Layerwise Progressive Freezing: A Training Scaffold for Depth-Scalable Binary Networks
Pith reviewed 2026-06-29 05:06 UTC · model grok-4.3
The pith
StoMPP trains deep binary neural networks without straight-through estimators by progressively binarizing layers forward from input to output.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
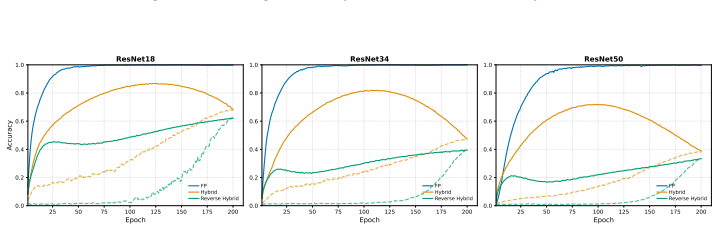
The central claim is that forward layerwise progressive binarization supplies an STE-free training rule whose accuracy advantage over standard STE grows with depth because it controls when binary activations form and thereby severs gradient paths; reverse ordering produces near-chance results on the same tasks while binary-weight-only networks remain insensitive to order.
What carries the argument
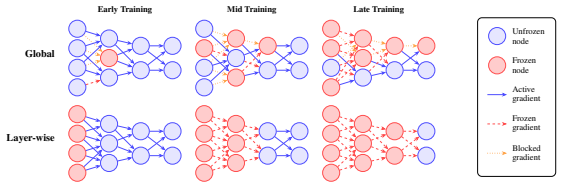
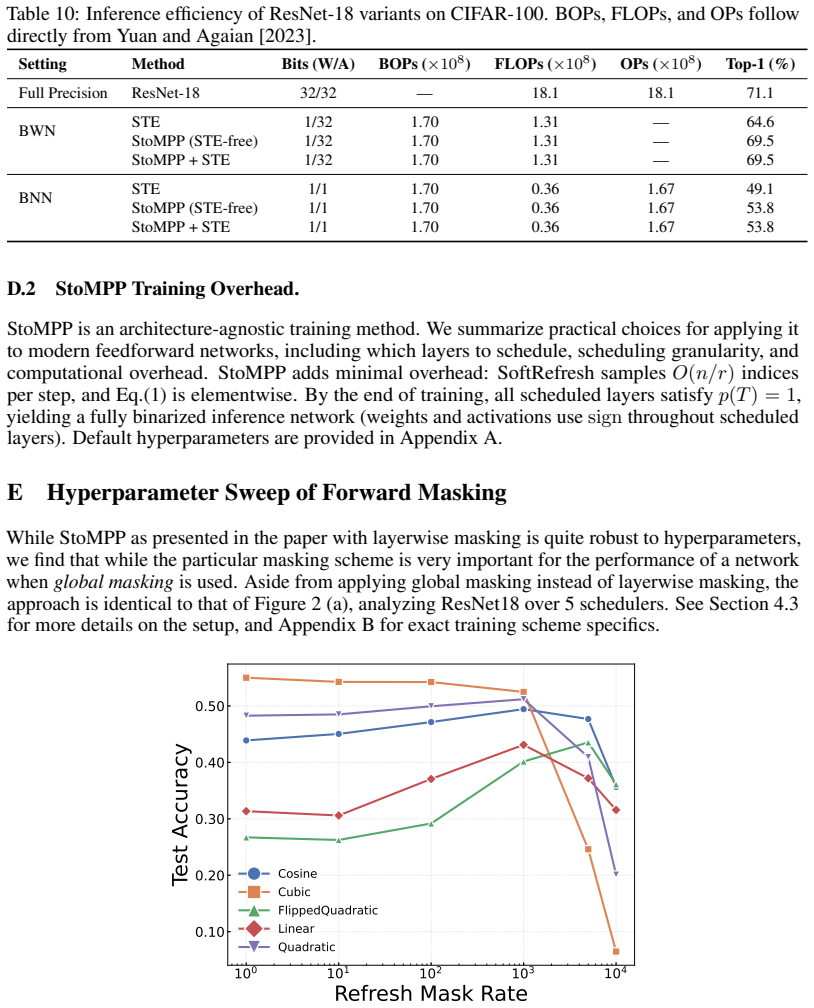
Stochastic Masked Partial Progressive Binarization (StoMPP): stochastic partial masks with soft refresh applied layer by layer from input to output to enforce binarization gradually.
