Disentangling Continuous-Time Latent Dynamics: Identifiability of Latent SDEs via Diffusion Shifts
Pith reviewed 2026-06-29 04:23 UTC · model grok-4.3
The pith
Two diagonal diffusion regimes identify latent coordinates of SDEs up to permutation and scaling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
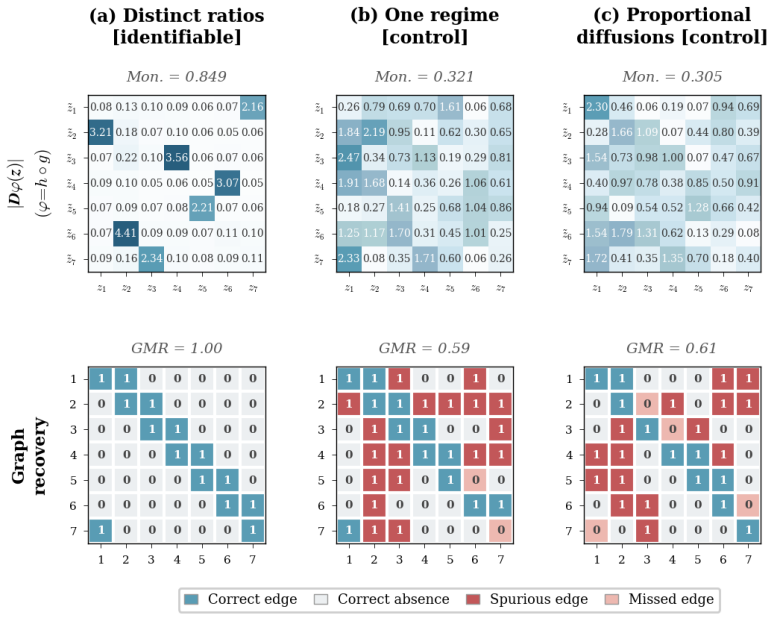
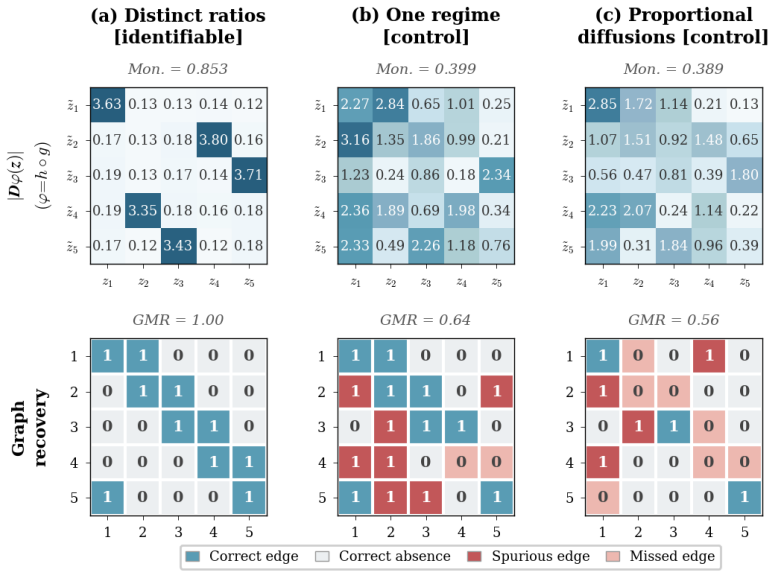
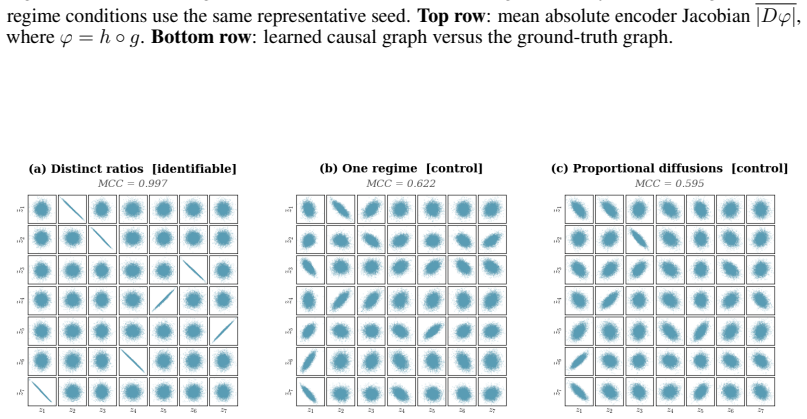
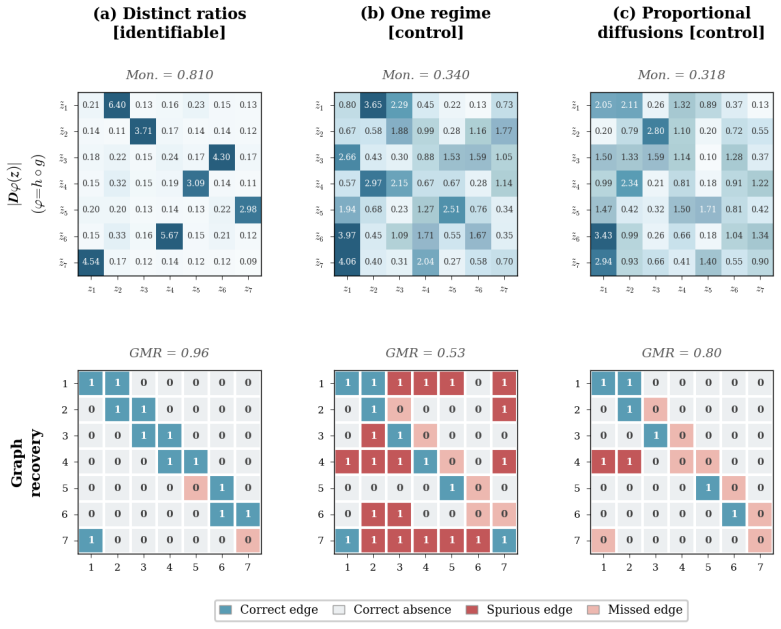
Two diagonal diffusion regimes with pairwise distinct coordinate-wise variance ratios identify the latent coordinates up to permutation and scaling, without any sparsity assumption on the drift. The result is first proved for linear Ornstein-Uhlenbeck systems and then extended to general additive-noise latent SDEs. Under mild smoothness, the instantaneous drift-Jacobian causal graph is identifiable up to the same permutation.
What carries the argument
Environment-induced shifts in diagonal diffusion covariance between two regimes that produce distinct coordinate-wise variance ratios.
If this is right
- Latent coordinates become recoverable up to permutation and scaling from data in only two environments.
