LLM-Guided Planning for Multi-hop Reasoning over Multimodal Nuclear Regulatory Documents
Pith reviewed 2026-06-30 07:12 UTC · model grok-4.3
The pith
An LLM agent plans its next read of a nuclear regulatory document tree and reaches 81.5 percent accuracy on a 200-question benchmark.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that state-conditioned planning by an LLM agent over a document tree produces 81.5 percent accuracy and 0.93 RAGAS faithfulness on 200 questions drawn from NuScale Final Safety Analysis Report documents, with a 38-point gain over a non-planning baseline that uses the identical tree, and with outperformance of LightRAG, HippoRAG, and GraphRAG while matching RAPTOR without offline indexing.
What carries the argument
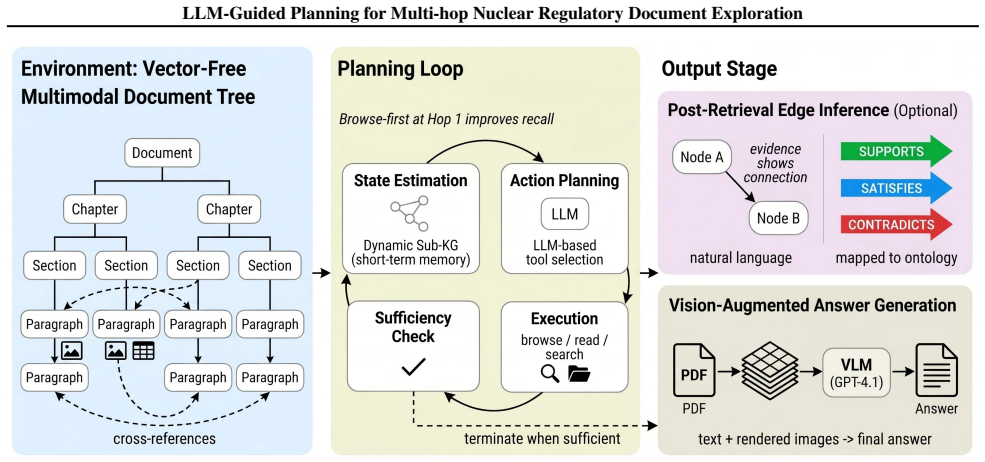
The LLM-based planning agent that selects the next tool action conditioned on its current dynamic knowledge graph state while operating over a vectorless document tree.
If this is right
- Removing state-conditioned action selection from the same document tree lowers accuracy from 81.5 percent to 43.5 percent.
- The planning agent matches or exceeds several graph-based retrieval systems without requiring an offline indexing stage.
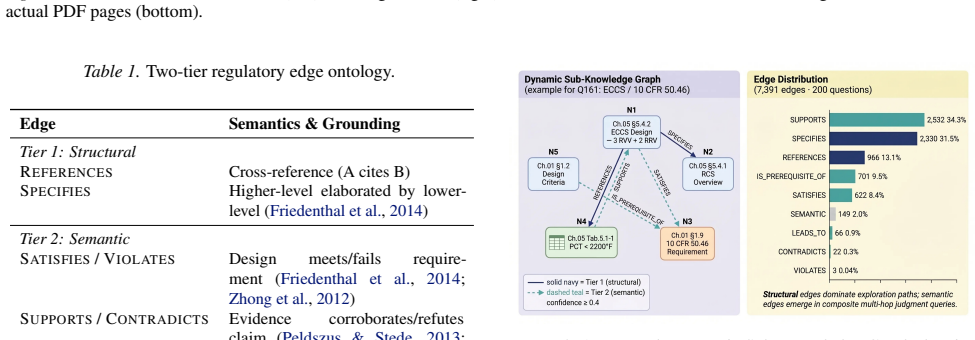
- Of 7,391 inferred knowledge-graph edges, only three (0.04 percent) are typed as scope-boundary violations and can serve as audit flags for human reviewers.
- Retaining the edge-inference module increases inference cost by 2.8 times but adds traceability without changing accuracy.
Where Pith is reading between the lines
- The same planning loop could be tested on other large structured document collections that require cross-section evidence assembly, such as legal codes or clinical trial reports.
