REVIEW 2 major objections 1 minor 2 cited by
Reviewed by Pith at T0; open to challenge.
T0 means a machine referee read the full paper against a public rubric. The mark states how deep the mechanical check went, never who wrote it. the ladder, T0–T4 →
T0 review · grok-4.3
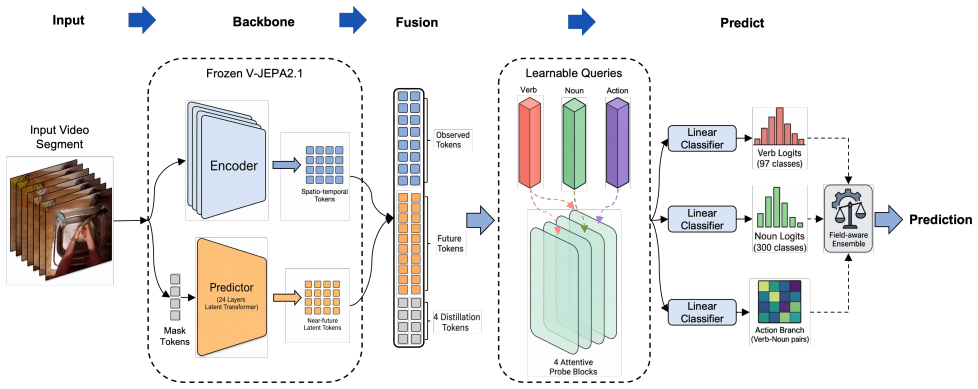
JFAA uses a frozen V-JEPA encoder and an attentive probe to win first place in the EPIC-KITCHENS-100 action anticipation challenge.
2026-05-21 05:47 UTC pith:UHY2EBLL
load-bearing objection They froze V-JEPA 2.1, added a lightweight attentive probe and field-aware ensemble, and took first on the official EK-100 anticipation server. the 2 major comments →
JFAA: Technical Report for the EPIC-KITCHENS-100 Action Anticipation Challenge at EgoVis 2026
The pith
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
JFAA achieves first place on the official server by relying on a frozen V-JEPA 2.1 encoder and predictor to supply observed context features and near-future latent tokens, which a lightweight attentive probe maps to verb, noun, and action logits using separate task queries, further improved by a field-aware ensemble over epoch predictions.
What carries the argument
The frozen V-JEPA 2.1 encoder and predictor that extract context features and near-future latent tokens for input to the attentive probe.
Load-bearing premise
The general video features from V-JEPA 2.1 are already sufficiently informative for egocentric kitchen actions without any fine-tuning on the target data.
What would settle it
Training the full model end-to-end by unfreezing the V-JEPA backbone and comparing the resulting accuracy on the challenge test set to the frozen version would show whether the frozen features are adequate.
If this is right
- Frozen general-domain video models suffice for egocentric action anticipation when paired with a small probe.
- Separate task queries allow independent optimization of verb and noun predictions within the same model.
- Selecting the most reliable epoch predictions per output field increases overall robustness.
- JEPA-style future token prediction provides useful representations for downstream anticipation without domain-specific training.
Where Pith is reading between the lines
- This approach implies that the latent space learned by V-JEPA captures action-relevant dynamics that generalize beyond its original training videos.
- Similar frozen-backbone strategies could be tested on other video prediction or anticipation benchmarks to measure transfer.
- Reducing the need for fine-tuning large models on target datasets may lower computational costs for new tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes JFAA, a JEPA-based Future Action Anticipation method for the EPIC-KITCHENS-100 Action Anticipation task. It uses a frozen V-JEPA 2.1 encoder and predictor to extract observed context features and near-future latent tokens, trains a lightweight attentive probe with separate task queries to predict verb, noun, and action logits, and applies field-aware ensembling over epoch-level predictions for robustness. The central result is that JFAA achieves first place on the official EgoVis 2026 EK-100 Action Anticipation Challenge server.
Significance. A first-place ranking on an independently judged challenge test set supplies direct external validation of the overall pipeline. If the performance gain can be attributed to the attentive probe and field-aware ensemble rather than the pre-trained V-JEPA 2.1 backbone alone, the work would demonstrate the transferability of general-video JEPA representations to egocentric kitchen actions and provide a lightweight, reproducible recipe for anticipation tasks. The stated intent to release code is a positive factor for reproducibility.
major comments (2)
- [Method] Method description (abstract and §3): the manuscript states that the V-JEPA 2.1 encoder and predictor remain frozen and only the attentive probe is trained, yet provides no ablation that isolates the contribution of these frozen general-video features versus a fine-tuned or domain-adapted backbone. Given the domain shift to hand-centric egocentric kitchen videos, this omission leaves open whether the reported first-place ranking is driven by the proposed JFAA components or by the backbone itself.