If this is right
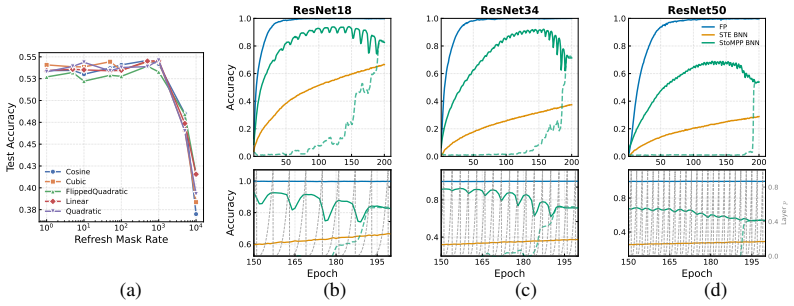
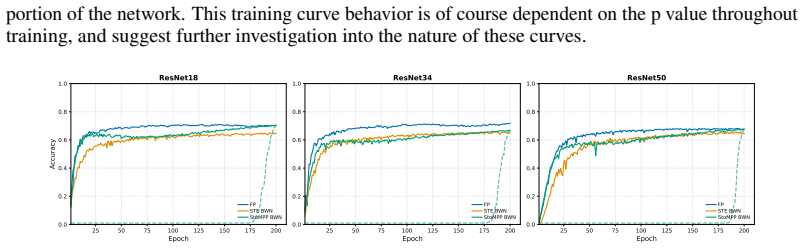
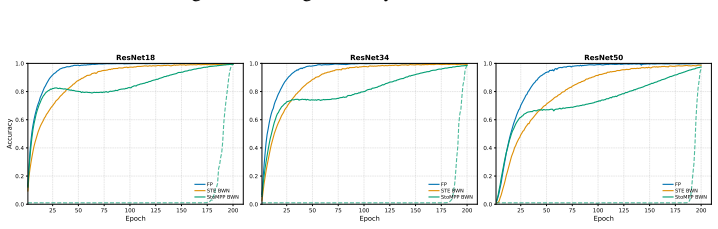
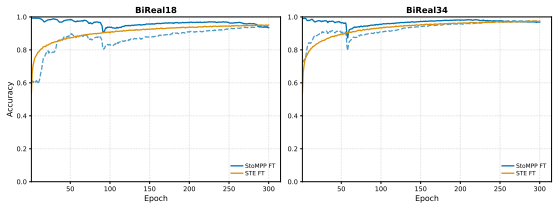
- Accuracy gains over vanilla STE increase with depth across ResNet-18, 34, and 50.
- The same forward-progression pattern improves results on MobileNetV2 and BERT fine-tuning.
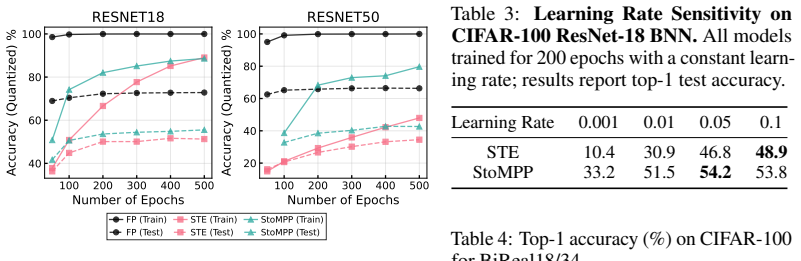
- Composing StoMPP with STE applied only to frozen entries produces still larger gains (+27.1 on CIFAR-10 for ResNet-50).
- Binary-weight networks without binary activations show no dependence on progression order.
Where Pith is reading between the lines
- The results imply that activation binarization, not weight binarization, is the dominant source of gradient isolation in these models.
- Similar progressive commitment schedules could be tested in other settings where discrete decisions create irreversible gradient barriers.
- The STE-free regime used for all ablations isolates the contribution of ordering itself from surrogate-gradient interactions.
Load-bearing premise
That the measured gains and the forward-versus-reverse asymmetry arise specifically from the timing of activation-induced gradient blockades rather than from unexamined details of the mask schedule or refresh rule.
What would settle it
An experiment in which reverse-order progression on ResNet-50 still reaches high accuracy on CIFAR-10 after artificially preserving gradient flow through the early layers would falsify the blockade-timing account.
Figures
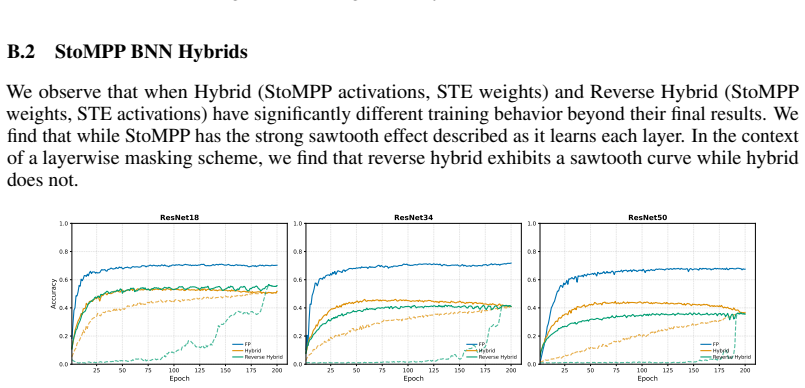
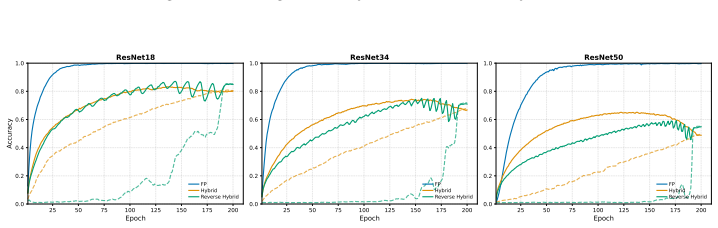
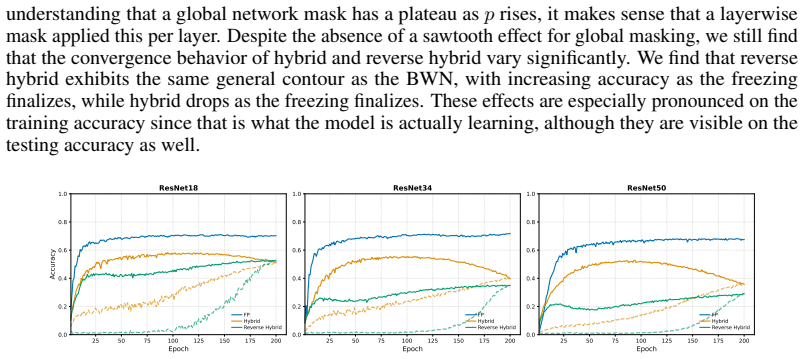
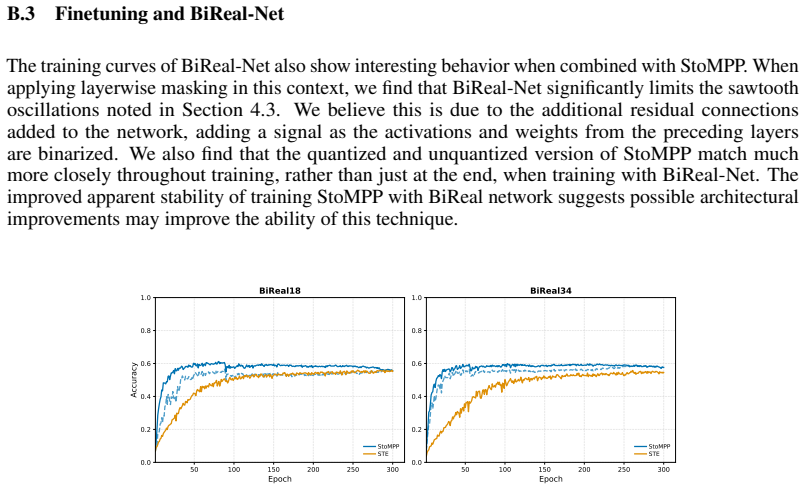
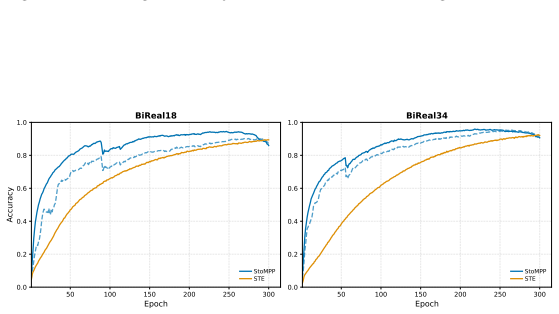
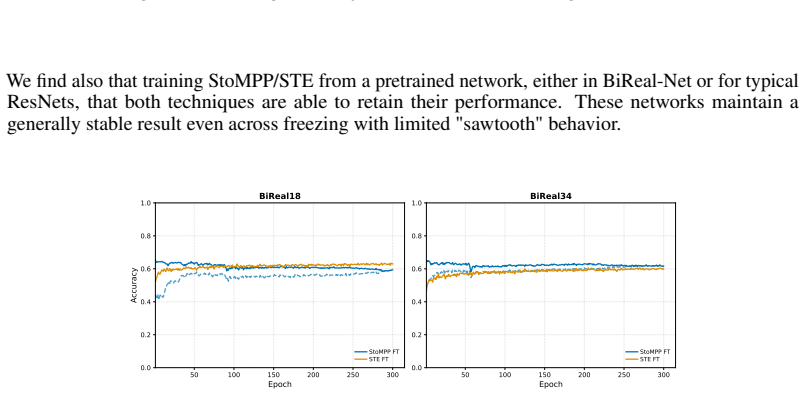
read the original abstract
Training binary neural networks (BNNs) from scratch is dominated by the straight-through estimator (STE), whose forward/backward mismatch produces severe accuracy degradation as networks deepen. We study an orthogonal axis: when and where binarization is enforced during training. We introduce StoMPP (Stochastic Masked