Mirror Descent Beyond Euclidean Stability: An Exponential Separation in Initialization Sensitivity
Pith reviewed 2026-06-27 13:48 UTC · model grok-4.3
The pith
Mirror descent with non-quadratic regularizers amplifies an initial perturbation exponentially over iterations, unlike gradient descent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
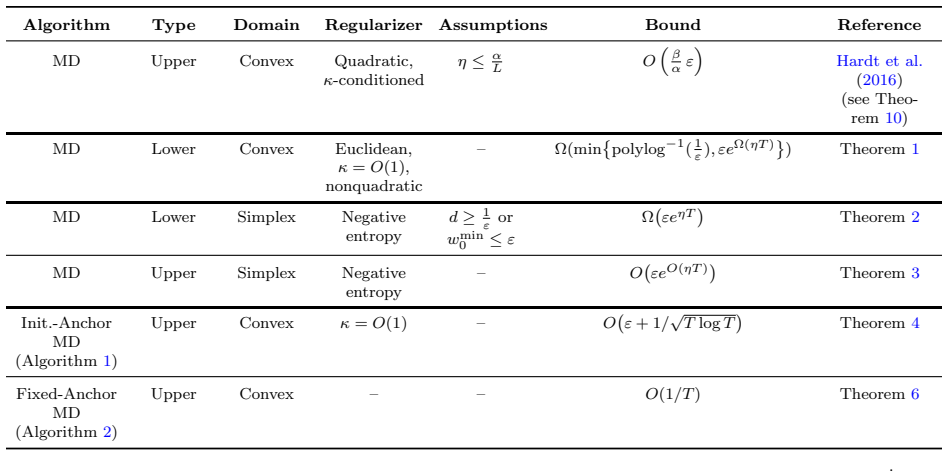
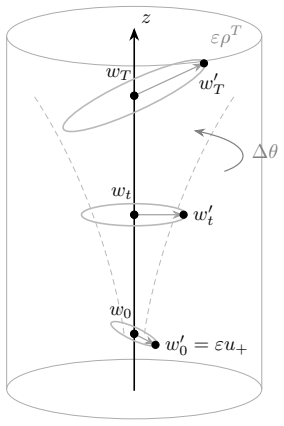
Once the regularizer is non-quadratic, mirror descent can be exponentially more sensitive to initialization than gradient descent, even with a well-conditioned regularizer in Euclidean norm. In a three-dimensional construction with a convex smooth objective and a strongly convex smooth well-conditioned regularizer, an initial ε perturbation amplifies to min{polylog^{-1}(1/ε), ε e^{Ω(ηT)}} after T iterations with step size η. For canonical KL-regularized mirror descent on the simplex, even linear objectives amplify perturbations exponentially in high-dimensional or near-boundary regimes.
What carries the argument
The non-quadratic regularizer inducing a non-Euclidean geometry in the mirror descent update that produces exponential amplification of perturbations.
If this is right
- Adding a Bregman regularization term toward an anchor point stabilizes the dynamics while largely preserving optimization guarantees.
- Anchoring at the initialization only partially mitigates the instability.
- Anchoring at a fixed point yields a more stable mechanism than anchoring at initialization.
- Even linear objectives under KL-regularized mirror descent on the simplex amplify initial perturbations exponentially in high-dimensional or near-boundary regimes.
Where Pith is reading between the lines
- The exponential sensitivity may contribute to reproducibility challenges when fine-tuning models with KL-regularized objectives starting from pretrained checkpoints.
- The separation indicates that stability guarantees proven for Euclidean or quadratic cases do not automatically extend to other Bregman divergences without extra safeguards.
- Choosing the anchor point in stabilized variants requires care, as different choices produce qualitatively different robustness properties.
Load-bearing premise
The three-dimensional construction uses a specific convex smooth objective paired with a non-quadratic regularizer that remains strongly convex and smooth with bounded Euclidean condition number.
What would settle it
Numerical execution of the three-dimensional construction for small ε and sufficiently large T showing that the perturbation size remains bounded by a constant factor of ε rather than reaching min{polylog^{-1}(1/ε), ε e^{Ω(ηT)}}.
