Ultra-Fast Neural Video Compression
Pith reviewed 2026-06-28 06:48 UTC · model grok-4.3
The pith
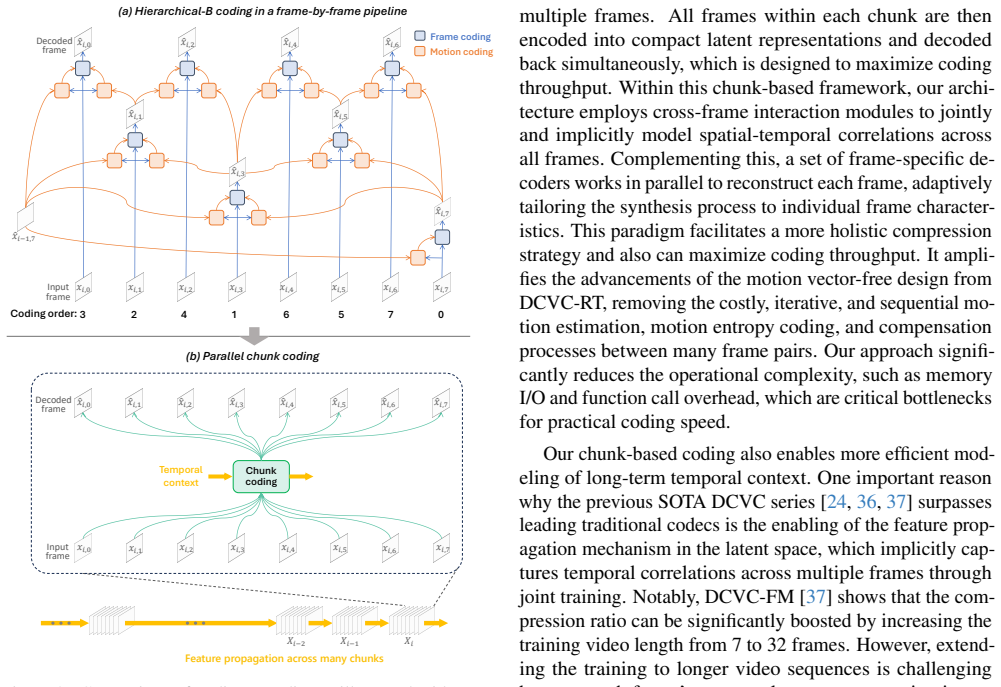
A chunk-based neural video codec encodes multiple frames into one latent representation to raise both speed and compression quality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
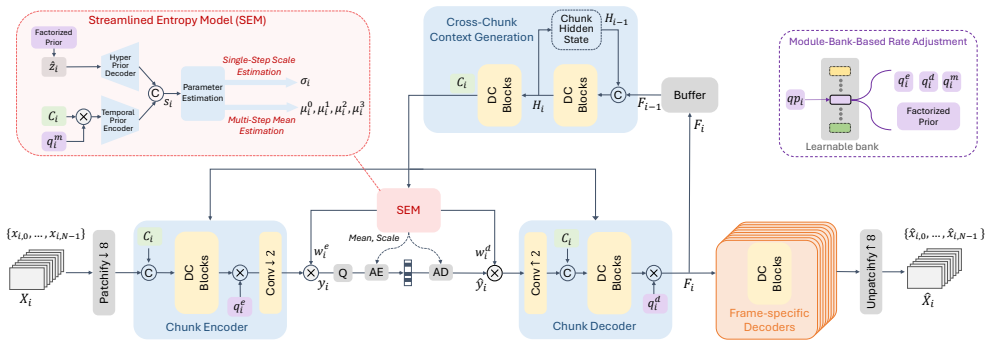
By encoding a chunk of multiple frames into a single compact latent representation and decoding them simultaneously with cross-frame interaction modules and frame-specific decoders, plus a streamlined single-step entropy mechanism, DCVC-UF achieves both ultra-fast encoding and decoding speeds and improved rate-distortion performance, setting a new state-of-the-art among neural video codecs.
What carries the argument
Chunk-based coding framework that collapses multiple frames into one latent with cross-frame interaction modules and single-step entropy coding.
If this is right
- Dramatically increases coding throughput by processing frames in parallel within each chunk.
- Enables more effective capture of long-term temporal correlations across the chunk.
