Investigating Multi-Agent Deliberation in Law
Pith reviewed 2026-07-01 01:40 UTC · model grok-4.3
The pith
Multi-agent deliberation frameworks match single LLMs on legal tasks but generate distinct answers that solve different cases.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
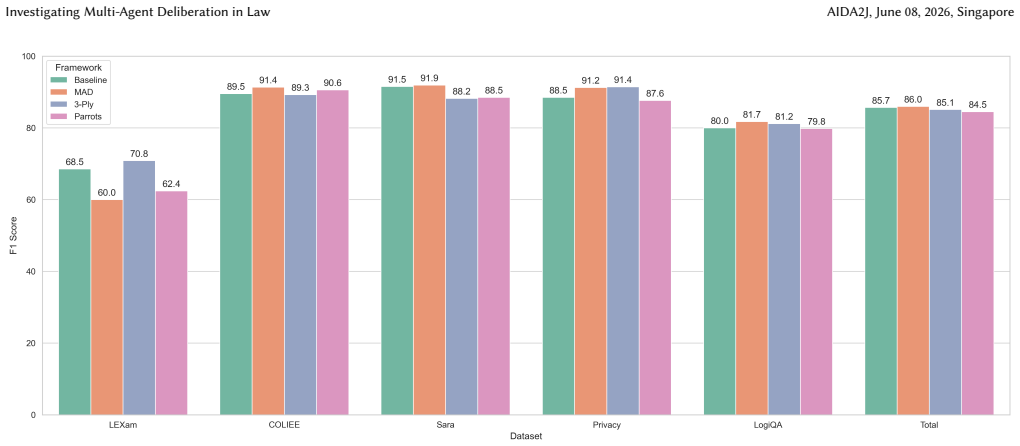
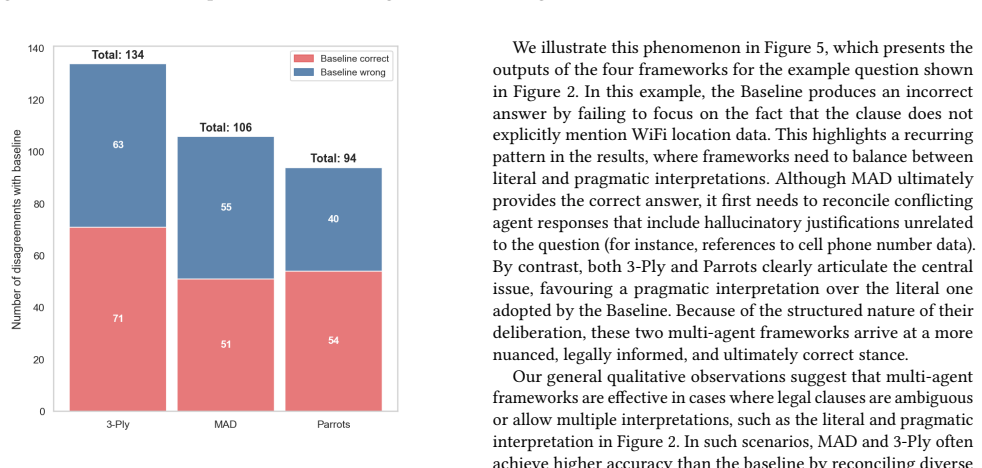
Multi-agent deliberation methods for legal reasoning using LLMs achieve comparable performance to baseline large language models but produce significantly distinct answers. These approaches can successfully solve cases that the baseline fails to address and vice versa. Qualitative evaluation shows multi-agent frameworks appear better suited for answering questions that require critical thinking from multiple perspectives.
What carries the argument
Multi-agent deliberation (MAD) frameworks, including two novel ones inspired by courtroom procedures and legal argumentation, that generate and compare multiple reasoning paths before reaching an answer.
If this is right
- Multi-agent systems can address legal cases that single large language models cannot.
- They show advantages on tasks that require critical thinking from multiple perspectives.
- Law-inspired multi-agent designs offer a viable direction for AI tools in the legal domain.
- The distinct answer sets suggest multi-agent methods can complement rather than duplicate monolithic approaches.