- The causal graph encoded by the drift Jacobian becomes identifiable under the same conditions.
- A two-stage estimator recovers the latent representation and optionally the graph.
- The predicted identifiability boundary is confirmed on synthetic systems and illustrated on real sensor trajectories.
Where Pith is reading between the lines
- The same diffusion-shift logic could be tested on other continuous-time models whose noise structure is environment-dependent.
- Collecting paired trajectories under deliberately altered noise variances might become a practical protocol for latent disentanglement.
- Relaxing diagonality or increasing the number of environments would be a direct next step to widen applicability.
Load-bearing premise
The diffusion covariance is exactly diagonal in the latent coordinates and the two environments produce distinct variance ratios for each coordinate.
What would settle it
A counter-example in which two environments satisfy the distinct-ratio condition yet the latent coordinates cannot be recovered up to permutation and scaling would falsify the identifiability theorem.
Figures
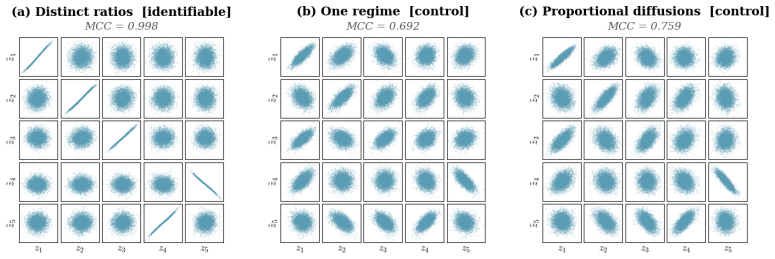