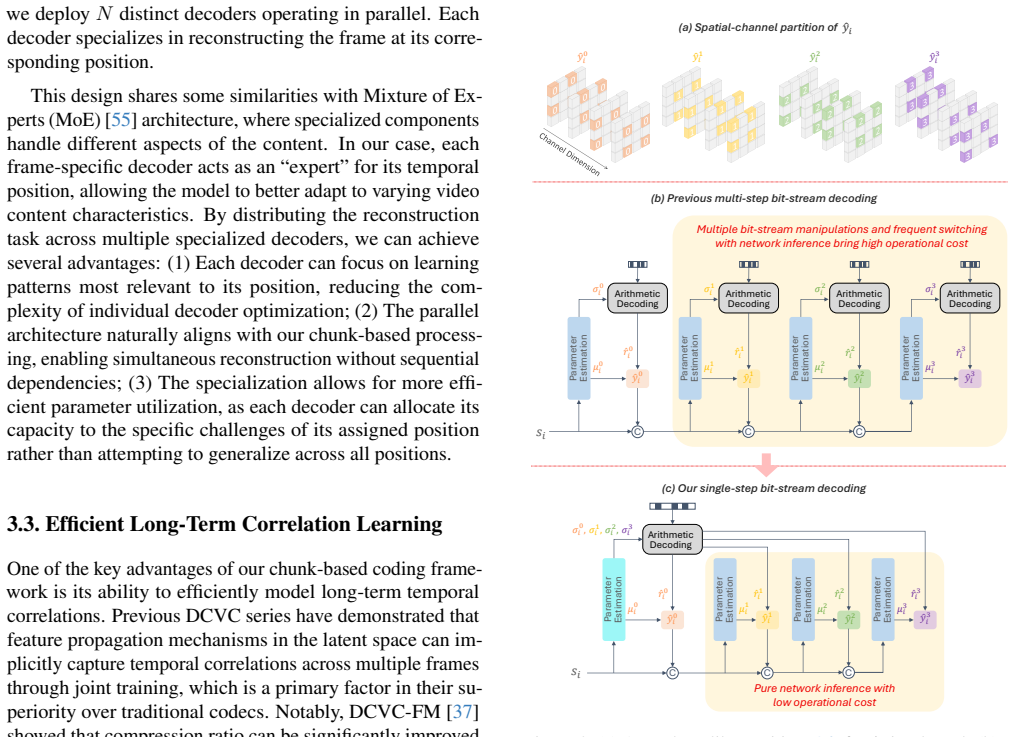
- Reduces decoding overhead by collapsing bit-stream interactions into one step.
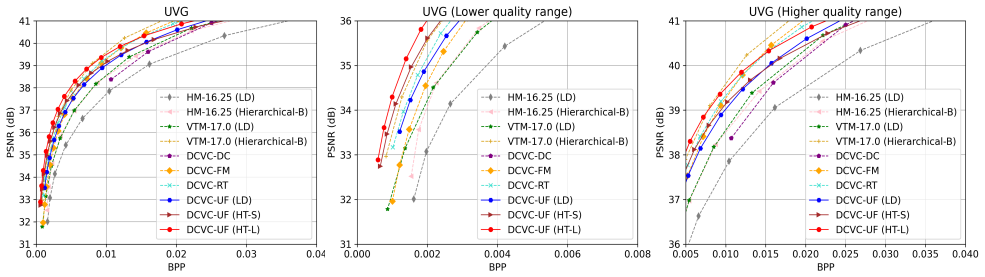
- Outperforms prior leading neural codecs in both speed and rate-distortion trade-off.
- Provides a concrete path toward real-world deployment of neural video codecs.
Where Pith is reading between the lines
- The same chunking idea could be tested on other sequential media such as audio or volumetric video to check whether joint modeling yields similar speed gains.
- If the single-step entropy mechanism generalizes, it might simplify hardware implementations that currently struggle with multi-step arithmetic coding.
- Future work could measure power consumption on mobile devices to see whether the throughput improvement translates to lower energy use per frame.
Load-bearing premise
The chunk-based joint modeling and single-step entropy deliver higher throughput and better rate-distortion results without hidden quality loss or unaccounted complexity costs.
What would settle it
Measure encoding and decoding frames per second together with BD-rate on the UVG or HEVC Class B datasets using the released code and compare directly against the previous leading neural codecs under identical hardware.
Figures
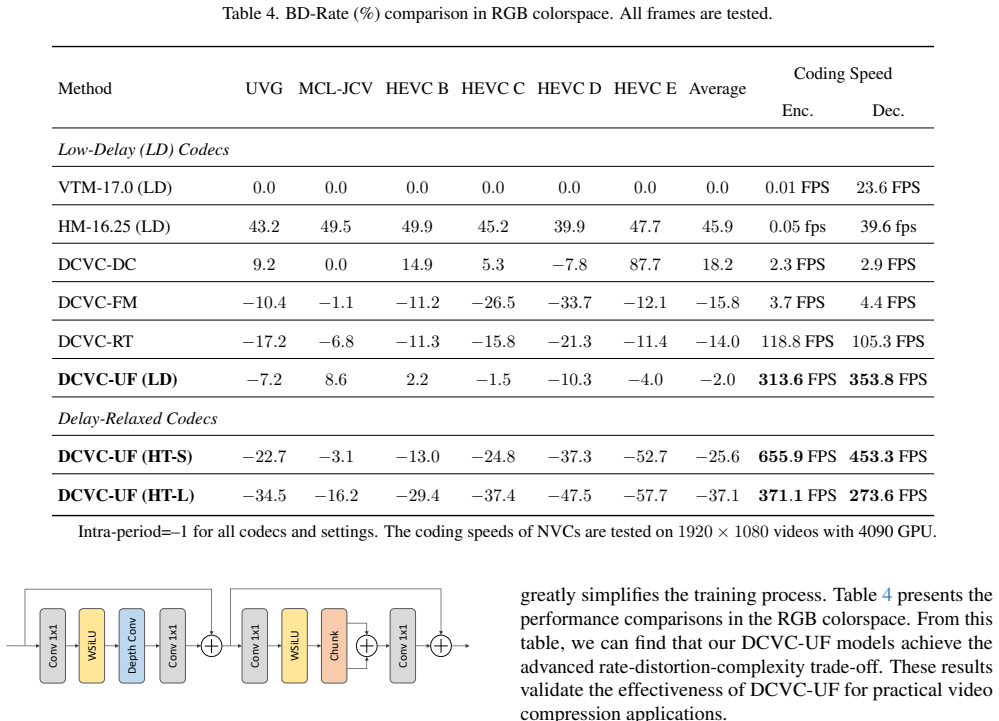
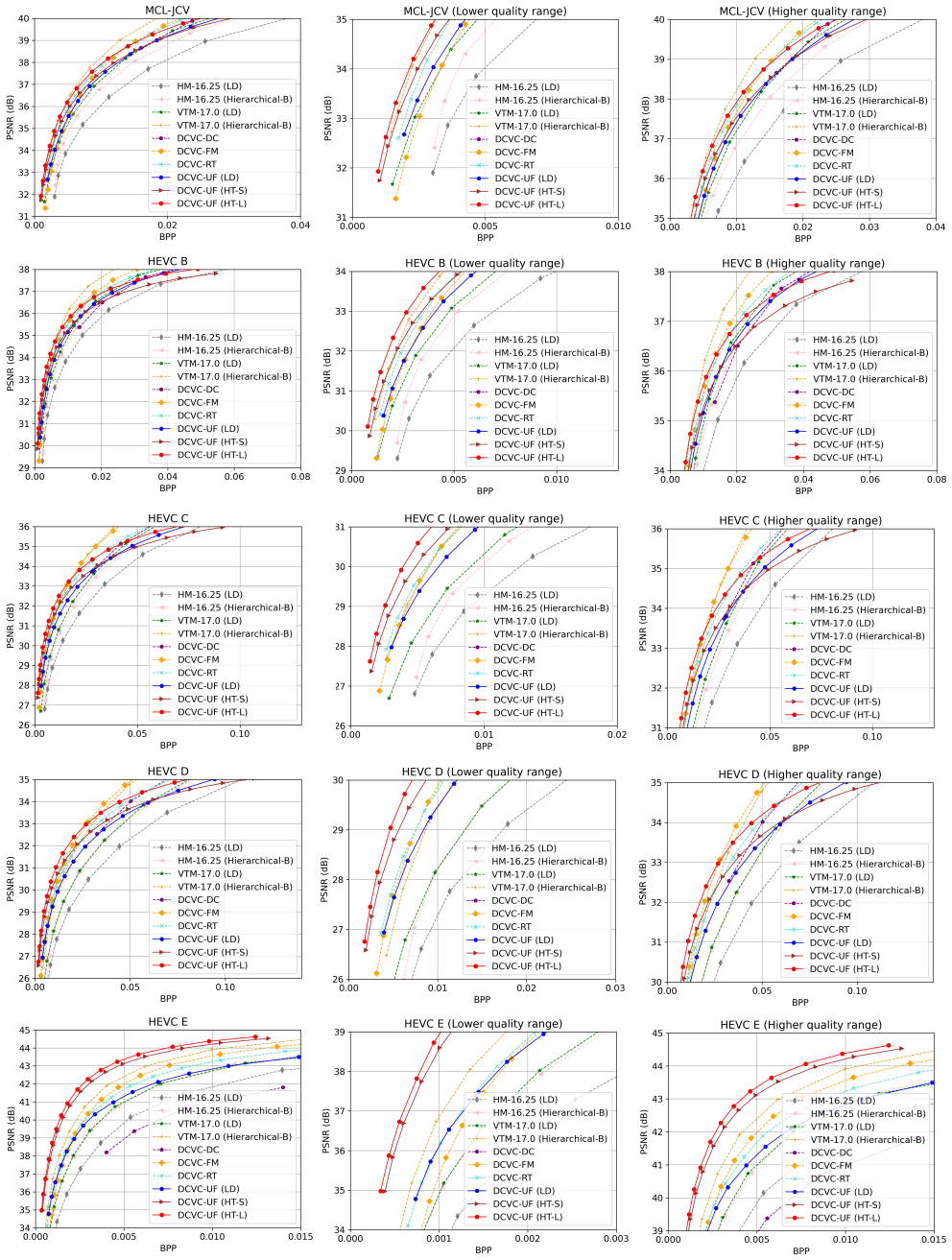
read the original abstract