Where Pith is reading between the lines
- Pairing outputs from multi-agent and single-model systems could increase the total number of cases solved without raising overall error rates.
- The observed answer differences may point to underlying limits in how single models explore alternative legal interpretations.
- The same deliberation pattern could be tested in other high-stakes domains that value multiple viewpoints, such as medical diagnosis or policy analysis.
Load-bearing premise
The performance differences and qualitative advantages seen in benchmarks will continue to appear under real-world legal conditions with varied case complexity and adversarial inputs.
What would settle it
A side-by-side test of the multi-agent frameworks and baseline models on a fresh collection of actual court cases that includes adversarial arguments and domain-specific constraints, checking whether the complementary success rates and critical-thinking edge persist.
Figures
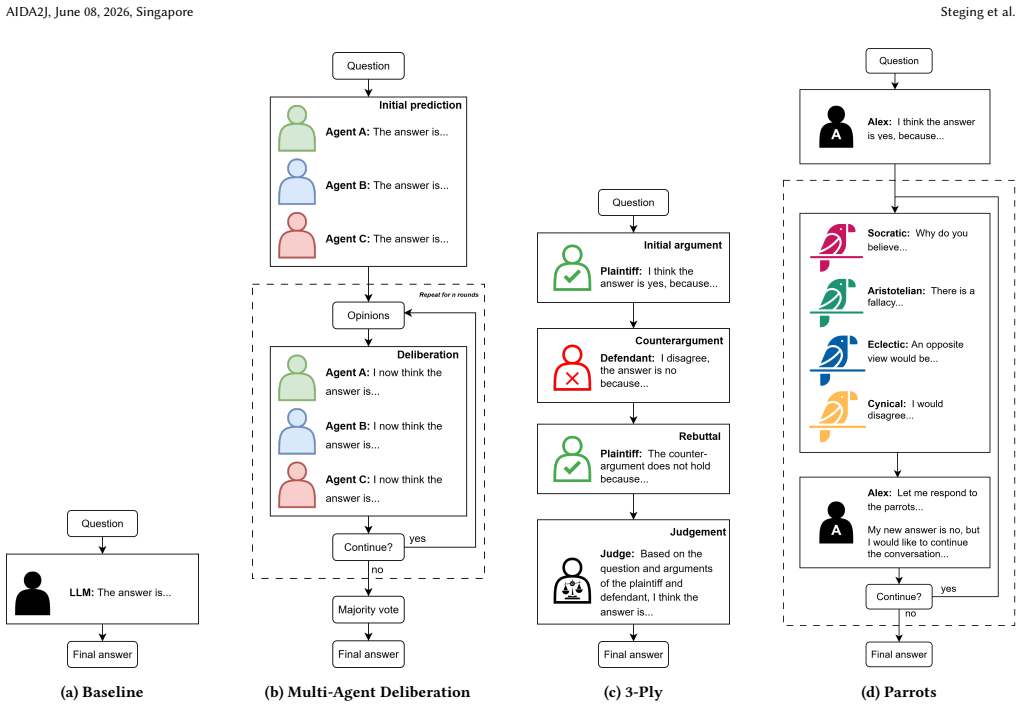




read the original abstract
Artificial Intelligence is increasingly applied to the field of law, and has the potential to increase access to justice. One particular movement that is gaining traction is that of agentic AI, wherein AI agents, based on Large Language Models (LLMs) can take autonomous actions. In particular, multi-agent approaches in the legal domain remain largely unexplored. In this paper, we investigate multi-agent deliberation methods for legal reasoning tasks using LLMs. We explore multi-agent deliberation (MAD) and introduce two novel multi-agent frameworks inspired by courtroom procedures and legal argumentation. Our experiments on both legal and non-legal benchmarks reveal that multi-agent frameworks achieve comparable overall performance to baseline large language models, but produce significantly distinct answers. Notably, these approaches can successfully solve cases that the baseline fails to address, and vice versa. We conduct a qualitative evaluation and highlight scenarios where multi-agent frameworks outperform monolithic approaches. For example, multi-agent approaches appear better suited for answering questions that require critical thinking from multiple perspectives. Our work positions multi-agent systems as a promising direction for AI in the legal domain, while demonstrating the potential of law-inspired multi-agent approaches for deliberation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript investigates multi-agent deliberation (MAD) for legal reasoning tasks with LLMs. It introduces MAD along with two novel frameworks modeled on courtroom procedures and legal argumentation. Experiments on legal and non-legal benchmarks indicate that the multi-agent approaches achieve comparable overall performance to baseline LLMs while producing significantly distinct answers, with each solving some cases the other misses. A qualitative evaluation is presented to highlight advantages in critical-thinking scenarios requiring multiple perspectives.
