Effective Dimension Governs Generalization in Quantum Kernel Vision Models
Pith reviewed 2026-06-26 18:03 UTC · model grok-4.3
The pith
The effective dimension of the quantum feature kernel explains why entanglement and noise both improve generalization in quantum vision models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
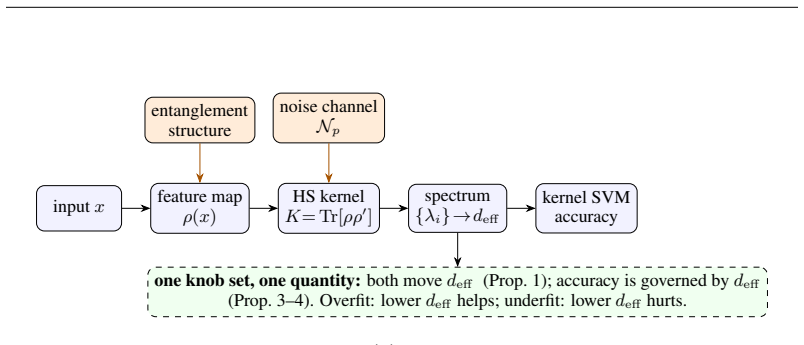
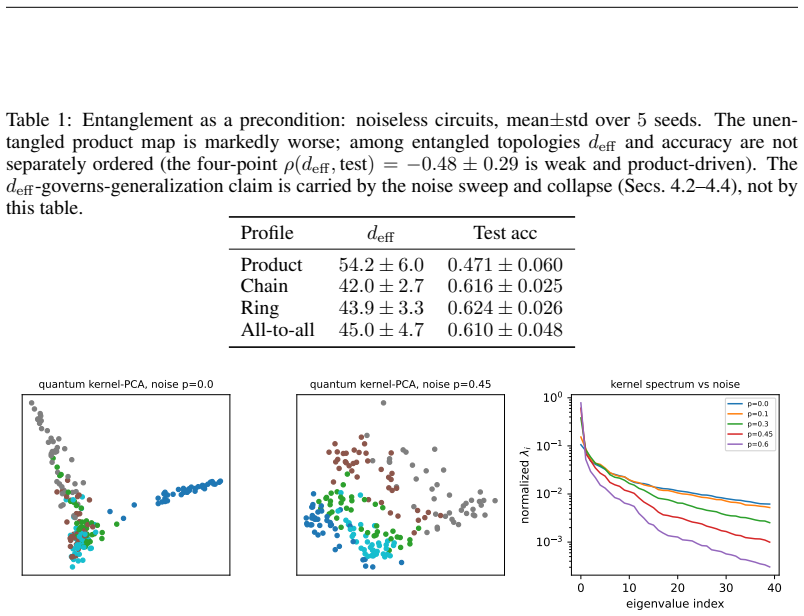
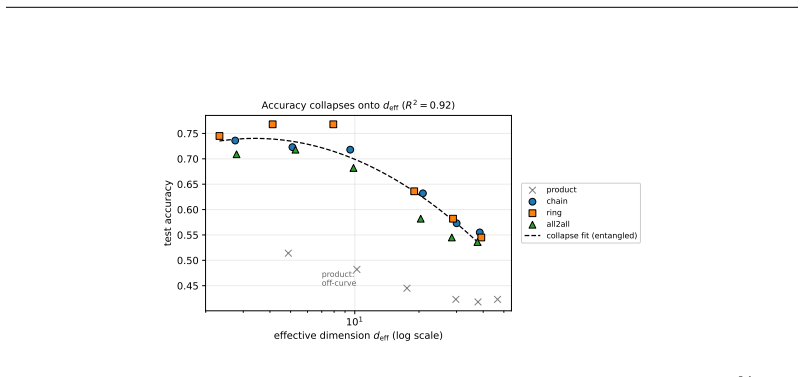
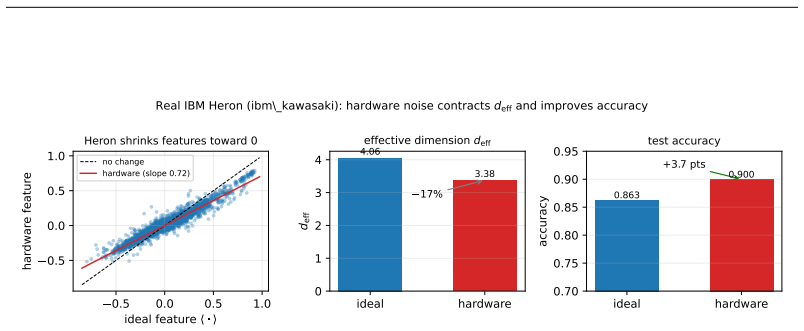
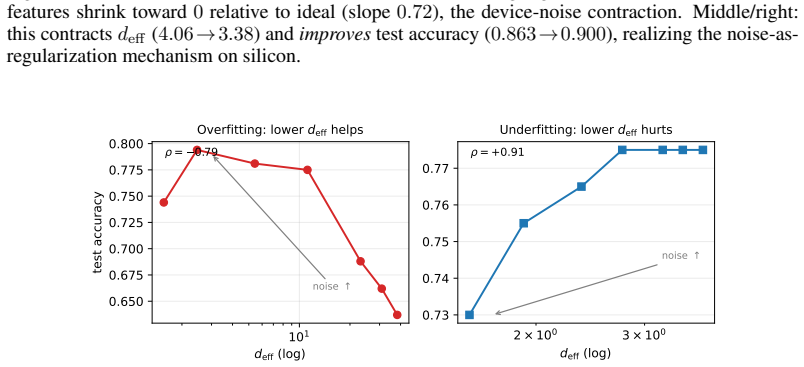
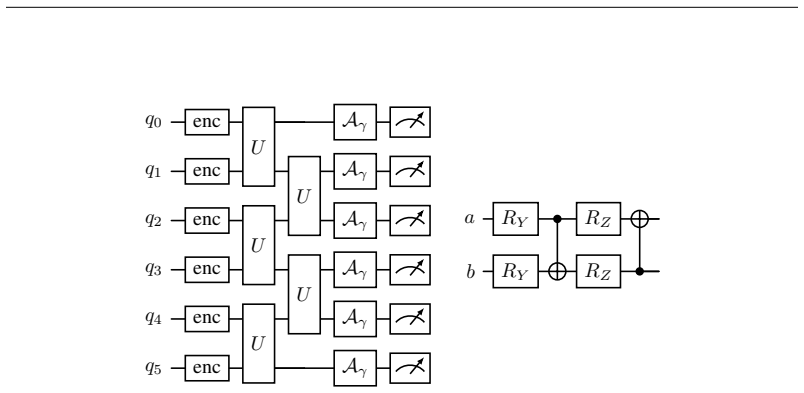
Both the benefit of entanglement structure and the benefit of quantum noise are manifestations of a single measurable quantity: the effective dimension d_eff of the (noise-shaped) quantum feature kernel. In an overfitting regime, contracting d_eff acts as ridge-like regularization. An exact decomposition of the depolarized kernel K_p = (1-p)^2 K + p(2-p)/D 1 1^T shows d_eff(K_p) approaches 1; amplitude damping contracts d_eff and lifts test accuracy by up to +13 percent along an inverted-U curve whose sign flips between over- and under-fitting regimes; a kernel-machine capacity bound and capacity/alignment risk decomposition complete the account.
What carries the argument
The effective dimension d_eff of the (noise-shaped) quantum feature kernel, which entanglement structure and quantum noise both move as control knobs.
If this is right
- Along the depolarizing channel the kernel admits an exact closed-form decomposition whose effective dimension collapses to 1 by construction.
- Amplitude damping produces a non-monotonic accuracy curve whose peak occurs at an intermediate noise level that matches an explicit spectral-filtering frontier.
- The sign of the noise effect reverses when the base model moves from overfitting to underfitting, confirming the regularization interpretation.
- A capacity bound derived from the kernel spectrum directly limits the risk gap once d_eff is known.
Where Pith is reading between the lines
- Designers could target a desired d_eff directly rather than searching over entanglement patterns or noise rates.
- The same spectral mechanism may apply to other kernel-based quantum models outside vision, provided they remain in the overfitting regime.
- If a general proof of monotone contraction under entanglement were found, the empirical verification step could be removed from future analyses.
Load-bearing premise
The models operate in an overfitting regime where contracting effective dimension improves generalization, and the observed monotone contraction of d_eff under entanglement extends beyond the tested cases.
What would settle it
A controlled experiment that varies entanglement or noise while holding measured d_eff fixed and still observes a change in test accuracy would falsify the claim that d_eff is the governing quantity.