While neural video codecs (NVCs) have demonstrated superior compression ratio, their prohibitive computational complexity remains a critical barrier to real-world deployment. This paper introduces a chunk-based coding framework designed to significantly improve the rate-distortion-complexity trade-off. Instead of processing frames sequentially, our approach encodes a chunk of multiple frames into a single compact latent representation and decodes them simultaneously. This is enabled by cross-frame interaction modules for joint spatial-temporal modeling and frame-specific decoders for parallel reconstruction. This paradigm not only dramatically enhances coding throughput but also facilitates more effective modeling of long-term temporal correlations. To further boost speed, we propose a streamlined entropy coding mechanism that consolidates bit-stream interactions into a single step, substantially reducing decoding overhead. Building on these innovations, we present DCVC-UF (Ultra-Fast), a new NVC that sets a new SOTA in performance. Our experiments show that DCVC-UF can achieve ultra-fast encoding and decoding speeds, significantly outperforming previous leading codecs. DCVC-UF serves as a notable landmark in the journey of NVC evolution. The code is at https://github.com/microsoft/DCVC.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DCVC-UF, a chunk-based neural video codec that encodes multiple frames jointly into a single compact latent representation via cross-frame interaction modules and frame-specific parallel decoders, combined with a consolidated single-step entropy coding mechanism. It claims this yields both higher coding throughput and improved rate-distortion performance over prior frame-by-frame NVCs, establishing a new SOTA while providing open code.
