From Uncertain Judgments to Calibrated Rankings: Conformal Elo Estimation for LLM Evaluation
Pith reviewed 2026-06-27 07:43 UTC · model grok-4.3
The pith
Two uncertainty layers turn LLM judge outputs into Elo ratings within 17.9 points of human ratings on average.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
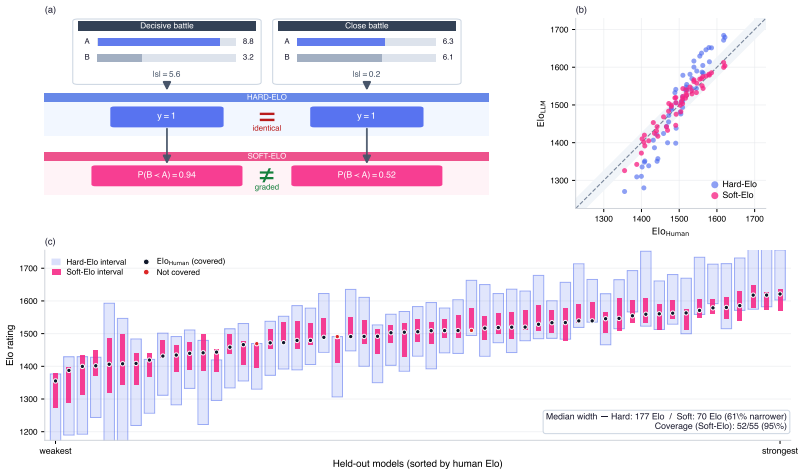
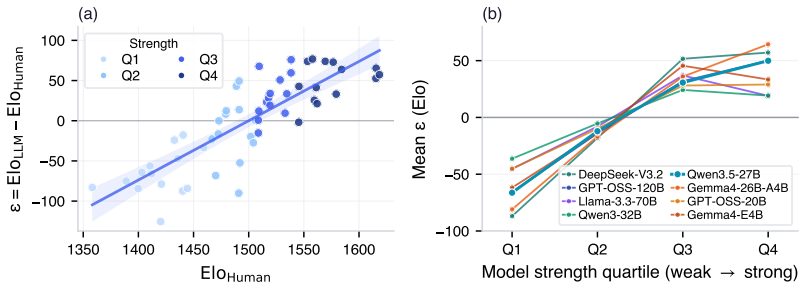
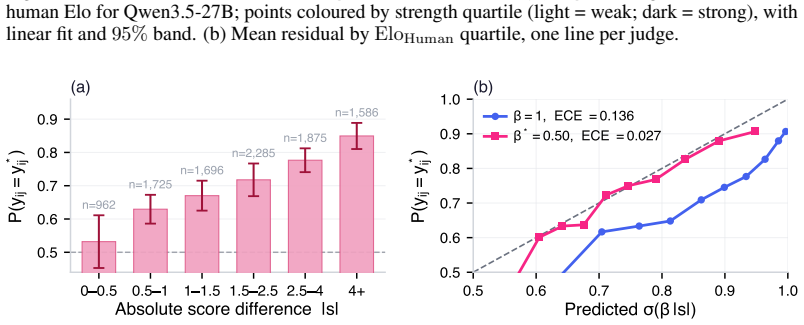
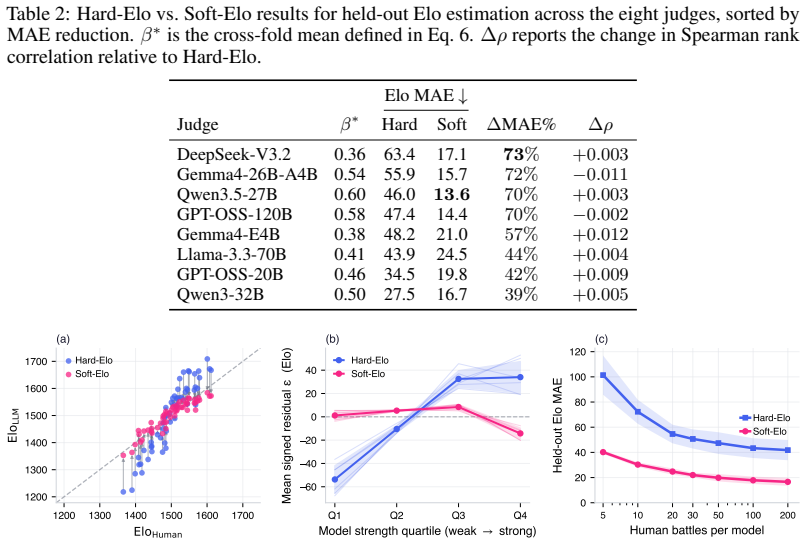
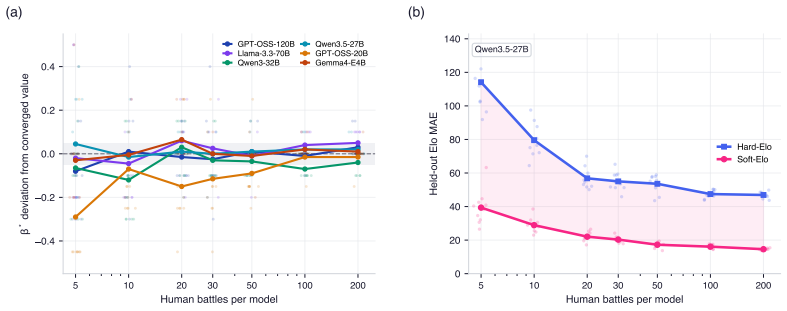
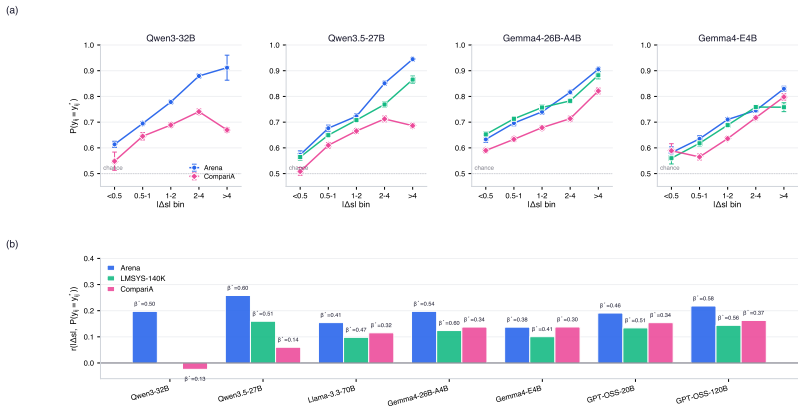
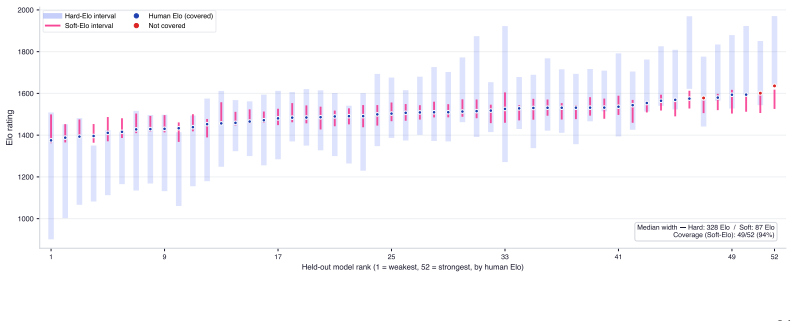
The central claim is that propagating calibrated win probabilities from LLM judge scores into the Bradley-Terry procedure, followed by split conformal prediction on the resulting Elo residuals against human ratings, yields LLM-derived ratings whose average error is 17.9 Elo points and whose intervals provide distribution-free marginal coverage.
What carries the argument
The two-layer pipeline of local uncertainty propagation via calibrated win probabilities into the Bradley-Terry model and global application of split conformal prediction to Elo rating residuals.
If this is right
- LLM-derived Elo ratings achieve an average absolute error of 17.9 points relative to human-derived ratings across held-out models.
- Prediction intervals around the Elo estimates satisfy marginal coverage guarantees regardless of the underlying error distribution.
- Developers can obtain both calibrated point estimates and honest uncertainty bounds for new models without conducting large human annotation campaigns.
- The method accounts for judge errors such as position bias and intransitivity through the uncertainty propagation step.
Where Pith is reading between the lines
- The local propagation technique could be adapted to improve ranking systems that do not rely on the Bradley-Terry model.
- If the exchangeability assumption holds across diverse model families, the conformal layer may generalize to other automated evaluation settings.
- Testing the method on models released after the held-out set would directly check whether the coverage guarantees persist in practice.
Load-bearing premise
The held-out models used to fit the conformal predictor are exchangeable with the models that will be evaluated in the future.
What would settle it
Collecting human Elo ratings for a fresh set of models and finding that the conformal prediction intervals cover the true values less often than the target probability.