Significance. If the reported empirical patterns hold, the work usefully demonstrates complementarity between single-LLM and multi-agent deliberation on the tested benchmarks, which could inform ensemble strategies in legal AI. The law-inspired framework designs add a domain-motivated angle to agentic systems. The manuscript does not claim real-world deployment or generalization beyond the benchmarks, so the scope remains appropriately bounded.
major comments (1)
- [Abstract] Abstract: the central claim that multi-agent frameworks 'achieve comparable overall performance' and 'produce significantly distinct answers' is stated without any numerical accuracy values, benchmark identifiers, definitions of 'distinct,' sample sizes, or statistical comparisons. Because this empirical observation is the load-bearing result, the results section (or a new table) must supply the concrete metrics, error bars, and exact task definitions that allow readers to assess whether the comparability and complementarity claims are supported.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that multi-agent frameworks 'achieve comparable overall performance' and 'produce significantly distinct answers' is stated without any numerical accuracy values, benchmark identifiers, definitions of 'distinct,' sample sizes, or statistical comparisons. Because this empirical observation is the load-bearing result, the results section (or a new table) must supply the concrete metrics, error bars, and exact task definitions that allow readers to assess whether the comparability and complementarity claims are supported.
Authors: We agree that the abstract would be strengthened by including concrete metrics and that the results presentation should make the supporting numbers fully transparent. The manuscript reports accuracy values, benchmark names (legal and non-legal), and the definition of distinct answers (cases solved by one approach but missed by the other) in the results section, along with sample sizes. To address the concern directly, we will revise the abstract to include key numerical accuracy figures and benchmark identifiers, and we will add or expand a summary table in the results section that includes error bars (from repeated runs where applicable) and any statistical comparisons. This change will be made in the revised manuscript. revision: yes
Circularity Check
No significant circularity; purely empirical comparison
full rationale
The paper reports benchmark experiments comparing multi-agent deliberation frameworks against baseline LLMs on legal and non-legal tasks. The central claim (comparable aggregate accuracy with distinct answer sets, each solving cases the other misses) is an observed empirical outcome, not a derivation, prediction, or fitted quantity that reduces to its own inputs. No equations, uniqueness theorems, ansatzes, or self-citations are invoked as load-bearing steps in any derivation chain. The work is self-contained against external benchmarks and does not rename known results or smuggle assumptions via citation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM agents can be effectively prompted to perform distinct roles in deliberation
Reference graph
Works this paper leans on
-
[1]
Abdelrahman Abdallah, Bhawna Piryani, and Adam Jatowt. 2023. Exploring the state of the art in legal QA systems.Journal of Big Data10, 1 (Aug. 2023). doi:10.1186/s40537-023-00802-8
-
[2]
D. B. Acharya, K. Kuppan, and B. Divya. 2025. Agentic AI: Autonomous in- telligence for complex goals—A comprehensive survey.IEEe Access13 (2025), 18912–18936
2025
-
[3]