Significance. If the reported gains in speed and RD performance hold under standard evaluation protocols without hidden costs in memory or long-sequence quality, the work would meaningfully advance practical deployment of neural video codecs by improving the rate-distortion-complexity frontier. The explicit release of code at https://github.com/microsoft/DCVC strengthens reproducibility and enables direct verification.
major comments (2)
- [Experiments] Experiments section: the central claim that chunk-based joint spatial-temporal modeling plus single-step entropy improves both RD performance and throughput without hidden degradation requires explicit reporting of peak memory usage for multi-frame latents and results on sequences longer than the evaluated chunks; the current throughput and RD numbers alone do not rule out unaccounted overheads under the paper's conditions.
- [Experiments] The assertion of 'significantly outperforming previous leading codecs' in both speed and quality rests on the assumption that frame-specific decoders and consolidated entropy introduce no parallelization or quality trade-offs; this needs direct ablation against the closest prior DCVC variants with matched chunk sizes to confirm the gains are not artifacts of evaluation setup.
minor comments (2)
- [Abstract] Abstract and introduction: the term 'ultra-fast' is used without a concrete definition (e.g., FPS threshold or comparison baseline); a quantitative definition would improve clarity.
- The manuscript would benefit from a table summarizing complexity metrics (encoding/decoding time, memory) alongside BD-rate for all compared methods to make the SOTA claim easier to assess at a glance.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comments point-by-point below and will incorporate the suggested clarifications and additional results in the revised version.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the central claim that chunk-based joint spatial-temporal modeling plus single-step entropy improves both RD performance and throughput without hidden degradation requires explicit reporting of peak memory usage for multi-frame latents and results on sequences longer than the evaluated chunks; the current throughput and RD numbers alone do not rule out unaccounted overheads under the paper's conditions.
Authors: We agree that explicit peak memory reporting and evaluation on longer sequences would strengthen the claims. In the revision we will add peak GPU memory measurements for the multi-frame latent representations across different chunk sizes. For sequence length, we will include additional experiments on full-length sequences (e.g., 100+ frames) by processing them as successive chunks, reporting both RD performance and any quality drift to confirm the absence of hidden degradation. revision: yes
-
Referee: [Experiments] The assertion of 'significantly outperforming previous leading codecs' in both speed and quality rests on the assumption that frame-specific decoders and consolidated entropy introduce no parallelization or quality trade-offs; this needs direct ablation against the closest prior DCVC variants with matched chunk sizes to confirm the gains are not artifacts of evaluation setup.
Authors: We acknowledge the value of matched-chunk-size ablations. In the revised manuscript we will add direct comparisons against the closest prior DCVC variants (e.g., DCVC and DCVC-FM) using identical chunk sizes and the same evaluation protocol. These ablations will isolate the contributions of the cross-frame interaction modules, frame-specific decoders, and single-step entropy coding, thereby confirming that the reported gains are not due to differences in chunk configuration. revision: yes
Circularity Check
No circularity: empirical architecture claims rest on external experiments, not self-referential definitions or fitted predictions.
full rationale
The paper proposes a chunk-based NVC framework with cross-frame modules and single-step entropy coding, then reports experimental RD and throughput gains. No equations, fitted parameters renamed as predictions, or self-citation chains that reduce the central claims to inputs by construction appear in the abstract or described structure. Claims are validated against prior codecs on standard benchmarks, making the derivation self-contained against external measurements.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
https : / / vcgit
HM. https : / / vcgit . hhi . fraunhofer . de / jvet/HM. 7, 12
-
[2]
https : / / vcgit
VTM. https : / / vcgit . hhi . fraunhofer . de / jvet/VVCSoftware_VTM. 1, 7, 12
-
[3]
https : / / github
Original Vimeo links. https : / / github . com / anchen1011 / toflow / blob / master / data / original_vimeo_links.txt. 6
-
[4]
Scale-space flow for end-to-end optimized video compression
