Qift: Shift-Friendly No-Zero W2 Post-Training Quantization for Rotated W2A4/KV4 LLM Inference
Pith reviewed 2026-06-28 15:47 UTC · model grok-4.3
The pith
A fixed no-zero two-bit weight level set based on zero-centered Gaussian model improves rotated W2A4 inference over the standard symmetric set on LLaMA models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
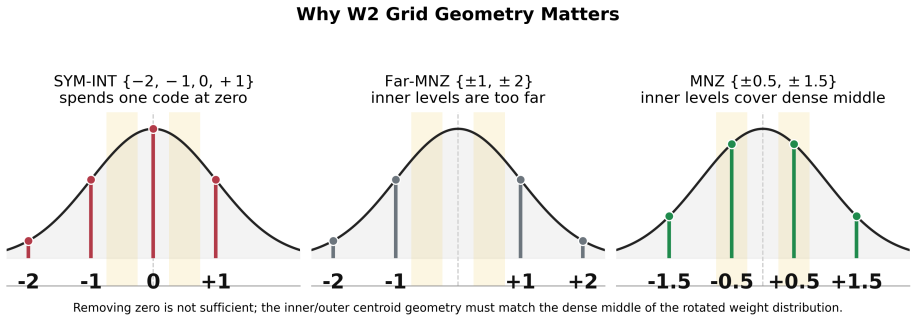
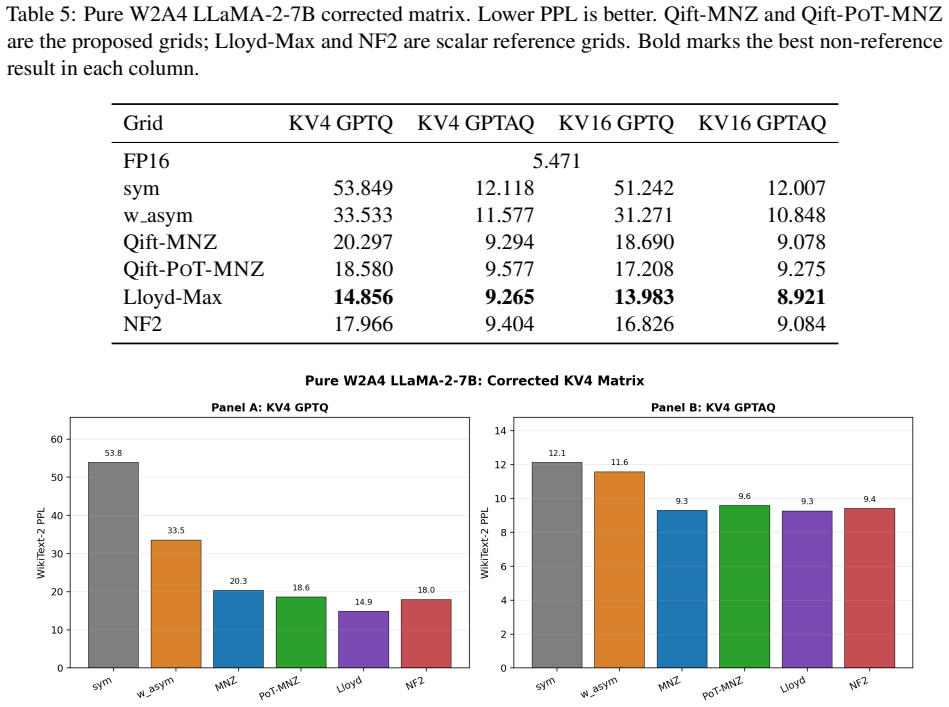
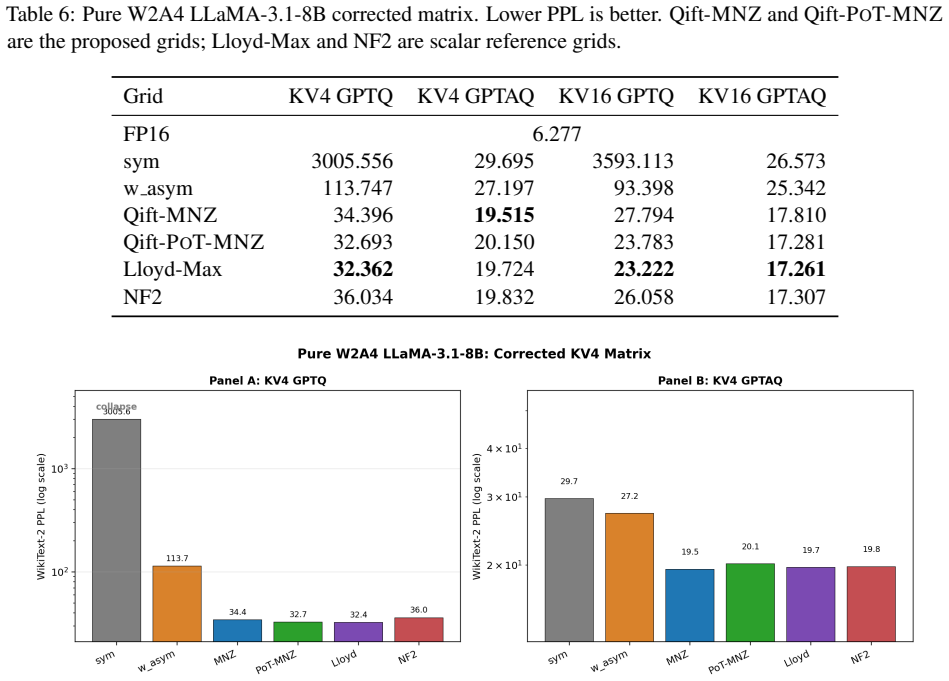
A fixed no-zero W2 level set {+/-0.5, +/-1.5} (equivalently {+/-1, +/-3} under half-scale) or its power-of-two counterpart {+/-1, +/-4}, chosen so the inner-to-outer centroid ratio lies between 0.25 and 0.33, consistently