Self-Guidance: Enhancing Neural Codecs via Decoder Manifold Alignment
Pith reviewed 2026-06-27 06:03 UTC · model grok-4.3
The pith
Aligning decoder manifolds between quantized tokens and continuous embeddings via a feature-mapping loss boosts neural codec fidelity and enables 4x codebook reduction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
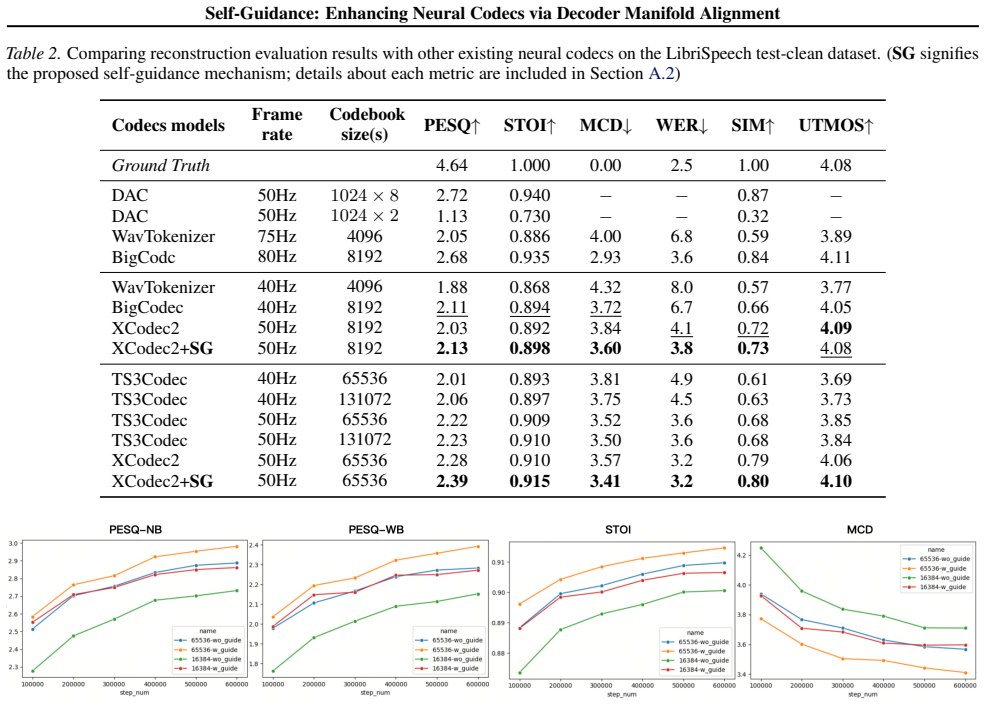
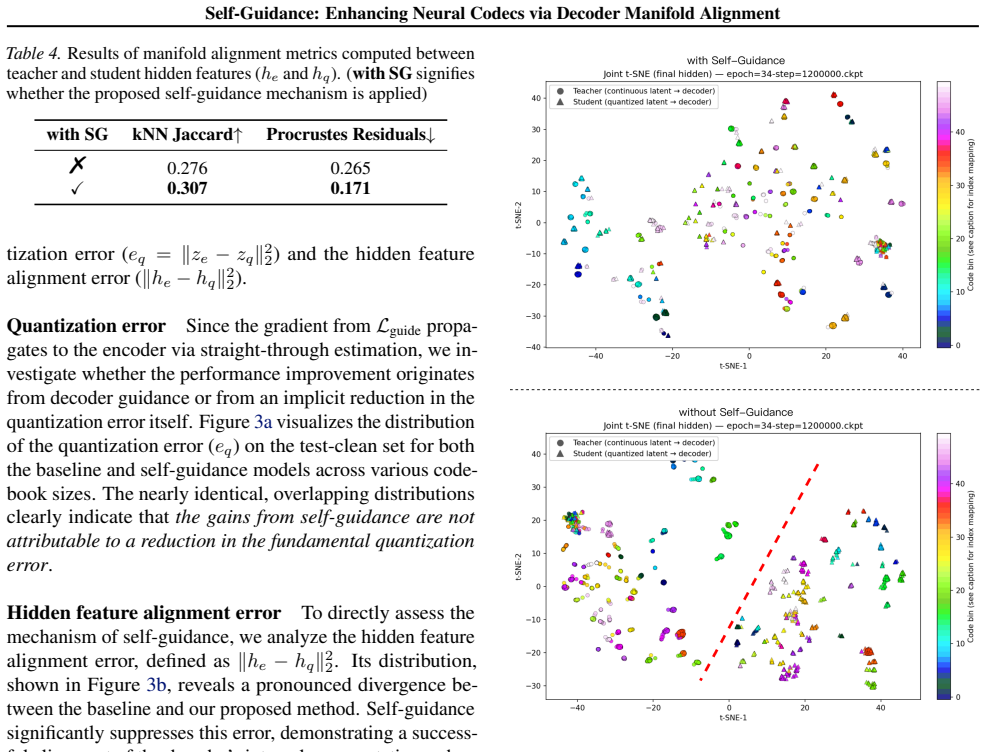
Self-guidance aligns the decoder's internal feature manifolds for quantized tokens and continuous embeddings using a feature-mapping loss, resulting in improved reconstruction metrics on XCodec2, state-of-the-art low-bitrate performance, and the ability to reduce the codebook size by 4x without fidelity loss, which in turn enhances LLM-based synthesis by simplifying the token space. Multiple statistical observations and visualizations corroborate the enhanced internal manifold alignment, and the method generalizes across various inductive biases.
What carries the argument
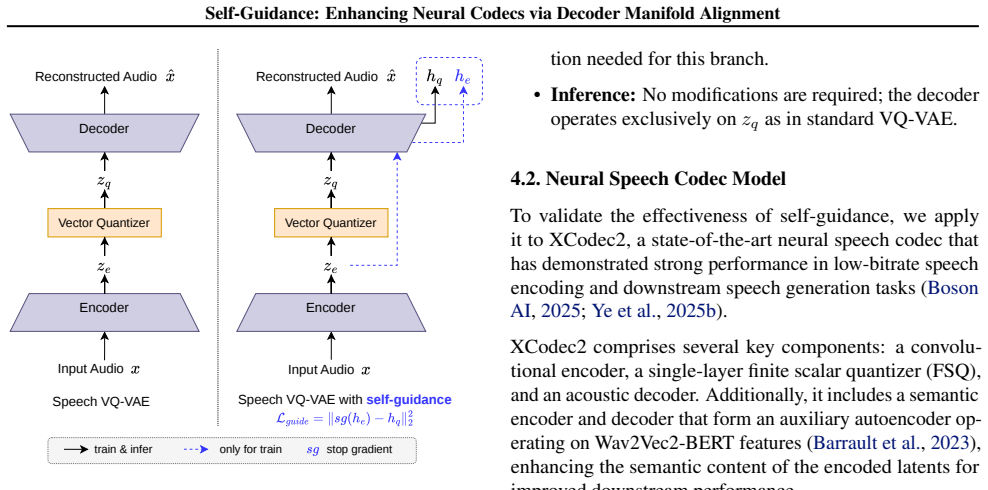
Self-guidance via a lightweight feature-mapping loss that aligns decoder feature manifolds between quantized tokens and original continuous embeddings.
If this is right
- All standard reconstruction metrics improve when self-guidance is added to the base codec.
- State-of-the-art performance is reached at low bitrates.
- The codebook can be reduced by a factor of four with no loss in fidelity.
- Downstream LLM-based TTS synthesis improves because the token modeling space becomes simpler.
- The alignment effect holds across models with different inductive biases.
Where Pith is reading between the lines
- The smaller discrete codebook may reduce the search space or perplexity faced by the language model during autoregressive generation.
- The same manifold-alignment loss could be tested on image or video codecs that also rely on vector quantization.
- If alignment is the active ingredient, the loss might be combined with existing regularization terms to further trade model size for performance.
Load-bearing premise
The measured gains in reconstruction metrics and downstream TTS performance are produced by the manifold alignment itself rather than by other unstated details of training or data.
What would settle it
An ablation that removes the feature-mapping loss or replaces it with a non-aligning objective and then checks whether the reported reconstruction improvements and 4x codebook reduction both disappear.