Eirikur Agustsson, David Minnen, Nick Johnston, Johannes Balle, Sung Jin Hwang, and George Toderici. Scale-space flow for end-to-end optimized video compression. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8503–8512, 2020. 3
2020
-
[5]
Alshina, J
E. Alshina, J. Ascenso, T. Ebrahimi, F. Pereira, and T. Richter. [AHG 11] Brief information about JPEG AI CfP status. In JVET-AA0047, 2022. 12
2022
-
[6]
Anchors · JPEG-AI MMSP Challenge
Anchors · JPEG-AI MMSP Challenge. Anchors · JPEG-AI MMSP Challenge. https://jpegai.github.io/7- anchors/. 12
-
[7]
Calculation of average PSNR differences between RD-curves.VCEG-M33, 2001
Gisle Bjontegaard. Calculation of average PSNR differences between RD-curves.VCEG-M33, 2001. 7
2001
-
[8]
Nerv: Neural representations for videos.Advances in Neural Information Processing Systems, 34:21557–21568, 2021
Hao Chen, Bo He, Hanyu Wang, Yixuan Ren, Ser Nam Lim, and Abhinav Shrivastava. Nerv: Neural representations for videos.Advances in Neural Information Processing Systems, 34:21557–21568, 2021. 1, 3
2021
-
[9]
Hnerv: A hybrid neural representation for videos
Hao Chen, Matthew Gwilliam, Ser-Nam Lim, and Abhinav Shrivastava. Hnerv: A hybrid neural representation for videos. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10270–10279, 2023. 3
2023
-
[10]
Junyu Chen, Wenkun He, Yuchao Gu, Yuyang Zhao, Jincheng Yu, Junsong Chen, Dongyun Zou, Yujun Lin, Zhekai Zhang, Muyang Li, et al. Dc-videogen: Efficient video generation with deep compression video autoencoder.arXiv preprint arXiv:2509.25182, 2025. 3
-
[11]
Liuhan Chen, Zongjian Li, Bin Lin, Bin Zhu, Qian Wang, Shenghai Yuan, Xing Zhou, Xinhua Cheng, and Li Yuan. Od- vae: An omni-dimensional video compressor for improving la- tent video diffusion model.arXiv preprint arXiv:2409.01199,
-
[12]
B-canf: Adaptive b-frame coding with conditional augmented normal- izing flows.IEEE Transactions on Circuits and Systems for Video Technology, 34(4):2908–2921, 2023
Mu-Jung Chen, Yi-Hsin Chen, and Wen-Hsiao Peng. B-canf: Adaptive b-frame coding with conditional augmented normal- izing flows.IEEE Transactions on Circuits and Systems for Video Technology, 34(4):2908–2921, 2023. 1, 3
2023
-
[13]
Neural Video Compression with Spatio-Temporal Cross-Covariance Transformers
Zhenghao Chen, Lucas Relic, Roberto Azevedo, Yang Zhang, Markus Gross, Dong Xu, Luping Zhou, and Christopher Schroers. Neural Video Compression with Spatio-Temporal Cross-Covariance Transformers. InProceedings of the 31st ACM International Conference on Multimedia, pages 8543– 8551, 2023. 1
2023
-
[14]
Zhenghao Chen, Zicong Chen, Lei Liu, Yiming Wu, and Dong Xu. Versatile video tokenization with generative 2d gaussian splatting.arXiv preprint arXiv:2508.11183, 2025. 1, 3
-
[15]
Neural inter-frame com- pression for video coding
Abdelaziz Djelouah, Joaquim Campos, Simone Schaub- Meyer, and Christopher Schroers. Neural inter-frame com- pression for video coding. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2019. 3
2019
-
[16]
Common Test Con- ditions and Software Reference Configurations for HEVC Range Extensions, document JCTVC-N1006.Joint Collabo- rative Team Video Coding ITU-T SG, 16
D Flynn, K Sharman, and C Rosewarne. Common Test Con- ditions and Software Reference Configurations for HEVC Range Extensions, document JCTVC-N1006.Joint Collabo- rative Team Video Coding ITU-T SG, 16. 7
-
[17]
Pnvc: Towards practical inr-based video compression
Ge Gao, Ho Man Kwan, Fan Zhang, and David Bull. Pnvc: Towards practical inr-based video compression. InProceed- ings of the AAAI Conference on Artificial Intelligence, pages 3068–3076, 2025. 3
2025
-
[18]
Givic: Generative implicit video compression.arXiv preprint arXiv:2503.19604, 2025
Ge Gao, Siyue Teng, Tianhao Peng, Fan Zhang, and David Bull. Givic: Generative implicit video compression.arXiv preprint arXiv:2503.19604, 2025. 1
-
[19]
Implicit mo- tion function
Yue Gao, Jiahao Li, Lei Chu, and Yan Lu. Implicit mo- tion function. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19278– 19289, 2024. 2
2024
-
[20]
Neural video com- pression using 2d gaussian splatting.arXiv preprint arXiv:2505.09324, 2025
Lakshya Gupta and Imran N Junejo. Neural video com- pression using 2d gaussian splatting.arXiv preprint arXiv:2505.09324, 2025. 1, 3
-
[21]
Video compression with rate- distortion autoencoders
Amirhossein Habibian, Ties van Rozendaal, Jakub M Tom- czak, and Taco S Cohen. Video compression with rate- distortion autoencoders. InProceedings of the IEEE/CVF international conference on computer vision, pages 7033– 7042, 2019. 2, 3, 4
2019
-
[22]
Canf-vc: Conditional aug- mented normalizing flows for video compression.European Conference on Computer Vision, 2022
Yung-Han Ho, Chih-Peng Chang, Peng-Yu Chen, Alessandro Gnutti, and Wen-Hsiao Peng. Canf-vc: Conditional aug- mented normalizing flows for video compression.European Conference on Computer Vision, 2022. 3
2022
-
[23]
Improving deep video compres- sion by resolution-adaptive flow coding
