Machine-learning surrogate model for one-dimensional GaAs/Al_(0.3)Ga_(0.7)As distributed Bragg reflector spectra
Pith reviewed 2026-06-27 19:26 UTC · model grok-4.3
The pith
A Gaussian process surrogate predicts DBR reflectance spectra seventy times faster than transfer-matrix calculations while supplying calibrated uncertainty.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
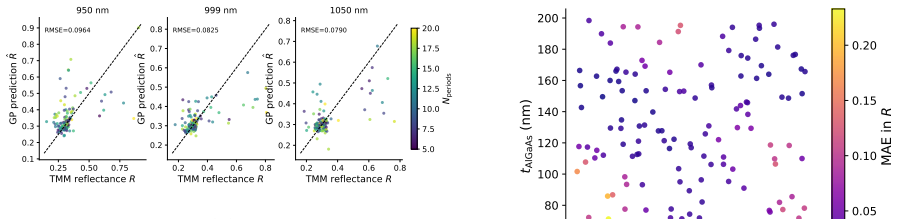
A Gaussian-process surrogate model trained on principal components of 1500 Latin-hypercube transfer-matrix simulations predicts the normal-incidence reflectance spectrum of one-dimensional GaAs/Al0.3Ga0.7As distributed Bragg reflectors. On a held-out test set the model attains RMSE = 0.085 and R² = 0.276; its 95 percent prediction bands cover 98.9 percent of the observed residuals. Inference requires 4.4 ms per spectrum, producing a roughly seventy-fold reduction in wall-clock time relative to the original transfer-matrix calculation and thereby enabling rapid design-space exploration.
What carries the argument
The Gaussian process regressor fitted independently to each of the 26 principal components of the reflectance spectrum, which reconstructs the full output while returning per-wavelength uncertainty estimates.
If this is right
- Designers can scan large regions of DBR parameter space in minutes rather than hours.
- The supplied uncertainty bands identify regions of the design space where predictions are most trustworthy.
- The surrogate can be inserted directly into iterative optimization loops that adjust layer thicknesses to meet target reflectance profiles.
- The same principal-component-plus-Gaussian-process pipeline can be retrained for other multilayer optical stacks once new transfer-matrix data are available.
Where Pith is reading between the lines
- The approach could be combined with the Random Forest baseline already tested in the paper to trade some uncertainty quantification for higher point-wise accuracy.
- Real-time graphical interfaces that let a user drag layer thicknesses and instantly see the updated spectrum become feasible once the model is embedded in design software.
- Retraining the surrogate on spectra that include oblique incidence or different material systems would extend its utility to a wider class of photonic components.
Load-bearing premise
The 1500 Latin-hypercube samples adequately cover the ranges of layer thicknesses and wavelengths that matter for practical DBR designs.
What would settle it
A fresh set of transfer-matrix simulations performed at parameter values outside the original Latin-hypercube bounds, where the Gaussian process predictions fall outside the reported 95 percent bands on a substantial fraction of wavelengths.
Figures
read the original abstract
We present a Gaussian-process (GP) surrogate model for the normal-incidence reflectance spectrum of one-dimensional GaAs/Al$_{0.3}$Ga$_{0.7}$ distributed Bragg reflectors (DBRs). A Latin-hypercube dataset of 1500 transfer-matrix-method (TMM) simulations is used to train and evaluate the model. Principal component analysis reduces the spectral output to 26 components; one GP is fitted per component. On a held-out test set the GP achieves RMSE=0.085 and $R^2=0.276$, while a Random Forest baseline reaches RMSE=0.065 and $R^2=0.572$. GP inference is 4.4 ms per spectrum compared with ~308 ms for TMM, yielding a ~70x speedup. Uncertainty calibration shows that the GP 95% prediction band covers 98.9% of test residuals. These results establish a rapid surrogate for DBR design-space exploration.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript develops a Gaussian-process surrogate for normal-incidence reflectance spectra of one-dimensional GaAs/Al0.3Ga0.7As DBRs. A 1500-point Latin-hypercube sample of TMM simulations is reduced via PCA to 26 components; independent GPs are trained on each component. On a held-out test set the GP reports RMSE = 0.085 and R² = 0.276 (Random Forest baseline: RMSE = 0.065, R² = 0.572), inference time 4.4 ms versus ~308 ms for TMM (~70× speedup), and 95 % prediction bands that cover 98.9 % of residuals. The authors conclude that the surrogate enables rapid DBR design-space exploration.