G. Amati. 2009.BM25. Springer US, Boston, MA, 257–260
2009
-
[4]
Arisaka, J
R. Arisaka, J. Dauphin, K. Satoh, and L. van der Torre. 2022. Multi-agent Argu- mentation and Dialogue.IfCoLog Journal of Logics and Their Applications9, 4 (2022), 853–886
2022
-
[5]
1988.Modelling Legal Argument: Reasoning with Cases and Hypo- theticals
Kevin Ashley. 1988.Modelling Legal Argument: Reasoning with Cases and Hypo- theticals. PhD Thesis. University of Massachusetts, Amherst
1988
-
[6]
Sourav Banerjee, Ayushi Agarwal, and Saloni Singla. 2025. LLMs Will Always Hallucinate, and We Need to Live with This. InIntelligent Systems and Applications, Kohei Arai (Ed.). Springer Nature Switzerland, Cham, 624–648
2025
-
[7]
Trevor Bench-Capon, Katie Atkinson, Floris Bex, Henry Prakken, and Bart Verheij
-
[8]
Computational Models of Legal Argument.IfCoLoG Journal of Logics and their Applications12(3) (2025), 323–425
2025
-
[9]
Trevor Bench-Capon and Giovanni Sartor. 2003. A model of legal reasoning with cases incorporating theories and values.Artificial Intelligence150, 1-2 (Nov. 2003), 97–143. doi:10.1016/S0004-3702(03)00108-5
-
[10]
Trevor Bench-Capon and Marek Sergot. 1988. Towards a Rule-Based Repre- sentation of Open Texture in Law.Computer Power and Legal Language(1988), 81–88
1988
-
[11]
Sebastian Benthall and Katherine J. Strandburg. 2021. Agent-Based Modeling as a Legal Theory Tool.Frontiers in Physics9 (2021). doi:10.3389/fphy.2021.666386
- [12]
-
[13]
Yilun Du, Shuang Li, Antonio Torralba, Joshua B Tenenbaum, and Igor Mordatch
-
[14]
Improving Factuality and Reasoning in Language Models through Multiagent Debate
Improving factuality and reasoning in language models through multiagent debate.arXiv preprint arXiv:2305.14325(2023). AIDA2J, June 08, 2026, Singapore Steging et al
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
Ellsworth
P.C. Ellsworth. 2005.Legal reasoning. Cambridge University Press, New York, 685–704
2005
-
[16]
Yu Fan, Jingwei Ni, Jakob Merane, Etienne Salimbeni, Yang Tian, Yoan Hermstrüwer, Yinya Huang, Mubashara Akhtar, Florian Geering, Oliver Dreyer, Daniel Brunner, Markus Leippold, Mrinmaya Sachan, Alexander Stremitzer, Christoph Engel, Elliott Ash, and Joel Niklaus. 2025. LEXam: Benchmark- ing Legal Reasoning on 340 Law Exams. arXiv:2505.12864 [cs.CL] https...
-
[17]
Eveline T. Feteris. 1997. A Survey of 25 Years of Research on Legal Argumentation. Argumentation11, 3 (1997), 355–376. doi:10.1023/A:1007794830151
-
[18]
Randy Goebel, Yoshinobu Kano, Mi-Young Kim, Juliano Rabelo, Ken Satoh, and Masaharu Yoshioka. 2024. Overview of benchmark datasets and methods for the legal information extraction/entailment competition (COLIEE) 2024. InJSAI International Symposium on Artificial Intelligence. Springer, 109–124
2024
-
[19]
Gordon, and Michał Araszkiewicz
Guido Governatori, Trevor Bench-Capon, Bart Verheij, Giovanni Sartor, Adam Wyner, Matthias Grabmair, Katie Atkinson, Henry Prakken, Floris Bex, Thomas F. Gordon, and Michał Araszkiewicz. 2022. Thirty years of Artificial Intelligence and Law: the first decade.Artificial Intelligence and Law30, 4 (2022), 481–519
2022
-
[20]
Ho, Christopher Ré, Adam Chilton, Aditya Narayana, Alex Chohlas-Wood, Austin Peters, Brandon Waldon, Daniel N
Neel Guha, Julian Nyarko, Daniel E. Ho, Christopher Ré, Adam Chilton, Aditya Narayana, Alex Chohlas-Wood, Austin Peters, Brandon Waldon, Daniel N. Rock- more, Diego Zambrano, Dmitry Talisman, Enam Hoque, Faiz Surani, Frank Fagan, Galit Sarfaty, Gregory M. Dickinson, Haggai Porat, Jason Hegland, Jessica Wu, Joe Nudell, Joel Niklaus, John Nay, Jonathan H. C...