Figures
read the original abstract
Mirror Descent (MD) extends Gradient Descent (GD) beyond Euclidean geometry and has recently reappeared as a lens for KL-regularized policy optimization in reinforcement learning and LLM post-training. This raises a basic robustness question, crucial to reproducibility and reliability: how sensitive are MD dynamics to their inputs? We focus on initialization, often itself a pretrained or previously aligned model. Quadratic-regularized MD, including GD and Mahalanobis geometries, is well-known to be stable for convex smooth objectives. We show a sharp contrast: once the regularizer is non-quadratic, MD can be exponentially more sensitive to initialization than GD, even with a well-conditioned regularizer in Euclidean norm. We give a three-dimensional construction with a convex, smooth objective and a strongly convex, smooth, well-conditioned regularizer where an initial $\varepsilon$ perturbation is quickly amplified to $\min\{\text{polylog}^{-1}(1/\varepsilon), \varepsilon e^{\Omega(\eta T)}\}$ after $T$ iterations of MD with step size $\eta$. For canonical KL-regularized MD on the simplex, we show that even linear objectives can amplify an initial $\varepsilon$ perturbation exponentially fast in high-dimensional or near-boundary regimes. Finally, we show that adding a Bregman regularization term toward an anchor point can stabilize the dynamics while largely preserving the optimization guarantees, and that the choice of anchor is crucial: anchoring at the initialization only partially mitigates the instability, whereas anchoring at a fixed point yields a more stable mechanism.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that mirror descent with non-quadratic regularizers can exhibit exponential sensitivity to initialization perturbations, unlike quadratic-regularized MD or GD. It provides an explicit three-dimensional construction with convex smooth objective f and strongly convex smooth regularizer ψ (with Euclidean condition number bounded independently of ε and T) where an O(ε) initialization difference amplifies to min{polylog^{-1}(1/ε), ε e^{Ω(ηT)}} after T steps of MD. It further shows exponential amplification for canonical KL-regularized MD on the simplex even with linear objectives in high-dimensional or near-boundary regimes, and proposes stabilization by adding a Bregman term toward a fixed anchor point.
Significance. If the constructions hold, the result is significant for robustness analysis of MD in RL and LLM post-training contexts. The explicit mathematical constructions and analysis constitute a strength, providing concrete, parameter-free examples of the claimed separation rather than fitted or self-referential arguments.
major comments (2)
- [three-dimensional construction] The central claim rests on the 3D construction (detailed after the introduction) simultaneously satisfying: (i) f convex and smooth, (ii) ψ strongly convex and smooth, (iii) Euclidean condition number of ψ bounded independently of ε and T, and (iv) the discrete MD update producing the stated amplification bound. The analysis must explicitly verify that the Euclidean Lipschitz constant of ∇ψ does not grow with the construction parameters or ε.
- [KL-regularized MD analysis] § on KL-regularized MD on the simplex: the exponential amplification claim for linear objectives in high-dimensional or near-boundary regimes must confirm that the dynamics yield the growth factor without introducing hidden ε-dependence that would violate the well-conditioned regularizer assumption.
minor comments (1)
- [Abstract] The notation min{polylog^{-1}(1/ε), ε e^{Ω(ηT)}} in the abstract and main claim could be expanded with a brief parenthetical on the regime where each term dominates.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive feedback. The positive assessment of the paper's significance is appreciated. We address each major comment below with clarifications and commit to revisions as needed.
read point-by-point responses
-
Referee: The analysis must explicitly verify that the Euclidean Lipschitz constant of ∇ψ does not grow with the construction parameters or ε.
Authors: We agree that an explicit verification strengthens the presentation. In the 3D construction, ψ is defined via a Hessian that is diagonal with eigenvalues in [1,2], so the Euclidean Lipschitz constant of ∇ψ is at most 2 independently of ε and T (and the condition number is likewise bounded by 2). We will add a short lemma in the revised Section 3 providing the direct Hessian-norm calculation to make this uniform bound fully explicit. revision: yes
-
Referee: the exponential amplification claim for linear objectives in high-dimensional or near-boundary regimes must confirm that the dynamics yield the growth factor without introducing hidden ε-dependence that would violate the well-conditioned regularizer assumption.