Figures

read the original abstract
Neural speech codecs based on Vector-Quantized VAEs (VQ-VAEs) are core audio tokenizers for speech LLMs, yet their reconstruction fidelity is bottlenecked by quantization error. Modifying the quantizer or increasing model capacity are common fixes, but they complicate downstream language modeling. Our core idea is to align the decoder's internal feature manifolds when processing both the quantized tokens and their original continuous embeddings, using a lightweight feature-mapping loss. This requires minimal training overhead and no inference-time changes. Applied to XCodec2, self-guidance improves all reconstruction metrics, achieving state-of-the-art low-bitrate performance. Notably, it enables a 4x codebook reduction without fidelity loss, which downstream TTS experiments show significantly improves LLM-based synthesis by simplifying the token modeling space. Multiple statistical observations and visualizations corroborate the enhanced internal manifold alignment in the decoder. Extensive experiments confirm its generality across various inductive biases. Self-guidance thus establishes an efficient, broadly applicable method for high-fidelity neural audio coding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes 'self-guidance,' a training objective that adds a lightweight feature-mapping loss to align decoder internal feature manifolds when processing quantized tokens versus their original continuous embeddings in VQ-VAE neural speech codecs. Applied to XCodec2, the method is reported to improve all reconstruction metrics to achieve state-of-the-art low-bitrate performance, enable a 4x codebook reduction without fidelity loss, and yield significant gains in downstream LLM-based TTS synthesis by simplifying the token space. Visualizations and statistical observations are presented as corroboration of enhanced manifold alignment, with claims of generality across inductive biases and no inference-time overhead.
Significance. If the reported gains are causally due to the manifold-alignment loss rather than training confounders, the approach offers an efficient, inference-free route to higher-fidelity neural audio codecs and simpler token modeling for speech LLMs, with potential broad applicability.
major comments (2)
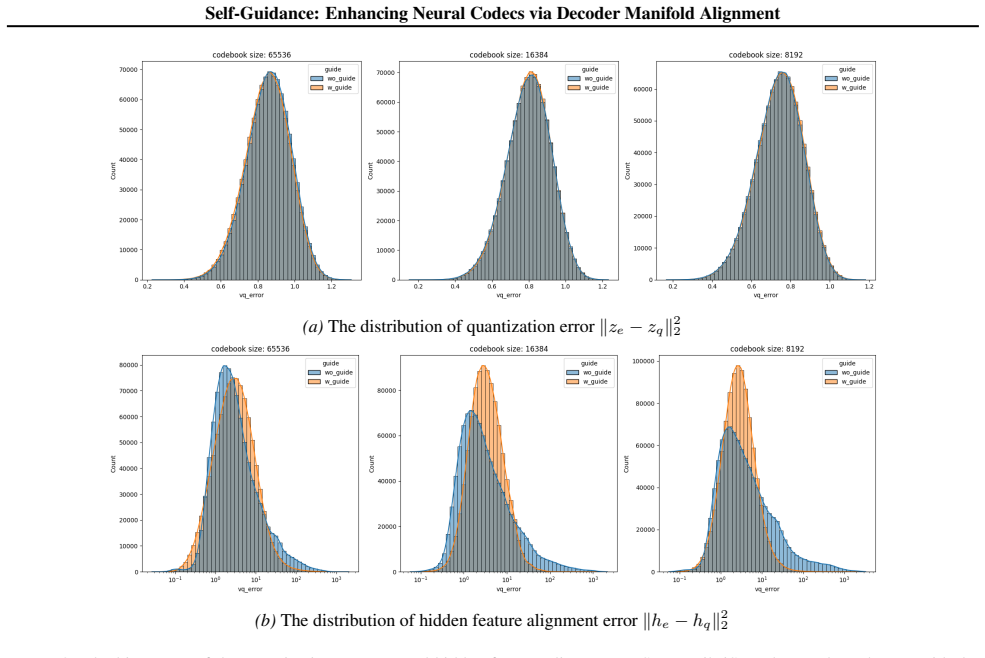
- [Experiments] The central claim that the feature-mapping loss drives the reconstruction improvements, 4x codebook reduction, and TTS gains requires that its effect be isolated. No ablation is described that holds all other training details (optimizer schedule, total steps, data order, regularization, random seed) fixed while adding or removing only the self-guidance term; without this, attribution to manifold alignment remains unverified.