2023
-
[21]
Hart and L Green
H.L.A. Hart and L Green. 2012.The concept of law(3rd edition ed.). Oxford University Press, Oxford
2012
-
[22]
Zhitao He, Pengfei Cao, Chenhao Wang, Zhuoran Jin, Yubo Chen, Jiexin Xu, Huaijun Li, Xiaojian Jiang, Kang Liu, and Jun Zhao. 2024. AgentsCourt: Building Judicial Decision-Making Agents with Court Debate Simulation and Legal Knowl- edge Augmentation. arXiv:2403.02959 [cs.CL] https://arxiv.org/abs/2403.02959
- [23]
- [24]
-
[25]
Jiang and X
C. Jiang and X. Yang. 2025. AgentsBench: A Multi-Agent LLM Simulation Frame- work for Legal Judgment Prediction.Systems13, 8 (2025), 641. doi:10.3390/ systems13080641
2025
-
[26]
Jinqi Lai, Wensheng Gan, Jiayang Wu, Zhenlian Qi, and Philip S. Yu. 2024. Large language models in law: A survey.AI Open5 (2024), 181–196. doi:10.1016/j. aiopen.2024.09.002
work page doi:10.1016/j 2024
-
[27]
Hanmeng Liu, Jian Liu, Leyang Cui, Zhiyang Teng, Nan Duan, Ming Zhou, and Yue Zhang. 2023. LogiQA 2.0—An Improved Dataset for Logical Reasoning in Natural Language Understanding.IEEE/ACM Transactions on Audio, Speech, and Language Processing31 (2023), 2947–2962. doi:10.1109/TASLP.2023.3293046
-
[28]
Jorge Martinez-Gil. 2023. A survey on legal question–answering systems.Com- puter Science Review48 (2023), 100552. doi:10.1016/j.cosrev.2023.100552
-
[29]
Nicolas Maudet, Simon Parsons, and Iyad Rahwan. 2007. Argumentation in Multi-Agent Systems: Context and Recent Developments. InArgumentation in Multi-Agent Systems: Third International Workshop, ArgMAS 2006, Hakodate, Japan, May 8, 2006. Revised Selected and Invited Papers, Nicolas Maudet, Simon Parsons, and Iyad Rahwan (Eds.). Lecture Notes in Computer S...
-
[30]
Izquierdo, and Giovanni Sartor
Eunate Mayor, Luis R. Izquierdo, and Giovanni Sartor. 2009. Nice and Nasty Lawyers, is the Legal System to Blame? Agent-based simulation insights. In Proceedings of the 2009 Conference on Legal Knowledge and Information Systems: JURIX 2009: The Twenty-Second Annual Conference. IOS Press, NLD, 126–135
2009
-
[31]
E. Musi, N. Kokciyan, K. Al-Khatib, D. Ceolin, E. Dietz, K. Gutekunst, A. Hautli- Janisz, C.M. Santibañez Yañez, J. Schneider, J. Scholz, C. Steging, J. Visser, and H. Wachsmuth. 2025. Toward Reasonable Parrots: Why Large Language Models Should Argue with Us by Design. InThe 12th Workshop on Argument Mining, co-located with ACL 2025. Vienna, Austria
2025
-
[32]
Henry Prakken and Giovanni Sartor. 2015. Law and logic: A review from an argumentation perspective.Artificial Intelligence227 (2015), 214–245. doi:10. 1016/j.artint.2015.06.005
2015
-
[33]
E. L. Rissland and K. D. Ashley. 1987. A case-based system for trade secrets law. InProceedings of the first international conference on Artificial intelligence and law - ICAIL ’87. ACM Press, Boston, Massachusetts, United States, 60–66. doi:10.1145/41735.41743
-
[34]
Antonino Rotolo and Giovanni Sartor. 2023. Argumentation and explanation in the law.Frontiers in Artificial Intelligence6 (2023), 1130559. doi:10.3389/frai.2023. 1130559
-
[35]
Gordon, Matthias Grabmair, and Henry Prakken
Giovanni Sartor, Michał Araszkiewicz, Katie Atkinson, Adam Wyner, Trevor Bench-Capon, Guido Governatori, Bart Verheij, Floris Bex, Thomas F. Gordon, Matthias Grabmair, and Henry Prakken. 2022. Thirty years of Artificial Intelli- gence and Law: the second decade.Artificial Intelligence and Law30, 4 (2022), 521–557
2022
-
[36]
Savelka and K.D
J. Savelka and K.D. Ashley. 2023. The unreasonable effectiveness of large language models in zero-shot semantic annotation of legal texts.Frontiers in Artificial Intelligence6 (2023)