- Replacing the static benchmark questions with queries that arise during an actual multi-week regulatory review would reveal whether the reported planning gain survives open-ended, evolving information needs.
- The low fraction of flagged edges suggests the knowledge graph stays mostly within document scope, but this property may vary with document tree depth or topic diversity.
Load-bearing premise
The 200-question benchmark over NuScale FSAR documents is a representative and unbiased proxy for the multi-hop reasoning demands that arise in actual nuclear regulatory review workflows.
What would settle it
Running the same agent on a fresh collection of regulatory documents or on questions generated from live reviewer workflows and measuring whether accuracy remains near 81.5 percent would settle whether the planning advantage holds outside the fixed benchmark.
Figures
read the original abstract
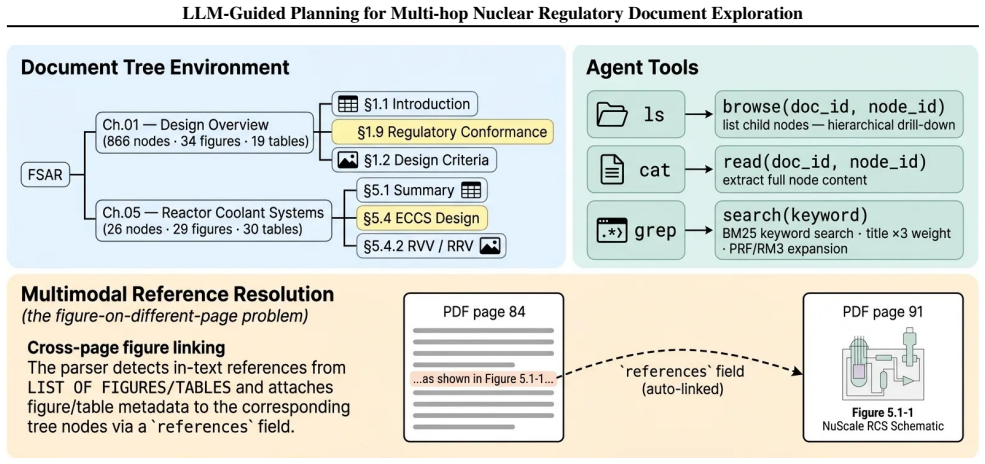
Reviewing nuclear regulatory documents requires multi-hop reasoning across tens of thousands of pages, where judgments depend on evidence assembled across multiple chapters. We frame this task as planning: an LLM-based agent observes the evidence collected so far, picks the next document fragment to inspect, and stops when the evidence is sufficient. The agent operates over a vectorless document tree using browse, read, and search tools, and maintains a dynamic knowledge graph (KG) as state. On a 200-question benchmark over NuScale Final Safety Analysis Report (FSAR) documents, the system reaches 81.5% accuracy with a RAGAS Faithfulness of 0.93. The dominant performance factor is planning: against PageIndex, which uses the same document tree without state-conditioned action selection, the gap is +38.0pp (43.5% to 81.5%, p<0.001). The system also outperforms LightRAG (73.0%, p<0.05), HippoRAG (70.5%, p<0.01), and GraphRAG (49.5%, p<0.001), and matches RAPTOR (75.5%, p=0.11) without offline indexing. Edge inference adds 2.8x cost without raising accuracy; we retain it as a traceability module. Of 7,391 inferred edges, 3 Violates edges (0.04%) flag scope boundaries (Q058) and partial conformance (Q176) as typed annotations that a human reviewer can audit.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper frames multi-hop reasoning over large nuclear regulatory documents (e.g., NuScale FSAR) as an LLM agent planning task. The agent uses browse/read/search tools over a vectorless document tree, maintains a dynamic knowledge graph as state, and decides when evidence is sufficient. On a 200-question benchmark it reports 81.5% accuracy (RAGAS Faithfulness 0.93), a +38pp gap over PageIndex (same tree, no state-conditioned planning), and outperformance versus LightRAG, HippoRAG, and GraphRAG.