Significance. A well-calibrated, fast surrogate for DBR spectra would be useful for design optimization. The reported uncertainty calibration is a positive feature, but the low GP R² relative to the Random Forest baseline limits the practical utility of the presented model for design exploration.
major comments (3)
- [Abstract] Abstract: the statement that the results 'establish a rapid surrogate for DBR design-space exploration' is not supported by the reported metrics; the GP R² = 0.276 is substantially lower than the Random Forest R² = 0.572, indicating that the surrogate explains only ~28 % of the spectral variance and therefore cannot reliably support design-space exploration.
- [Methods] Methods / Results: no details are given on GP hyperparameter selection, kernel choice, or the procedure used to determine the number of retained PCA components (26). These choices directly affect the reported R² and RMSE and must be documented to allow assessment of robustness.
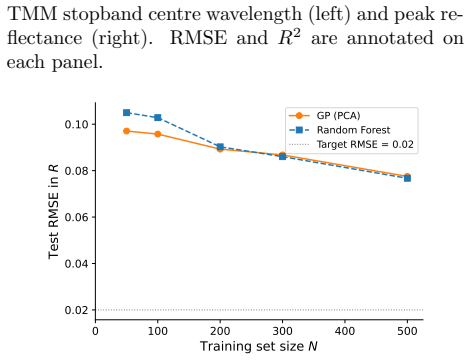
- [Results] Results: the claim of adequate sampling by the 1500-point Latin-hypercube design is not accompanied by any convergence test (e.g., learning curves or additional validation points outside the original hypercube), leaving open whether the low GP R² arises from insufficient coverage of the design space.
minor comments (1)
- [Abstract] The abstract and main text should explicitly state the wavelength range and number of spectral points used in the TMM simulations and PCA.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which have helped us improve the clarity and rigor of the manuscript. We address each major comment below and have made revisions where the concerns are valid.
read point-by-point responses
-
Referee: [Abstract] Abstract: the statement that the results 'establish a rapid surrogate for DBR design-space exploration' is not supported by the reported metrics; the GP R² = 0.276 is substantially lower than the Random Forest R² = 0.572, indicating that the surrogate explains only ~28 % of the spectral variance and therefore cannot reliably support design-space exploration.
Authors: We agree that the original abstract phrasing overstated the surrogate's utility for design-space exploration given the modest R². While the GP provides calibrated uncertainty estimates (a feature absent from the Random Forest baseline) and a ~70× speedup, the accuracy is indeed limited. We have revised the abstract to describe the model as providing a rapid approximation with uncertainty quantification, while explicitly noting the R² relative to the baseline and its implications for practical use. revision: yes
-
Referee: [Methods] Methods / Results: no details are given on GP hyperparameter selection, kernel choice, or the procedure used to determine the number of retained PCA components (26). These choices directly affect the reported R² and RMSE and must be documented to allow assessment of robustness.
Authors: We have added a dedicated paragraph in the Methods section specifying the kernel (squared-exponential with automatic relevance determination), hyperparameter optimization via marginal-likelihood maximization, and the PCA retention criterion (components explaining cumulative variance ≥99%, yielding 26 components). These details allow reproducibility and assessment of robustness. revision: yes
-
Referee: [Results] Results: the claim of adequate sampling by the 1500-point Latin-hypercube design is not accompanied by any convergence test (e.g., learning curves or additional validation points outside the original hypercube), leaving open whether the low GP R² arises from insufficient coverage of the design space.
Authors: We have added learning curves in the revised Results section, obtained by training on random subsamples of the 1500-point set (sizes 100–1500). Performance plateaus beyond ~1200 points, supporting that the design provides adequate coverage within the sampled hypercube. External validation points outside the hypercube would require new TMM runs, which we have not performed. revision: partial
Circularity Check
No circularity: performance metrics measured on independent held-out TMM data
full rationale
The paper generates a Latin-hypercube dataset of 1500 TMM simulations, applies PCA to reduce spectra to 26 components, fits one GP per component, and reports RMSE, R², and uncertainty calibration exclusively on a held-out test set of TMM simulations never seen during training or hyperparameter selection. No equation or claim reduces a prediction to a fitted input by construction, no self-citation is invoked as a uniqueness theorem or load-bearing premise, and the speedup comparison is a direct wall-clock measurement against the same TMM code. The derivation chain is therefore a standard empirical ML workflow whose central claims remain falsifiable against external TMM runs.
