WaterGen: Decoupling Scene and Medium in Underwater Image Generation
Pith reviewed 2026-07-01 06:42 UTC · model grok-4.3
The pith
Decoupling scene generation from water medium effects inside a latent diffusion model produces controllable and physically accurate underwater images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
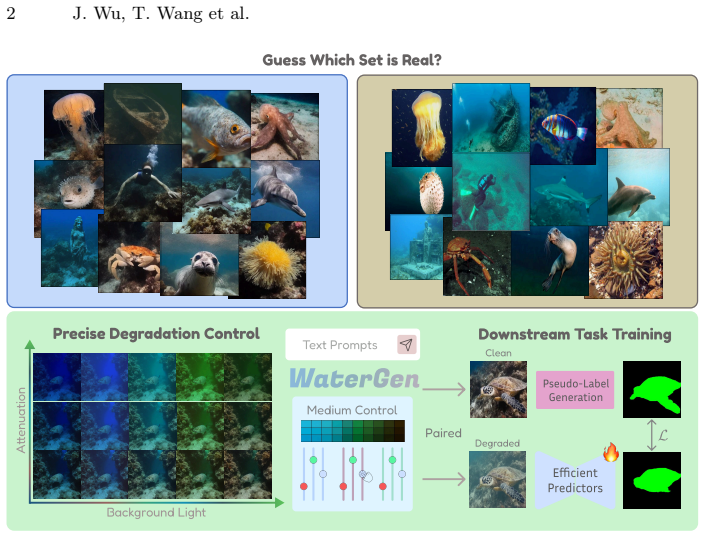
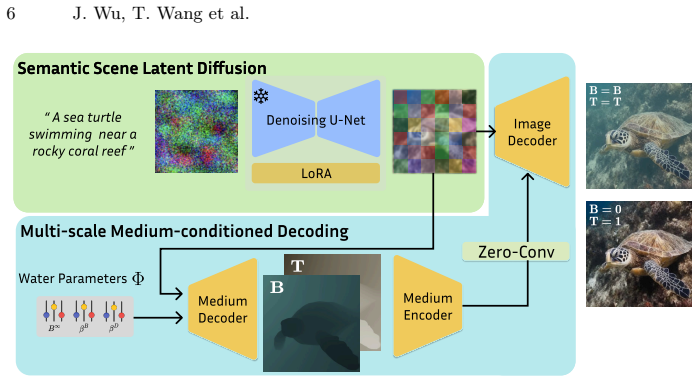
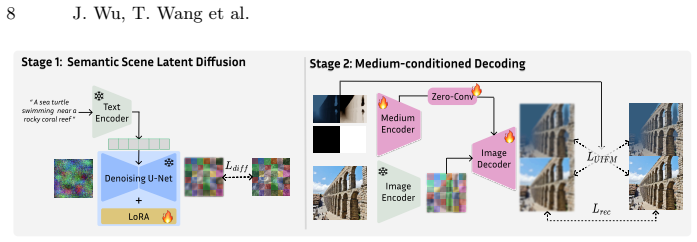
Underwater image synthesis can be decomposed into two stages inside a latent diffusion framework: first, fine-tuning the U-Net on degradation-free underwater images to generate diverse latent embeddings of scene content; second, formulating the physically accurate medium degradation as a conditional decoding process on those embeddings. This produces images with independent control over scene structure and water appearance, from which large-scale synthetic datasets can be built that improve downstream underwater restoration and semantic segmentation performance.
What carries the argument
Two-stage latent diffusion process that first generates scene-content embeddings and then applies conditional medium degradation synthesis.
If this is right
- Large synthetic datasets become feasible with independent control over scene diversity and water conditions.
- Training on the generated data raises accuracy in underwater image restoration tasks.
- Semantic segmentation models benefit from both realistic appearance and reliable pseudo-labels.
- The approach removes the realism-controllability trade-off present in prior single-stage underwater synthesis methods.
Where Pith is reading between the lines
- The same separation of content and medium could be tested on other scattering environments such as fog or turbid air.