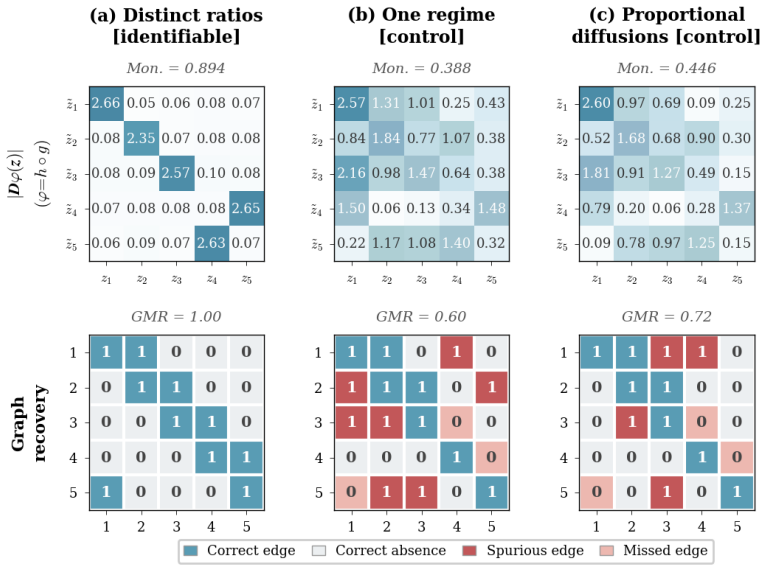
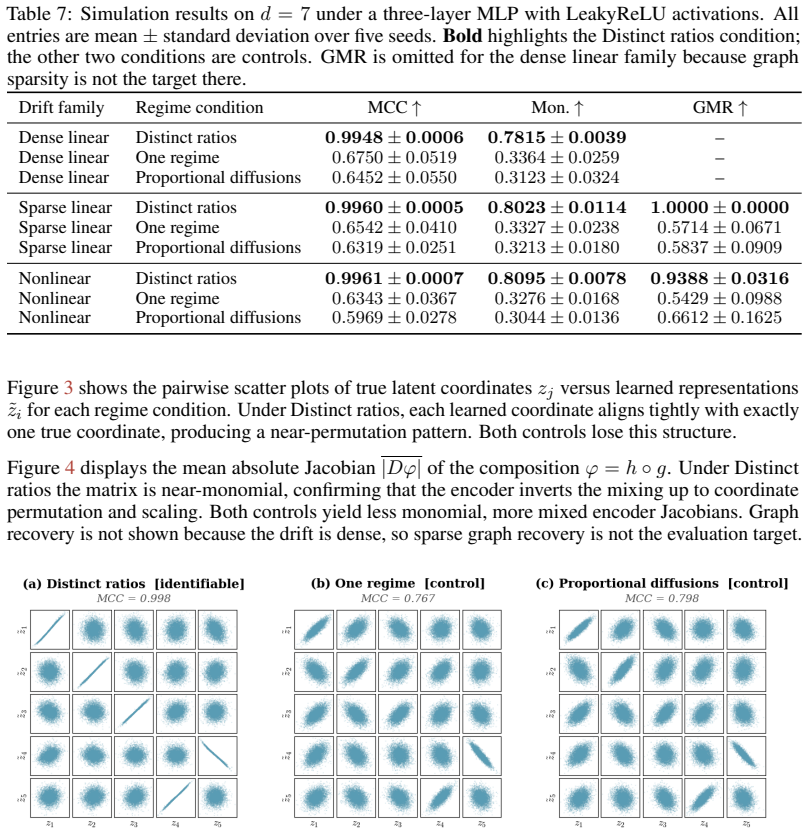
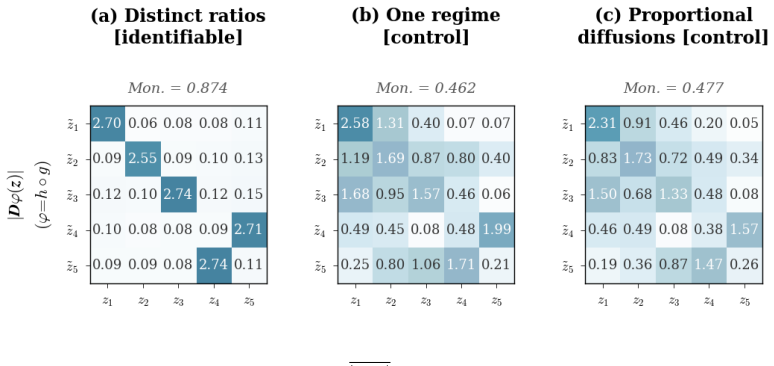
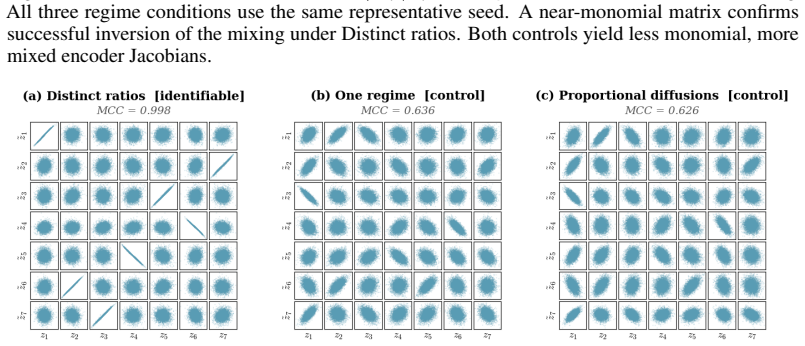
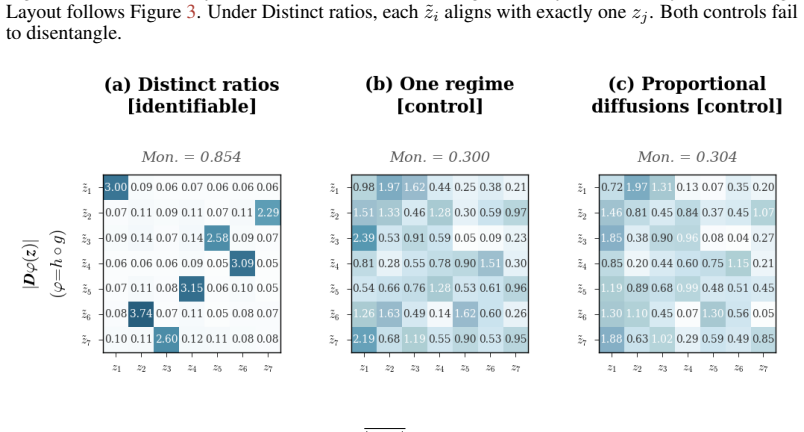

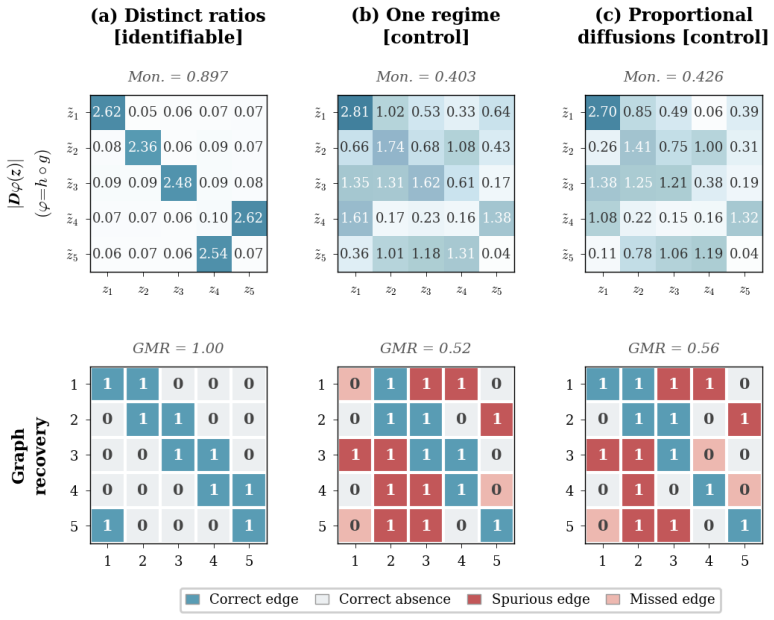
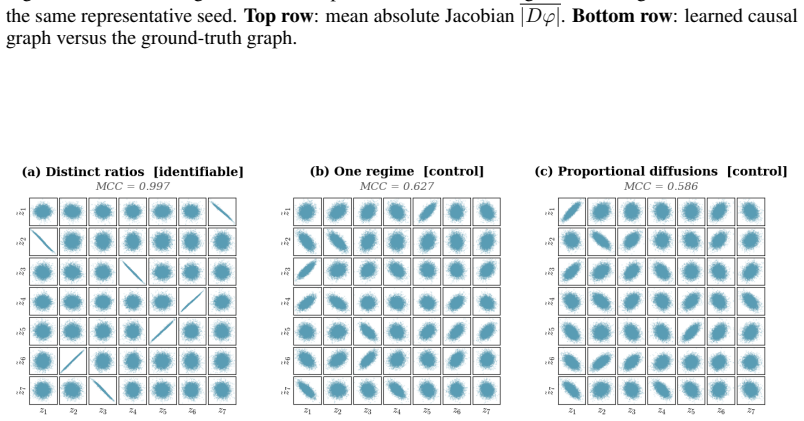

read the original abstract
Causal representation learning for time series has developed strong identifiability results in discrete-time latent causal models, but identifiability in continuous-time latent stochastic differential equation (SDE) models remains largely open. We address this gap using environment-induced shifts in diffusion covariance. We study additive-noise latent SDEs observed through an unknown nonlinear diffeomorphism, with shared drift but environment-specific diffusion covariance. We show that two diagonal diffusion regimes with pairwise distinct coordinate-wise variance ratios identify the latent coordinates up to permutation and scaling, without any sparsity assumption on the drift. We first prove this result for linear Ornstein--Uhlenbeck systems and then extend it to general additive-noise latent SDEs. Under mild smoothness, the instantaneous drift-Jacobian causal graph is identifiable up to the same permutation. We propose a two-stage estimator for latent disentanglement and optional graph recovery; experiments on synthetic systems confirm the predicted identifiability boundary, and an application to Hardanger Bridge monitoring data illustrates the approach on real sensor trajectories.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that for latent SDEs with additive noise observed through an unknown nonlinear diffeomorphism, with shared drift but environment-specific diffusion covariances, two diagonal diffusion regimes with pairwise distinct coordinate-wise variance ratios identify the latent coordinates up to permutation and scaling, without sparsity assumptions on the drift. The result is first established for linear Ornstein-Uhlenbeck systems and then extended to general additive-noise latent SDEs. Under mild smoothness, the instantaneous drift-Jacobian causal graph is also identifiable up to the same equivalence. A two-stage estimator is proposed for latent disentanglement (and optional graph recovery), with experiments on synthetic systems confirming the identifiability boundary and an application to Hardanger Bridge sensor data.
