https://github.com/SRI-CSL/ PVS/blob/master/doc/language/types.tex, 2024. Documents context-propagation rules for TCCs through AND, OR, IMPLIES, and IF-THEN-ELSE
2024
-
[37]
Machine-assisted proof
Terence Tao. Machine-assisted proof. Notices of the American Mathematical Society , 72(1):6–16, 2025
2025
-
[38]
The story of Erdős problem #1026
Terence Tao. The story of Erdős problem #1026. Blog post on What’s new , https://terrytao. wordpress.com/2025/12/08/the-story-of-erdos-problem-126/ , 2025. December 8, 2025
2025
-
[39]
AI is ready for primetime in math and theoretical physics
Terence Tao. AI is ready for primetime in math and theoretical physics. Ope- nAI Academy blog interview, https://academy.openai.com/public/blogs/ terence-tao-ai-is-ready-for-primetime-in-math-and-theoretical-physics-2026-03-06 ,
2026
-
[40]
The Mizar mathematical library and its mathematical vernacular
Andrzej Trybulec et al. The Mizar mathematical library and its mathematical vernacular. Journal of Formalized Mathematics , 1990. Mizar system; project page: https://mizar.uwb.edu.pl/
1990
-
[41]
Gomez, Łukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Advances in Neural Information Processing Systems (NeurIPS) , 2017
2017
-
[42]
Kimina-Prover preview: Towards large formal reasoning models with reinforcement learning
Haiming Wang, Mert Unsal, Xiaohan Lin, Mantas Baksys, Junqi Liu, et al. Kimina-Prover preview: Towards large formal reasoning models with reinforcement learning. arXiv preprint arXiv:2504.11354, 2025
Pith/arXiv arXiv 2025
-
[43]
ScaleAutoResearch-Ramsey: Finding new Ramsey bounds through scaling au- toresearch
Yiping Wang. ScaleAutoResearch-Ramsey: Finding new Ramsey bounds through scaling au- toresearch. GitHub repository, https://github.com/ypwang61/ScaleAutoResearch-Ramsey,
-
[44]
Reports R(3, 17) ≥ 93 (first improvement since 1994) and R(4, 15) ≥ 160
1994
-
[45]
ThetaEvolve: Test-time learning on open problems
Yiping Wang, Shao-Rong Su, Zhiyuan Zeng, Eva Xu, Liliang Ren, Xinyu Yang, Zeyi Huang, Xuehai He, Luyao Ma, Baolin Peng, Hao Cheng, Pengcheng He, Weizhu Chen, Shuohang Wang, Simon Shaolei Du, and Yelong Shen. ThetaEvolve: Test-time learning on open problems. arXiv preprint arXiv:2511.23473 , 2025
Pith/arXiv arXiv 2025
-
[46]
Waterproof: A plugin for the Coq/Rocq proof assistant for writing proofs in a style resembling handwritten mathematics
Jelle Wemmenhove, Cosmin Manea, Jim Portegies, et al. Waterproof: A plugin for the Coq/Rocq proof assistant for writing proofs in a style resembling handwritten mathematics. https:// github.com/impermeable/coq-waterproof, 2024. Software
2024
-
[47]
Autoformalization in the era of large language models: A survey
Ke Weng, Lun Du, Sirui Li, Wangyue Lu, Haozhe Sun, Hengyu Liu, and Tiancheng Zhang. Autoformalization in the era of large language models: A survey. arXiv preprint arXiv:2505.23486, 2025
arXiv 2025
-
[48]
Integration of controlled natural language in formal mathematics systems
EuroProofNet WG5. Integration of controlled natural language in formal mathematics systems. Deliverable 14, EuroProofNet, 2025
2025
-
[49]
Jiang, Wenda Li, Markus N
Yuhuai Wu, Albert Q. Jiang, Wenda Li, Markus N. Rabe, Charles Staats, Mateja Jamnik, and Christian Szegedy. Autoformalization with large language models. In Advances in Neural Infor- mation Processing Systems (NeurIPS) , 2022
2022
-
[50]
A natural formalized proof language
Lihan Xie, Zhicheng Hui, and Qinxiang Cao. A natural formalized proof language. In Con- ference on Automated Deduction (CADE) , 2024. ProofGrader system; https://github.com/ Laplace-Demon/ProofGrader