Authors: The KL-regularizer analysis uses the standard simplex geometry and derives the growth factor from the linear objective combined with local linearization of the mirror map; the conditioning of the regularizer remains independent of ε by construction of the high-dimensional and near-boundary regimes. We will revise the relevant subsection to include an explicit remark and a short recurrence derivation confirming the absence of hidden ε-dependence in the amplification factor. revision: partial
Circularity Check
No circularity: explicit 3D construction and direct dynamics analysis
full rationale
The paper's central result is an explicit three-dimensional construction of a convex smooth objective f and a non-quadratic strongly convex smooth regularizer ψ (with bounded Euclidean condition number) together with a direct analysis of the MD iterates on that pair. The claimed amplification of an ε-initialization difference is obtained by substituting the constructed functions into the MD update rule and bounding the resulting recurrence; no parameter is fitted to data, no quantity is defined in terms of the target separation, and no load-bearing step reduces to a self-citation. The KL-regularized simplex case and the stabilization result are likewise obtained by direct calculation on explicit linear objectives and anchor choices. All steps are therefore self-contained against external benchmarks and receive the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The objective function is convex and smooth
- domain assumption The regularizer is strongly convex, smooth, and well-conditioned in Euclidean norm yet non-quadratic
Reference graph
Works this paper leans on
-
[1]
Advances in neural information processing systems , volume=
On the complexity of linear prediction: Risk bounds, margin bounds, and regularization , author=. Advances in neural information processing systems , volume=
-
[2]
Conference on Learning Theory , pages=
Uniform stability for first-order empirical risk minimization , author=. Conference on Learning Theory , pages=. 2022 , organization=
2022
-
[3]
SIAM Journal on Optimization , volume=
Relatively smooth convex optimization by first-order methods, and applications , author=. SIAM Journal on Optimization , volume=. 2018 , publisher=
2018
-
[4]
arXiv preprint arXiv:2511.22283 , year=
The Hidden Cost of Approximation in Online Mirror Descent , author=. arXiv preprint arXiv:2511.22283 , year=
-
[5]
2013 , publisher=
Introductory lectures on convex optimization: A basic course , volume=. 2013 , publisher=
2013
-
[6]
SIAM Journal on Matrix Analysis and Applications , volume=
Randomized iterative methods for linear systems , author=. SIAM Journal on Matrix Analysis and Applications , volume=. 2015 , publisher=
2015
-
[7]
Accessed: May , url=
Last iterate of sgd converges (even in unbounded domains), 2020 , author=. Accessed: May , url=
2020
-
[8]
Conference on Learning Theory , pages=
Toward a noncommutative arithmetic-geometric mean inequality: conjectures, case-studies, and consequences , author=. Conference on Learning Theory , pages=. 2012 , organization=
2012
-
[9]
How good is
Safran, Itay and Shamir, Ohad , booktitle=. How good is. 2020 , organization=
2020
-
[10]
Closing the convergence gap of
Rajput, Shashank and Gupta, Anant and Papailiopoulos, Dimitris , booktitle=. Closing the convergence gap of. 2020 , organization=
2020
-
[11]
Advances in Neural Information Processing Systems , volume=
Random reshuffling: Simple analysis with vast improvements , author=. Advances in Neural Information Processing Systems , volume=
-
[12]
International Conference on Machine Learning , pages=
Tighter lower bounds for shuffling SGD: Random permutations and beyond , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[13]
arXiv preprint arXiv:2306.12498 , year=
Empirical risk minimization with shuffled SGD: a primal-dual perspective and improved bounds , author=. arXiv preprint arXiv:2306.12498 , year=
-
[14]
arXiv preprint arXiv:2403.06873 , year=
Last iterate convergence of incremental methods and applications in continual learning , author=. arXiv preprint arXiv:2403.06873 , year=
-
[15]
Conference on Learning Theory , pages=
Making the last iterate of sgd information theoretically optimal , author=. Conference on Learning Theory , pages=. 2019 , organization=
2019
-
[16]
arXiv preprint arXiv:2307.11134 , year=
Exact convergence rate of the last iterate in subgradient methods , author=. arXiv preprint arXiv:2307.11134 , year=
-
[17]
International Conference on Machine Learning , pages=
Train faster, generalize better: Stability of stochastic gradient descent , author=. International Conference on Machine Learning , pages=. 2016 , organization=