- [Experiments] Experiments section: no training details, hyperparameter settings, or error analysis are supplied, which prevents assessment of whether the ranking is robust or sensitive to implementation choices.
minor comments (1)
- [Abstract] The abstract mentions 'field-aware ensemble' but does not define the selection criterion or the number of epochs involved; a brief description or pseudocode would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive suggestions. Below we provide point-by-point responses to the major comments and indicate the revisions we plan to make.
read point-by-point responses
-
Referee: [Method] Method description (abstract and §3): the manuscript states that the V-JEPA 2.1 encoder and predictor remain frozen and only the attentive probe is trained, yet provides no ablation that isolates the contribution of these frozen general-video features versus a fine-tuned or domain-adapted backbone. Given the domain shift to hand-centric egocentric kitchen videos, this omission leaves open whether the reported first-place ranking is driven by the proposed JFAA components or by the backbone itself.
Authors: We acknowledge the value of an ablation study to better attribute the performance gains. As a technical report for the challenge, our focus was on presenting the method that secured first place. We did not conduct fine-tuning experiments due to the high computational demands and the challenge's emphasis on leveraging pre-trained models like V-JEPA 2.1. The design of the lightweight attentive probe with task-specific queries and the field-aware ensemble represents our main contributions for adapting these features to egocentric action anticipation. We will revise the manuscript to include a more explicit discussion of this design rationale and the potential impact of domain shift. revision: partial
-
Referee: [Experiments] Experiments section: no training details, hyperparameter settings, or error analysis are supplied, which prevents assessment of whether the ranking is robust or sensitive to implementation choices.
Authors: We agree that additional details would enhance the reproducibility and assessment of our results. In the revised manuscript, we will add a dedicated subsection or appendix with training details, hyperparameter values, and an error analysis based on the validation set performance. revision: yes
- The lack of an ablation study comparing frozen versus fine-tuned backbones, as conducting such experiments was not feasible within the scope and timeline of the challenge submission.
Circularity Check
No significant circularity; external challenge ranking provides independent validation
full rationale
The paper describes an empirical method that freezes a pre-existing V-JEPA 2.1 encoder/predictor, trains only a lightweight attentive probe on top, and reports performance via an external official challenge server ranking. No equations or derivations are presented that reduce a claimed result to a fitted parameter or self-citation by construction. The central claim (first place on the EK-100 server) is measured against an independently judged benchmark rather than quantities defined inside the paper, satisfying the criteria for a self-contained, non-circular technical report.
Axiom & Free-Parameter Ledger
free parameters (1)
- attentive probe parameters
axioms (1)
- domain assumption V-JEPA 2.1 representations remain informative for action anticipation when the backbone is kept frozen
read the original abstract
We propose JFAA, a JEPA-based Future Action Anticipation method for the EPIC-KITCHENS-100 (EK-100) Action Anticipation task. Inspired by the representation learning and future prediction ability of V-JEPA 2.1, JFAA uses a frozen encoder and predictor to extract observed context features and near-future latent tokens. A lightweight attentive probe is then trained to predict verb, noun, and action logits with separate task queries. To improve robustness, we further build a field-aware ensemble over selected epoch-level predictions, allowing each output field to benefit from its most reliable candidates. Experimental results on the official challenge server show that JFAA achieves first place in the EgoVis 2026 EK-100 Action Anticipation Challenge. Our code will be released at https://github.com/CorrineQiu/JFAA.
Figures


Forward citations
Cited by 2 Pith papers
-
FROST-STA: Frozen Dense Features for the Ego4D Short-Term Object Interaction Anticipation
FROST-STA ranks second in the Ego4D Short-Term Object Interaction Anticipation challenge with 5.13 mAP by adapting frozen V-JEPA features with object-centric heads and ensembling.
-
TAP-JEPA: Frozen Future-Latent Probing and Two-Stage Score Fusion for EPIC-KITCHENS-100 Action Anticipation
TAP-JEPA applies frozen V-JEPA features, latent future prediction, and two-stage fusion of attentive probes to reach 27.91% MT5R and second place on the EK-100 action anticipation leaderboard.