2024
-
[51]
DeepSeek-Prover: Advancing theorem proving in LLMs through large-scale synthetic data
Huajian Xin, Daya Guo, Zhihong Shao, Zhizhou Ren, Qihao Zhu, Bo Liu, Chong Ruan, Wenda Li, and Xiaodan Liang. DeepSeek-Prover: Advancing theorem proving in LLMs through large-scale synthetic data. arXiv preprint arXiv:2405.14333 , 2024. 12
arXiv 2024
-
[52]
On the Theory of Deep Learning
Xiyu Zhai. On the Theory of Deep Learning . PhD thesis, Massachusetts Institute of Technol- ogy, 2024. Doctoral dissertation. The super-computation-graph machinery later carried over to Visored’s kernel originated here
2024
-
[53]
Simplified ForTheL
Kunhao Zheng, Jesse Michael Han, and Stanislas Polu. MiniF2F: a cross-system benchmark for formal Olympiad-level mathematics. In International Conference on Learning Representations (ICLR), 2022. 13 A Extended Related Work A.1 Progress of AI for Mathematics LLMs built on the Transformer [ 39] have become capable mathematical reasoners, with steady progres...
2022
-
[54]
**Read the problem** from a `.tex` file (the prefix inside `\begin{example}...\end{example}`)
-
[55]
**Think through the proof** in natural language first
-
[56]
**Extend the prefix** with proof statements
-
[57]
**Verify** by running: `visored-core-cli <file_path> --specs-dir <specs_dir>`
-
[58]
**If error**, parse the error message and fix the text
-
[59]
**Repeat** until SUCCESS ## Harder Problems For harder problems:
-
[60]
**Solve in natural language first** - Write out the complete proof in plain English/math before attempting CNL
-
[61]
**Convert to CNL** - Only after you have a working natural language proof, translate it step by step
-
[62]
Let such that
**If you can't solve it in natural language** - That's YOUR problem, not visored's. Don't blame the prover for your inability to find the proof. This ensures you distinguish between: - **Your failure**: Can't find the proof strategy - **Visored limitation**: Found the proof but visored can't verify a specific step ## Verification Command **IMPORTANT: Alwa...
1984
-
[63]
Check `docs/tactics/` for proof strategies
-
[64]
Check `docs/syntax/` for LaTeX syntax rules
-
[65]
Check `docs/workarounds/` for known limitations
-
[66]
# Set Tactics ## Set Minimality (Smallest Element) To prove `$x$ is the smallest element of $S$`:
If new issue, report to maintainer and document ## Reference Examples - `test-data/visored/elaborator/` - Extensive examples - `main/props/` - Basic propositions - `minif2f/valid/` - Competition math problems - `tactics/` - Various proof tactics docs/tactics/set.md. # Set Tactics ## Set Minimality (Smallest Element) To prove `$x$ is the smallest element of $S$`:
-
[67]
Let $x\in\mathbb{R}$
Prove `$\forall y \in S,\, x \le y$` ### Example ```latex Let $S\subseteq\mathbb{Q}$. Let $x\in\mathbb{R}$. Assume $x\in S$. Assume $\forall y\in S,\,x\le y$. Then $x$ is the smallest element of $S$. ``` ## Second Smallest Element To prove `$x_2$ is the second smallest element of $S$`:
-
[68]
Prove `$x_1$ is the smallest element of $S$`
-
[69]
Let $x_1, x_2\in\mathbb{R}$
Prove `$\forall y \in S,\, x_1 < y \rightarrow x_2 \le y$` ### Example ```latex Let $S\subseteq\mathbb{Q}$. Let $x_1, x_2\in\mathbb{R}$. Assume $x_1\in S$. Assume $x_1$ is the smallest element of $S$. Assume $x_2\in S$. Assume $\forall y\in S,\,x_1 < y \rightarrow x_2\le y$. Then $x_2$ is the second smallest element of $S$. ``` Reference: `test-data/visor...