2016
-
[18]
The 22nd international conference on artificial intelligence and statistics , pages=
Fast and faster convergence of sgd for over-parameterized models and an accelerated perceptron , author=. The 22nd international conference on artificial intelligence and statistics , pages=. 2019 , organization=
2019
-
[19]
Lecture notes , volume=
Introductory lectures on convex programming volume i: Basic course , author=. Lecture notes , volume=
-
[20]
Mathematical Programming , volume=
An optimal method for stochastic composite optimization , author=. Mathematical Programming , volume=. 2012 , publisher=
2012
-
[21]
Conference on Learning Theory , pages=
Benign overfitting of constant-stepsize sgd for linear regression , author=. Conference on Learning Theory , pages=. 2021 , organization=
2021
-
[22]
Advances in Neural Information Processing Systems , volume=
Tight nonparametric convergence rates for stochastic gradient descent under the noiseless linear model , author=. Advances in Neural Information Processing Systems , volume=
-
[23]
2020 , publisher=
First-order and stochastic optimization methods for machine learning , author=. 2020 , publisher=
2020
-
[24]
Proceedings of the 37th International Conference on Machine Learning , pages =
Fine-Grained Analysis of Stability and Generalization for Stochastic Gradient Descent , author =. Proceedings of the 37th International Conference on Machine Learning , pages =. 2020 , editor =
2020
-
[25]
The Twelfth International Conference on Learning Representations , year=
Revisiting the Last-Iterate Convergence of Stochastic Gradient Methods , author=. The Twelfth International Conference on Learning Representations , year=
-
[26]
Advances in neural information processing systems , volume=
Smoothness, low noise and fast rates , author=. Advances in neural information processing systems , volume=
-
[27]
Advances in neural information processing systems , volume=
Non-strongly-convex smooth stochastic approximation with convergence rate O (1/n) , author=. Advances in neural information processing systems , volume=
-
[28]
Advances in Neural Information Processing Systems , volume=
Optimal rates for random order online optimization , author=. Advances in Neural Information Processing Systems , volume=
-
[29]
Advances in Neural Information Processing Systems , volume=
Benign underfitting of stochastic gradient descent , author=. Advances in Neural Information Processing Systems , volume=
-
[30]
International Conference on Machine Learning , pages=
Sgd without replacement: Sharper rates for general smooth convex functions , author=. International Conference on Machine Learning , pages=. 2019 , organization=
2019
-
[31]
The Journal of Machine Learning Research , volume=
Learnability, stability and uniform convergence , author=. The Journal of Machine Learning Research , volume=. 2010 , publisher=
2010
-
[32]
The Journal of Machine Learning Research , volume=
Stability and generalization , author=. The Journal of Machine Learning Research , volume=. 2002 , publisher=
2002
-
[33]
Proceedings of the 30th International Conference on Machine Learning , pages =
Stochastic Gradient Descent for Non-smooth Optimization: Convergence Results and Optimal Averaging Schemes , author =. Proceedings of the 30th International Conference on Machine Learning , pages =. 2013 , editor =
2013
-
[34]
ICLR , year=
The Implicit Bias of Gradient Descent on Separable Data , author=. ICLR , year=
-
[35]
The Implicit Bias of Gradient Descent on Separable Data , archivePrefix = "arXiv", arxivId =
Soudry, Daniel and Hoffer, Elad and. The Implicit Bias of Gradient Descent on Separable Data , archivePrefix = "arXiv", arxivId =. arXiv:1710.10345v3 , journal=
-
[36]
AISTATS , year=
Stochastic gradient descent on separable data: Exact convergence with a fixed learning rate , author=. AISTATS , year=
-
[37]
Journal of Global Optimization , volume=
Accelerated sampling Kaczmarz Motzkin algorithm for the linear feasibility problem , author=. Journal of Global Optimization , volume=. 2020 , publisher=
2020
-
[38]
IEEE Transactions on Signal Processing , volume=
On the convergence behavior of the LMS and the normalized LMS algorithms , author=. IEEE Transactions on Signal Processing , volume=. 1993 , publisher=
1993
-
[39]
AISTATS , year=
Convergence of gradient descent on separable data , author=. AISTATS , year=
-
[40]
ICML , year=
Lexicographic and Depth-Sensitive Margins in Homogeneous and Non-Homogeneous Deep Models , author=. ICML , year=
-
[41]
and Liu, Qiang and Ma, Tengyu , journal =
Wei, Colin and Lee, Jason D. and Liu, Qiang and Ma, Tengyu , journal =. On the Margin Theory of Feedforward Neural Networks , year =
-
[42]
Conference on Learning Theory (COLT) , year=