Figures
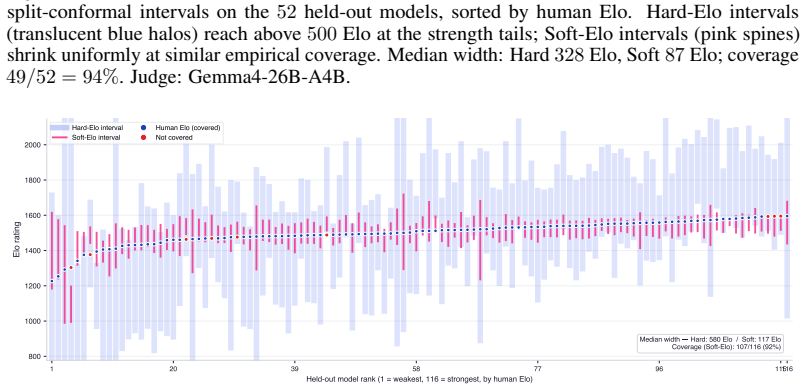
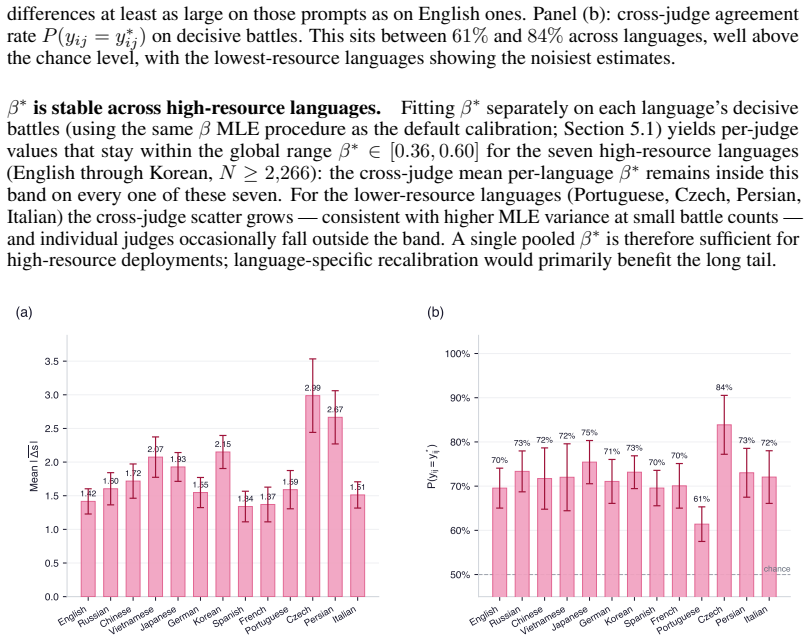
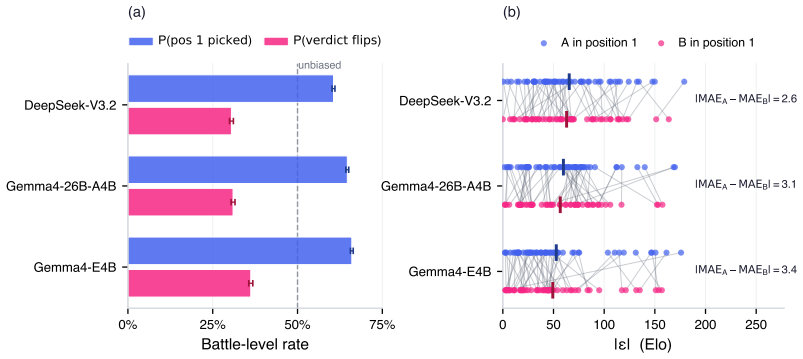
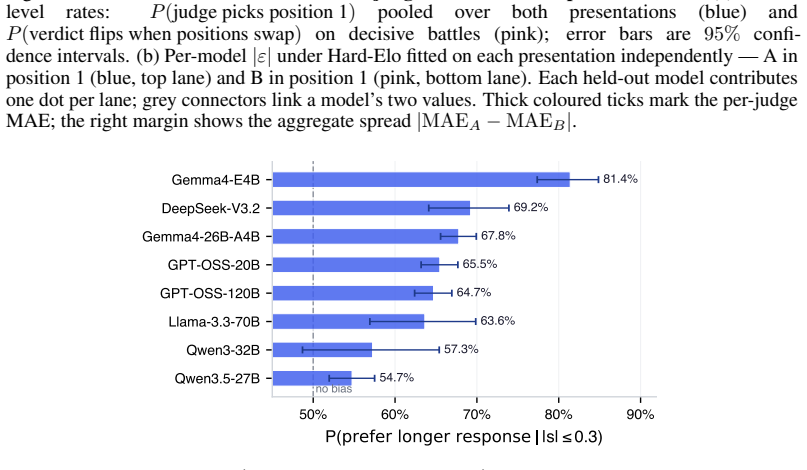
read the original abstract
Evaluating new large language models typically requires costly human annotation campaigns at scale. LLM-as-a-judge offers a cheaper alternative, but judge scores carry systematic errors - such as position bias, self-preference, or intransitivity - that can strongly miscalibrate the resulting rankings. We quantify the resulting judge-human disagreement at two complementary levels. At the local level, we estimate per-battle uncertainty from the judge's own score differences by propagating calibrated win probabilities rather than hard labels into the Bradley-Terry procedure. This alone provides a drastic improvement to Elo estimation accuracy, bringing LLM-derived ratings within 17.9 Elo MAE of human-derived ones when averaged over 55 held-out models on LMArena. At the global level, we apply split conformal prediction to the residual gap between LLM-derived and human-derived Elo ratings across held-out models, producing prediction intervals with distribution-free marginal coverage guarantees that account for irreducible LLM-human disagreement. Together, these two layers yield a low-cost evaluation tool that provides developers with calibrated Elo estimates and honest uncertainty bounds, without access to large-scale human annotations.To facilitate reproducibility, we release our code at https://github.com/kargibora/SoftElo .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a two-layer approach to calibrate Elo ratings derived from LLM-as-a-judge evaluations against human ratings. At the local level, per-battle uncertainty is estimated by propagating calibrated win probabilities (rather than hard labels) into the Bradley-Terry model. At the global level, split conformal prediction is applied to the residuals between LLM-derived and human-derived Elo ratings on held-out models to produce prediction intervals with distribution-free marginal coverage. The work reports that the local layer alone reduces mean absolute error to 17.9 Elo across 55 held-out models on LMArena and claims the combined method yields calibrated estimates plus honest uncertainty bounds without large-scale human annotations; code is released for reproducibility.