- [Method] §3 (method) and the abstract assert that the loss aligns decoder manifolds on quantized vs. continuous embeddings, yet no equation or pseudocode is supplied showing the precise form of the feature-mapping loss or how it is balanced against the standard VQ-VAE objective; this prevents verification that the loss is independent of the final metrics.
minor comments (1)
- [Abstract] The abstract asserts metric improvements and codebook reduction but supplies no equations, ablation details, or error analysis; cannot verify whether the loss term actually drives the claimed effects.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below and will revise the manuscript to incorporate the requested clarifications and experiments.
read point-by-point responses
-
Referee: [Experiments] The central claim that the feature-mapping loss drives the reconstruction improvements, 4x codebook reduction, and TTS gains requires that its effect be isolated. No ablation is described that holds all other training details (optimizer schedule, total steps, data order, regularization, random seed) fixed while adding or removing only the self-guidance term; without this, attribution to manifold alignment remains unverified.
Authors: We agree that a controlled ablation isolating only the self-guidance term is required to substantiate the causal claims. In the revision we will add such an experiment, keeping optimizer, schedule, total steps, data order, regularization, and random seed fixed while toggling only the feature-mapping loss. This will directly verify attribution to manifold alignment. revision: yes
-
Referee: [Method] §3 (method) and the abstract assert that the loss aligns decoder manifolds on quantized vs. continuous embeddings, yet no equation or pseudocode is supplied showing the precise form of the feature-mapping loss or how it is balanced against the standard VQ-VAE objective; this prevents verification that the loss is independent of the final metrics.
Authors: We acknowledge that the explicit equation and balancing details for the feature-mapping loss were omitted from §3. The revised manuscript will include the precise mathematical form of the loss, its weighting coefficient relative to the VQ-VAE objective, and (space permitting) pseudocode, allowing independent verification that the term is independent of the reported metrics. revision: yes
Circularity Check
No circularity: independent additive loss with empirical results
full rationale
The paper proposes a new feature-mapping loss term to align decoder manifolds between quantized and continuous embeddings. This is an additive training objective whose effect on reconstruction metrics is measured empirically after training. No equations reduce a claimed prediction to the loss definition by construction, no fitted parameters are relabeled as predictions, and no load-bearing claims rest on self-citations or uniqueness theorems imported from prior author work. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Frontiers in systems neuroscience , volume=
Representational similarity analysis-connecting the branches of systems neuroscience , author=. Frontiers in systems neuroscience , volume=. 2008 , publisher=
2008
-
[2]
, author=
Visualizing data using t-SNE. , author=. Journal of machine learning research , volume=
-
[3]
International Conference on Machine Learning , pages=
Functional neural networks: Shift invariant models for functional data with applications to EEG classification , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[4]
Advances in neural information processing systems , volume=
Generalized shape metrics on neural representations , author=. Advances in neural information processing systems , volume=
-
[5]
International conference on machine learning , pages=
Similarity of neural network representations revisited , author=. International conference on machine learning , pages=. 2019 , organization=
2019
-
[6]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Be your own teacher: Improve the performance of convolutional neural networks via self distillation , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[7]
International conference on machine learning , pages=
Born again neural networks , author=. International conference on machine learning , pages=. 2018 , organization=
2018
-
[8]
Advances in Neural Information Processing Systems , volume=
Self-distillation amplifies regularization in hilbert space , author=. Advances in Neural Information Processing Systems , volume=
-
[9]
IEEE/ACM Transactions on Audio, Speech, and Language Processing , volume=
Latent-domain predictive neural speech coding , author=. IEEE/ACM Transactions on Audio, Speech, and Language Processing , volume=. 2023 , publisher=