Figures

read the original abstract
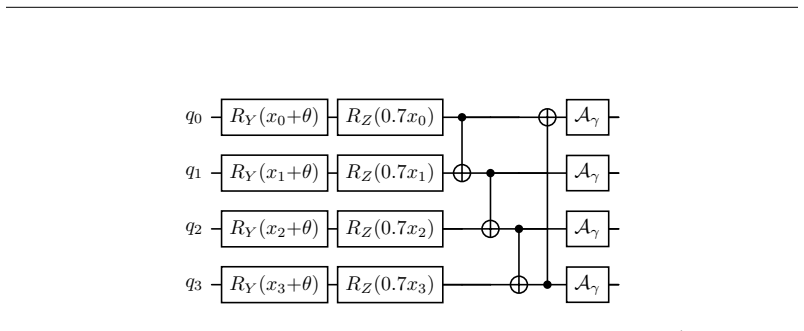
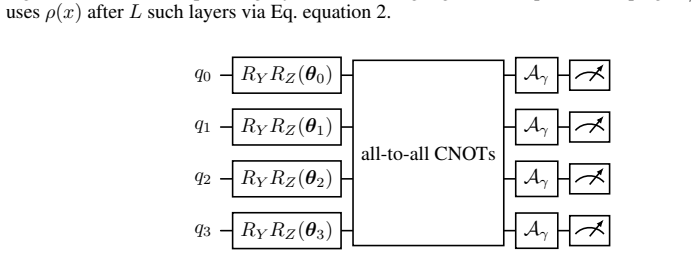
Recent quantum vision models-quantum vision transformers and quantum convolutional networks-report two striking but unexplained empirical phenomena: (i) ansatze with more, or more uniformly distributed, entanglement generalize better, and (ii) injecting quantum noise can improve test accuracy rather than degrade it. These observations are currently treated as curiosities, discovered by grid search and explained, if at all, by hand. We show that both are manifestations of a single, measurable quantity: the \emph{effective dimension} $d_{\rm eff}$ of the (noise-shaped) quantum feature kernel. Working primarily with quantum-kernel vision models-a quantum feature map read out by a kernel classifier-we give a spectral account in which entanglement structure and quantum noise are two knobs that move $d_{\rm eff}$; in an overfitting regime, contracting $d_{\rm eff}$ acts as ridge-like regularization. We analyze the mechanism: an \emph{exact} decomposition of the depolarized kernel $K_p=(1-p)^2K+\tfrac{p(2-p)}{D}\mathbf{1}\mathbf{1}^\top$ with $d_{\rm eff}(K_p)\to1$, a contraction result (and its boundary) for amplitude damping, a kernel-machine capacity bound, and a capacity/alignment risk decomposition; the monotone contraction operative in our entangled experiments is verified empirically, not proven in general. Along the one-parameter depolarizing family the collapse is instead exact by construction; we use it only to confirm the kernel decomposition to machine precision and at up to $12$ qubits, not as evidence for $d_{\rm eff}$. Amplitude damping contracts $d_{\rm eff}$ and lifts test accuracy by up to $+13\%$ along an inverted-U sweet spot; the effect's sign flips between the over- and under-fitting regimes; noise injection matches an explicit spectral-filtering frontier. Our results organize two reported anecdotes into a single measurable principle for designing quantum-vision models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that the effective dimension d_eff of the (noise-shaped) quantum feature kernel unifies two empirical phenomena in quantum vision models: (i) ansatze with more or more uniform entanglement generalize better, and (ii) certain quantum noise injections improve test accuracy. Both act by contracting d_eff, which provides ridge-like regularization in overfitting regimes. Support includes an exact decomposition of the depolarized kernel K_p = (1-p)^2 K + p(2-p)/D 1 1^T with d_eff(K_p) -> 1, a contraction result (with boundary) for amplitude damping, a kernel-machine capacity bound, a capacity/alignment risk decomposition, and empirical verification (not a general proof) of monotone d_eff contraction under the tested entangled ansatze. Experiments show noise lifting accuracy by up to +13% along an inverted-U, with sign flip between over- and under-fitting regimes.
Significance. If the central claim holds, the work converts two reported anecdotes into a single measurable spectral principle for ansatz and noise design in quantum-kernel vision models. Credit is given for the exact kernel decomposition (confirmed to machine precision at up to 12 qubits), the capacity bound, and the reproducible empirical contraction results along the depolarizing family.
major comments (1)
- [Abstract and entanglement-experiment section] Abstract and the entanglement-experiment section: the unification that both entanglement structure and noise act via d_eff contraction rests on the monotone contraction under entanglement being verified empirically rather than derived from a general spectral property; while the paper correctly scopes the claim to the tested ansatze, this makes the load-bearing mechanism dependent on the specific regimes and data rather than a derived property that would extend to the broader class of quantum-kernel vision models.
minor comments (2)
- Clarify in the main text how the overfitting regime is identified in each experiment (e.g., via training vs. test gap thresholds) so that the ridge-regularization interpretation can be directly checked against the reported accuracy curves.
- The capacity/alignment risk decomposition is central; ensure the precise statement of the bound (including any constants or assumptions on the feature map) is stated explicitly rather than referenced only in passing.
Simulated Author's Rebuttal
We thank the referee for the careful reading, the positive assessment of the exact kernel decomposition and capacity bound, and the recommendation for minor revision. We respond to the single major comment below.
read point-by-point responses
-
Referee: [Abstract and entanglement-experiment section] Abstract and the entanglement-experiment section: the unification that both entanglement structure and noise act via d_eff contraction rests on the monotone contraction under entanglement being verified empirically rather than derived from a general spectral property; while the paper correctly scopes the claim to the tested ansatze, this makes the load-bearing mechanism dependent on the specific regimes and data rather than a derived property that would extend to the broader class of quantum-kernel vision models.