Significance. If the empirical gains and coverage guarantees hold under the stated assumptions, the method would provide a practical, low-cost tool for developers to obtain calibrated LLM rankings with uncertainty quantification. The explicit code release is a positive contribution to reproducibility. However, the significance is limited by the dependence on an exchangeability assumption whose validity for future models is not demonstrated, and by the absence of sufficient experimental protocol details to allow independent verification of the 17.9 Elo figure.
major comments (2)
- [Abstract / global layer] Abstract and global-layer description: the claim of distribution-free marginal coverage for the conformal prediction intervals rests on the exchangeability of the 55 held-out calibration models with future evaluation models. The manuscript does not provide evidence or sensitivity analysis addressing whether evolving LLM distributions, judge biases, or intransitivities would violate this assumption and thereby invalidate the coverage guarantee for new models.
- [Experimental results] Experimental results paragraph: the reported 17.9 Elo MAE on 55 held-out models is presented without the full protocol (data splits, judge-score calibration procedure, selection criteria for the 55 models, or whether any post-hoc tuning occurred). This omission makes it impossible to assess whether the improvement is robust or potentially inflated by selection effects.
minor comments (1)
- [Abstract] The abstract states that the local layer 'alone provides a drastic improvement,' but the manuscript should clarify whether the 17.9 MAE figure already incorporates the global conformal layer or is strictly local.
Simulated Author's Rebuttal
We thank the referee for the thoughtful comments on the exchangeability assumption and experimental protocol. We address each major point below with clarifications and proposed revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract / global layer] Abstract and global-layer description: the claim of distribution-free marginal coverage for the conformal prediction intervals rests on the exchangeability of the 55 held-out calibration models with future evaluation models. The manuscript does not provide evidence or sensitivity analysis addressing whether evolving LLM distributions, judge biases, or intransitivities would violate this assumption and thereby invalidate the coverage guarantee for new models.
Authors: The distribution-free marginal coverage guarantee of split conformal prediction holds under the standard exchangeability assumption between calibration and test points, which is stated explicitly in the global-layer section and is a core requirement of the method (see references to conformal prediction literature in the paper). We agree that evolving LLM distributions or changing judge biases could violate exchangeability in deployment, but the guarantee is valid whenever the assumption holds for a given calibration/test pair. We will add a dedicated paragraph in the discussion section acknowledging this limitation and include a sensitivity analysis by randomly subsampling different calibration sets from the 55 models to illustrate robustness under varying conditions. This addresses the concern without overstating the result. revision: partial
-
Referee: [Experimental results] Experimental results paragraph: the reported 17.9 Elo MAE on 55 held-out models is presented without the full protocol (data splits, judge-score calibration procedure, selection criteria for the 55 models, or whether any post-hoc tuning occurred). This omission makes it impossible to assess whether the improvement is robust or potentially inflated by selection effects.