Partial Progressive Binarization), which gradually replaces clipped weights and activations with their hard binary counterparts layer by layer from input to output, using stochastic partial masks with soft refresh. StoMPP delivers two complementary benefits. As a standalone training rule, it provides a fully STE-free procedure that improves over vanilla STE with gains that grow with depth (ResNet-50 BNN: +18.0/+13.5/+3.8 on CIFAR-10/100/ImageNet), and the pattern holds across ResNet-18/34/50, MobileNetV2, and BERT fine-tuning. Composed with surrogate gradients by applying STE only to frozen entries, it reaches +27.1/+19.8/+17.7 over vanilla STE on the same setting. Underlying both regimes is a single mechanistic finding: progression order is decisive. Forward layerwise progression prevents depth collapse, reverse progression collapses to near-chance, and binary-weight networks (without binary activations) are insensitive to order. We trace this asymmetry to activation-induced gradient blockades: a committed binary activation severs gradient flow upstream, and ordering controls when these blockades form. To isolate the progression's contribution from any benefit conferred by STE, we conduct all ablations in the STE-free regime; the resulting characterization (schedule, refresh, ordering, dynamics) thus reflects the progression itself rather than its interaction with surrogate gradients.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces StoMPP (Stochastic Masked Partial Progressive Binarization), a training procedure for binary neural networks that progressively enforces binarization layer-by-layer from input to output using stochastic partial masks and soft refresh. It claims this yields an STE-free method that outperforms vanilla STE with depth-dependent gains (e.g., +18.0/+13.5/+3.8 on CIFAR-10/100/ImageNet for ResNet-50 BNN), holds across ResNet-18/34/50, MobileNetV2 and BERT, and that forward progression prevents depth collapse while reverse progression collapses due to activation-induced gradient blockades; all ablations are performed in the STE-free regime to isolate the progression effect.
