PipeSD: An Efficient Cloud-Edge Collaborative Pipeline Inference Framework with Speculative Decoding
Pith reviewed 2026-05-15 03:07 UTC · model grok-4.3
The pith
PipeSD speeds up cloud-edge LLM inference 1.16x-2.16x by pipelining token batches and flexible verification.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
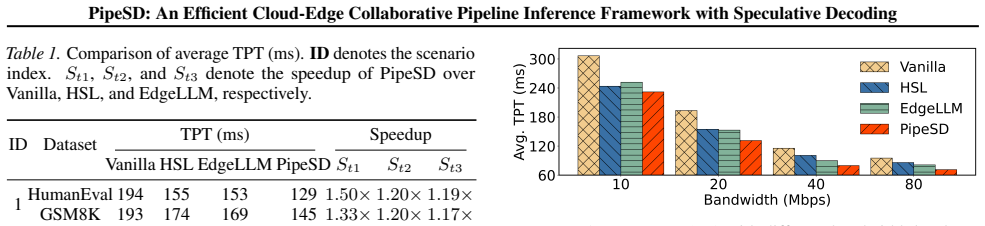
PipeSD overlaps token generation and communication through a token-batch pipeline scheduling mechanism optimized by dynamic programming, and improves verification flexibility through a dual-threshold NAV triggering mechanism with a lightweight Bayesian optimization autotuner; the resulting framework, implemented with llama-cpp-python, PyTorch, and FastAPI, delivers 1.16x-2.16x speedup and 14.3%-25.3% lower energy use compared with state-of-the-art baselines across four scenarios and two draft-target model pairs.
What carries the argument
Token-batch pipeline scheduler with dynamic-programming optimization paired with dual-threshold NAV triggering tuned by Bayesian autotuner; it overlaps generation and communication while allowing flexible verification to cut rollbacks.
If this is right
- Token generation and communication can be overlapped to raise utilization in distributed LLM inference.
- Flexible non-autoregressive verification reduces premature checks and costly rollbacks.
- Energy consumption falls 14-25 percent while generation speed rises across tested model pairs and scenarios.
- Cloud workload offloading remains compatible with offline robustness and privacy guarantees.
- The same mechanisms apply to multiple draft-target model pairs without per-deployment retuning.
Where Pith is reading between the lines
- The pipelining idea could extend to other distributed AI workloads such as vision or sensor models that also mix local and remote computation.
- Real-time adaptation of the Bayesian thresholds could let the system respond to changing network conditions without manual intervention.
- If the autotuner proves lightweight enough, similar self-tuning could appear in pure edge deployments that occasionally borrow cloud capacity.
Load-bearing premise
The dynamic-programming batch scheduler and Bayesian autotuner will keep delivering stable gains across unseen model pairs, network conditions, and workloads without hidden overhead or needing extensive retuning.
What would settle it
Measuring speedup below 1.1x or zero energy reduction when the same implementation is run on a new model pair under different network latency would disprove the claim of consistent outperformance.
Figures




read the original abstract
Speculative decoding can significantly accelerate LLM inference, especially given that its cloud-edge collaborative deployment offers cloud workload offloading, offline robustness, and privacy enhancement. However, existing collaborative inference frameworks with speculative decoding are constrained by (i) sequential token generation and communication with low resource utilization, and (ii) inflexible cloud non-autoregressive verification (NAV) triggering that induces premature verification or costly rollbacks. In this paper, we propose PipeSD, an efficient cloud-edge collaborative pipeline inference framework with speculative decoding. PipeSD overlaps token generation and communication by a token-batch pipeline scheduling mechanism optimized by dynamic programming, and improves verification flexibility through a dual-threshold NAV triggering mechanism with a lightweight Bayesian optimization autotuner. We implement PipeSD using llama-cpp-python, PyTorch, and FastAPI, and evaluate it on a real-world cloud-edge testbed with two draft-target model pairs across four scenarios. Results show that PipeSD consistently outperforms state-of-the-art baselines, achieving 1.16x-2.16x speedup and reducing energy consumption by 14.3%-25.3%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PipeSD, a cloud-edge collaborative pipeline inference framework for large language models using speculative decoding. It proposes a token-batch pipeline scheduling mechanism optimized via dynamic programming to overlap generation and communication, along with a dual-threshold non-autoregressive verification (NAV) triggering mechanism enhanced by a lightweight Bayesian optimization autotuner. The framework is implemented using llama-cpp-python, PyTorch, and FastAPI, and evaluated on a real-world cloud-edge testbed with two draft-target model pairs across four scenarios, claiming consistent outperformance of state-of-the-art baselines with speedups of 1.16x-2.16x and energy reductions of 14.3%-25.3%.
Significance. If the empirical results hold under broader conditions, PipeSD could meaningfully advance efficient distributed inference for LLMs by improving pipeline utilization and verification flexibility in cloud-edge setups. The use of dynamic programming for scheduling and Bayesian tuning for triggering offers a principled approach to optimization that may generalize if validated more extensively.
major comments (1)
- [Evaluation] The experiments cover only two draft-target model pairs on one testbed across four scenarios. This limited scope leaves the generalization of the dynamic-programming batch scheduler and Bayesian autotuner unproven, as the mechanisms may incur hidden overhead or require per-deployment retuning under varying model scales, network conditions, or workloads, undermining the claim of consistent speedups.
Simulated Author's Rebuttal
Thank you for the opportunity to respond to the referee's comments. We appreciate the positive assessment of the paper's potential impact and address the major comment on evaluation below.
read point-by-point responses
-
Referee: [Evaluation] The experiments cover only two draft-target model pairs on one testbed across four scenarios. This limited scope leaves the generalization of the dynamic-programming batch scheduler and Bayesian autotuner unproven, as the mechanisms may incur hidden overhead or require per-deployment retuning under varying model scales, network conditions, or workloads, undermining the claim of consistent speedups.
Authors: We thank the referee for pointing out the limited scope of our experiments. While the evaluation is indeed restricted to two model pairs and one testbed, these were selected to cover a range of practical cloud-edge conditions through the four scenarios, which vary in terms of communication latency and bandwidth. The dynamic-programming-based scheduler is designed to be general, as it takes as input the profiled computation and communication times for any given model pair and network, solving for the optimal pipeline schedule without assuming specific model scales. Similarly, the Bayesian autotuner optimizes the dual thresholds based on empirical performance data from the deployment, allowing adaptation to different workloads. We have measured and reported the overhead of these mechanisms in Section 5, showing they are negligible. To better address generalization, in the revised version we will expand the 'Discussion' section to include an analysis of how the proposed mechanisms can be applied to other model sizes and network conditions, along with potential limitations. revision: partial
Circularity Check
No circularity: claims rest on direct empirical measurements
full rationale
The paper describes a pipeline scheduling mechanism using dynamic programming and a dual-threshold NAV trigger with Bayesian autotuner, then reports measured speedups (1.16x-2.16x) and energy reductions from implementation on a specific cloud-edge testbed with two model pairs. No equations, predictions, or uniqueness theorems are presented that reduce by construction to fitted inputs, self-citations, or renamed ansatzes; the results are direct testbed outputs rather than derived quantities forced by the method itself.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.