-
[70]
**Show each element is in S** (forward direction)
-
[71]
**Show all elements of S satisfy a characterization** (backward direction)
-
[72]
**Conclude the iff characterization**
-
[73]
Then $2 \in S$
**Derive set equality and cardinality** ```latex % Show 1 ∈ S, 2 ∈ S Then $1 \in S$. Then $2 \in S$. % Show ∀x ∈ S, x = 1 ∨ x = 2 Let $x \in S$. Then ... (derive bounds on x) We have $x \in \mathbb{N}$. We have $x > 0$. We have $x < 3$. Then $x = 1 \lor x = 2$. % Conclude Then $\forall x \in S,\, x = 1 \lor x = 2$. Then $\forall x \in \mathbb{N},\, x \in ...
2008
-
[74]
Assume ∀n ∈ N, n > 1 ∧ n mod 2 = 1 =⇒ f (n) = f (n −
+ 1 . Assume ∀n ∈ N, n > 1 ∧ n mod 2 = 1 =⇒ f (n) = f (n −
-
[75]
The goal is to prove f (2017) = 2018
+ 2 . The goal is to prove f (2017) = 2018 . Let k ∈ N. We prove f (2k + 1) = 2 k + 2 by induction on k : • Case k = 0 . We have f (1) = 2 . We have 2 · 0 + 2 = 2 . Then f (2 · 0 + 1) = 2 · 0 + 2 . • Case k ≥ 0. Assume f (2k + 1) = 2 k + 2. The goal is to prove f (2(k + 1) + 1) = 2( k + 1) + 2 . We have 2(k + 1) + 1 = 2 k + 3. We have 2k + 3 > 1. We have ...
2017
-
[76]
succ_eq_add_one k have hadd : k + 1 = Nat.succ k := (Nat.add_one k)
: f 2017 = 2018 := by have key : ∀ k : ℕ, f (2 * k + 1) = 2 * k + 2 := by intro k induction k with | zero => simpa using h1 | succ k ih => have hindex : 2 * (k + 1) + 1 = 2 * k + 3 := by have hsucc : Nat.succ k = k + 1 := Nat. succ_eq_add_one k have hadd : k + 1 = Nat.succ k := (Nat.add_one k). symm ring have hgt : 2 * k + 3 > 1 := by omega have hmod : (2...
2017
-
[77]
= π / 4 := by have h1 : (0 : ℝ) ≤ π / 4 := by linarith have h2 : π / 4 ≤ π := by linarith have hcos_pi4 : Real.cos (π / 4) = Real.sqrt 2 / 2 := Real.cos_pi_div_four have := Real.arccos_cos h1 h2 rw [hcos_pi4] at this exact this by_cases hxπ : x ≤ π · have harccos_cos : Real.arccos (Real.cos x) = x := Real .arccos_cos hx0 hxπ have hmono : Real.arccos (Real...
1965
-
[78]
Set-builder with √n ∈ (2, 7/2) rewritten as n ∈ { 5,
:= by have h_lower : (2 : ℝ) < Real.sqrt n ↔ (4 : ℝ) < (n : ℝ) := by have h2 : (0 : ℝ) ≤ 2 := by norm_num have := Real.lt_sqrt (x := (2 : ℝ)) (y := (n : ℝ)) h2 simpa [ show ((2 : ℝ))^2 = 4 by norm_num] using this have h_upper : Real.sqrt n < (7 : ℝ) / 2 ↔ (n : ℝ) < (49 : ℝ) / 4 := by have hpos : (0 : ℝ) < 7 / 2 := by norm_num have := Real.sqrt_lt' (x := (...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.