Significance. If the central claims hold, the work supplies a concrete, STE-free training scaffold that demonstrably improves depth scalability of BNNs and supplies a mechanistic account of why progression order matters. The explicit separation of progression from surrogate-gradient interactions via STE-free ablations is a methodological strength that makes the ordering result falsifiable and potentially reusable.
major comments (2)
- [Abstract] Abstract (mechanistic finding paragraph): the attribution of the forward-vs-reverse asymmetry to activation-induced gradient blockades is load-bearing for the central mechanistic claim, yet the manuscript does not report a control that holds the stochastic mask schedule, sampling probabilities, and refresh rule fixed while reversing only the progression order. Without this isolation, the observed pattern could arise from mask-depth interactions rather than blockade timing.
- [Abstract] Abstract (results paragraph): the reported accuracy deltas are presented as evidence that StoMPP improves over vanilla STE, but no table or section specifies whether the STE baseline used identical optimizer settings, learning-rate schedules, or binarization thresholds; this detail is required to confirm that the depth-dependent gains are not partly due to mismatched hyper-parameters.
minor comments (1)
- [Abstract] The abstract refers to 'soft refresh' without a one-sentence definition; adding a brief parenthetical description would improve immediate readability for readers unfamiliar with the mask-update rule.
Simulated Author's Rebuttal
We thank the referee for these precise comments on the abstract. Both points identify areas where additional clarity or controls would strengthen the presentation. We respond to each below and will revise the manuscript to address them.
read point-by-point responses
-
Referee: [Abstract] Abstract (mechanistic finding paragraph): the attribution of the forward-vs-reverse asymmetry to activation-induced gradient blockades is load-bearing for the central mechanistic claim, yet the manuscript does not report a control that holds the stochastic mask schedule, sampling probabilities, and refresh rule fixed while reversing only the progression order. Without this isolation, the observed pattern could arise from mask-depth interactions rather than blockade timing.
Authors: We agree that a control isolating progression order while holding the mask schedule, sampling probabilities, and refresh rule fixed is the cleanest way to attribute the asymmetry to blockade timing. In the current experiments the stochastic partial masks are generated and applied according to the progression direction, so a pure reversal requires re-indexing the schedule to the opposite layer order. We will add this exact control experiment (same random seeds, same per-layer mask probabilities and refresh, only the direction reversed) to the revised manuscript and report the resulting accuracy curves. This will be placed in the ablation section alongside the existing forward/reverse comparison. revision: yes
-
Referee: [Abstract] Abstract (results paragraph): the reported accuracy deltas are presented as evidence that StoMPP improves over vanilla STE, but no table or section specifies whether the STE baseline used identical optimizer settings, learning-rate schedules, or binarization thresholds; this detail is required to confirm that the depth-dependent gains are not partly due to mismatched hyper-parameters.
Authors: All reported comparisons to vanilla STE were performed with identical optimizer (SGD with the same momentum and weight decay), identical learning-rate schedule (including warm-up and decay points), identical binarization threshold (0.5 after clipping), and the same data augmentation and initialization. These settings are stated in the experimental protocol section and were reused without modification for the STE baseline. We will add an explicit sentence in the abstract results paragraph and a footnote in the main results table confirming that the baseline shares the exact hyper-parameter configuration. revision: yes
Circularity Check
No circularity: empirical method and ablations are self-contained
full rationale
The paper introduces StoMPP as a training procedure and supports its claims (depth-scaling gains, forward-vs-reverse asymmetry) via experimental results on multiple architectures and ablations performed in the STE-free regime. No equations, fitted parameters, or self-citations are presented that reduce the reported gains or the attributed mechanism (activation-induced gradient blockades) to a definitional identity or to the same inputs by construction. The progression order and mask schedule are described as independent design choices whose effects are measured externally rather than derived from themselves.