- Varying water parameters at inference time without retraining the scene generator may support rapid simulation of different ocean conditions.
- The resulting datasets could serve as a testbed for studying how much physical accuracy is actually required for downstream task gains.
Load-bearing premise
Scene generation and medium modeling can be decoupled within a latent diffusion framework while preserving both realism and physical accuracy of the water effects.
What would settle it
A direct comparison showing that images generated with independently varied medium parameters fail to reproduce the measured attenuation and backscattering statistics of real paired clean-degraded underwater photographs of identical scenes.
Figures











read the original abstract
Underwater computer vision tasks, such as detection, restoration, and segmentation, are limited by the scarcity of large-scale and diverse training data. We introduce WaterGen, a method for generating large-scale, realistic, and diverse underwater images that provides independent control of the scene and water medium conditions. Our approach treats underwater image generation as the decoupled control of two factors: realistic and diverse scene content (what is in the image), and accurate and controllable water medium effects (what the water does to the image). Existing methods generally achieve only part of this objective: they either provide controllability with limited realism or diversity, or generate realistic scenes without accurately and independently modeling water-medium effects. Our key insight, that allows us to avoid this compromise, is that scene generation and medium modeling can be decoupled within a latent diffusion framework, enabling diverse scene generation together with accurate and controllable underwater appearance. To do this, we decompose underwater image synthesis into two stages. First, we fine-tune the latent diffusion U-Net using degradation-free underwater images so that it learns to generate diverse and realistic latent embeddings of underwater scene content without medium-induced degradation. Second, we formulate the physically accurate medium degradation synthesis as a conditional decoding process applied to these latent embeddings. This decoupled design allows our model to generate diverse scenes with full control of underwater appearance. We leverage WaterGen to build large-scale synthetic underwater datasets that are diverse in scene structures and accurate in water effects and pseudo-labels. We demonstrate that our synthetic data consistently improve downstream performance in underwater restoration and semantic segmentation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes WaterGen, a two-stage latent diffusion approach for underwater image synthesis that decouples realistic scene content generation (via fine-tuning a U-Net on degradation-free images) from physically accurate medium degradation (via conditional decoding of the resulting latents). This enables independent control over scene diversity and water effects (attenuation, scattering) to produce large-scale synthetic datasets, which are shown to improve downstream underwater restoration and semantic segmentation performance.
Significance. If the decoupling holds and the medium stage produces physically grounded effects rather than merely plausible ones, the method could meaningfully alleviate data scarcity in underwater CV by supplying controllable, diverse training data with reliable pseudo-labels. The explicit two-stage design within a latent diffusion framework is a clear conceptual strength that avoids the realism-controllability trade-offs noted in prior work.
major comments (2)
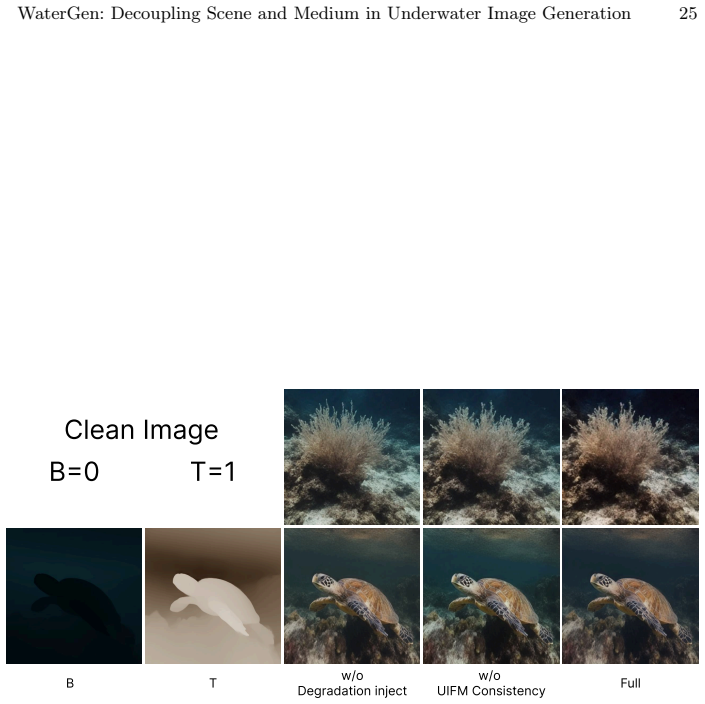
- [§3.2] §3.2 (medium degradation synthesis): The claim that the conditional decoding stage produces 'physically accurate' water effects is load-bearing for the central contribution, yet the manuscript provides no direct validation against the image formation model (e.g., recovered attenuation coefficients, scattering parameters, or Jerlov-type transmission maps). Downstream task gains can arise from any consistent appearance shift and therefore do not secure the physical-accuracy assertion.