Zhihao Hu, Zhenghao Chen, Dong Xu, Guo Lu, Wanli Ouyang, and Shuhang Gu. Improving deep video compres- sion by resolution-adaptive flow coding. InComputer Vision– ECCV 2020: 16th European Conference, Glasgow, UK, Au- gust 23–28, 2020, Proceedings, Part II 16, pages 193–209. Springer, 2020. 3
2020
-
[24]
Towards practical real-time neural video compression
Zhaoyang Jia, Bin Li, Jiahao Li, Wenxuan Xie, Linfeng Qi, Houqiang Li, and Yan Lu. Towards practical real-time neural video compression. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2025, Nashville, TN, USA, June 11-25, 2024, 2025. 1, 2, 4, 7, 12, 13
2025
-
[25]
Wei Jiang, Junru Li, Kai Zhang, and Li Zhang. Biecvc: Gated diversification of bidirectional contexts for learned video compression.arXiv preprint arXiv:2505.09193, 2025. 1, 3
-
[26]
3d gaussian splatting for real-time radiance field rendering.ACM Trans
Bernhard Kerbl, Georgios Kopanas, Thomas Leimk¨uhler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering.ACM Trans. Graph., 42(4):139–1, 2023. 1, 3
2023
-
[27]
C3: High-performance and low-complexity neural compression from a single image or video
Hyunjik Kim, Matthias Bauer, Lucas Theis, Jonathan Richard Schwarz, and Emilien Dupont. C3: High-performance and low-complexity neural compression from a single image or video. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, pages 9347–9358, 2024. 1, 3
2024
-
[28]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
Hinerv: Video compression with hierarchical encoding-based neural representation.Advances in Neural Information Processing Systems, 36:72692–72704, 2023
Ho Man Kwan, Ge Gao, Fan Zhang, Andrew Gower, and David Bull. Hinerv: Video compression with hierarchical encoding-based neural representation.Advances in Neural Information Processing Systems, 36:72692–72704, 2023. 3
2023
-
[30]
Nvrc: Neural video representation compres- sion.Advances in Neural Information Processing Systems, 37:132440–132462, 2024
Ho Man Kwan, Ge Gao, Fan Zhang, Andrew Gower, and David Bull. Nvrc: Neural video representation compres- sion.Advances in Neural Information Processing Systems, 37:132440–132462, 2024. 1, 3
2024
-
[31]
Conditional Coding for Flexible Learned Video Compression
Th´eo Ladune, Pierrick Philippe, Wassim Hamidouche, Lu Zhang, and Olivier D´eforges. Conditional Coding for Flexible Learned Video Compression. InNeural Compression: From Information Theory to Applications – Workshop @ ICLR 2021, 2021. 3
2021
-
[32]
Mobilecodec: neural inter-frame video com- pression on mobile devices
Hoang Le, Liang Zhang, Amir Said, Guillaume Sautiere, Yang Yang, Pranav Shrestha, Fei Yin, Reza Pourreza, and Auke Wiggers. Mobilecodec: neural inter-frame video com- pression on mobile devices. InProceedings of the 13th ACM Multimedia Systems Conference, pages 324–330, 2022. 3
2022
-
[33]
Gaussian- video: Efficient video representation and compression by gaussian splatting
Inseo Lee, Youngyoon Choi, and Joonseok Lee. Gaussian- video: Efficient video representation and compression by gaussian splatting. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 4471–4480, 2025. 3
2025
-
[34]
Deep contextual video com- pression.Advances in Neural Information Processing Sys- tems, 34:18114–18125, 2021
Jiahao Li, Bin Li, and Yan Lu. Deep contextual video com- pression.Advances in Neural Information Processing Sys- tems, 34:18114–18125, 2021. 2, 3
2021
-
[35]
Hybrid spatial-temporal en- tropy modelling for neural video compression
Jiahao Li, Bin Li, and Yan Lu. Hybrid spatial-temporal en- tropy modelling for neural video compression. InProceedings of the 30th ACM International Conference on Multimedia, pages 1503–1511, 2022
2022
-
[36]
Neural video compression with diverse contexts
Jiahao Li, Bin Li, and Yan Lu. Neural video compression with diverse contexts. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22616– 22626, 2023. 2, 4, 5, 6, 7, 12
2023
-
[37]
Neural Video Compression with Feature Modulation
Jiahao Li, Bin Li, and Yan Lu. Neural Video Compression with Feature Modulation. InIEEE/CVF Conference on Com- puter Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 17-21, 2024, 2024. 1, 2, 3, 4, 5, 6, 7
2024
-
[38]
M-LVC: Multiple frames prediction for learned video compression
Jianping Lin, Dong Liu, Houqiang Li, and Feng Wu. M-LVC: Multiple frames prediction for learned video compression. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3546–3554, 2020. 3
2020
-
[39]
MMVC: Learned Multi-Mode Video Compression with Block-based Prediction Mode Selection and Density-Adaptive Entropy Coding
Bowen Liu, Yu Chen, Rakesh Chowdary Machineni, Shiyu Liu, and Hun-Seok Kim. MMVC: Learned Multi-Mode Video Compression with Block-based Prediction Mode Selection and Density-Adaptive Entropy Coding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18487–18496, 2023
2023
-
[40]
Neural video coding using multi- scale motion compensation and spatiotemporal context model