Axiom & Free-Parameter Ledger
free parameters (1)
- binarization progression schedule
invented entities (1)
-
StoMPP procedure
no independent evidence
Reference graph
Works this paper leans on
-
[1]
and Gal, Yarin , year=
Alizadeh, Milad and Fernández-Marqués, Javier and Lane, Nicholas D. and Gal, Yarin , year=. An Empirical study of Binary Neural Networks’ Optimisation , url=
-
[2]
ProxQuant: Quantized Neural Networks via Proximal Operators
Bai, Yu and Wang, Yu-Xiang and Liberty, Edo , year=. ProxQuant: Quantized Neural Networks via Proximal Operators , url=. doi:10.48550/arXiv.1810.00861 , abstractNote=
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1810.00861
-
[3]
Learning low-precision neural networks without Straight-Through Estimator(STE)
Liu, Zhi-Gang and Mattina, Matthew , year=. Learning low-precision neural networks without Straight-Through Estimator(STE) , url=. doi:10.48550/arXiv.1903.01061 , abstractNote=
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1903.01061 1903
-
[4]
Learning Multiple Layers of Features from Tiny Images , journal =
Krizhevsky, Alex , year =. Learning Multiple Layers of Features from Tiny Images , journal =
-
[5]
arXiv preprint arXiv:1409.0575 , year=
ImageNet Large Scale Visual Recognition Challenge , author=. arXiv preprint arXiv:1409.0575 , year=
-
[6]
Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation
Bengio, Yoshua and Léonard, Nicholas and Courville, Aaron , year=. Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation , url=. doi:10.48550/arXiv.1308.3432 , abstractNote=
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1308.3432
-
[7]
Chinese Journal of Engineering , author=
A survey of quantization methods for deep neural networks , volume=. Chinese Journal of Engineering , author=. 2023 , month=oct, pages=. doi:10.13374/j.issn2095-9389.2022.12.27.004 , abstractNote=
-
[8]
Courbariaux, Matthieu and Hubara, Itay and Soudry, Daniel and El-Yaniv, Ran and Bengio, Yoshua , year=. Binarized Neural Networks: Training Deep Neural Networks with Weights and Activations Constrained to +1 or -1 , url=. doi:10.48550/arXiv.1602.02830 , abstractNote=
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1602.02830
-
[9]
Imagenet: A large-scale hierarchical image database , booktitle=
Deng, Jia and Dong, Wei and Socher, Richard and Li, Li-Jia and Li, Kai and Fei-Fei, Li , year=. Imagenet: A large-scale hierarchical image database , booktitle=
-
[10]
IEEE Transactions on Nanotechnology , author=
Mask Technique for Fast and Efficient Training of Binary Resistive Crossbar Arrays , volume=. IEEE Transactions on Nanotechnology , author=. 2019 , pages=. doi:10.1109/TNANO.2019.2927493 , abstractNote=
-
[11]
IEEE Transactions on Parallel and Distributed Systems , author=
TaiChi: A Hybrid Compression Format for Binary Sparse Matrix-Vector Multiplication on GPU , volume=. IEEE Transactions on Parallel and Distributed Systems , author=. 2022 , month=dec, pages=. doi:10.1109/TPDS.2022.3170501 , number=
-
[12]
Soft then Hard: Rethinking the Quantization in Neural Image Compression , url=
Guo, Zongyu and Zhang, Zhizheng and Feng, Runsen and Chen, Zhibo , year=. Soft then Hard: Rethinking the Quantization in Neural Image Compression , url=. doi:10.48550/arXiv.2104.05168 , abstractNote=
-
[13]
Stochastic Computing for Hardware Implementation of Binarized Neural Networks , volume=. IEEE Access , author=. 2019 , pages=. doi:10.1109/ACCESS.2019.2921104 , abstractNote=
-
[14]
Training Binary Weight Networks via Semi-Binary Decomposition , ISBN=
Hu, Qinghao and Li, Gang and Wang, Peisong and Zhang, Yifan and Cheng, Jian , editor=. Training Binary Weight Networks via Semi-Binary Decomposition , ISBN=. Computer Vision – ECCV 2018 , publisher=. 2018 , pages=. doi:10.1007/978-3-030-01261-8_39 , abstractNote=
-
[15]
Huh, Minyoung and Cheung, Brian and Agrawal, Pulkit and Isola, Phillip , year=. Straightening Out the Straight-Through Estimator: Overcoming Optimization Challenges in Vector Quantized Networks , url=. doi:10.48550/arXiv.2305.08842 , abstractNote=
-
[16]
Signed Binary Weight Networks , url=
Kuhar, Sachit and Tumanov, Alexey and Hoffman, Judy , year=. Signed Binary Weight Networks , url=. doi:10.48550/arXiv.2211.13838 , abstractNote=
-
[17]
Lahoud, Fayez and Achanta, Radhakrishna and Márquez-Neila, Pablo and Süsstrunk, Sabine , year=. Self-Binarizing Networks , url=. doi:10.48550/arXiv.1902.00730 , abstractNote=
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1902.00730 1902
-
[18]
ReActNet: Towards Precise Binary Neural Network with Generalized Activation Functions , url=
Liu, Zechun and Shen, Zhiqiang and Savvides, Marios and Cheng, Kwang-Ting , year=. ReActNet: Towards Precise Binary Neural Network with Generalized Activation Functions , url=. doi:10.48550/arXiv.2003.03488 , abstractNote=
-
[19]
Piggyback: Adapting a Single Network to Multiple Tasks by Learning to Mask Weights , ISBN=
Mallya, Arun and Davis, Dillon and Lazebnik, Svetlana , editor=. Piggyback: Adapting a Single Network to Multiple Tasks by Learning to Mask Weights , ISBN=. Computer Vision – ECCV 2018 , publisher=. 2018 , pages=. doi:10.1007/978-3-030-01225-0_5 , abstractNote=