Significance. If the results hold, this advances causal representation learning by moving identifiability results into continuous-time latent SDE models while removing the sparsity requirements common in discrete-time settings. The use of environment-induced diffusion shifts as the identifying signal, combined with the absence of drift sparsity and the additional graph identifiability result, provides a distinctive theoretical contribution. Empirical confirmation on both synthetic and real trajectories strengthens the practical relevance for time-series disentanglement.
major comments (1)
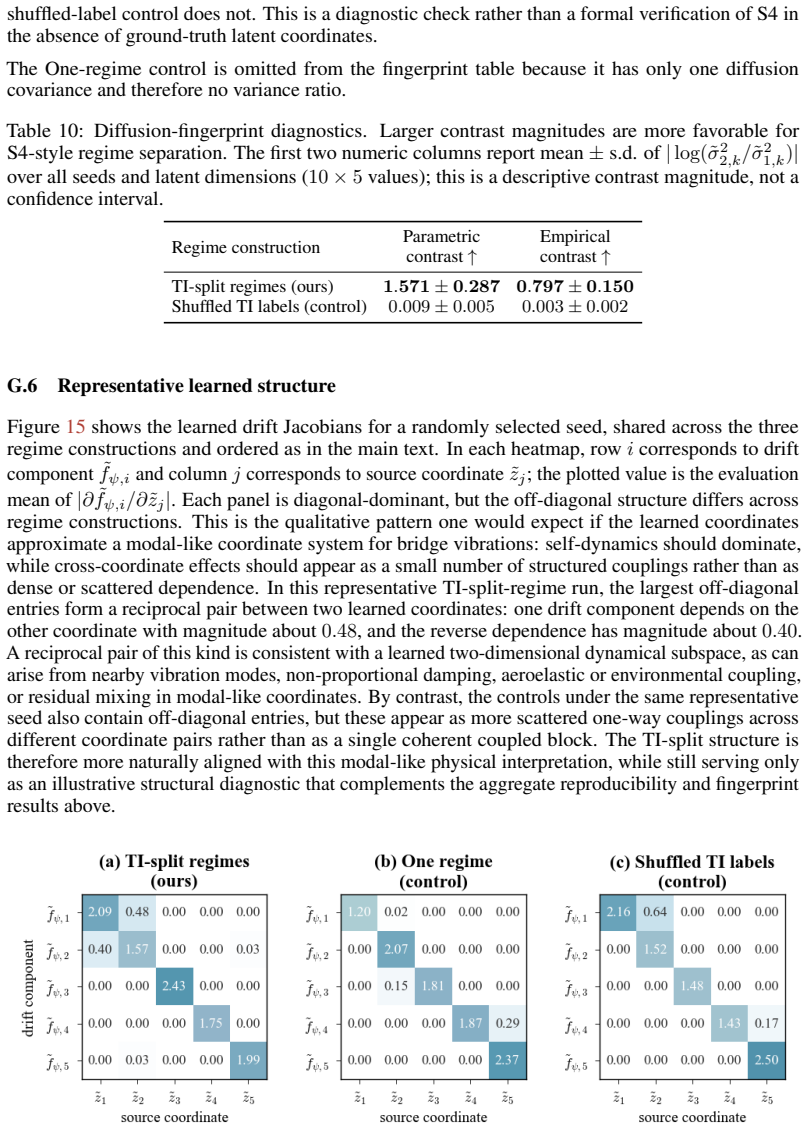
- [nonlinear extension] The extension from the linear OU case to general additive-noise latent SDEs is load-bearing for the central claim. The abstract sketches the strategy but does not detail how the argument carries over; any additional regularity conditions on the drift or diffeomorphism must be stated explicitly to confirm there are no hidden gaps.
minor comments (2)
- [Abstract] The precise definition of 'pairwise distinct coordinate-wise variance ratios' should be formalized with an equation or inequality in the main theorem statement to remove any ambiguity.