Significance. If the 200-question benchmark is a valid proxy for regulatory review tasks, the work would provide useful empirical evidence that state-conditioned planning is the dominant factor in retrieval-augmented multi-hop reasoning over long structured documents. The inclusion of a dynamic KG for traceability (with explicit “Violates” edge annotations) and the cost/accuracy trade-off analysis for edge inference are concrete strengths that could inform auditability requirements in regulated domains.
major comments (3)
- [Experiments / Benchmark] Benchmark construction (Experiments section / §4 or equivalent): the manuscript supplies no description of how the 200 questions were sourced, authored, or expert-validated, nor any statistics on hop count distribution, chapter coverage, or alignment with typical regulatory review tasks such as cross-chapter conformance checks. This information is load-bearing for the central claim that the 81.5% accuracy and +38pp planning gap (p<0.001) generalize beyond the specific benchmark.
- [Experiments / Baselines] PageIndex baseline comparison (Experiments section): while the +38pp gap is presented as evidence that state-conditioned action selection is the key differentiator, the paper does not detail how PageIndex’s action selection differs from the proposed planner at the level of the observation and stopping criteria, making it difficult to isolate the contribution of the dynamic KG state.
- [Introduction / Discussion] Representativeness claim (Introduction / §1 and Discussion): the assertion that results on the NuScale FSAR benchmark demonstrate utility for “actual nuclear regulatory review workflows” is not supported by any mapping of the benchmark questions to real review artifacts or by any external validation; without this, the statistical significance of the accuracy numbers cannot be interpreted as evidence of practical impact.
minor comments (2)
- [Abstract] Abstract: the phrasing “3 Violates edges (0.04%)” is unclear; clarify whether this refers to three edges labeled “Violates” and what the parenthetical percentage is computed over.
- [Abstract / Results] The p=0.11 result versus RAPTOR is reported as “matches”; consider adding a brief note on whether this is interpreted as statistical equivalence or simply non-significance.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We address each major comment below. Where the manuscript is missing necessary details, we will revise to incorporate them; where clarification is needed, we provide it and will expand the text accordingly.
read point-by-point responses
-
Referee: [Experiments / Benchmark] Benchmark construction (Experiments section / §4 or equivalent): the manuscript supplies no description of how the 200 questions were sourced, authored, or expert-validated, nor any statistics on hop count distribution, chapter coverage, or alignment with typical regulatory review tasks such as cross-chapter conformance checks. This information is load-bearing for the central claim that the 81.5% accuracy and +38pp planning gap (p<0.001) generalize beyond the specific benchmark.
Authors: We agree this information is essential for interpreting the results. The current manuscript does not include these details. In the revised version we will add a dedicated subsection (new §4.1) that describes: (1) sourcing of the 200 questions from the NuScale FSAR by two nuclear-engineering domain experts; (2) the multi-stage authoring and validation protocol (initial drafting, independent review for factual accuracy and hop count, resolution of disagreements); (3) hop-count distribution (mean 3.2 hops, range 2–6); (4) chapter coverage statistics; and (5) explicit alignment with common regulatory tasks such as cross-chapter conformance checks. These additions will directly support the generalizability discussion. revision: yes
-
Referee: [Experiments / Baselines] PageIndex baseline comparison (Experiments section): while the +38pp gap is presented as evidence that state-conditioned action selection is the key differentiator, the paper does not detail how PageIndex’s action selection differs from the proposed planner at the level of the observation and stopping criteria, making it difficult to isolate the contribution of the dynamic KG state.
Authors: We accept that the current description is insufficient to isolate the contribution. PageIndex uses the identical document tree and tool set but (a) its observation is the raw retrieved fragments only, without the dynamic KG state summary, and (b) its stopping rule is a fixed step budget plus a simple relevance threshold rather than an evidence-sufficiency judgment conditioned on the KG. We will add a new comparison table (Table 3) and two paragraphs in §4.3 that explicitly contrast the observation spaces and stopping criteria, thereby clarifying that the performance gap is attributable to state-conditioned planning. revision: yes
-
Referee: [Introduction / Discussion] Representativeness claim (Introduction / §1 and Discussion): the assertion that results on the NuScale FSAR benchmark demonstrate utility for “actual nuclear regulatory review workflows” is not supported by any mapping of the benchmark questions to real review artifacts or by any external validation; without this, the statistical significance of the accuracy numbers cannot be interpreted as evidence of practical impact.