Reference graph
Works this paper leans on
-
[1]
Qiaohui Chu, Haoyu Zhang, Yisen Feng, Meng Liu, Weili Guan, Yaowei Wang, and Liqiang Nie. Technical report for Ego4D long-term action anticipation challenge 2025.arXiv preprint arXiv:2506.02550, 2025. 1
-
[2]
Intention-guided cognitive reason- ing for egocentric long-term action anticipation
Qiaohui Chu, Haoyu Zhang, Meng Liu, Yisen Feng, Haoxi- ang Shi, and Liqiang Nie. Intention-guided cognitive reason- ing for egocentric long-term action anticipation. InProceed- ings of the AAAI Conference on Artificial Intelligence, pages 17436–17444, 2026. 1
work page 2026
-
[3]
Cubuk, Barret Zoph, Jonathon Shlens, and Quoc V
Ekin D. Cubuk, Barret Zoph, Jonathon Shlens, and Quoc V . Le. RandAugment: Practical automated data augmenta- tion with a reduced search space. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, pages 702–703, 2020. 2
work page 2020
-
[4]
Dima Damen, Hazel Doughty, Giovanni Maria Farinella, Sanja Fidler, Antonino Furnari, Evangelos Kazakos, Davide Moltisanti, Jonathan Munro, Toby Perrett, Will Price, et al. The EPIC-KITCHENS dataset: Collection, challenges and baselines.IEEE Transactions on Pattern Analysis and Ma- chine Intelligence, 43(11):4125–4141, 2020. 2
work page 2020
-
[5]
Dima Damen, Hazel Doughty, Giovanni Maria Farinella, Antonino Furnari, Evangelos Kazakos, Jian Ma, Davide Moltisanti, Jonathan Munro, Toby Perrett, Will Price, et al. Rescaling egocentric vision: Collection, pipeline and chal- lenges for EPIC-KITCHENS-100.International Journal of Computer Vision, 130(1):33–55, 2022. 2
work page 2022
-
[6]
Osgnet@ ego4d episodic memory challenge 2025.arXiv preprint arXiv:2506.03710, 2025
Yisen Feng, Haoyu Zhang, Qiaohui Chu, Meng Liu, Weili Guan, Yaowei Wang, and Liqiang Nie. OSGNet @ Ego4D episodic memory challenge 2025.arXiv preprint arXiv:2506.03710, 2025. 1
-
[7]
Focal loss for dense object detection
Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Doll´ar. Focal loss for dense object detection. InPro- ceedings of the IEEE International Conference on Computer Vision, pages 2980–2988, 2017. 3
work page 2017
-
[8]
V-JEPA 2.1: Unlocking Dense Features in Video Self-Supervised Learning
Lorenzo Mur-Labadia, Matthew Muckley, Amir Bar, Mido Assran, Koustuv Sinha, Mike Rabbat, Yann LeCun, Nicolas Ballas, and Adrien Bardes. V-JEPA 2.1: Unlocking dense features in video self-supervised learning.arXiv preprint arXiv:2603.14482, 2026. 2
work page internal anchor Pith review arXiv 2026
-
[9]
Multimodal dialog system: Rela- tional graph-based context-aware question understanding
Haoyu Zhang, Meng Liu, Zan Gao, Xiaoqiang Lei, Yinglong Wang, and Liqiang Nie. Multimodal dialog system: Rela- tional graph-based context-aware question understanding. In Proceedings of the 29th ACM International Conference on Multimedia, pages 695–703, 2021. 1
work page 2021
-
[10]
Haoyu Zhang, Meng Liu, Yuhong Li, Ming Yan, Zan Gao, Xiaojun Chang, and Liqiang Nie. Attribute-guided collab- orative learning for partial person re-identification.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(12):14144–14160, 2023. 3
work page 2023
-
[11]
Multi-factor adaptive vision selec- tion for egocentric video question answering
Haoyu Zhang, Meng Liu, Zixin Liu, Xuemeng Song, Yaowei Wang, and Liqiang Nie. Multi-factor adaptive vision selec- tion for egocentric video question answering. InProceedings of the 41st International Conference on Machine Learning, pages 59310–59328. PMLR, 2024. 1
work page 2024
-
[12]
HCQA-1.5 @ Ego4D EgoSchema challenge 2025.arXiv preprint arXiv:2505.20644, 2025
Haoyu Zhang, Yisen Feng, Qiaohui Chu, Meng Liu, Weili Guan, Yaowei Wang, and Liqiang Nie. HCQA-1.5 @ Ego4D EgoSchema challenge 2025.arXiv preprint arXiv:2505.20644, 2025. 1
-
[13]
Exo2Ego: Exocentric knowledge guided MLLM for egocentric video understand- ing
Haoyu Zhang, Qiaohui Chu, Meng Liu, Haoxiang Shi, Yaowei Wang, and Liqiang Nie. Exo2Ego: Exocentric knowledge guided MLLM for egocentric video understand- ing. InProceedings of the AAAI Conference on Artificial Intelligence, pages 12502–12510, 2026. 1
work page 2026
-
[14]
Spatial understand- ing from videos: Structured prompts meet simulation data
Haoyu Zhang, Meng Liu, Zaijing Li, Haokun Wen, Weili Guan, Yaowei Wang, and Liqiang Nie. Spatial understand- ing from videos: Structured prompts meet simulation data. Advances in Neural Information Processing Systems, 38: 103202–103229, 2026. 1
work page 2026
-
[15]
Random erasing data augmentation
Zhun Zhong, Liang Zheng, Guoliang Kang, Shaozi Li, and Yi Yang. Random erasing data augmentation. InProceed- ings of the AAAI Conference on Artificial Intelligence, pages 13001–13008, 2020. 2
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.