- The two-stage estimator description would benefit from pseudocode or explicit steps showing how the diffusion covariance estimates are used to recover the latent coordinates.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our contribution and for the constructive comment. We address the major comment below.
read point-by-point responses
-
Referee: [nonlinear extension] The extension from the linear OU case to general additive-noise latent SDEs is load-bearing for the central claim. The abstract sketches the strategy but does not detail how the argument carries over; any additional regularity conditions on the drift or diffeomorphism must be stated explicitly to confirm there are no hidden gaps.
Authors: We agree that the nonlinear extension is central and that the abstract provides only a high-level sketch. The full argument appears in the main text (following the linear OU result), where we use the fact that the diffeomorphism preserves the additive-noise structure and that the shared drift remains identifiable via the distinct diffusion ratios. The regularity conditions are the mild smoothness assumptions already stated for existence/uniqueness of solutions and applicability of Itô calculus (C² drift, C³ diffeomorphism). In the revision we will insert an explicit remark immediately after the linear theorem that (i) lists these conditions in one place and (ii) gives a concise step-by-step outline of how the linear identifiability argument lifts to the nonlinear setting, thereby removing any ambiguity about hidden gaps. revision: yes
Circularity Check
No significant circularity
full rationale
The paper advances a mathematical identifiability theorem for latent SDEs under environment-induced diffusion shifts. The central result states that two diagonal diffusion regimes with pairwise distinct per-coordinate variance ratios suffice to identify latent coordinates (up to permutation and scaling) and the instantaneous drift-Jacobian graph, first for linear OU processes and then for general additive-noise SDEs. This identifying condition is stated explicitly as an assumption in the theorem statement rather than derived from or presupposed by the target result. No fitted parameters are renamed as predictions, no self-citation chains are invoked to justify uniqueness, and the proof is presented as self-contained without reduction to prior author work or ansatz smuggling. The absence of sparsity assumptions on the drift is an explicit feature of the stated conditions, not a hidden circularity.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The observation map is an unknown nonlinear diffeomorphism.
- domain assumption Drift is shared across environments while diffusion covariance is environment-specific and diagonal.
Reference graph
Works this paper leans on
-
[1]
Ahuja, A
K. Ahuja, A. Mansouri, and Y . Wang. Multi-domain causal representation learning via weak distributional invariances. InInternational Conference on Artificial Intelligence and Statistics, pages 865–873. PMLR, 2024
2024
-
[2]
M. W. Baumgartner, A. Lei, J. Watson, and I. Posner. Disentangling dynamical systems: Causal representation learning meets local sparse attention.arXiv preprint arXiv:2603.14483, 2026
Pith/arXiv arXiv 2026
-
[3]
G. Chen, Y . Shen, Z. Chen, X. Song, Y . Sun, W. Yao, X. Liu, and K. Zhang. Caring: learning temporal causal representation under non-invertible generation process. InProceedings of the 41st International Conference on Machine Learning, pages 7236–7259, 2024
2024
-
[4]
R. T. Chen, Y . Rubanova, J. Bettencourt, and D. K. Duvenaud. Neural ordinary differential equations.Advances in neural information processing systems, 31, 2018
2018
-
[5]
S. Fan, K. Zhang, and L. Cheng. Trace: Trajectory recovery for continuous mechanism evolution in causal representation learning.arXiv preprint arXiv:2601.21135, 2026
arXiv 2026
-
[6]
Fenerci, K
A. Fenerci, K. Andreas Kvåle, Ø. Wiig Petersen, A. Rønnquist, and O. Øiseth. Data set from long-term wind and acceleration monitoring of the hardanger bridge.Journal of Structural Engineering, 147(5):04721003, 2021
2021
-
[7]
Fenerci, K
A. Fenerci, K. A. Kvåle, Ø. W. Petersen, A. Rønnquist, and O. Øiseth. Wind and acceleration data from the hardanger bridge.Norges teknisk-naturvitenskapelige universitet, 2020
2020
-
[8]
V . Guan, J. Janssen, H. Rahmani, A. Warren, S. Zhang, E. Robeva, and G. Schiebinger. Identifying drift, diffusion, and causal structure from temporal snapshots.arXiv preprint arXiv:2410.22729, 2024
arXiv 2024
-
[9]
Hälvä and A