- [§4] §4 (experiments): The reported improvements on restoration and segmentation lack an ablation that isolates the effect of independent medium control from the benefit of simply having more diverse scene content; without this, it is unclear whether the decoupling itself drives the gains or whether a single-stage model with comparable scene diversity would suffice.
minor comments (2)
- [§3] Notation for the conditional decoder inputs (latent embeddings vs. explicit medium parameters) is introduced without a consolidated table or diagram, making the two-stage pipeline harder to follow on first reading.
- [Figures 4-6] Figure captions for the generated examples should explicitly state the water-type or parameter settings used so readers can verify controllability.
Simulated Author's Rebuttal
We thank the referee for the constructive and insightful comments. We address each major comment below, clarifying our approach and indicating where revisions will strengthen the manuscript.
read point-by-point responses
-
Referee: [§3.2] §3.2 (medium degradation synthesis): The claim that the conditional decoding stage produces 'physically accurate' water effects is load-bearing for the central contribution, yet the manuscript provides no direct validation against the image formation model (e.g., recovered attenuation coefficients, scattering parameters, or Jerlov-type transmission maps). Downstream task gains can arise from any consistent appearance shift and therefore do not secure the physical-accuracy assertion.
Authors: We agree that direct empirical validation against the image formation model would provide stronger support for the physical-accuracy claim. Our conditional decoding stage is formulated to implement the standard underwater image formation model (attenuation and scattering) as a learned conditional process on the latent embeddings. While this design ensures the effects are grounded in the physical model by construction, we did not include parameter-recovery experiments. We will add such validation in the revision, for instance by synthesizing images with known coefficients and demonstrating recovery of those parameters from the generated outputs. revision: yes
-
Referee: [§4] §4 (experiments): The reported improvements on restoration and segmentation lack an ablation that isolates the effect of independent medium control from the benefit of simply having more diverse scene content; without this, it is unclear whether the decoupling itself drives the gains or whether a single-stage model with comparable scene diversity would suffice.
Authors: This is a fair point; an explicit ablation would better isolate the contribution of the decoupling. The two-stage design is motivated precisely by the need for independent control, which a single-stage model cannot achieve without trading off either scene diversity or medium accuracy. We will add an ablation comparing WaterGen against a single-stage latent diffusion baseline trained on equivalent scene content, quantifying the gains attributable to separate medium control in both controllability metrics and downstream task performance. revision: yes
Circularity Check
No circularity; forward two-stage synthesis pipeline with external empirical validation
full rationale
The paper describes a constructive two-stage latent diffusion method: (1) fine-tuning a U-Net on degradation-free underwater images to generate scene latents, then (2) applying medium degradation via conditional decoding. This is a proposed generative architecture, not a derivation that reduces any claimed result to its own inputs by construction. The downstream improvements in restoration and segmentation are presented as empirical outcomes on separate tasks, not as quantities fitted or renamed from the generation process itself. No self-citations, uniqueness theorems, ansatzes, or fitted-input-as-prediction patterns appear in the provided abstract or description. The derivation chain is self-contained as an engineering pipeline.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Latent diffusion U-Nets can be fine-tuned on degradation-free images to capture scene content independently of medium effects.