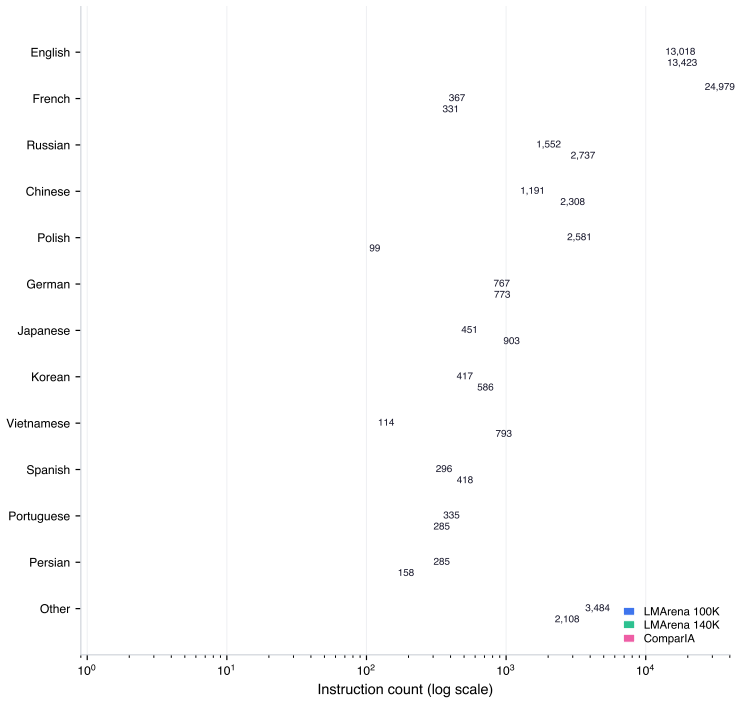
Authors: We acknowledge that the main text omitted a concise summary of the experimental protocol. The 55 models were the most recent entries on the LMArena leaderboard at the time of data collection; battles were split via a random 70/30 train/calibration-test partition with no post-hoc tuning of hyperparameters beyond the described Platt scaling for win-probability calibration on a held-out validation subset of battles. Full details, including exact model IDs and code for the splits, appear in the released repository. We will expand the experimental results section with a dedicated protocol subsection summarizing these elements to enable independent verification. revision: yes
- Empirical demonstration that exchangeability will hold for arbitrary future LLMs is not possible without access to those models and is therefore outside the scope of any single study.
Circularity Check
No significant circularity; claims grounded in held-out validation
full rationale
The paper's derivation chain is self-contained. Local Elo improvements are quantified as 17.9 MAE against independent human-derived ratings on 55 held-out models, and global conformal intervals are produced by applying standard split conformal prediction to observed residuals between LLM and human Elo values. Neither step reduces outputs to inputs by construction, nor relies on self-citations or author-specific uniqueness theorems for load-bearing premises. The exchangeability assumption for coverage is an explicit modeling choice subject to external falsification rather than a definitional tautology.
Axiom & Free-Parameter Ledger
free parameters (1)
- conformal significance level
axioms (1)
- standard math Split conformal prediction yields marginal coverage under exchangeability of calibration and test points
Reference graph
Works this paper leans on
-
[1]
Chatbot arena: An open platform for evaluating LLMs by human preference
Wei-Lin Chiang, Lianmin Zheng, Ying Sheng, Anastasios Nikolas Angelopoulos, Tianle Li, Dacheng Li, Banghua Zhu, Hao Zhang, Michael Jordan, Joseph E Gonzalez, and Ion Stoica. Chatbot arena: An open platform for evaluating LLMs by human preference. InInternational Conference on Machine Learning, volume 235, pages 8359–8388. PMLR, 2024
2024
-
[2]
Lucie Termignon, Simonas Zilinskas, Hadrien P´elissier, Aur´elien Barrot, Nicolas Chesnais, and Elie Gavoty. compar:ia: The french government’s llm arena to collect french-language human prompts and preference data.arXiv preprint arXiv:2602.06669, 2026
arXiv 2026
-
[3]
Gonzalez, and Ion Stoica
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging LLM-as-a-judge with MT-bench and chatbot arena. InThirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2023
2023
-
[4]
Length-controlled alpacaeval: A simple debiasing of automatic evaluators
Yann Dubois, Percy Liang, and Tatsunori Hashimoto. Length-controlled alpacaeval: A simple debiasing of automatic evaluators. InFirst Conference on Language Modeling, 2024
2024
-
[5]
Gonzalez, and Ion Stoica
Tianle Li, Wei-Lin Chiang, Evan Frick, Lisa Dunlap, Tianhao Wu, Banghua Zhu, Joseph E. Gonzalez, and Ion Stoica. From crowdsourced data to high-quality benchmarks: Arena-hard and benchbuilder pipeline. InForty-second International Conference on Machine Learning, 2025
2025
-
[6]
Judging the judges: A systematic study of position bias in LLM-as-a-judge
Lin Shi, Chiyu Ma, Wenhua Liang, Xingjian Diao, Weicheng Ma, and Soroush V osoughi. Judging the judges: A systematic study of position bias in LLM-as-a-judge. InProceedings of the 14th International Joint Conference on Natural Language Processing and the 4th Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics, pages 292...