Haojie Liu, Ming Lu, Zhan Ma, Fan Wang, Zhihuang Xie, Xun Cao, and Yao Wang. Neural video coding using multi- scale motion compensation and spatiotemporal context model. IEEE Transactions on Circuits and Systems for Video Tech- nology, 31(8):3182–3196, 2020. 3
2020
-
[41]
Conditional en- tropy coding for efficient video compression
Jerry Liu, Shenlong Wang, Wei-Chiu Ma, Meet Shah, Rui Hu, Pranaab Dhawan, and Raquel Urtasun. Conditional en- tropy coding for efficient video compression. InEuropean Conference on Computer Vision, pages 453–468. Springer,
-
[42]
An exploration with entropy constrained 3d gaussians for 2d video compression
Xiang Liu, Bin Chen, Zimo Liu, Yaowei Wang, and Shu-Tao Xia. An exploration with entropy constrained 3d gaussians for 2d video compression. InThe Thirteenth International Conference on Learning Representations, 2023. 3
2023
-
[43]
DVC: an end-to-end deep video compression framework
Guo Lu, Wanli Ouyang, Dong Xu, Xiaoyun Zhang, Chunlei Cai, and Zhiyong Gao. DVC: an end-to-end deep video compression framework. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11006–11015, 2019. 3
2019
-
[44]
An end-to-end learning framework for video compression.IEEE transactions on pattern analysis and machine intelligence, 43(10):3292–3308, 2020
Guo Lu, Xiaoyun Zhang, Wanli Ouyang, Li Chen, Zhiyong Gao, and Dong Xu. An end-to-end learning framework for video compression.IEEE transactions on pattern analysis and machine intelligence, 43(10):3292–3308, 2020. 2, 3
2020
-
[45]
Wenzhuo Ma and Zhenzhong Chen. Diffusion-based per- ceptual neural video compression with temporal diffusion information reuse.arXiv preprint arXiv:2501.13528, 2025. 1
-
[46]
Uncertainty-Aware Deep Video Compression with Ensembles.IEEE Transac- tions on Multimedia, 2024
Wufei Ma, Jiahao Li, Bin Li, and Yan Lu. Uncertainty-Aware Deep Video Compression with Ensembles.IEEE Transac- tions on Multimedia, 2024. 3
2024
-
[47]
Vct: A video compression transformer.arXiv preprint arXiv:2206.07307, 2022
Fabian Mentzer, George Toderici, David Minnen, Sung-Jin Hwang, Sergi Caelles, Mario Lucic, and Eirikur Agusts- son. Vct: A video compression transformer.arXiv preprint arXiv:2206.07307, 2022. 3
-
[48]
UVG dataset: 50/120fps 4K sequences for video codec analysis and development
Alexandre Mercat, Marko Viitanen, and Jarno Vanne. UVG dataset: 50/120fps 4K sequences for video codec analysis and development. InProceedings of the 11th ACM Multimedia Systems Conference, pages 297–302, 2020. 7
2020
-
[49]
Joint autoregressive and hierarchical priors for learned image com- pression.Advances in neural information processing systems, 31, 2018
David Minnen, Johannes Ball´e, and George D Toderici. Joint autoregressive and hierarchical priors for learned image com- pression.Advances in neural information processing systems, 31, 2018. 2, 5
2018
-
[50]
End-to-end learning of video compression using spatio-temporal autoencoders
Jorge Pessoa, Helena Aidos, Pedro Tom ´as, and M ´ario AT Figueiredo. End-to-end learning of video compression using spatio-temporal autoencoders. In2020 IEEE Workshop on Signal Processing Systems (SiPS), pages 1–6. IEEE, 2020. 3, 4
2020
-
[51]
Motion information propagation for neural video compression
Linfeng Qi, Jiahao Li, Bin Li, Houqiang Li, and Yan Lu. Motion information propagation for neural video compression. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6111–6120, 2023. 3
2023
-
[52]
Long-term temporal context gathering for neural video compression
Linfeng Qi, Zhaoyang Jia, Jiahao Li, Bin Li, Houqiang Li, and Yan Lu. Long-term temporal context gathering for neural video compression. InEuropean Conference on Computer Vision, pages 305–322. Springer, 2024. 1, 3
2024
-
[53]
Generative latent coding for ultra-low bitrate image and video compression.IEEE Transactions on Circuits and Systems for Video Technology, 2025
Linfeng Qi, Zhaoyang Jia, Jiahao Li, Bin Li, Houqiang Li, and Yan Lu. Generative latent coding for ultra-low bitrate image and video compression.IEEE Transactions on Circuits and Systems for Video Technology, 2025. 1
2025
-
[54]
ELF-VC: Effi- cient learned flexible-rate video coding
Oren Rippel, Alexander G Anderson, Kedar Tatwawadi, San- jay Nair, Craig Lytle, and Lubomir Bourdev. ELF-VC: Effi- cient learned flexible-rate video coding. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 14479–14488, 2021. 3
2021
-
[55]
Scaling vision with sparse mix- ture of experts.Advances in Neural Information Processing Systems, 34:8583–8595, 2021
Carlos Riquelme, Joan Puigcerver, Basil Mustafa, Maxim Neumann, Rodolphe Jenatton, Andr´e Susano Pinto, Daniel Keysers, and Neil Houlsby. Scaling vision with sparse mix- ture of experts.Advances in Neural Information Processing Systems, 34:8583–8595, 2021. 5
2021
-
[56]
Temporal Context Mining for Learned Video Compression