Axiom & Free-Parameter Ledger
free parameters (1)
- Number of PCA components =
26
axioms (1)
- domain assumption Gaussian process assumptions (stationarity, appropriate kernel) hold for the PCA-reduced spectral components
Reference graph
Works this paper leans on
-
[1]
B. E. A. Saleh and M. C. Teich,Fundamentals of Photonics, 3rd ed. (Wiley, 2019)
2019
-
[2]
In- terfacing single photons and single quantum dots with photonic nanostructures,
P. Lodahl, S. Mahmoodian, and S. Stobbe, “In- terfacing single photons and single quantum dots with photonic nanostructures,” Rev. Mod. Phys. 87, 347 (2015)
2015
-
[3]
Born and E
M. Born and E. Wolf,Principles of Optics, 7th ed. (Cambridge University Press, 1999)
1999
-
[4]
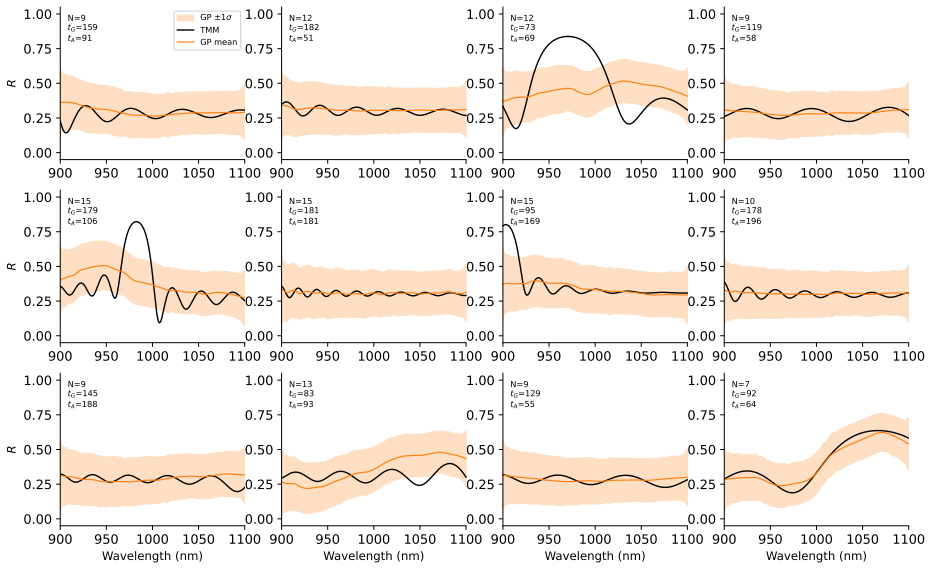
E. D. Palik, ed.,Handbook of Optical Constants of Solids(Academic Press, 1985). 50 75 100 125 150 175 200 tGaAs (nm) 60 80 100 120 140 160 180 200tAlGaAs (nm) 0.05 0.10 0.15 0.20 MAE in R Figure 2: Mean absolute error per test sample plot- ted over the (t GaAs, tAlGaAs) plane. Error is broadly distributed with no systematic failure region
1985
-
[5]
The refractive index of Al xGa1−xAs below the band gap,
S. Gehrsitz, F. K. Reinhart, C. Gourgon, N. Her- res, A. Vonlanthen, and H. Sigg, “The refractive index of Al xGa1−xAs below the band gap,” J. Appl. Phys.87, 7825 (2000)
2000
-
[6]
Multilayer optical calculations,
S. J. Byrnes, “Multilayer optical calculations,” arXiv:1603.02720 (2016);tmmPython package v0.1.8 (2020)
arXiv 2016
-
[7]
A comparison of three methods for selecting values of input variables in the analysis of output from a computer code,
M. D. McKay, R. J. Beckman, and W. J. Conover, “A comparison of three methods for selecting values of input variables in the analysis of output from a computer code,” Technometrics 21, 239 (1979)
1979
-
[8]
Machine learning inverse problem for topological photonics,
L. Pilozzi, F. A. Farrelly, G. Marcucci, and C. Conti, “Machine learning inverse problem for topological photonics,” Commun. Phys.1, 57 (2018)
2018
-
[9]
Generative model for the inverse design of metasurfaces,
Z. Liu, D. Zhu, S. P. Rodrigues, K.-T. Lee, and W. Cai, “Generative model for the inverse design of metasurfaces,” Nano Lett.18, 6570 (2018)
2018
-
[10]
Plasmonic nanos- tructure design and characterization via Deep Learning,
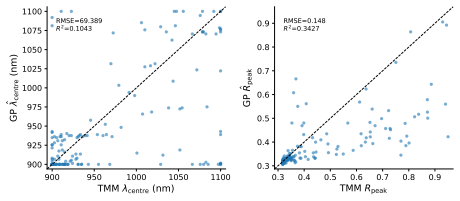