- domain assumption Underwater medium degradation can be accurately modeled as a conditional decoding process applied to latent scene embeddings.
Reference graph
Works this paper leans on
-
[1]
In: CVPR
Akkaynak, D., Treibitz, T.: A Revised Underwater Image Formation Model. In: CVPR. pp. 6723–6732 (2018)
2018
-
[2]
Electronic Imaging2016(18), 1–8 (2016).https://doi.org/10.2352/ISSN.2470- 1173.2016.18.DPMI-252
Blasinski, H., Farrell, J.: A three parameter underwater image formation model. Electronic Imaging2016(18), 1–8 (2016).https://doi.org/10.2352/ISSN.2470- 1173.2016.18.DPMI-252
-
[3]
Depth Pro: Sharp Monocular Metric Depth in Less Than a Second
Bochkovskii, A., Delaunoy, A., Germain, H., Santos, M., Zhou, Y., Richter, S.R., Koltun, V.: Depth pro: Sharp monocular metric depth in less than a second. arXiv preprint arXiv:2410.02073 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
In: Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition
Cai, H., He, J., Qiao, Y., Dong, C.: Toward interactive modulation for photo- realistic image restoration. In: Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition. pp. 294–303 (2021)
2021
-
[5]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Cai,H.,Huang,T.W.,Gehlot,S.,Feng,B.Y.,Shah,S.,Su,G.M.,Metzler,C.:Para- metric shadow control for portrait generation in text-to-image diffusion models. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 18207–18217 (2025)
2025
-
[6]
ACM Transactions on Multimedia Computing, Communications and Applications21(1), 1–22 (2024)
Desai, C., Benur, S., Patil, U., Mudenagudi, U.: Rsuigm: Realistic synthetic un- derwater image generation with image formation model. ACM Transactions on Multimedia Computing, Communications and Applications21(1), 1–22 (2024)
2024
-
[7]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Desai, C., Tabib, R.A., Reddy, S.S., Patil, U., Mudenagudi, U.: Ruig: Realistic un- derwater image generation towards restoration. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 2181–2189 (2021)
2021
-
[8]
Advances in neural information processing systems34, 8780–8794 (2021)
Dhariwal, P., Nichol, A.: Diffusion models beat gans on image synthesis. Advances in neural information processing systems34, 8780–8794 (2021)
2021
-
[9]
arXiv preprint arXiv:2509.12747 (2025)
He, B., Shahidzadeh, A.H., Chen, Y., Wu, J., Guan, T., Chen, G., Choset, H., Manocha, D., Chou, G., Fermuller, C., et al.: Navmoe: Hybrid model-and learning- based traversability estimation for local navigation via mixture of experts. arXiv preprint arXiv:2509.12747 (2025)
-
[10]
Advances in neural information processing systems33, 6840–6851 (2020)
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. Advances in neural information processing systems33, 6840–6851 (2020)
2020
-
[11]
IEEE transactions on image processing34, 1602–1615 (2023)
Hong, L., Wang, X., Zhang, G., Zhao, M.: Usod10k: a new benchmark dataset for underwater salient object detection. IEEE transactions on image processing34, 1602–1615 (2023)
2023
-
[12]
Iclr1(2), 3 (2022)
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., et al.: Lora: Low-rank adaptation of large language models. Iclr1(2), 3 (2022)
2022
-
[13]
In: 2020 IEEE/RSJ international conference on intelligent robots and systems (IROS)
Islam, M.J., Edge, C., Xiao, Y., Luo, P., Mehtaz, M., Morse, C., Enan, S.S., Sattar, J.: Semantic segmentation of underwater imagery: Dataset and benchmark. In: 2020 IEEE/RSJ international conference on intelligent robots and systems (IROS). pp. 1769–1776. IEEE (2020)
2020
-
[14]
In: Computer Vision, pp