2023
-
[10]
CoRR , volume=
Dongchao Yang and Songxiang Liu and Rongjie Huang and Jinchuan Tian and Chao Weng and Yuexian Zou , title=. CoRR , volume=. 2023 , cdate=
2023
-
[11]
Audio Imagination: NeurIPS 2024 Workshop AI-Driven Speech, Music, and Sound Generation , year=
Closer Look at Neural Codec Resynthesis: Bridging the Gap between Codec and Waveform Generation , author=. Audio Imagination: NeurIPS 2024 Workshop AI-Driven Speech, Music, and Sound Generation , year=
2024
-
[12]
IEEE transactions on information theory , volume=
Least squares quantization in PCM , author=. IEEE transactions on information theory , volume=. 1982 , publisher=
1982
-
[13]
Advances in Neural Information Processing Systems , volume=
Neural networks fail to learn periodic functions and how to fix it , author=. Advances in Neural Information Processing Systems , volume=
-
[15]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Codec does matter: Exploring the semantic shortcoming of codec for audio language model , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[16]
2015 IEEE international conference on acoustics, speech and signal processing (ICASSP) , pages=
Librispeech: an asr corpus based on public domain audio books , author=. 2015 IEEE international conference on acoustics, speech and signal processing (ICASSP) , pages=. 2015 , organization=
2015
-
[17]
arXiv preprint arXiv:1904.02882 , year=
Libritts: A corpus derived from librispeech for text-to-speech , author=. arXiv preprint arXiv:1904.02882 , year=
Pith/arXiv arXiv 1904
-
[19]
ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Libri-light: A benchmark for asr with limited or no supervision , author=. ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2020 , organization=
2020
-
[20]
IEEE Transactions on audio, speech, and language processing , volume=
An algorithm for intelligibility prediction of time--frequency weighted noisy speech , author=. IEEE Transactions on audio, speech, and language processing , volume=. 2011 , publisher=
2011
-
[21]
2001 IEEE international conference on acoustics, speech, and signal processing
Perceptual evaluation of speech quality (PESQ)-a new method for speech quality assessment of telephone networks and codecs , author=. 2001 IEEE international conference on acoustics, speech, and signal processing. Proceedings (Cat. No. 01CH37221) , volume=. 2001 , organization=
2001
-
[23]
Advances in neural information processing systems , volume=
Hifi-gan: Generative adversarial networks for efficient and high fidelity speech synthesis , author=. Advances in neural information processing systems , volume=
-
[24]
Proceedings of the IEEE international conference on computer vision , pages=
Least squares generative adversarial networks , author=. Proceedings of the IEEE international conference on computer vision , pages=
-
[25]
2006 , institution=
k-means++: The advantages of careful seeding , author=. 2006 , institution=
2006
-
[26]
TextMining Workshop at KDD2000 (May 2000) , pages=
A comparison of document clustering techniques , author=. TextMining Workshop at KDD2000 (May 2000) , pages=
2000
-
[28]
2024 , eprint=
Why Do Speech Language Models Fail to Generate Semantically Coherent Outputs? A Modality Evolving Perspective , author=. 2024 , eprint=
2024
-
[30]
2025 , eprint=
Qwen2.5 Technical Report , author=. 2025 , eprint=
2025
-
[31]
2025 , howpublished =
2025
-
[33]
The Twelfth International Conference on Learning Representations , year=
Vocos: Closing the gap between time-domain and Fourier-based neural vocoders for high-quality audio synthesis , author=. The Twelfth International Conference on Learning Representations , year=
-
[35]
Advances in neural information processing systems , volume=
Neural discrete representation learning , author=. Advances in neural information processing systems , volume=
-
[36]
IEEE/ACM transactions on audio, speech, and language processing , volume=
Audiolm: a language modeling approach to audio generation , author=. IEEE/ACM transactions on audio, speech, and language processing , volume=. 2023 , publisher=
2023
-
[37]
arXiv e-prints , pages=
The llama 3 herd of models , author=. arXiv e-prints , pages=
-
[38]
arXiv preprint arXiv:2306.12925 , year=
Audiopalm: A large language model that can speak and listen , author=. arXiv preprint arXiv:2306.12925 , year=
-
[40]
Advances in Neural Information Processing Systems , volume=
Simple and controllable music generation , author=. Advances in Neural Information Processing Systems , volume=
-
[43]
Advances in neural information processing systems , volume=
Visual autoregressive modeling: Scalable image generation via next-scale prediction , author=. Advances in neural information processing systems , volume=