2025
-
[7]
Bowman, and Shi Feng
Arjun Panickssery, Samuel R. Bowman, and Shi Feng. LLM evaluators recognize and favor their own generations. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
2024
-
[8]
Tuning LLM judge design decisions for 1/1000 of the cost
David Salinas, Omar Swelam, and Frank Hutter. Tuning LLM judge design decisions for 1/1000 of the cost. InProceedings of the 42nd International Conference on Machine Learning, volume 267 ofProceedings of Machine Learning Research, pages 52728–52744. PMLR, 2025
2025
-
[9]
Investigating non-transitivity in llm-as- a-judge
Yi Xu, Laura Ruis, Tim Rockt¨aschel, and Robert Kirk. Investigating non-transitivity in llm-as- a-judge. InProceedings of the 42nd International Conference on Machine Learning, volume 267 ofProceedings of Machine Learning Research, pages 69583–69612. PMLR, 2025
2025
-
[10]
Mediocrity is the key for llm as a judge anchor selection, 2026
Shachar Don-Yehiya, Asaf Yehudai, Leshem Choshen, and Omri Abend. Mediocrity is the key for llm as a judge anchor selection, 2026
2026
-
[11]
Auto-arena: Automating LLM evaluations with agent peer battles and committee discussions
Ruochen Zhao, Wenxuan Zhang, Yew Ken Chia, Weiwen Xu, Deli Zhao, and Lidong Bing. Auto-arena: Automating LLM evaluations with agent peer battles and committee discussions. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors, Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume ...
2025
-
[12]
Pierre Boyeau, Anastasios Nikolas Angelopoulos, Tianle Li, Nir Yosef, Jitendra Malik, and Michael I. Jordan. AutoEval done right: Using synthetic data for model evaluation. In Aarti Singh, Maryam Fazel, Daniel Hsu, Simon Lacoste-Julien, Felix Berkenkamp, Tegan Maharaj, Kiri Wagstaff, and Jerry Zhu, editors,Proceedings of the 42nd International Conference ...
-
[13]
PMLR, 13–19 Jul 2025
2025
-
[14]
Large language models are not fair evaluators
Peiyi Wang, Lei Li, Liang Chen, Zefan Cai, Dawei Zhu, Binghuai Lin, Yunbo Cao, Lingpeng Kong, Qi Liu, Tianyu Liu, and Zhifang Sui. Large language models are not fair evaluators. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 94...
2024
-
[15]
Explaining length bias in LLM-based preference evaluations
Zhengyu Hu, Linxin Song, Jieyu Zhang, Zheyuan Xiao, Tianfu Wang, Zhengyu Chen, Nicholas Jing Yuan, Jianxun Lian, Kaize Ding, and Hui Xiong. Explaining length bias in LLM-based preference evaluations. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Findings of the Association for Computational Lin- guistics: EMNLP...
2025
-
[16]
Self-preference bias in LLM-as-a-judge
Koki Wataoka, Tsubasa Takahashi, and Ryokan Ri. Self-preference bias in LLM-as-a-judge. In Neurips Safe Generative AI Workshop 2024, 2024
2024
-
[17]
Huang, Yunyi Shen, Dennis Wei, and Tamara Broderick
Jenny Y . Huang, Yunyi Shen, Dennis Wei, and Tamara Broderick. Dropping just a handful of preferences can change top large language model rankings. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[18]
Smith, Beyza Ermis, Marzieh Fadaee, and Sara Hooker
Shivalika Singh, Yiyang Nan, Alex Wang, Daniel D’souza, Sayash Kapoor, Ahmet ¨Ust¨un, Sanmi Koyejo, Yuntian Deng, Shayne Longpre, Noah A. Smith, Beyza Ermis, Marzieh Fadaee, and Sara Hooker. The leaderboard illusion. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2026
2026
-
[19]
Bridging human and LLM judgments: Understanding and narrowing the gap
Felipe Maia Polo, Xinhe Wang, Mikhail Yurochkin, Gongjun Xu, Moulinath Banerjee, and Yuekai Sun. Bridging human and LLM judgments: Understanding and narrowing the gap. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
2026
-
[20]
Elo uncovered: Robustness and best practices in language model evaluation
Meriem Boubdir, Edward Kim, Beyza Ermis, Sara Hooker, and Marzieh Fadaee. Elo uncovered: Robustness and best practices in language model evaluation. In Sebastian Gehrmann, Alex Wang, Jo˜ao Sedoc, Elizabeth Clark, Kaustubh Dhole, Khyathi Raghavi Chandu, Enrico Santus, and Hooman Sedghamiz, editors,Proceedings of the Third Workshop on Natural Language Gener...
2023
-
[21]
Siavash Ameli, Siyuan Zhuang, Ion Stoica, and Michael W. Mahoney. A statistical framework for ranking llm-based chatbots. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[22]
am-ELO: A stable framework for arena-based LLM evaluation
Zirui Liu, Jiatong Li, Yan Zhuang, Qi Liu, Shuanghong Shen, Jie Ouyang, Mingyue Cheng, and Shijin Wang. am-ELO: A stable framework for arena-based LLM evaluation. In Aarti Singh, Maryam Fazel, Daniel Hsu, Simon Lacoste-Julien, Felix Berkenkamp, Tegan Maharaj, Kiri Wagstaff, and Jerry Zhu, editors,Proceedings of the 42nd International Conference on Machine...
