Quality-Aware Modulation for Diffusion Transformers
Pith reviewed 2026-07-01 06:13 UTC · model grok-4.3
The pith
A lightweight module derives quality signals from timestep and prompt embeddings to adjust adaptive LayerNorm in diffusion transformers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
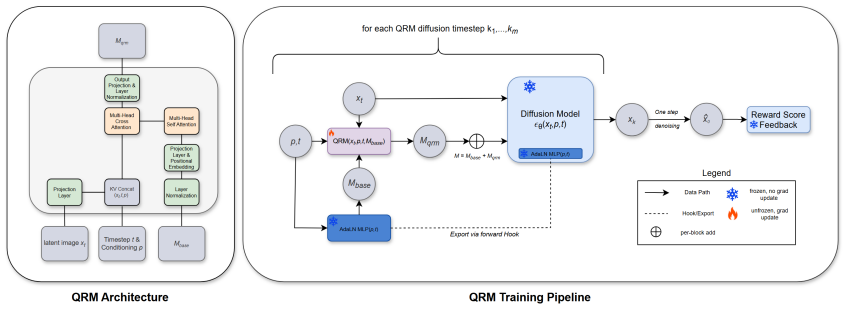
The Quality Representation Module (QRM) learns a quality-aware representation from existing timestep and prompt embeddings, produces a set of vectors M_qrm, and uses those vectors to adjust the adaptive LayerNorm modulation inside DiT transformer blocks, thereby injecting a quality-sensitive signal into the denoising parameters and yielding consistent image quality improvements over baseline DiT models without altering the sampling schedule or backbone.
What carries the argument
The Quality Representation Module (QRM) that outputs vectors M_qrm to rescale adaptive LayerNorm parameters inside DiT blocks.
If this is right
- Generated images show consistent quality gains over baseline DiT models on fidelity and consistency measures.
- The diffusion backbone and sampling schedule remain unchanged.
- Ablation studies confirm that both the chosen training losses and the module architecture affect the quality of the learned representation.
- The quality signal is added directly into the existing modulation pathway inside each transformer block.
Where Pith is reading between the lines
- The same quality-vector approach could be tested on other conditioning signals such as classifier-free guidance strength.
- If the module generalizes across different DiT variants, it might serve as a drop-in quality booster for existing trained models.
- Training the QRM on larger or more diverse prompt sets could reveal whether the learned quality signal captures style or content preferences.
Load-bearing premise
That a useful quality-aware representation can be learned from timestep and prompt embeddings alone without external quality labels or supervision.
What would settle it
An experiment that adds the QRM to a DiT model and finds no improvement in standard image quality metrics or human preference scores, or that finds new visual artifacts introduced by the modulation.
Figures



read the original abstract
Modern text-to-image diffusion models, such as diffusion transformers (DiT), rely on timestep or prompt embeddings to modulate the strength of the denoising process in each timestep. While this modulation communicates the current noise level, it does not provide any quality-aware information, which can lead to generated images that are unaligned, visually inconsistent, and lacking in fidelity. In this paper, we propose the Quality Representation Module (QRM), a lightweight transformer module that learns a quality-aware representation based on existing model inputs, and produces a set of vectors $M_{qrm}$. These vectors adjust the adaptive LayerNorm modulation within the DiT transformer blocks, thereby injecting a quality-sensitive signal into the denoising parameters. The QRM introduces no significant changes to the sampling schedule or diffusion backbone. Experiments include ablations on QRM training losses and architectures, as well as empirical results demonstrating consistent image quality improvements over baseline DiT-based models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the Quality Representation Module (QRM), a lightweight transformer module for DiT-based text-to-image diffusion models. QRM learns a quality-aware representation solely from existing inputs (timestep and prompt embeddings) and outputs vectors M_qrm that modulate the adaptive LayerNorm parameters inside DiT blocks. The goal is to inject a quality-sensitive signal that improves image alignment, consistency, and fidelity. The approach requires no changes to the sampling schedule or diffusion backbone. The paper includes ablations on QRM training losses and architectures plus empirical results claiming consistent improvements over baseline DiT models.
Significance. A validated lightweight module that reliably improves generation quality via modulation of existing DiT components would be a practical contribution to diffusion transformer design. The absence of any quantitative metrics, dataset details, baseline comparisons, or grounding mechanism for the quality signal, however, prevents assessment of whether the claimed improvements are real, reproducible, or attributable to quality awareness rather than added capacity.
major comments (2)
- [Abstract] Abstract: the central empirical claim of 'consistent image quality improvements over baseline DiT-based models' together with 'ablations on QRM training losses and architectures' is asserted without any quantitative metrics, dataset names, baseline models, or error analysis. This renders the primary result unverifiable from the provided text.