2023
-
[37]
Alex Schwartz. 2019. An agent-based model of judicial power.Journal of Law9, 1 (2019), 21–53
2019
-
[38]
Alex Schwartz. 2020. Agent-Based Modeling for Legal Studies. InComputational Legal Studies: The Promise and Challenge of Data-Driven Research, Ryan Whalen (Ed.). Edward Elgar Publishing, Cheltenham, UK and Northampton, MA, USA, Chapter 14, 312–327. doi:10.4337/9781788977456.00019
-
[39]
Marco Siino, Mariana Falco, Daniele Croce, and Paolo Rosso. 2025. Exploring LLMs Applications in Law: A Literature Review on Current Legal NLP Ap- proaches.IEEE Access13 (2025), 18253–18276. doi:10.1109/ACCESS.2025.3533217
-
[40]
Steenhuis, B
Q. Steenhuis, B. Willey, and D. Colarusso. 2023. Beyond Readability with Rate- MyPDF: A Combined Rule-based and Machine Learning Approach to Improving Court Forms. InProceedings of the Nineteenth International Conference on Artificial Intelligence and Law. 287–296
2023
-
[41]
Cor Steging, Silja Renooij, and Bart Verheij. 2026. Parameterized Argumentation- based Reasoning Tasks for Benchmarking Generative Language Models. InPro- ceedings of the Twentieth International Conference on Artificial Intelligence and Law (ICAIL ’25). Association for Computing Machinery, New York, NY, USA, 455–459. doi:10.1145/3769126.3769230
-
[42]
Bart Verheij. 2016. Formalizing value-guided argumentation for ethical systems design.Artificial Intelligence and Law24, 4 (Dec. 2016), 387–407. doi:10.1007/ s10506-016-9189-y
2016
-
[43]
Gordon, Matthias Grabmair, Henry Prakken, Giovanni Sartor, Bart Verheij, and Adam Wyner
Serena Villata, Michał Araszkiewicz, Kevin Ashley, Katie Atkinson, Trevor Bench- Capon, Floris Bex, Guido Governatori, Thomas F. Gordon, Matthias Grabmair, Henry Prakken, Giovanni Sartor, Bart Verheij, and Adam Wyner. 2022. Thirty years of Artificial Intelligence and Law: the third decade.Artificial Intelligence and Law30, 4 (2022), 561–591
2022
- [44]
-
[45]
yes" and the defendant always argues
Sebastian Zimmeck, Peter Story, Daniel Smullen, Abhilasha Ravichander, Ziqi Wang, Joel R Reidenberg, N Cameron Russell, and Norman Sadeh. 2019. Maps: Scaling privacy compliance analysis to a million apps.Proc. Priv. Enhancing Tech. 2019 (2019), 66. Investigating Multi-Agent Deliberation in Law AIDA2J, June 08, 2026, Singapore Appendix A Prompts This secti...
2019
-
[46]
Identify which points are logically sound and relevant to the question
-
[47]
Identify which points are weak, irrelevant, or flawed
-
[48]
Determine whether the arguments reinforce or contradict each other
-
[49]
Treat the arguments as supplemental reasoning, not as new facts
Use this analysis to refine your final decision. Treat the arguments as supplemental reasoning, not as new facts. Base your verdict primarily on the question. Explicitly reason step by step and conclude strictly with: Answer: yes or Answer: no (g) Prompt for the final decision by the judge. Figure 7: Prompts used in the 3-Ply system. Investigating Multi-A...
2026
-
[50]
Give a summary of your reasoning
-
[51]
Restate your current stance clearly in the form: Answer: Yes or Answer: No
-
[52]
Continue: no
On a new line, decide if you want to continue the conversation: Continue: yes (default — if there are still open questions or doubts OR if not all parrots have spoken yet.) Continue: no (if you are confident in your stance OR the parrots are only repeating points you have already addressed). If you choose "Continue: no", briefly explain why further discus...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.