outperforms the standard level set {-2,-1,0,+1} in rotated W2A4/KV4 inference on both LLaMA-2-7B and LLaMA-3.1-8B; the gains appear in perplexity, accuracy, and GPTQ residuals because the new mapping better matches the approximate zero-centered Gaussian shape produced by Hadamard rotation of pretrained weights.
What carries the argument
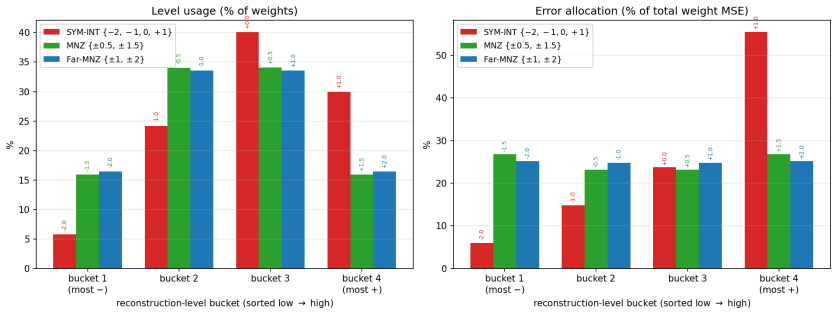
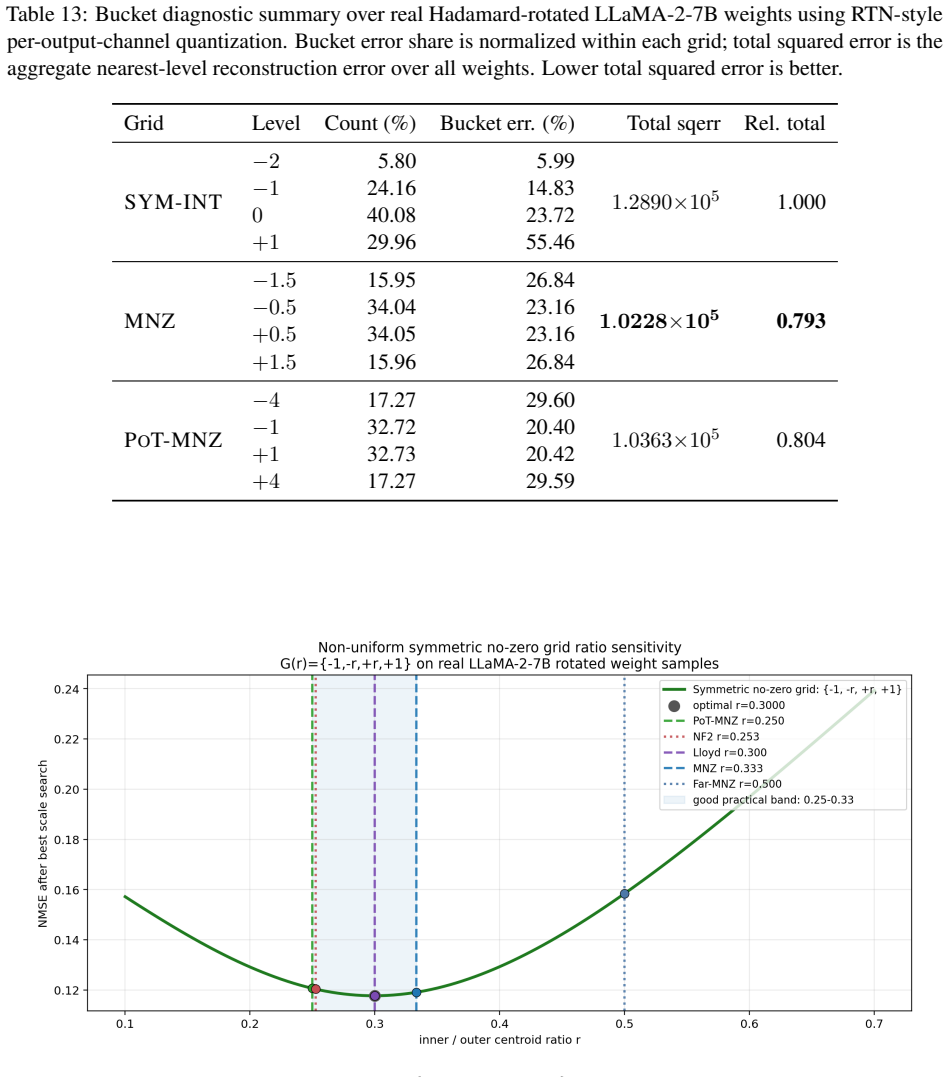
The no-zero level set {+/-0.5, +/-1.5} identified by scale-invariant ratio analysis of the inner/outer centroid ratio range 0.25-0.33; it replaces the standard symmetric levels while remaining training-free, zero-point-free, and group-grid-free.
If this is right