Islam, M.J., Li, A.Q., Girdhar, Y.A., Rekleitis, I.: Computer vision applications in underwater robotics and oceanography. In: Computer Vision, pp. 173–204. Chap- man and Hall/CRC (2024)
2024
-
[15]
IEEE robotics and automation letters5(2), 3227–3234 (2020)
Islam, M.J., Xia, Y., Sattar, J.: Fast underwater image enhancement for improved visual perception. IEEE robotics and automation letters5(2), 3227–3234 (2020)
2020
-
[16]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Isola, P., Zhu, J.Y., Zhou, T., Efros, A.A.: Image-to-image translation with condi- tional adversarial networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 1125–1134 (2017)
2017
-
[17]
IEEE journal of oceanic engineering15(2), 101–111 (1990) WaterGen: Decoupling Scene and Medium in Underwater Image Generation 17
Jaffe, J.S.: Computer modeling and the design of optimal underwater imaging systems. IEEE journal of oceanic engineering15(2), 101–111 (1990) WaterGen: Decoupling Scene and Medium in Underwater Image Generation 17
1990
-
[18]
IEEE Trans- actions on Image Processing (2026)
Jia, Y., Lin, Q., Li, H., Li, Y., Kwong, S., Cong, R.: Vit-uwa: Vision transformer underwater-adapter for dense predictions beneath the water surface. IEEE Trans- actions on Image Processing (2026)
2026
-
[19]
In: European Conference on Computer Vision
Jia, Y., Hoyer, L., Huang, S., Wang, T., Van Gool, L., Schindler, K., Obukhov, A.: Dginstyle: Domain-generalizable semantic segmentation with image diffusion mod- els and stylized semantic control. In: European Conference on Computer Vision. pp. 91–109. Springer (2024)
2024
-
[20]
PHISWID: Physics-inspired underwater image dataset synthesized from RGB-D images,
Kaneko, R., Ueda, T., Higashi, H., Tanaka, Y.: Phiswid: Physics-inspired underwa- ter image dataset synthesized from rgb-d images. arXiv preprint arXiv:2404.03998 (2024)
-
[21]
IEEE Transactions on Pattern Analysis and Machine Intelligence (2025)
Ke, B., Qu, K., Wang, T., Metzger, N., Huang, S., Li, B., Obukhov, A., Schindler, K.: Marigold: Affordable adaptation of diffusion-based image generators for image analysis. IEEE Transactions on Pattern Analysis and Machine Intelligence (2025)
2025
-
[22]
In: ICCV
Ke, J., Wang, Q., Wang, Y., Milanfar, P., Yang, F.: Musiq: Multi-scale image quality transformer. In: ICCV. pp. 5148–5157 (2021)
2021
-
[23]
arXiv preprint arXiv:2412.01456 (2024)
Khan, M., Negi, A., Kulkarni, A., Phutke, S.S., Vipparthi, S.K., Murala, S.: Phase- former: Phase-based attention mechanism for underwater image restoration and beyond. arXiv preprint arXiv:2412.01456 (2024)
-
[24]
Auto-Encoding Variational Bayes
Kingma, D.P., Welling, M.: Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114 (2013)
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[25]
IEEE transactions on image processing29, 4376–4389 (2019)
Li, C., Guo, C., Ren, W., Cong, R., Hou, J., Kwong, S., Tao, D.: An underwater image enhancement benchmark dataset and beyond. IEEE transactions on image processing29, 4376–4389 (2019)
2019
-
[26]
arXiv preprint arXiv:2505.15581 (2025)
Li, H., Lian, S., Li, Z., Cong, R., Li, C., Yang, L.T., Zhang, W., Kwong, S.: Advanc- ing marine research: Uwsam framework and uiis10k dataset for precise underwater instance segmentation. arXiv preprint arXiv:2505.15581 (2025)
-
[27]
In: Proceedings of the 33rd ACM International Conference on Multimedia
Li, H., Lin, G., Li, Z., Kwong, S., Cong, R.: Fscdiff: Frequency-spatial entangled conditional diffusion model for underwater salient object detection. In: Proceedings of the 33rd ACM International Conference on Multimedia. pp. 8379–8388 (2025)