-
[20]
Training Binary Neural Networks via Gaussian Variational Inference and Low-Rank Semidefinite Programming , url=
Orecchia, Lorenzo and Hu, Jiawei and He, Xue and Mark, Wang Zhe and Yang, Xulei and Wu, Min and Geng, Xue , year=. Training Binary Neural Networks via Gaussian Variational Inference and Low-Rank Semidefinite Programming , url=
-
[21]
Binary Neural Networks: A Survey , url=. arXiv.org , author=. 2020 , month=mar, language=. doi:10.1016/j.patcog.2020.107281 , abstractNote=
-
[22]
XNOR-Net: ImageNet Classification Using Binary Convolutional Neural Networks
Rastegari, Mohammad and Ordonez, Vicente and Redmon, Joseph and Farhadi, Ali , year=. XNOR-Net: ImageNet Classification Using Binary Convolutional Neural Networks , url=. doi:10.48550/arXiv.1603.05279 , abstractNote=
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1603.05279
-
[23]
Park, Geon and Yoon, Jaehong and Zhang, Haiyang and Zhang, Xing and Hwang, Sung Ju and Eldar, Yonina C. , year=. BiTAT: Neural Network Binarization with Task-dependent Aggregated Transformation , url=. doi:10.48550/arXiv.2207.01394 , abstractNote=
-
[24]
Liu, Zechun and Wu, Baoyuan and Luo, Wenhan and Yang, Xin and Liu, Wei and Cheng, Kwang-Ting , year=. Bi-Real Net: Enhancing the Performance of 1-bit CNNs With Improved Representational Capability and Advanced Training Algorithm , url=. doi:10.48550/arXiv.1808.00278 , abstractNote=
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1808.00278
-
[25]
Robust and Tiny Binary Neural Networks using Gradient-based Explainability Methods , ISBN=
Sabih, Muhammad and Yayla, Mikail and Hannig, Frank and Teich, Jürgen and Chen, Jian-Jia , year=. Robust and Tiny Binary Neural Networks using Gradient-based Explainability Methods , ISBN=. doi:10.1145/3578356.3592595 , booktitle=
-
[26]
IEICE Transactions on Information and Systems , author=
Extending Binary Neural Networks to Bayesian Neural Networks with Probabilistic Interpretation of Binary Weights , volume=. IEICE Transactions on Information and Systems , author=. 2024 , pages=. doi:10.1587/transinf.2023LOP0009 , abstractNote=
-
[27]
Shekhovtsov, Alexander and Yanush, Viktor , editor=. Reintroducing Straight-Through Estimators as Principled Methods for Stochastic Binary Networks , ISBN=. Pattern Recognition , publisher=. 2021 , pages=. doi:10.1007/978-3-030-92659-5_7 , abstractNote=
-
[28]
Proceedings of the AAAI Conference on Artificial Intelligence , author=
How to Train a Compact Binary Neural Network with High Accuracy? , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , author=. 2017 , month=feb, language=. doi:10.1609/aaai.v31i1.10862 , abstractNote=
-
[29]
BiPer: Binary Neural Networks using a Periodic Function , url=
Vargas, Edwin and Correa, Claudia and Hinojosa, Carlos and Arguello, Henry , year=. BiPer: Binary Neural Networks using a Periodic Function , url=. doi:10.48550/arXiv.2404.01278 , abstractNote=
-
[30]
Forward and Backward Information Retention for Accurate Binary Neural Networks , url=
Qin, Haotong and Gong, Ruihao and Liu, Xianglong and Shen, Mingzhu and Wei, Ziran and Yu, Fengwei and Song, Jingkuan , year=. Forward and Backward Information Retention for Accurate Binary Neural Networks , url=. doi:10.48550/arXiv.1909.10788 , abstractNote=
-
[31]
arXiv.org , author=
XNOR-Net++: Improved Binary Neural Networks , url=. arXiv.org , author=. 2019 , month=sept, language=
2019
-
[32]
Learning Accurate Low-Bit Deep Neural Networks with Stochastic Quantization
Dong, Yinpeng and Ni, Renkun and Li, Jianguo and Chen, Yurong and Zhu, Jun and Su, Hang , year=. Learning Accurate Low-Bit Deep Neural Networks with Stochastic Quantization , url=. doi:10.48550/arXiv.1708.01001 , abstractNote=
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1708.01001
-
[33]
IEEE Transactions on Very Large Scale Integration (VLSI) Systems , author=
An Energy-Efficient Architecture for Binary Weight Convolutional Neural Networks , volume=. IEEE Transactions on Very Large Scale Integration (VLSI) Systems , author=. 2018 , month=feb, pages=. doi:10.1109/TVLSI.2017.2767624 , abstractNote=
-
[34]
OvSW: Overcoming Silent Weights for Accurate Binary Neural Networks , ISBN=
Xiang, Jingyang and Chen, Zuohui and Li, Siqi and Wu, Qing and Liu, Yong , editor=. OvSW: Overcoming Silent Weights for Accurate Binary Neural Networks , ISBN=. Computer Vision – ECCV 2024 , publisher=. 2025 , pages=. doi:10.1007/978-3-031-73414-4_1 , abstractNote=
-
[35]
Deepsd: Automatic deep skinning and pose space deformation for 3d garment animation
ReCU: Reviving the Dead Weights in Binary Neural Networks , ISSN=. 2021 IEEE/CVF International Conference on Computer Vision (ICCV) , author=. 2021 , month=oct, pages=. doi:10.1109/ICCV48922.2021.00515 , abstractNote=
-
[36]
Ren, Ao and Zhang, Tianyun and Ye, Shaokai and Li, Jiayu and Xu, Wenyao and Qian, Xuehai and Lin, Xue and Wang, Yanzhi , year=. ADMM-NN: An Algorithm-Hardware Co-Design Framework of DNNs Using Alternating Direction Method of Multipliers , url=. doi:10.48550/arXiv.1812.11677 , abstractNote=