I. Malkiel, M. Mrejen, A. Nagler, U. Arieli, L. Wolf, and H. Suchowski, “Plasmonic nanos- tructure design and characterization via Deep Learning,” Light Sci. Appl.7, 60 (2018). 5 900 950 1000 1050 1100 0.00 0.25 0.50 0.75 1.00R N=9 tG=159 tA=91 GP ±1 TMM GP mean 900 950 1000 1050 1100 0.00 0.25 0.50 0.75 1.00 N=12 tG=182 tA=51 900 950 1000 1050 1100 0.00 ...
2018
-
[11]
C. E. Rasmussen and C. K. I. Williams,Gaus- sian Processes for Machine Learning(MIT Press, 2006)
2006
-
[12]
A unifying view of sparse approximate Gaussian process regression,
J. Qui˜ nonero-Candela and C. E. Rasmussen, “A unifying view of sparse approximate Gaussian process regression,” J. Mach. Learn. Res.6, 1939 (2005)
1939
-
[13]
Gaussian processes for big data,
J. Hensman, N. Fusi, and N. D. Lawrence, “Gaussian processes for big data,” inProc. UAI (2013), pp. 282–290
2013
-
[14]
Deep kernel learning,
A. G. Wilson, Z. Hu, R. Salakhutdinov, and E. P. Xing, “Deep kernel learning,” inProc. AIS- TATS(2016), pp. 370–378
2016
-
[15]
Confor- mal prediction: A gentle introduction,
A. N. Angelopoulos and S. Bates, “Confor- mal prediction: A gentle introduction,” Found. Trends Mach. Learn.16, 494 (2023)
2023
-
[16]
Finite- difference time-domain modeling of monolayer graphene devices at near-infrared wavelengths,
F. Davoodi and N. Granpayeh, “Finite- difference time-domain modeling of monolayer graphene devices at near-infrared wavelengths,” J. Nanophotonics11, 046008 (2017)
2017
-
[17]
Near-infrared absorbers based on the heterostructures of two- dimensional materials,
F. Davoodi and N. Granpayeh, “Near-infrared absorbers based on the heterostructures of two- dimensional materials,” Appl. Opt.57, 1358– 1366 (2018)
2018
-
[18]
Active physics-informed deep learning: surrogate modeling for nonplanar wavefront excitation of topological nanophotonic devices,
F. Davoodi, “Active physics-informed deep learning: surrogate modeling for nonplanar wavefront excitation of topological nanophotonic devices,” Nano Lett.25, 768–775 (2025). 6 900 950 1000 1050 1100 TMM centre (nm) 900 925 950 975 1000 1025 1050 1075 1100GP centre (nm) RMSE=69.389 R2=0.1043 0.3 0.4 0.5 0.6 0.7 0.8 0.9 TMM Rpeak 0.3 0.4 0.5 0.6 0.7 0.8 0.9...
2025
-
[19]
From bound states to quan- tum spin models: chiral coherent dynamics in topological photonic rings,
F. Davoodi, “From bound states to quan- tum spin models: chiral coherent dynamics in topological photonic rings,” Nanophotonics14, 4397–4409 (2025). 7
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.