-
[46]
Advances in neural information processing systems , volume=
Generating diverse high-fidelity images with vq-vae-2 , author=. Advances in neural information processing systems , volume=
-
[47]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Taming transformers for high-resolution image synthesis , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[48]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
High-resolution image synthesis with latent diffusion models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[49]
International conference on machine learning , pages=
Zero-shot text-to-image generation , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[50]
arXiv preprint arXiv:1611.01144 , year=
Categorical reparameterization with gumbel-softmax , author=. arXiv preprint arXiv:1611.01144 , year=
-
[51]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Regularized vector quantization for tokenized image synthesis , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[52]
International Conference on Machine Learning , pages=
Straightening out the straight-through estimator: Overcoming optimization challenges in vector quantized networks , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[56]
IEEE/ACM Transactions on Audio, Speech, and Language Processing , volume=
Soundstream: An end-to-end neural audio codec , author=. IEEE/ACM Transactions on Audio, Speech, and Language Processing , volume=. 2021 , publisher=
2021
-
[57]
Advances in Neural Information Processing Systems , volume=
High-fidelity audio compression with improved rvqgan , author=. Advances in Neural Information Processing Systems , volume=
-
[58]
arXiv preprint arXiv:2305.02765 , year=
Hifi-codec: Group-residual vector quantization for high fidelity audio codec , author=. arXiv preprint arXiv:2305.02765 , year=
-
[59]
ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Fewer-token neural speech codec with time-invariant codes , author=. ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2024 , organization=
2024
-
[60]
IEEE/ACM Transactions on Audio, Speech, and Language Processing , year=
APCodec: A neural audio codec with parallel amplitude and phase spectrum encoding and decoding , author=. IEEE/ACM Transactions on Audio, Speech, and Language Processing , year=
-
[62]
arXiv preprint arXiv:2406.02328 , year=
Simplespeech: Towards simple and efficient text-to-speech with scalar latent transformer diffusion models , author=. arXiv preprint arXiv:2406.02328 , year=
-
[63]
arXiv preprint arXiv:2407.15835 , year=
dmel: Speech tokenization made simple , author=. arXiv preprint arXiv:2407.15835 , year=
-
[64]
ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Scoredec: A phase-preserving high-fidelity audio codec with a generalized score-based diffusion post-filter , author=. ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2024 , organization=
2024
-
[65]
ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Generative de-quantization for neural speech codec via latent diffusion , author=. ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2024 , organization=
2024
-
[66]
ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
FlowMAC: Conditional flow matching for audio coding at low bit rates , author=. ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2025 , organization=
2025
-
[67]
arXiv preprint arXiv:2410.14411 , year=
Snac: Multi-scale neural audio codec , author=. arXiv preprint arXiv:2410.14411 , year=
-
[68]
arXiv preprint arXiv:2408.09027 , year=
Efficient autoregressive audio modeling via next-scale prediction , author=. arXiv preprint arXiv:2408.09027 , year=
-
[74]
Advances in neural information processing systems , volume=
wav2vec 2.0: A framework for self-supervised learning of speech representations , author=. Advances in neural information processing systems , volume=
-
[75]
arXiv preprint arXiv:2104.00355 , year=
Speech resynthesis from discrete disentangled self-supervised representations , author=. arXiv preprint arXiv:2104.00355 , year=
-
[76]
ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
SELM: Speech enhancement using discrete tokens and language models , author=. ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2024 , organization=
2024
-
[77]
arXiv preprint arXiv:2406.10735 , year=
How should we extract discrete audio tokens from self-supervised models? , author=. arXiv preprint arXiv:2406.10735 , year=
-
[78]
arXiv preprint arXiv:2406.09869 , year=
MMM: Multi-layer multi-residual multi-stream discrete speech representation from self-supervised learning model , author=. arXiv preprint arXiv:2406.09869 , year=
-
[79]
arXiv preprint arXiv:2309.00169 , year=