2025
-
[28]
IEEE Robotics and Automation letters3(1), 387–394 (2017)
Li, J., Skinner, K.A., Eustice, R.M., Johnson-Roberson, M.: Watergan: Unsuper- vised generative network to enable real-time color correction of monocular under- water images. IEEE Robotics and Automation letters3(1), 387–394 (2017)
2017
-
[29]
In: International conference on machine learning
Li, J., Li, D., Savarese, S., Hoi, S.: Blip-2: Bootstrapping language-image pre- training with frozen image encoders and large language models. In: International conference on machine learning. pp. 19730–19742. PMLR (2023)
2023
-
[30]
In: Proceedings of the IEEE/CVF international conference on computer vision
Lian, S., Li, H., Cong, R., Li, S., Zhang, W., Kwong, S.: Watermask: Instance seg- mentation for underwater imagery. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 1305–1315 (2023)
2023
-
[31]
In: Proceedings of the 41st International Conference on Machine Learning
Lian, S., Zhang, Z., Li, H., Li, W., Yang, L.T., Kwong, S., Cong, R.: Diving into underwater:Segmentanythingmodelguidedunderwatersalientinstancesegmenta- tion and a large-scale dataset. In: Proceedings of the 41st International Conference on Machine Learning. pp. 29545–29559 (2024)
2024
-
[32]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Lin, H., Liang, D., Qi, Z., Bai, X.: A unified image-dense annotation generation model for underwater scenes. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 961–970 (2025)
2025
-
[33]
IEEE Transactions on Circuits and Systems for Video Technology (2025)
Lv, Q., Dong, J., Li, Y., Chen, S., Yu, H., Zhang, S., Wang, W.: Uwstereo: A large synthetic dataset for underwater stereo matching. IEEE Transactions on Circuits and Systems for Video Technology (2025)
2025
-
[34]
In: Proceedings of the AAAI conference on artificial intelligence (2024) 18 J
Mou, C., Wang, X., Xie, L., Wu, Y., Zhang, J., Qi, Z., Shan, Y.: T2i-adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models. In: Proceedings of the AAAI conference on artificial intelligence (2024) 18 J. Wu, T. Wang et al
2024
-
[35]
IEEE Journal of Oceanic Engineering41(3), 541–551 (2015)
Panetta, K., Gao, C., Agaian, S.: Human-visual-system-inspired underwater image quality measures. IEEE Journal of Oceanic Engineering41(3), 541–551 (2015)
2015
-
[36]
IEEE Journal of Oceanic Engineering (2024)
Peng, Y.T., Chen, Y.R., Chen, G.R., Liao, C.J.: Histoformer: Histogram-based transformer for efficient underwater image enhancement. IEEE Journal of Oceanic Engineering (2024)
2024
-
[37]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Podell, D., English, Z., Lacey, K., Blattmann, A., Dockhorn, T., Müller, J., Penna, J., Rombach, R.: Sdxl: Improving latent diffusion models for high-resolution image synthesis. arXiv preprint arXiv:2307.01952 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[38]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021)
2021
-
[39]
IEEE Robotics and Automation Letters (2026)
Rajyaguru, N., Wang, T., Tajne, A., He, B., Wu, J., Fermuller, C., Metzler, C., Aloimonos, Y.: Polardepth: Polarization-guided monocular depth for visual odom- etry. IEEE Robotics and Automation Letters (2026)
2026
-
[40]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10684–10695 (2022)
2022
-
[41]
Advances in neural information processing systems35, 36479–36494 (2022)
Saharia, C., Chan, W., Saxena, S., Li, L., Whang, J., Denton, E.L., Ghasemipour, K., Gontijo Lopes, R., Karagol Ayan, B., Salimans, T., et al.: Photorealistic text- to-image diffusion models with deep language understanding. Advances in neural information processing systems35, 36479–36494 (2022)