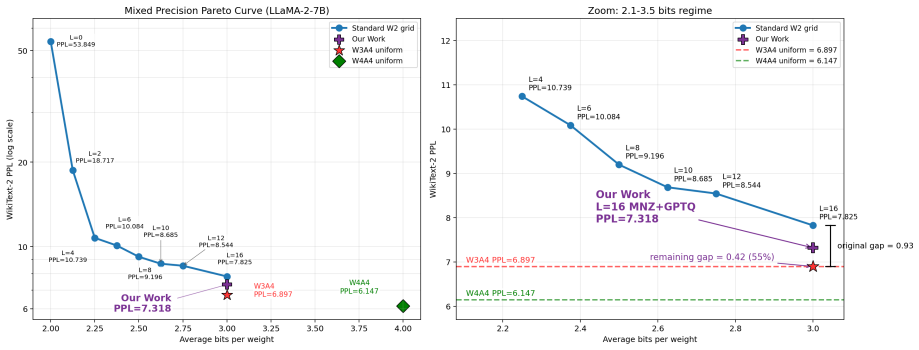
- The no-zero sets raise L-layer mixed W2/W4 perplexity while keeping the same per-channel scaling.
- At L=16 mixed precision they narrow the gap to full W3A4 while holding half the layers at two-bit weights.
- Mirror no-zero, Lloyd, NF2, and PoT-MNZ level sets also perform well because they share the same 0.25-0.33 centroid ratio.
- The approach stays deployment-friendly: no learned codebooks, no extra zero-point storage, and sign-and-shift decoding for the power-of-two variant.
Where Pith is reading between the lines
- If the Gaussian-after-rotation property holds for other orthogonal transforms, the same ratio-derived level set could be reused without retraining.