Xihua Sheng, Jiahao Li, Bin Li, Li Li, Dong Liu, and Yan Lu. Temporal Context Mining for Learned Video Compression. IEEE Transactions on Multimedia, 2022. 3
2022
-
[57]
Bi-directional deep contextual video compression.IEEE Transactions on Multimedia, 2025
Xihua Sheng, Li Li, Dong Liu, and Shiqi Wang. Bi-directional deep contextual video compression.IEEE Transactions on Multimedia, 2025. 1, 3
2025
-
[58]
Implicit neural representa- tions with periodic activation functions.Advances in neural information processing systems, 33:7462–7473, 2020
Vincent Sitzmann, Julien Martel, Alexander Bergman, David Lindell, and Gordon Wetzstein. Implicit neural representa- tions with periodic activation functions.Advances in neural information processing systems, 33:7462–7473, 2020. 1
2020
-
[59]
Towards real-time neural video codec for cross-platform application using calibration information
Kuan Tian, Yonghang Guan, Jinxi Xiang, Jun Zhang, Xiao Han, and Wei Yang. Towards real-time neural video codec for cross-platform application using calibration information. InProceedings of the 31st ACM International Conference on Multimedia, pages 7961–7970, 2023. 3
2023
-
[60]
Mobilenvc: Real-time 1080p neural video compression on a mobile de- vice
Ties Van Rozendaal, Tushar Singhal, Hoang Le, Guillaume Sautiere, Amir Said, Krishna Buska, Anjuman Raha, Dim- itris Kalatzis, Hitarth Mehta, Frank Mayer, et al. Mobilenvc: Real-time 1080p neural video compression on a mobile de- vice. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 4323–4333, 2024. 3
2024
-
[61]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[62]
MCL-JCV: a JND-based H
Haiqiang Wang, Weihao Gan, Sudeng Hu, Joe Yuchieh Lin, Lina Jin, Longguang Song, Ping Wang, Ioannis Katsavouni- dis, Anne Aaron, and C-C Jay Kuo. MCL-JCV: a JND-based H. 264/A VC video quality assessment dataset. In2016 IEEE international conference on image processing (ICIP), pages 1509–1513. IEEE, 2016. 7
2016
-
[63]
Omnitokenizer: A joint image- video tokenizer for visual generation.Advances in Neural Information Processing Systems, 37:28281–28295, 2024
Junke Wang, Yi Jiang, Zehuan Yuan, Bingyue Peng, Zuxuan Wu, and Yu-Gang Jiang. Omnitokenizer: A joint image- video tokenizer for visual generation.Advances in Neural Information Processing Systems, 37:28281–28295, 2024. 3
2024
-
[64]
Gsvc: Effi- cient video representation and compression through 2d gaus- sian splatting
Longan Wang, Yuang Shi, and Wei Tsang Ooi. Gsvc: Effi- cient video representation and compression through 2d gaus- sian splatting. InProceedings of the 35th Workshop on Net- work and Operating System Support for Digital Audio and Video, pages 15–21, 2025. 3
2025
-
[65]
Improved video vae for latent video diffusion model
Pingyu Wu, Kai Zhu, Yu Liu, Liming Zhao, Wei Zhai, Yang Cao, and Zheng-Jun Zha. Improved video vae for latent video diffusion model. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 18124–18133, 2025. 3
2025
-
[66]
Single-step diffusion-based video coding with semantic-temporal guidance
Naifu Xue, Zhaoyang Jia, Jiahao Li, Bin Li, Zihan Zheng, Yuan Zhang, and Yan Lu. Single-step diffusion-based video coding with semantic-temporal guidance. InIEEE/CVF Con- ference on Computer Vision and Pattern Recognition, CVPR,
-
[67]
Video enhancement with task-oriented flow.International Journal of Computer Vision, 127(8):1106– 1125, 2019
Tianfan Xue, Baian Chen, Jiajun Wu, Donglai Wei, and William T Freeman. Video enhancement with task-oriented flow.International Journal of Computer Vision, 127(8):1106– 1125, 2019. 6
2019
-
[68]
Learning for video compression with hierarchical quality and recurrent enhancement
Ren Yang, Fabian Mentzer, Luc Van Gool, and Radu Timofte. Learning for video compression with hierarchical quality and recurrent enhancement. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6628–6637, 2020. 1, 3
2020
-
[69]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiao- han Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer.arXiv preprint arXiv:2408.06072, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[70]
Cv- vae: A compatible video vae for latent generative video mod- els.Advances in Neural Information Processing Systems, 37: 12847–12871, 2024
Sijie Zhao, Yong Zhang, Xiaodong Cun, Shaoshu Yang, Muyao Niu, Xiaoyu Li, Wenbo Hu, and Ying Shan. Cv- vae: A compatible video vae for latent generative video mod- els.Advances in Neural Information Processing Systems, 37: 12847–12871, 2024
2024
-
[71]
Open-Sora: Democratizing Efficient Video Production for All
Zangwei Zheng, Xiangyu Peng, Tianji Yang, Chenhui Shen, Shenggui Li, Hongxin Liu, Yukun Zhou, Tianyi Li, and Yang You. Open-sora: Democratizing efficient video production for all.arXiv preprint arXiv:2412.20404, 2024. 3 Ultra-Fast Neural Video Compression Supplementary Material This document provides supplementary material for our paper, detailing the exp...
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.