- [Abstract] Abstract: the assertion that QRM learns a 'quality-aware representation' and injects a 'quality-sensitive signal' rests on processing only timestep and prompt embeddings, yet no quality proxy, perceptual loss, discriminator, preference model, or output-quality metric is described that would ground the learned M_qrm vectors in actual image quality rather than generic modulation capacity. Any observed gains could therefore arise from extra parameters or altered dynamics, directly weakening the quality-sensitivity interpretation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comments point by point below. Where revisions are needed to improve verifiability, we will update the abstract accordingly while preserving the core claims supported by the experiments.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim of 'consistent image quality improvements over baseline DiT-based models' together with 'ablations on QRM training losses and architectures' is asserted without any quantitative metrics, dataset names, baseline models, or error analysis. This renders the primary result unverifiable from the provided text.
Authors: We agree that the abstract, being a concise summary, does not embed the specific quantitative details. The full manuscript contains these elements in the experiments section, including dataset information, baseline DiT models, key metrics demonstrating improvements, and ablation results on losses and architectures. To make the primary claims verifiable directly from the abstract, we will revise it to include representative quantitative results, dataset names, and baseline references. revision: yes
-
Referee: [Abstract] Abstract: the assertion that QRM learns a 'quality-aware representation' and injects a 'quality-sensitive signal' rests on processing only timestep and prompt embeddings, yet no quality proxy, perceptual loss, discriminator, preference model, or output-quality metric is described that would ground the learned M_qrm vectors in actual image quality rather than generic modulation capacity. Any observed gains could therefore arise from extra parameters or altered dynamics, directly weakening the quality-sensitivity interpretation.
Authors: The quality-sensitive signal is grounded via the QRM training losses, which are explicitly ablated in the manuscript and designed to promote improvements in alignment, consistency, and fidelity as measured by standard output-quality metrics. While no external discriminator or preference model is employed, the end-to-end optimization ties the learned modulations to quality outcomes, and architecture ablations control for added capacity. We will revise the abstract to briefly reference the role of these training losses in establishing the quality-aware property. revision: yes
Circularity Check
No circularity: architectural proposal with empirical ablations, no self-referential derivation
full rationale
The paper introduces QRM as an additive lightweight transformer module that processes existing timestep/prompt embeddings to produce modulation vectors for adaLN. No equations, uniqueness theorems, or self-citations are presented that reduce the claimed quality improvement to a quantity defined by the method itself. Ablations on training losses and architectures are described as empirical checks rather than a closed derivation loop. The central claim rests on observed image quality gains over baseline DiT, which is an external empirical outcome rather than a self-definition or fitted-input prediction. This is the common case of a self-contained architectural change without load-bearing circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Forty-first international conference on machine learning (2024)
Esser, P., Kulal, S., Blattmann, A., Entezari, R., Müller, J., Saini, H., Levi, Y., Lorenz, D., Sauer, A., Boesel, F., et al.: Scaling rectified flow transformers for high-resolution image synthesis. In: Forty-first international conference on machine learning (2024)
2024
-
[2]
In: Proceedings of the 2021 conference on empirical methods in natural language processing
Hessel, J., Holtzman, A., Forbes, M., Le Bras, R., Choi, Y.: Clipscore: A reference-free evaluation metric for image captioning. In: Proceedings of the 2021 conference on empirical methods in natural language processing. pp. 7514–7528 (2021)
2021
-
[3]
Advances in neural information processing systems33, 6840–6851 (2020)
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. Advances in neural information processing systems33, 6840–6851 (2020)
2020
-
[4]
Auto-Encoding Variational Bayes
Kingma, D.P., Welling, M.: Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114 (2013)
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[5]
Labs, B.F.: Flux.https://github.com/black-forest-labs/flux(2024)
2024
-
[6]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Li, X., Liu, Y., Isobe, T., Jia, X., Cui, Q., Zhou, D., Li, D., He, Y., Lu, H., Wang, Z., Barsoum, E.: Reneg: Learning negative embedding with reward guidance. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 23636–23645 (June 2025)
2025
-
[7]
Machine Intelligence Research22(4), 730–751 (Jun 2025)