2025
-
[23]
Beyond bradley-terry models: A general preference model for language model alignment
Yifan Zhang, Ge Zhang, Yue Wu, Kangping Xu, and Quanquan Gu. Beyond bradley-terry models: A general preference model for language model alignment. In Aarti Singh, Maryam Fazel, Daniel Hsu, Simon Lacoste-Julien, Felix Berkenkamp, Tegan Maharaj, Kiri Wagstaff, and Jerry Zhu, editors,Proceedings of the 42nd International Conference on Machine Learning, volum...
2025
-
[24]
Nonparamet- ric llm evaluation from preference data, 2026
Dennis Frauen, Athiya Deviyani, Mihaela van der Schaar, and Stefan Feuerriegel. Nonparamet- ric llm evaluation from preference data, 2026. 11
2026
-
[25]
Reward learning from preference with ties, 2024
Jinsong Liu, Dongdong Ge, and Ruihao Zhu. Reward learning from preference with ties, 2024
2024
-
[26]
Beyond binary preferences: A principled framework for reward modeling with ordinal feedback, 2026
Amirhossein Afsharrad, Ruida Zhou, Luca Viano, Sanjay Lall, and Mohammad Ghavamzadeh. Beyond binary preferences: A principled framework for reward modeling with ordinal feedback, 2026
2026
-
[27]
Reward modeling with ordinal feedback: Wisdom of the crowd
Shang Liu, Yu Pan, Guanting Chen, and Xiaocheng Li. Reward modeling with ordinal feedback: Wisdom of the crowd. In Aarti Singh, Maryam Fazel, Daniel Hsu, Simon Lacoste-Julien, Felix Berkenkamp, Tegan Maharaj, Kiri Wagstaff, and Jerry Zhu, editors,Proceedings of the 42nd International Conference on Machine Learning, volume 267 ofProceedings of Machine Lear...
2025
-
[28]
Improving LLM-as-a-judge inference with the judgment distribution
Victor Wang, Michael JQ Zhang, and Eunsol Choi. Improving LLM-as-a-judge inference with the judgment distribution. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Findings of the Association for Computational Linguistics: EMNLP 2025, pages 23173–23199, Suzhou, China, November 2025. Association for Computational L...
2025
-
[29]
Beyond single-point judgment: Distribution alignment for llm-as-a-judge, 2025
Luyu Chen, Zeyu Zhang, Haoran Tan, Quanyu Dai, Hao Yang, Zhenhua Dong, and Xu Chen. Beyond single-point judgment: Distribution alignment for llm-as-a-judge, 2025
2025
-
[30]
Malin, and Yuan Xue
Zhuohang Li, Xiaowei Li, Chengyu Huang, Guowang Li, Katayoon Goshvadi, Bo Dai, Dale Schuurmans, Paul Zhou, Hamid Palangi, Yiwen Song, Palash Goyal, Murat Kantarcioglu, Bradley A. Malin, and Yuan Xue. Judging with confidence: Calibrating autoraters to preference distributions, 2025
2025
-
[31]
Beyond ordinal preferences: Why alignment needs cardinal human feedback, 2025
Parker Whitfill and Stewy Slocum. Beyond ordinal preferences: Why alignment needs cardinal human feedback, 2025
2025
-
[32]
LLM- rubric: A multidimensional, calibrated approach to automated evaluation of natural language texts
Helia Hashemi, Jason Eisner, Corby Rosset, Benjamin Van Durme, and Chris Kedzie. LLM- rubric: A multidimensional, calibrated approach to automated evaluation of natural language texts. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Proceedings of the 62nd An- nual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers),...
2024
-
[33]
Quantitative llm judges, 2025
Aishwarya Sahoo, Jeevana Kruthi Karnuthala, Tushar Parmanand Budhwani, Pranchal Agarwal, Sankaran Vaidyanathan, Alexa Siu, Franck Dernoncourt, Jennifer Healey, Nedim Lipka, Ryan Rossi, Uttaran Bhattacharya, and Branislav Kveton. Quantitative llm judges, 2025
2025
-
[34]
Analyzing uncertainty of LLM-as-a-judge: Interval evaluations with conformal prediction
Huanxin Sheng, Xinyi Liu, Hangfeng He, Jieyu Zhao, and Jian Kang. Analyzing uncertainty of LLM-as-a-judge: Interval evaluations with conformal prediction. In Christos Christodoulopou- los, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 11286–11328, Su...