Repcodec: A speech representation codec for speech tokenization , author=. arXiv preprint arXiv:2309.00169 , year=
-
[80]
arXiv preprint arXiv:2406.11037 , year=
Nast: Noise aware speech tokenization for speech language models , author=. arXiv preprint arXiv:2406.11037 , year=
-
[81]
arXiv preprint arXiv:2410.24177 , year=
DC-Spin: A Speaker-invariant Speech Tokenizer for Spoken Language Models , author=. arXiv preprint arXiv:2410.24177 , year=
-
[82]
arXiv preprint arXiv:2403.03100 , year=
Naturalspeech 3: Zero-shot speech synthesis with factorized codec and diffusion models , author=. arXiv preprint arXiv:2403.03100 , year=
-
[83]
IEEE Journal of Selected Topics in Signal Processing , year=
Universal Speech Token Learning Via Low-Bitrate Neural Codec and Pretrained Representations , author=. IEEE Journal of Selected Topics in Signal Processing , year=
-
[84]
arXiv preprint arXiv:2412.01053 , year=
FreeCodec: A disentangled neural speech codec with fewer tokens , author=. arXiv preprint arXiv:2412.01053 , year=
-
[85]
IEEE Journal of Selected Topics in Signal Processing , year=
Semanticodec: An ultra low bitrate semantic audio codec for general sound , author=. IEEE Journal of Selected Topics in Signal Processing , year=
-
[86]
arXiv preprint arXiv:2308.16692 , year=
Speechtokenizer: Unified speech tokenizer for speech large language models , author=. arXiv preprint arXiv:2308.16692 , year=
-
[87]
IEEE/ACM transactions on audio, speech, and language processing , volume=
Hubert: Self-supervised speech representation learning by masked prediction of hidden units , author=. IEEE/ACM transactions on audio, speech, and language processing , volume=. 2021 , publisher=
2021
-
[88]
IEEE Journal of Selected Topics in Signal Processing , volume=
Wavlm: Large-scale self-supervised pre-training for full stack speech processing , author=. IEEE Journal of Selected Topics in Signal Processing , volume=. 2022 , publisher=
2022
-
[90]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[91]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
-
[92]
2016 , publisher=
Deep learning , author=. 2016 , publisher=
2016
-
[93]
Barrault, L., Chung, Y.-A., Meglioli, M. C., Dale, D., Dong, N., Duppenthaler, M., Duquenne, P.-A., Ellis, B., Elsahar, H., Haaheim, J., et al. Seamless: Multilingual expressive and streaming speech translation. arXiv preprint arXiv:2312.05187, 2023
arXiv 2023
-
[94]
Higgs Audio V2: Redefining Expressiveness in Audio Generation
Boson AI . Higgs Audio V2: Redefining Expressiveness in Audio Generation . https://github.com/boson-ai/higgs-audio, 2025. GitHub repository. Release blog available at https://www.boson.ai/blog/higgs-audio-v2
2025
-
[95]
Wavlm: Large-scale self-supervised pre-training for full stack speech processing
Chen, S., Wang, C., Chen, Z., Wu, Y., Liu, S., Chen, Z., Li, J., Kanda, N., Yoshioka, T., Xiao, X., et al. Wavlm: Large-scale self-supervised pre-training for full stack speech processing. IEEE Journal of Selected Topics in Signal Processing, 16 0 (6): 0 1505--1518, 2022
2022
-
[96]
High fidelity neural audio compression
D \'e fossez, A., Copet, J., Synnaeve, G., and Adi, Y. High fidelity neural audio compression. arXiv preprint arXiv:2210.13438, 2022
Pith/arXiv arXiv 2022
-
[97]
Moshi: a speech-text foundation model for real-time dialogue
D \'e fossez, A., Mazar \'e , L., Orsini, M., Royer, A., P \'e rez, P., J \'e gou, H., Grave, E., and Zeghidour, N. Moshi: a speech-text foundation model for real-time dialogue. arXiv preprint arXiv:2410.00037, 2024
Pith/arXiv arXiv 2024
-
[98]
Focalcodec: Low-bitrate speech coding via focal modulation networks
Della Libera, L., Paissan, F., Subakan, C., and Ravanelli, M. Focalcodec: Low-bitrate speech coding via focal modulation networks. arXiv preprint arXiv:2502.04465, 2025
arXiv 2025
-
[99]
The llama 3 herd of models
Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Yang, A., Fan, A., et al. The llama 3 herd of models. arXiv e-prints, pp.\ arXiv--2407, 2024
2024
-
[100]
Taming transformers for high-resolution image synthesis
Esser, P., Rombach, R., and Ommer, B. Taming transformers for high-resolution image synthesis. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp.\ 12873--12883, 2021
2021
-
[101]
Born again neural networks
Furlanello, T., Lipton, Z., Tschannen, M., Itti, L., and Anandkumar, A. Born again neural networks. In International conference on machine learning, pp.\ 1607--1616. PMLR, 2018
2018
-
[102]
Lscodec: Low-bitrate and speaker-decoupled discrete speech codec
Guo, Y., Li, Z., Du, C., Wang, H., Chen, X., and Yu, K. Lscodec: Low-bitrate and speaker-decoupled discrete speech codec. arXiv preprint arXiv:2410.15764, 2024
arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.