Beneath the valley of the noncommutative arithmetic-geometric mean inequality: conjectures, case-studies, and consequences , author=. Conference on Learning Theory (COLT) , year=
-
[43]
Implicit Bias of Gradient Descent on Linear Convolutional Networks , volume =
Gunasekar, Suriya and Lee, Jason D and Soudry, Daniel and Srebro, Nati , booktitle =. Implicit Bias of Gradient Descent on Linear Convolutional Networks , volume =
-
[44]
and Bassily, R
Ma, S. and Bassily, R. and Belkin, M. , eprint =
- [45]
-
[46]
Smith, S. L. and Kindermans, P. and Ying, C. and Le, Q. V. , booktitle =
-
[47]
ICLR, Spotlight
At Stability's Edge: How to Adjust Hyperparameters to Preserve Minima Selection in Asynchronous Training of Neural Networks? , author=. ICLR, Spotlight. , year=
-
[48]
Nar, Kamil and Sastry, S Shankar , booktitle =
-
[49]
Wu, Lei and Ma, Chao and E, Weinan , booktitle =
-
[50]
COLT , year=
How do infinite width bounded norm networks look in function space? , author=. COLT , year=
-
[51]
, author=
The perceptron: a probabilistic model for information storage and organization in the brain. , author=. Psychological review , year=
-
[52]
Advances in Neural Information Processing Systems , pages=
Train longer, generalize better: closing the generalization gap in large batch training of neural networks , author=. Advances in Neural Information Processing Systems , pages=
-
[54]
Bertsekas, Dimitri P. , doi =. Mathematical Programming , keywords =. arXiv , arxivId =:1507.01030 , file =
-
[55]
arXiv , pages =
Smith, Leslie N , eprint =. arXiv , pages =
-
[56]
International Conference of Artificial Neural Networks (ICANN) , year=
-
[57]
ICML , year=
Characterizing implicit bias in terms of optimization geometry , author=. ICML , year=
-
[58]
AISTATS , title =
Nacson, Mor Shpigel and Lee, Jason and Gunasekar, Suriya and Srebro, Nathan and Soudry, Daniel , eprint =. AISTATS , title =
-
[59]
Journal of the ACM (JACM) , volume=
Sublinear optimization for machine learning , author=. Journal of the ACM (JACM) , volume=. 2012 , publisher=
2012
- [60]
-
[61]
2012 , publisher=
Boosting: Foundations and algorithms , author=. 2012 , publisher=
2012
-
[62]
arXiv , arxivId =:1705.08741 , title =
Hoffer, Elad and Hubara, Itay and Soudry, Daniel , booktitle =. arXiv , arxivId =:1705.08741 , title =
-
[63]
, publisher =
Bertsekas, D. , publisher =
-
[64]
The Annals of Mathematical Statistics , number =
Robbins, Herbert and Monro, Sutton , doi =. The Annals of Mathematical Statistics , number =
-
[65]
Foundations and Trends
Bubeck, S. Foundations and Trends
-
[66]
Ben-David, Shai and Shalev-Shwartz, Shai , doi =
-
[67]
Ghadimi, Saeed and Lan, Guanghui and Zhang, Hongchao , eprint =. Math. Prog. , keywords =
-
[68]
Wu, Yuhuai and Ren, Mengye and Liao, Renjie and Grosse, Roger , journal =
-
[69]
and Bertsekas, D.P
Geary, A. and Bertsekas, D.P. , doi =. Proceedings of the 38th IEEE Conference on Decision and Control (Cat. No.99CH36304) , keywords =
-
[70]
JMLR , keywords =
Wang, Weiran , eprint =. JMLR , keywords =
-
[71]
Shamir, Ohad , eprint =
-
[72]
Nedic, Angelia and Bertsekas, Dimitri P. , doi =. Stochastic Optimization: Algorithms and Applications , pages =
-
[73]
Machine learning , volume=
On the equivalence of weak learnability and linear separability: New relaxations and efficient boosting algorithms , author=. Machine learning , volume=. 2010 , publisher=
2010
-
[74]
arXiv preprint arXiv:1307.1192 , year=
AdaBoost and forward stagewise regression are first-order convex optimization methods , author=. arXiv preprint arXiv:1307.1192 , year=
-
[75]
Journal of Machine Learning Research , volume=
Efficient margin maximizing with boosting , author=. Journal of Machine Learning Research , volume=
-
[76]
The Annals of Statistics , volume=
Boosting with early stopping: Convergence and consistency , author=. The Annals of Statistics , volume=. 2005 , publisher=
2005
-
[77]
arXiv , title =
Xu, Tengyu and Zhou, Yi and Ji, Kaiyi and Liang, Yingbin , eprint =. arXiv , title =
-
[78]
Proceedings of the 30th International Conference on International Conference on Machine Learning-Volume 28 , pages=
Margins, shrinkage and boosting , author=. Proceedings of the 30th International Conference on International Conference on Machine Learning-Volume 28 , pages=. 2013 , organization=
2013
-
[79]
arXiv preprint arXiv:1803.07300v2 , year=
Risk and parameter convergence of logistic regression , author=. arXiv preprint arXiv:1803.07300v2 , year=
-
[80]
Neural computation , year=
Natural gradient works efficiently in learning , author=. Neural computation , year=
-
[81]
2004 , publisher=
Convex optimization , author=. 2004 , publisher=
2004
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.