Authors: We agree that the monotone contraction of d_eff under the entangled ansatze is verified empirically for the tested families rather than derived from a general spectral property. The manuscript already states this limitation explicitly in the abstract and main text: 'the monotone contraction operative in our entangled experiments is verified empirically, not proven in general.' The unification claim is therefore scoped to the quantum-kernel vision models, ansatze, and overfitting regimes studied, where both entanglement structure and noise are shown (via the exact depolarizing decomposition, amplitude-damping contraction, capacity bound, and empirical results) to contract d_eff and act as ridge-like regularization. While a general spectral theorem applicable to arbitrary ansatze would be desirable, the present work converts the two empirical phenomena into a single measurable quantity within the considered class. No further revision to the scoping language appears necessary. revision: no
Circularity Check
No significant circularity; explicit decompositions and stated empirical verification keep derivation self-contained
full rationale
The paper supplies an exact kernel decomposition K_p = (1-p)^2 K + p(2-p)/D 1 1^T with d_eff(K_p) -> 1 for the depolarizing channel (used only to verify the decomposition to machine precision, not as evidence for d_eff), a contraction result with boundary for amplitude damping, a kernel-machine capacity bound, and a capacity/alignment risk decomposition. It explicitly states that the monotone contraction of d_eff under entanglement 'is verified empirically, not proven in general.' No quoted step reduces a claimed prediction or uniqueness result to a fitted input, self-citation, or definitional equivalence. The unification of entanglement and noise effects under d_eff is therefore organized from these independent analyses plus experiments rather than forced by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Exact decomposition of the depolarized kernel K_p = (1-p)^2 K + p(2-p)/D 1 1^T
Reference graph
Works this paper leans on
-
[1]
Nature computational science , volume=
The power of quantum neural networks , author=. Nature computational science , volume=. 2021 , publisher=
2021
-
[2]
International Workshop on Efficient Medical Artificial Intelligence , pages=
From O (n 2) to O (n) parameters: Quantum self-attention in vision transformers for biomedical image classification , author=. International Workshop on Efficient Medical Artificial Intelligence , pages=. 2025 , organization=
2025
-
[3]
Quantum , volume=
Quantum vision transformers , author=. Quantum , volume=
-
[4]
Nature Physics , volume=
Quantum convolutional neural networks , author=. Nature Physics , volume=. 2019 , publisher=
2019
-
[5]
Advances in neural information processing systems , volume=
On kernel-target alignment , author=. Advances in neural information processing systems , volume=
-
[6]
Nature , volume=
Supervised learning with quantum-enhanced feature spaces , author=. Nature , volume=. 2019 , publisher=
2019
-
[7]
Nature communications , volume=
Power of data in quantum machine learning , author=. Nature communications , volume=. 2021 , publisher=
2021
-
[8]
Scientific Reports , volume=
Hybrid quantum-classical-quantum convolutional neural networks , author=. Scientific Reports , volume=. 2025 , publisher=
2025
-
[9]
arXiv preprint arXiv:2505.05957 , year=
Efficient quantum convolutional neural networks for image classification: Overcoming hardware constraints , author=. arXiv preprint arXiv:2505.05957 , year=
-
[10]
arXiv preprint arXiv:2101.11020 , year=
Supervised quantum machine learning models are kernel methods , author=. arXiv preprint arXiv:2101.11020 , year=
-
[11]
Physical review letters , volume=
Quantum machine learning in feature Hilbert spaces , author=. Physical review letters , volume=. 2019 , publisher=
2019
-
[12]
Quantum Information Processing , volume=
Quantum convolutional neural networks for multiclass image classification , author=. Quantum Information Processing , volume=. 2024 , publisher=
2024
-
[13]
Advanced Quantum Technologies , volume=
Expressibility and entangling capability of parameterized quantum circuits for hybrid quantum-classical algorithms , author=. Advanced Quantum Technologies , volume=. 2019 , publisher=
2019
-
[14]
arXiv preprint arXiv:2510.12291 , year=
Hybrid Vision Transformer and Quantum Convolutional Neural Network for Image Classification , author=. arXiv preprint arXiv:2510.12291 , year=
-
[15]
Hybrid quantum inception-inspired convolutional neural network for image classification: W. Wu, Y. Zhang , author=. The Journal of Supercomputing , volume=. 2025 , publisher=
2025
-
[16]
arXiv preprint arXiv:2504.02730 , year=
Hqvit: Hybrid quantum vision transformer for image classification , author=. arXiv preprint arXiv:2504.02730 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.