Authors: We agree the original wording overstates the direct applicability. The manuscript frames the benchmark as a proxy for regulatory review tasks but provides no mapping to real review artifacts or external validation. In the revision we will (1) replace the strong claim with a qualified statement that the results supply empirical evidence for state-conditioned planning on this proxy benchmark, (2) add an explicit limitations paragraph in the Discussion that notes the absence of real-world workflow mapping and external validation, and (3) retain the statistical significance only as evidence internal to the benchmark. This addresses the concern without misrepresenting the scope of the contribution. revision: partial
Circularity Check
No circularity: empirical benchmark results are direct measurements
full rationale
The paper presents accuracy (81.5%), faithfulness (0.93), and comparative gaps (+38pp over PageIndex) as direct empirical measurements on an external 200-question NuScale FSAR benchmark. No equations, fitted parameters renamed as predictions, self-definitional constructs, or load-bearing self-citations appear in the provided text. The planning mechanism and KG state are described as operational components evaluated against baselines on the same tree, without any reduction of the headline claims to inputs by construction. This is the most common honest finding for purely empirical system papers.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs can maintain a sufficiently accurate dynamic knowledge graph from tool outputs without systematic drift or hallucination
Reference graph
Works this paper leans on
-
[1]
NuclearQA: A human-made benchmark for language models for the nuclear domain
Acharya, A., Munikoti, S., Hellinger, A., Smith, S., Wagle, S., and Horawalavithana, S. NuclearQA: A human-made benchmark for language models for the nuclear domain. arXiv preprint arXiv:2310.10920,
-
[2]
APEX-Searcher: Refining Credit Assignment with Subgoaling for Agentic Retrieval-Augmented Generation
Chen, K., Kong, Q., Zhao, F., and Mao, W. APEX- Searcher: Augmenting LLMs’ search capabilities through agentic planning and execution.arXiv preprint arXiv:2603.13853,
work page internal anchor Pith review Pith/arXiv arXiv
- [3]
- [4]
-
[5]
From Local to Global: A Graph RAG Approach to Query-Focused Summarization
Edge, D., Trinh, H., Cheng, N., Bradley, J., Chao, A., Mody, A., Truitt, S., and Larson, J. From local to global: A Graph RAG approach to query-focused summarization. arXiv preprint arXiv:2404.16130,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Retrieval-Augmented Generation for Large Language Models: A Survey
Gao, Y ., Xiong, Y ., Gao, X., et al. Retrieval-augmented generation for large language models: A survey.arXiv preprint arXiv:2312.10997,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
LightRAG: Simple and Fast Retrieval-Augmented Generation
Guo, Z., Xia, L., Yu, Y ., Ao, T., and Huang, C. LightRAG: Simple and fast retrieval-augmented generation.arXiv preprint arXiv:2410.05779,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
J., Shu, Y ., Gu, Y ., Yasunaga, M., and Su, Y
Guti´errez, B. J., Shu, Y ., Gu, Y ., Yasunaga, M., and Su, Y . HippoRAG: Neurobiologically inspired long-term memory for large language models.arXiv preprint arXiv:2405.14831,
-
[9]
Jain, A., Meenachi, N. M., and Venkatraman, B. NukeBERT: A pre-trained language model for low resource nuclear domain.arXiv preprint arXiv:2003.13821,
- [10]
- [11]
- [12]
- [13]
-
[14]
Wang, S., Zhou, Y ., and Fang, Y . BookRAG: A hierarchi- cal structure-aware index-based approach for RAG on complex documents.arXiv preprint arXiv:2512.03413,
- [15]
-
[16]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
Zheng, L., Chiang, W.-L., Sheng, Y ., et al. Judging LLM-as- a-judge with MT-Bench and chatbot arena.arXiv preprint arXiv:2306.05685,
work page internal anchor Pith review Pith/arXiv arXiv
- [17]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.