Lu, C., Zhou, Y., Bao, F., Chen, J., Li, C., Zhu, J.: Dpm-solver++: Fast solver for guided sampling of diffusion probabilistic models. Machine Intelligence Research22(4), 730–751 (Jun 2025). https://doi.org/10.1007/s11633-025-1562-4,http://dx.doi.org/10. 1007/s11633-025-1562-4
-
[8]
arXiv preprint arXiv:2503.13070 (2025)
Luo, Y., Hu, T., Luo, W., Kawaguchi, K., Tang, J.: Reward-instruct: A reward-centric ap- proach to fast photo-realistic image generation. arXiv preprint arXiv:2503.13070 (2025)
-
[9]
Midjourney, Inc.: Midjourney.https://www.midjourney.com(2022), text-to-image genera- tive model
2022
-
[10]
OpenAI: Dall·e 3.https://openai.com/dall-e-3(2023), text-to-image generative model
2023
-
[11]
In: Proceedings of the IEEE/CVF international conference on computer vision
Peebles, W., Xie, S.: Scalable diffusion models with transformers. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 4195–4205 (2023)
2023
-
[12]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Podell, D., English, Z., Lacey, K., Blattmann, A., Dockhorn, T., Müller, J., Penna, J., Rom- bach, R.: Sdxl: Improving latent diffusion models for high-resolution image synthesis. arXiv preprint arXiv:2307.01952 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021)
2021
-
[14]
Journal of machine learning research21(140), 1–67 (2020) 13
Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y., Li, W., Liu, P.J.: Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of machine learning research21(140), 1–67 (2020) 13
2020
-
[15]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image syn- thesis with latent diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10684–10695 (2022)
2022
-
[16]
Schuhmann, C., Beaumont, R., Vencu, R., Gordon, C., Wightman, R., Cherti, M., Coombes, T., Katta, A., Mullis, C., Wortsman, M., et al.: Laion-5b: An open large-scale dataset for training nextgenerationimage-text models.Advancesin neuralinformation processingsystems 35, 25278–25294 (2022)
2022
-
[17]
Stability AI: Stable diffusion.https://stability.ai/stable-diffusion(2022), accessed: 2025-08-08
2022
-
[18]
Stability AI: Stable diffusion v2.https://stability.ai/news/ stable-diffusion-v2-release(2022), accessed: 2025-08-08
2022
-
[19]
Stability AI: Stable diffusion 3.5 implementation (mmdit-x architecture).https:// huggingface.co/stabilityai/stable-diffusion-3.5-large(2024), accessed: 2025-08-08
2024
-
[20]
Advances in neural information processing systems 30(2017)
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, Ł., Polosukhin, I.: Attention is all you need. Advances in neural information processing systems 30(2017)
2017
-
[21]
Wu, X., Hao, Y., Sun, K., Chen, Y., Zhu, F., Zhao, R., Li, H.: Human preference score v2: A solid benchmark for evaluating human preferences of text-to-image synthesis. arXiv preprint arXiv:2306.09341 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Wu, X., Sun, K., Zhu, F., Zhao, R., Li, H.: Human preference score: Better aligning text- to-image models with human preference. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 2096–2105 (2023)
2096
-
[23]
Advances in Neural Information Processing Systems36, 15903–15935 (2023)
Xu, J., Liu, X., Wu, Y., Tong, Y., Li, Q., Ding, M., Tang, J., Dong, Y.: Imagereward: Learning and evaluating human preferences for text-to-image generation. Advances in Neural Information Processing Systems36, 15903–15935 (2023)
2023
-
[24]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Ye, Z., Chen, Z., Li, T., Huang, Z., Luo, W., Qi, G.J.: Schedule on the fly: Diffusion time prediction for faster and better image generation. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 23412–23422 (2025)
2025
-
[25]
Scaling Autoregressive Models for Content-Rich Text-to-Image Generation
Yu, J., Xu, Y., Koh, J.Y., Luong, T., Baid, G., Wang, Z., Vasudevan, V., Ku, A., Yang, Y., Ayan, B.K., et al.: Scaling autoregressive models for content-rich text-to-image generation. arXiv preprint arXiv:2206.107892(3), 5 (2022) 14 Figure 4: Images generated using Baseline SD3.5 (No QRM) corresponding to Figure 1 in the primary text. A Supplemental Infor...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[26]
a photo of a red orange and a purple broccoli
“a photo of a red orange and a purple broccoli”
-
[27]
“ultra detailed, beautiful cute girl wearing modern stylish costume in the style of Assamese bihu mekhela sador gamosa design, dia de los muertos, scifi, cyberpunk, fantasy, intricate details, eerie, movie still, airbrush, elegant, super highly detailed, professional digital painting, artstation, concept art, smooth, sharp focus, no blur, no dof, extreme ...
-
[28]
a hamster dragon
“a hamster dragon” Second row (left to right):
-
[29]
close-up portrait of a smiling businesswoman holding a cell phone, oil painting in the style of Rembrandt
“close-up portrait of a smiling businesswoman holding a cell phone, oil painting in the style of Rembrandt” 15
-
[30]
A tornado made of bees crashing into a skyscraper. painting in the style of Hokusai
“A tornado made of bees crashing into a skyscraper. painting in the style of Hokusai.” A.2 Computational Efficiency Although QRM introduces an additional transformer module into the denoising pipeline, the result- ing computational overhead remains moderate in practice. QRM operates only during a subset of denoising steps and processes a compact represent...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.