H. Hälvä and A. Hyvarinen. Hidden markov nonlinear ica: Unsupervised learning from nonstationary time series. InConference on Uncertainty in Artificial Intelligence, pages 939–
-
[10]
Hälvä, S
H. Hälvä, S. Le Corff, L. Lehéricy, J. So, Y . Zhu, E. Gassiat, and A. Hyvarinen. Disentan- gling identifiable features from noisy data with structured nonlinear ica.Advances in Neural Information Processing Systems, 34:1624–1633, 2021
2021
-
[11]
Hyvarinen and H
A. Hyvarinen and H. Morioka. Unsupervised feature extraction by time-contrastive learning and nonlinear ica.Advances in neural information processing systems, 29, 2016
2016
-
[12]
Hyvarinen and H
A. Hyvarinen and H. Morioka. Nonlinear ica of temporally dependent stationary sources. In Artificial intelligence and statistics, pages 460–469. PMLR, 2017
2017
-
[13]
Hyvärinen and P
A. Hyvärinen and P. Pajunen. Nonlinear independent component analysis: Existence and uniqueness results.Neural networks, 12(3):429–439, 1999
1999
-
[14]
Hyvarinen, H
A. Hyvarinen, H. Sasaki, and R. Turner. Nonlinear ica using auxiliary variables and generalized contrastive learning. InThe 22nd international conference on artificial intelligence and statistics, pages 859–868. PMLR, 2019
2019
-
[15]
Khemakhem, D
I. Khemakhem, D. Kingma, R. Monti, and A. Hyvarinen. Variational autoencoders and nonlinear ica: A unifying framework. InInternational conference on artificial intelligence and statistics, pages 2207–2217. PMLR, 2020
2020
-
[16]
Kidger, J
P. Kidger, J. Morrill, J. Foster, and T. Lyons. Neural controlled differential equations for irregular time series.Advances in neural information processing systems, 33:6696–6707, 2020
2020
-
[17]
Li, T.-K
X. Li, T.-K. L. Wong, R. T. Chen, and D. Duvenaud. Scalable gradients for stochastic differential equations. InInternational conference on artificial intelligence and statistics, pages 3870–3882. PMLR, 2020
2020
-
[18]
Z. Li, M. Fu, J. Huang, Y . Shen, R. Cai, Y . Sun, G. Chen, and K. Zhang. Towards identifiability of hierarchical temporal causal representation learning. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. 10
2025
-
[19]
Z. Li, Y . Shen, K. Zheng, R. Cai, X. Song, M. Gong, G. Chen, and K. Zhang. On the identi- fication of temporal causal representation with instantaneous dependence. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[20]
Lippe, S
P. Lippe, S. Magliacane, S. Löwe, Y . M. Asano, T. Cohen, and E. Gavves. Causal represen- tation learning for instantaneous and temporal effects in interactive systems. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[21]
Lippe, S
P. Lippe, S. Magliacane, S. Löwe, Y . M. Asano, T. Cohen, and S. Gavves. Citris: Causal identifiability from temporal intervened sequences. InInternational Conference on Machine Learning, pages 13557–13603. PMLR, 2022
2022
-
[22]
Locatello, S
F. Locatello, S. Bauer, M. Lucic, G. Raetsch, S. Gelly, B. Schölkopf, and O. Bachem. Chal- lenging common assumptions in the unsupervised learning of disentangled representations. In international conference on machine learning, pages 4114–4124. PMLR, 2019
2019
-
[23]
Manten, C
G. Manten, C. Casolo, E. Ferrucci, S. W. Mogensen, C. Salvi, and N. Kilbertus. Signature kernel conditional independence tests in causal discovery for stochastic processes. In13th Interna- tional Conference on Learning Representations, ICLR 2025, pages 62970–63006. International Conference on Learning Representations, ICLR, 2025
2025
-
[24]
Manten, C
G. Manten, C. Casolo, S. W. Mogensen, and N. Kilbertus. An asymmetric independence model for causal discovery on path spaces. InCausal Learning and Reasoning, pages 64–89. PMLR, 2025
2025
-
[25]
Morioka and A
H. Morioka and A. Hyvarinen. Causal representation learning made identifiable by grouping of observational variables. InInternational Conference on Machine Learning, pages 36249–36293. PMLR, 2024
2024
-
[26]
I. Ng, S. Xie, X. Dong, P. Spirtes, and K. Zhang. Causal representation learning from general environments under nonparametric mixing. InInternational Conference on Artificial Intelligence and Statistics, pages 3700–3708. PMLR, 2025
2025
-
[27]
Oksendal.Stochastic differential equations: an introduction with applications
B. Oksendal.Stochastic differential equations: an introduction with applications. Springer Science & Business Media, 2013
2013
-
[28]
Reizinger, S
P. Reizinger, S. Guo, F. Huszár, B. Schölkopf, and W. Brendel. Identifiable exchangeable mechanisms for causal structure and representation learning. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[29]
J. Ren, Y . Wang, and B. Huang. Causal representation meets stochastic modeling under generic geometry.arXiv preprint arXiv:2602.05033, 2026