2022
-
[42]
ACM TOMM (2023)
Sharma, P., Bisht, I., Sur, A.: Wavelength-based attributed deep neural network for underwater image restoration. ACM TOMM (2023)
2023
-
[43]
Siddique, M.A.B., Ramesh, V., Liu, J., Singh, P., Islam, M.J.: Ustyle: Waterbody styletransferofunderwaterscenesbydepth-guidedfeaturesynthesis.IEEEJournal of Oceanic Engineering (JOE) (2025)
2025
-
[44]
IEEE Robotics and Au- tomation Letters (2025)
Siddique, M.A.B., Wu, J., Rekleitis, I., Islam, M.J.: Aquafuse: Waterbody fusion for physics-guided view synthesis of underwater scenes. IEEE Robotics and Au- tomation Letters (2025)
2025
-
[45]
In: Pacific rim conference on multimedia
Song, W., Wang, Y., Huang, D., Tjondronegoro, D.: A rapid scene depth esti- mation model based on underwater light attenuation prior for underwater image restoration. In: Pacific rim conference on multimedia. pp. 678–688. Springer (2018)
2018
-
[46]
In: ICLR (2021)
Song, Y., Sohl-Dickstein, J., Kingma, D.P., Kumar, A., Ermon, S., Poole, B.: Score- based generative modeling through stochastic differential equations. In: ICLR (2021)
2021
-
[47]
In: 2019 IEEE Interna- tional Conference on Image Processing (ICIP)
Ueda, T., Yamada, K., Tanaka, Y.: Underwater image synthesis from rgb-d images and its application to deep underwater image restoration. In: 2019 IEEE Interna- tional Conference on Image Processing (ICIP). pp. 2115–2119. IEEE (2019)
2019
-
[48]
IEEE Trans- actions on Image Processing (2026)
Wang, C., Li, H., Li, C., Liu, H., Tang, X., Kwong, S.: Expose camouflage in the water: Underwater camouflaged instance segmentation and dataset. IEEE Trans- actions on Image Processing (2026)
2026
-
[49]
arXiv preprint arXiv:1912.10269 (2019)
Wang, N., Zhou, Y., Han, F., Zhu, H., Yao, J.: Uwgan: Underwater gan for real- world underwater color restoration and dehazing. arXiv preprint arXiv:1912.10269 (2019)
-
[50]
arXiv preprint arXiv:2309.08523 (2023)
Wang, T., Kanakis, M., Schindler, K., Van Gool, L., Obukhov, A.: Breathing new life into 3d assets with generative repainting. arXiv preprint arXiv:2309.08523 (2023)
-
[51]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Wang, T., Xie, M., Cai, H., Shah, S., Metzler, C.A.: Flash-split: 2d reflection removal with flash cues and latent diffusion separation. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 5688–5698 (2025) WaterGen: Decoupling Scene and Medium in Underwater Image Generation 19
2025
-
[52]
Wu, J.: Low-cost depth estimation and 3d reconstruction in scattering medium. Ph.D. thesis, University of Florida (2023)
2023
-
[53]
Real2SAM2Real: Generative 3D Caches as Complementary Context for Video Diffusion
Wu, J., Cai, H., Fermuller, C., Metzler, C., Aloimonos, Y.: Real2sam2real: Gen- erative 3d caches as complementary context for video diffusion. arXiv preprint arXiv:2606.00299 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[54]
In: 2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)
Wu, J., Lin, X., He, B., Fermüller, C., Aloimonos, Y.: Viewactive: Active viewpoint optimization from a single image. In: 2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). pp. 11812–11818. IEEE (2025)
2025
-
[55]
In: 2024 IEEE/RSJ In- ternational Conference on Intelligent Robots and Systems (IROS)
Wu, J., Lin, X., Negahdaripour, S., Fermüller, C., Aloimonos, Y.: Marvis: Motion & geometry aware real and virtual image segmentation. In: 2024 IEEE/RSJ In- ternational Conference on Intelligent Robots and Systems (IROS). pp. 2778–2785. IEEE (2024)
2024
-
[56]