- The ratio analysis supplies a simple diagnostic that could be applied to derive level sets for other bit widths or activation precisions.
- Testing the fixed set on models larger than 8B or on non-LLaMA architectures would check whether the zero-centered Gaussian premise generalizes beyond the two evaluated models.
Load-bearing premise
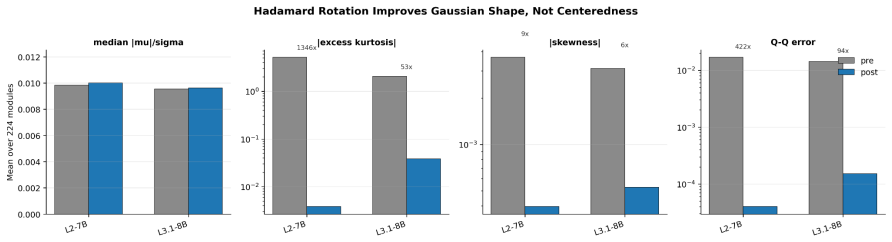
Pretrained weights are already nearly zero-centered and Hadamard rotation primarily Gaussianizes their standardized shape, allowing one fixed no-zero level set to work for all modules without per-module or learned adjustments.
What would settle it
On a new model or rotation where the weight distribution is not approximately zero-centered Gaussian, measure whether the no-zero set still lowers perplexity and raises accuracy relative to the standard set; failure to do so would falsify the source-model justification.
Figures
read the original abstract
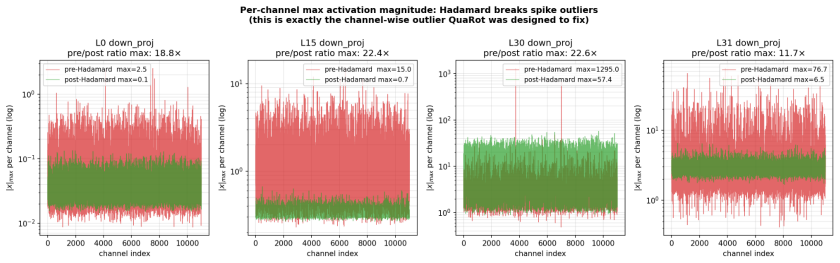
Two-bit weight quantization is attractive for memory-efficient LLM inference, but the standard W2 level set {-2,-1,0,+1} often collapses under aggressive W2A4/KV4 settings. We study the scalar level-set geometry of two-bit weights in a Hadamard-rotated quantization pipeline. Conventional asymmetric W2 substantially improves over the standard level set, indicating that W2A4 failure is not only a bit-width problem but also a reconstruction-level problem. Across all 224 linear modules in each of LLaMA-2-7B and LLaMA-3.1-8B, pretrained weights are already nearly zero-centered, while Hadamard rotation primarily Gaussianizes their standardized shape: excess kurtosis and Q-Q error drop by orders of magnitude. Based on this approximate zero-centered Gaussian-like source model, we propose Qift, a fixed no-zero W2 level set for rotated W2A4/KV4 inference. The main level set is {+/-0.5, +/-1.5}, equivalently {+/-1, +/-3} under a half-scale reparameterization; a power-of-two variant uses {+/-1, +/-4} for sign-and-shift decoded weight application. Qift redesigns the fixed two-bit code-to-level mapping and is training-free, learned-codebook-free, group-grid-free, and zero-point-free, retaining the standard per-channel scale. A scale-invariant ratio analysis identifies an effective inner/outer centroid ratio range of 0.25 to 0.33, explaining why mirror no-zero (MNZ), Lloyd, NF2, and PoT-MNZ perform well while {+/-1, +/-2} does not. On both models, the no-zero level sets consistently improve pure W2A4 perplexity, L-layer mixed W2/W4 perplexity, downstream accuracy, and GPTQ residual behavior over the standard W2 level set. At L=16 mixed precision, they substantially narrow the gap to W3A4 while keeping half of the transformer layers at two-bit precision, giving a simple, source-aware, and deployment-friendly alternative to more complex learned W2 codebooks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Qift, a fixed no-zero W2 level set {±0.5, ±1.5} (and PoT variant {±1, ±4}) for post-training quantization of Hadamard-rotated weights under W2A4/KV4 settings. It claims that pretrained weights in LLaMA-2-7B and LLaMA-3.1-8B are nearly zero-centered, rotation primarily Gaussianizes their shape (reducing excess kurtosis and Q-Q error), and this motivates the level set over the standard {-2,-1,0,1}. The method is training-free, zero-point-free, and retains per-channel scaling; a scale-invariant ratio analysis identifies an effective inner/outer centroid range of 0.25-0.33. Exhaustive evaluation across all 224 linear modules per model reports consistent gains in pure W2A4 perplexity, L-layer mixed W2/W4 perplexity, downstream accuracy, and GPTQ residuals, narrowing the gap to W3A4 at L=16 mixed precision.