2025
-
[35]
Scope: Selective conformal optimized pairwise llm judging, 2026
Sher Badshah, Ali Emami, and Hassan Sajjad. Scope: Selective conformal optimized pairwise llm judging, 2026
2026
-
[36]
Prediction-powered ranking of large language models
Ivi Chatzi, Eleni Straitouri, Suhas Thejaswi, and Manuel Gomez Rodriguez. Prediction-powered ranking of large language models. InAdvances in Neural Information Processing Systems, volume 37, 2024
2024
-
[37]
Alex Hofer, Bhuwan Dhingra, Amir Globerson, and William W
Adam Fisch, Joshua Maynez, R. Alex Hofer, Bhuwan Dhingra, Amir Globerson, and William W. Cohen. Stratified prediction-powered inference for effective hybrid evaluation of language models. InAdvances in Neural Information Processing Systems, volume 37, 2024
2024
-
[38]
Adaptive prediction-powered autoeval with reliability and efficiency guarantees
Sangwoo Park, Matteo Zecchin, and Osvaldo Simeone. Adaptive prediction-powered autoeval with reliability and efficiency guarantees. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
2026
-
[39]
Margarida Campos, Ant´onio Farinhas, Chrysoula Zerva, M´ario A. T. Figueiredo, and Andr´e F. T. Martins. Conformal prediction for natural language processing: A survey.Transactions of the Association for Computational Linguistics, 12:1497–1516, 2024. 12
2024
-
[40]
Rank analysis of incomplete block designs: I
Ralph Allan Bradley and Milton E Terry. Rank analysis of incomplete block designs: I. The method of paired comparisons.Biometrika, 39(3/4):324–345, 1952
1952
-
[41]
Springer, 2005
Vladimir V ovk, Alexander Gammerman, and Glenn Shafer.Algorithmic Learning in a Random World. Springer, 2005
2005
-
[42]
Distribution-free predictive inference for regression.Journal of the American Statistical Associ- ation, 113(523):1094–1111, 2018
Jing Lei, Max G’Sell, Alessandro Rinaldo, Ryan J Tibshirani, and Larry Wasserman. Distribution-free predictive inference for regression.Journal of the American Statistical Associ- ation, 113(523):1094–1111, 2018
2018
-
[43]
Normalized nonconformity measures for regression conformal prediction
Harris Papadopoulos, Alex Gammerman, and Vladimir V ovk. Normalized nonconformity measures for regression conformal prediction. InProceedings of the IASTED International Conference on Artificial Intelligence and Applications, pages 64–69, 2008
2008
-
[44]
H´enaff, Alexander Kolesnikov, Xiaohua Zhai, and A¨aron van den Oord
Lucas Beyer, Olivier J. H´enaff, Alexander Kolesnikov, Xiaohua Zhai, and A¨aron van den Oord. Are we done with ImageNet?arXiv preprint arXiv:2006.07159, 2020
arXiv 2006
-
[45]
Conformal prediction beyond exchangeability.Annals of Statistics, 51(2):816–845, 2023
Rina Foygel Barber, Emmanuel J Cand`es, Aaditya Ramdas, and Ryan J Tibshirani. Conformal prediction beyond exchangeability.Annals of Statistics, 51(2):816–845, 2023. 13 A Judge Protocol: System Prompt and Criteria Definitions System Prompt Judges receive the following system prompt; the placeholders are filled with the criterion descriptions below, an opt...
2023
-
[46]
Penalize missing requested parts or deviating from constraints
Adherence.Follows the user’s instructions and constraints precisely: required format, scope, style constraints, and any do/don’t requirements. Penalize missing requested parts or deviating from constraints. 10 Fully follows the user’s instructions and constraints, including format and scope. 7 Mostly follows the request but misses some details or adds min...
-
[47]
Provides useful steps, options, or explanations tailored to the request
Helpfulness.Advances the user’s goal with relevant, actionable content. Provides useful steps, options, or explanations tailored to the request. Penalize generic filler or non-responsive content. 10 Directly solves the user’s problem with highly useful, actionable, and relevant content. 7 Generally helpful and relevant, but misses some useful detail or op...
-
[48]
Avoids hallucinations and unwar- ranted specifics
Factuality.Information is correct and appropriately qualified. Avoids hallucinations and unwar- ranted specifics. If uncertain, expresses uncertainty and does not fabricate sources, citations, or details. 10 Accurate and well-qualified throughout, with no fabricated or unsupported claims. 7 Mostly accurate, with only minor imprecision or insufficient qual...
-
[49]
Addresses all sub-questions and important constraints
Completeness.Covers the key aspects of the request without major omissions. Addresses all sub-questions and important constraints. Penalize partial answers or skipped items. 10 Covers all major parts of the request with no important omissions. 7 Covers the main request but misses some secondary details or sub-parts. 4 Only partially addresses the request;...
-
[50]
A wins”, “tie
Fluency.Language and presentation quality: fluent, readable, appropriately concise, and well- formatted. Tone is appropriate for the user/context. 10 Fluent, natural, polished language with strong readability and appropriate tone. 7 Generally fluent and readable, with some awkward phrasing or minor disfluencies. 4 Frequent disfluencies or formatting issue...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.