arXiv 2026
-
[30]
Rubanova, R
Y . Rubanova, R. T. Chen, and D. K. Duvenaud. Latent ordinary differential equations for irregularly-sampled time series.Advances in neural information processing systems, 32, 2019
2019
-
[31]
Runge, A
J. Runge, A. Gerhardus, G. Varando, V . Eyring, and G. Camps-Valls. Causal inference for time series.Nature Reviews Earth & Environment, 4(7):487–505, 2023
2023
-
[32]
Särkkä and A
S. Särkkä and A. Solin.Applied stochastic differential equations, volume 10. Cambridge University Press, 2019
2019
-
[33]
Schölkopf, F
B. Schölkopf, F. Locatello, S. Bauer, N. R. Ke, N. Kalchbrenner, A. Goyal, and Y . Bengio. Toward causal representation learning.Proceedings of the IEEE, 109(5):612–634, 2021
2021
-
[34]
Shojaie and E
A. Shojaie and E. B. Fox. Granger causality: A review and recent advances.Annual review of statistics and its application, 9:289–319, 2022
2022
-
[35]
X. Song, Z. Li, G. Chen, Y . Zheng, Y . Fan, X. Dong, and K. Zhang. Causal temporal representa- tion learning with nonstationary sparse transition.Advances in Neural Information Processing Systems, 37:77098–77131, 2024
2024
-
[36]
X. Song, W. Yao, Y . Fan, X. Dong, G. Chen, J. C. Niebles, E. Xing, and K. Zhang. Temporally disentangled representation learning under unknown nonstationarity.Advances in Neural Information Processing Systems, 36:8092–8113, 2023. 11
2023
-
[37]
D. W. Stroock and S. S. Varadhan.Multidimensional diffusion processes. Springer, 2007
2007
-
[38]
Varici, E
B. Varici, E. Acartürk, K. Shanmugam, and A. Tajer. General identifiability and achievability for causal representation learning. InInternational Conference on Artificial Intelligence and Statistics, pages 2314–2322. PMLR, 2024
2024
-
[39]
von Kügelgen, M
J. von Kügelgen, M. Besserve, L. Wendong, L. Gresele, A. Keki ´c, E. Bareinboim, D. Blei, and B. Schölkopf. Nonparametric identifiability of causal representations from unknown interventions.Advances in Neural Information Processing Systems, 36:48603–48638, 2023
2023
-
[40]
B. Wang, J. Jennings, and W. Gong. Neural structure learning with stochastic differential equations. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[41]
Y . Wang, X. Geng, W. Huang, B. Huang, and M. Gong. Generator identification for linear sdes with additive and multiplicative noise.Advances in Neural Information Processing Systems, 36:64103–64138, 2023
2023
-
[42]
Welch, J
R. Welch, J. Zhang, and C. Uhler. Identifiability guarantees for causal disentanglement from purely observational data.Advances in Neural Information Processing Systems, 37:102796– 102821, 2024
2024
-
[43]
D. Xu, D. Yao, S. Lachapelle, P. Taslakian, J. V on Kügelgen, F. Locatello, and S. Magliacane. A sparsity principle for partially observable causal representation learning. InInternational Conference on Machine Learning, pages 55389–55433. PMLR, 2024
2024
-
[44]
D. Yao, C. Muller, and F. Locatello. Marrying causal representation learning with dynamical systems for science.Advances in Neural Information Processing Systems, 37:71705–71736, 2024
2024
-
[45]
D. Yao, D. Rancati, R. Cadei, M. Fumero, and F. Locatello. Unifying causal representation learning with the invariance principle. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[46]
D. Yao, D. Xu, S. Lachapelle, S. Magliacane, P. Taslakian, G. Martius, J. v. Kügelgen, and F. Locatello. Multi-view causal representation learning with partial observability. In12th International Conference on Learning Representations, 2024
2024
-
[47]
W. Yao, G. Chen, and K. Zhang. Temporally disentangled representation learning.Advances in Neural Information Processing Systems, 35:26492–26503, 2022
2022
-
[48]
W. Yao, Y . Sun, A. Ho, C. Sun, and K. Zhang. Learning temporally causal latent processes from general temporal data. In10th International Conference on Learning Representations, ICLR 2022, 2022
2022
-
[49]
Zhang, S
K. Zhang, S. Xie, I. Ng, and Y . Zheng. Causal representation learning from multiple distributions: A general setting. InInternational Conference on Machine Learning, pages 60057–60075. PMLR, 2024
2024
-
[50]
constant Jacobian ⇒ affine map
A. Zweig, Z. Lin, E. Azizi, and D. Knowles. Towards identifiability of interventional stochastic differential equations.arXiv preprint arXiv:2505.15987, 2025. 12 A Notation Table 3 summarizes the principal notation used throughout the paper. Table 3: Summary of notation. Symbol Description Spaces and indices dDimension of the latent (and observed) state s...
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.