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1812.11677
-
[37]
LQ-Nets: Learned Quantization for Highly Accurate and Compact Deep Neural Networks
Zhang, Dongqing and Yang, Jiaolong and Ye, Dongqiangzi and Hua, Gang , year=. LQ-Nets: Learned Quantization for Highly Accurate and Compact Deep Neural Networks , url=. doi:10.48550/arXiv.1807.10029 , abstractNote=
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1807.10029
-
[38]
PACT: Parameterized Clipping Activation for Quantized Neural Networks
Choi, Jungwook and Wang, Zhuo and Venkataramani, Swagath and Chuang, Pierce I.-Jen and Srinivasan, Vijayalakshmi and Gopalakrishnan, Kailash , year=. PACT: Parameterized Clipping Activation for Quantized Neural Networks , url=. doi:10.48550/arXiv.1805.06085 , abstractNote=
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1805.06085
-
[39]
Esser, Steven K. and McKinstry, Jeffrey L. and Bablani, Deepika and Appuswamy, Rathinakumar and Modha, Dharmendra S. , year=. Learned Step Size Quantization , url=. doi:10.48550/arXiv.1902.08153 , abstractNote=
-
[40]
DoReFa-Net: Training Low Bitwidth Convolutional Neural Networks with Low Bitwidth Gradients
Zhou, Shuchang and Wu, Yuxin and Ni, Zekun and Zhou, Xinyu and Wen, He and Zou, Yuheng , year=. DoReFa-Net: Training Low Bitwidth Convolutional Neural Networks with Low Bitwidth Gradients , url=. doi:10.48550/arXiv.1606.06160 , abstractNote=
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1606.06160
-
[41]
Overcoming Oscillations in Quantization-Aware Training , url=
Nagel, Markus and Fournarakis, Marios and Bondarenko, Yelysei and Blankevoort, Tijmen , year=. Overcoming Oscillations in Quantization-Aware Training , url=. doi:10.48550/arXiv.2203.11086 , abstractNote=
-
[42]
Quantized Neural Networks: Training Neural Networks with Low Precision Weights and Activations
Hubara, Itay and Courbariaux, Matthieu and Soudry, Daniel and El-Yaniv, Ran and Bengio, Yoshua , year=. Quantized Neural Networks: Training Neural Networks with Low Precision Weights and Activations , url=. doi:10.48550/arXiv.1609.07061 , abstractNote=
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1609.07061
-
[43]
Deep Residual Learning for Image Recognition
He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian , year=. Deep Residual Learning for Image Recognition , url=. doi:10.48550/arXiv.1512.03385 , abstractNote=
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1512.03385
-
[44]
BinaryRelax: A Relaxation Approach For Training Deep Neural Networks With Quantized Weights
Yin, Penghang and Zhang, Shuai and Lyu, Jiancheng and Osher, Stanley and Qi, Yingyong and Xin, Jack , year=. BinaryRelax: A Relaxation Approach For Training Deep Neural Networks With Quantized Weights , url=. doi:10.48550/arXiv.1801.06313 , abstractNote=
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1801.06313
-
[45]
Artificial Intelligence Review , author=
A comprehensive review of Binary Neural Network , volume=. Artificial Intelligence Review , author=. 2023 , month=nov, pages=. doi:10.1007/s10462-023-10464-w , abstractNote=
-
[46]
Incremental Network Quantization: Towards Lossless CNNs with Low-Precision Weights
Zhou, Aojun and Yao, Anbang and Guo, Yiwen and Xu, Lin and Chen, Yurong , year=. Incremental Network Quantization: Towards Lossless CNNs with Low-Precision Weights , url=. doi:10.48550/arXiv.1702.03044 , abstractNote=
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1702.03044
-
[47]
2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition , author=
Towards Effective Low-Bitwidth Convolutional Neural Networks , ISSN=. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition , author=. 2018 , month=june, pages=. doi:10.1109/CVPR.2018.00826 , abstractNote=
-
[48]
Advances in Neural Information Processing Systems , pages=
Towards Accurate Binary Convolutional Neural Network , author=. Advances in Neural Information Processing Systems , pages=
-
[49]
Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
MeliusNet: An Improved Network Architecture for Binary Neural Networks , author=. Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
-
[50]
Neurocomputing , volume=
Training Binary Neural Networks with Knowledge Transfer , author=. Neurocomputing , volume=
-
[51]
Proceedings of the 38th International Conference on Machine Learning , pages=
How Do Adam and Training Strategies Help BNNs Optimization? , author=. Proceedings of the 38th International Conference on Machine Learning , pages=
-
[52]
European Conference on Computer Vision , pages=
ReActNet: Towards Precise Binary Neural Network with Generalized Activation Functions , author=. European Conference on Computer Vision , pages=
-
[53]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Improving Accuracy of Binary Neural Networks using Unbalanced Activation Distribution , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[54]
2022 , eprint=
AdaBin: Improving Binary Neural Networks with Adaptive Binary Sets , author=. 2022 , eprint=
2022
-
[55]
2018 , eprint=
Projection Convolutional Neural Networks for 1-bit CNNs via Discrete Back Propagation , author=. 2018 , eprint=