IEEE Transactions on Pattern Analysis and Machine Intelligence (2025)
Wu, J., Wang, T., Siddique, M.A.B., Islam, M.J., Fermuller, C., Aloimonos, Y., Metzler, C.A.: Single-step latent diffusion for underwater image restoration. IEEE Transactions on Pattern Analysis and Machine Intelligence (2025)
2025
-
[57]
In: 2023 IEEE Conference on Artificial Intelligence (CAI)
Wu, J., Yu, B., Islam, M.J.: 3d reconstruction of underwater scenes using nonlinear domain projection. In: 2023 IEEE Conference on Artificial Intelligence (CAI). pp. 359–361. IEEE (2023)
2023
-
[58]
Advances in neural information processing systems34, 12077–12090 (2021)
Xie, E., Wang, W., Yu, Z., Anandkumar, A., Alvarez, J.M., Luo, P.: Segformer: Simple and efficient design for semantic segmentation with transformers. Advances in neural information processing systems34, 12077–12090 (2021)
2021
-
[59]
arXiv preprint arXiv:2406.02972 (2024)
Xiong, T., Wu, J., He, B., Fermuller, C., Aloimonos, Y., Huang, H., Metzler, C.A.: Event3dgs: Event-based 3d gaussian splatting for high-speed robot egomotion. arXiv preprint arXiv:2406.02972 (2024)
-
[60]
Journal of Marine Science and Engineering11(9), 1657 (2023)
Xu, D., Zhou, J., Liu, Y., Min, X.: Underwater image enhancement based on hybrid enhanced generative adversarial network. Journal of Marine Science and Engineering11(9), 1657 (2023)
2023
-
[61]
Journal of Marine Science and Engineering11(10), 1929 (2023)
Yang, D., Zhang, T., Li, B., Li, M., Chen, W., Li, X., Wang, X.: Underwater image translation via multi-scale generative adversarial network. Journal of Marine Science and Engineering11(10), 1929 (2023)
1929
-
[62]
arXiv preprint arXiv:2209.12358 (2022)
Yu, B., Wu, J., Islam, M.J.: Udepth: Fast monocular depth estimation for visually- guided underwater robots. arXiv preprint arXiv:2209.12358 (2022)
-
[63]
In: Proceedings of the IEEE/CVF In- ternational Conference on Computer Vision
Yuan, D., Burner, L., Wu, J., Liu, M., Chen, J., Aloimonos, Y., Fermüller, C.: Learning normal flow directly from events. In: Proceedings of the IEEE/CVF In- ternational Conference on Computer Vision. pp. 7969–7979 (2025)
2025
-
[64]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Zhang, F., You, S., Li, Y., Fu, Y.: Atlantis: Enabling underwater depth estimation with stable diffusion. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 11852–11861 (2024)
2024
-
[65]
In: Proceedings of the IEEE/CVF international conference on computer vision
Zhang, L., Rao, A., Agrawala, M.: Adding conditional control to text-to-image diffusion models. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 3836–3847 (2023)
2023
-
[66]
Sensors21(9), 3268 (2021)
Zhao, Q., Xin, Z., Yu, Z., Zheng, B.: Unpaired underwater image synthesis with a disentangled representation for underwater depth map prediction. Sensors21(9), 3268 (2021)
2021
-
[67]
Frontiers in Marine Science8, 690962 (2021)
Zhao, Q., Zheng, Z., Zeng, H., Yu, Z., Zheng, H., Zheng, B.: The synthesis of unpaired underwater images for monocular underwater depth prediction. Frontiers in Marine Science8, 690962 (2021)
2021
-
[68]
WaterGen: Decoupling Scene and Medium in Underwater Image Generation
Zhu, J.Y., Park, T., Isola, P., Efros, A.A.: Unpaired image-to-image translation using cycle-consistent adversarial networks. In: Proceedings of the IEEE interna- tional conference on computer vision. pp. 2223–2232 (2017) 20 J. Wu, T. Wang et al. Supplementary Material for: “WaterGen: Decoupling Scene and Medium in Underwater Image Generation” 6 More Visu...
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.