2018
-
[56]
QKD: Quantization-aware Knowledge Distillation , journal=ArXiv, url=
Kim, Jangho and Bhalgat, Yash and Lee, Jinwon and Patel, Chirag and Kwak, Nojun , year=. QKD: Quantization-aware Knowledge Distillation , journal=ArXiv, url=. doi:10.48550/arXiv.1911.12491 , abstractNote=
-
[57]
Tongtong Gao and Yue Zhou and Shukai Duan and Xiaofang Hu , keywords =. Memristive KDG-BNN: Memristive binary neural networks trained via knowledge distillation and generative adversarial networks , journal =. 2022 , issn =. doi:https://doi.org/10.1016/j.knosys.2022.108962 , url =
-
[58]
2019 , eprint=
Circulant Binary Convolutional Networks: Enhancing the Performance of 1-bit DCNNs with Circulant Back Propagation , author=. 2019 , eprint=
2019
-
[59]
2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW) , year=
BinaryDenseNet: Developing an Architecture for Binary Neural Networks , author=. 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW) , year=
2019
-
[60]
2022 , eprint=
Structured Binary Neural Networks for Image Recognition , author=. 2022 , eprint=
2022
-
[61]
A Bop and Beyond: A Second Order Optimizer for Binarized Neural Networks , url=
Suarez-Ramirez, Cuauhtemoc Daniel and Gonzalez-Mendoza, Miguel and Chang, Leonardo and Ochoa-Ruiz, Gilberto and Duran-Vega, Mario Alberto , year=. A Bop and Beyond: A Second Order Optimizer for Binarized Neural Networks , url=. doi:10.1109/cvprw53098.2021.00140 , booktitle=
-
[62]
2019 , eprint=
Latent Weights Do Not Exist: Rethinking Binarized Neural Network Optimization , author=. 2019 , eprint=
2019
-
[63]
2020 , eprint=
BinaryDuo: Reducing Gradient Mismatch in Binary Activation Network by Coupling Binary Activations , author=. 2020 , eprint=
2020
-
[64]
2019 , eprint=
Defensive Quantization: When Efficiency Meets Robustness , author=. 2019 , eprint=
2019
-
[65]
International Conference on Learning Representations , year=
Loss-aware Binarization of Deep Networks , author=. International Conference on Learning Representations , year=
-
[66]
Shan, Gu and Guoyin, Zhang and Chengwei, Jia and Yanxia, Wu , title =. 2023 , issue_date =. doi:10.1016/j.neucom.2023.126431 , journal =
-
[67]
2019 , eprint=
Regularizing Activation Distribution for Training Binarized Deep Networks , author=. 2019 , eprint=
2019
-
[68]
2026 , eprint=
Sparse-BitNet: 1.58-bit LLMs are Naturally Friendly to Semi-Structured Sparsity , author=. 2026 , eprint=
2026
-
[69]
BitNet: Scaling 1-bit Transformers for Large Language Models
Wang, Hongyu and Ma, Shuming and Dong, Li and Huang, Shaohan and Wang, Huaijie and Ma, Lingxiao and Yang, Fan and Wang, Ruiping and Wu, Yi and Wei, Furu , year=. BitNet: Scaling 1-bit Transformers for Large Language Models , url=. doi:10.48550/arXiv.2310.11453 , abstractNote=
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.11453
-
[70]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Dosovitskiy, Alexey and Beyer, Lucas and Kolesnikov, Alexander and Weissenborn, Dirk and Zhai, Xiaohua and Unterthiner, Thomas and Dehghani, Mostafa and Minderer, Matthias and Heigold, Georg and Gelly, Sylvain and Uszkoreit, Jakob and Houlsby, Neil , year=. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale , url=. doi:10.48550/arX...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2010.11929 2010
-
[71]
BinaryBERT: Pushing the Limit of BERT Quantization , url=
Bai, Haoli and Zhang, Wei and Hou, Lu and Shang, Lifeng and Jin, Jing and Jiang, Xin and Liu, Qun and Lyu, Michael and King, Irwin , year=. BinaryBERT: Pushing the Limit of BERT Quantization , url=. doi:10.48550/arXiv.2012.15701 , abstractNote=
-
[72]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina , year=. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding , url=. doi:10.48550/arXiv.1810.04805 , abstractNote=
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1810.04805
-
[73]
On Uniform Scalar Quantization for Learned Image Compression , url=
Zhang, Haotian and Li, Li and Liu, Dong , year=. On Uniform Scalar Quantization for Learned Image Compression , url=. doi:10.48550/arXiv.2309.17051 , abstractNote=
-
[74]
BiT: Robustly Binarized Multi-distilled Transformer , url=
Liu, Zechun and Oguz, Barlas and Pappu, Aasish and Xiao, Lin and Yih, Scott and Li, Meng and Krishnamoorthi, Raghuraman and Mehdad, Yashar , year=. BiT: Robustly Binarized Multi-distilled Transformer , url=. doi:10.48550/arXiv.2205.13016 , abstractNote=
-
[75]
BiBERT: Accurate Fully Binarized BERT , url=
Qin, Haotong and Ding, Yifu and Zhang, Mingyuan and Yan, Qinghua and Liu, Aishan and Dang, Qingqing and Liu, Ziwei and Liu, Xianglong , year=. BiBERT: Accurate Fully Binarized BERT , url=. doi:10.48550/arXiv.2203.06390 , abstractNote=
-
[76]
arXiv.org , author=
GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding , url=. arXiv.org , author=. 2018 , month=apr, language=
2018
-
[77]
Conference on Empirical Methods in Natural Language Processing , year=
Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank , author=. Conference on Empirical Methods in Natural Language Processing , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.