Significance. If the per-module empirical results hold, the work offers a simple, deployment-friendly, source-aware alternative to learned codebooks for low-bit LLM inference. Strengths include the exhaustive evaluation on every linear layer of two models, the identification of the 0.25-0.33 ratio range explaining why certain no-zero sets succeed, and the training-free nature with standard per-channel scaling retained. This could simplify W2A4/KV4 pipelines while retaining half the layers at 2-bit precision in mixed settings.
minor comments (3)
- Abstract and §3 (or equivalent results section): while the text states consistent improvements across 224 modules, include explicit numerical tables or figures with perplexity deltas, accuracy values, and error bars for the main W2A4 and mixed-precision settings to allow direct verification of the claimed gains over the standard level set.
- §4 (ratio analysis): the scale-invariant inner/outer centroid ratio derivation is central to explaining why {±0.5, ±1.5} succeeds; add a short self-contained derivation or pseudocode showing how the 0.25-0.33 range is obtained from the zero-centered Gaussian model without reference to final accuracy metrics.
- Figure captions and §5 (GPTQ residuals): clarify whether the reported residual behavior improvements are measured on the same rotated weights used for the level-set design or on an independent calibration set.
Simulated Author's Rebuttal
We thank the referee for the positive summary, recognition of the exhaustive per-module evaluation across 224 layers, the scale-invariant ratio analysis, and the training-free nature of Qift. The recommendation for minor revision is appreciated. No specific major comments were provided in the report.
Circularity Check
No significant circularity identified
full rationale
The paper proposes the Qift no-zero level set {±0.5, ±1.5} (and PoT variant) after observing that pretrained weights are nearly zero-centered and Hadamard rotation Gaussianizes their shape (excess kurtosis and Q-Q error drop by orders of magnitude). It then reports consistent empirical gains versus the standard {-2,-1,0,1} across all 224 modules on both LLaMA models for W2A4 perplexity, mixed-precision, accuracy, and GPTQ residuals. The scale-invariant ratio range 0.25-0.33 is extracted from the same rotated weight statistics to motivate the design but is not fitted to the target accuracy or perplexity metrics; the reported improvements stand on independent per-module measurements. No self-definitional equations, fitted-input predictions, load-bearing self-citations, uniqueness theorems, or ansatz smuggling appear. The derivation chain is self-contained against the stated benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Pretrained weights in the tested LLaMA models are already nearly zero-centered before rotation.
- domain assumption Hadamard rotation primarily Gaussianizes the standardized weight shape.
Reference graph
Works this paper leans on
-
[1]
GPTQ: Accurate Post-Training Quanti- zation for Generative Pre-trained Transformers
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. GPTQ: Accurate Post-Training Quanti- zation for Generative Pre-trained Transformers. InInternational Conference on Learning Representations, 2023.https://arxiv.org/abs/2210.17323
Pith/arXiv arXiv 2023
-
[2]
GPTAQ: Efficient Finetuning-Free Quantization for Asymmetric Calibration
Yuhang Li, Ruokai Yin, Donghyun Lee, Shiting Xiao, and Priyadarshini Panda. GPTAQ: Efficient Finetuning-Free Quantization for Asymmetric Calibration. InInternational Conference on Machine Learning, 2025.https://arxiv.org/abs/2504.02692
arXiv 2025
-
[3]
Croci, Bo Li, Pashmina Cameron, Martin Jaggi, Dan Alistarh, Torsten Hoefler, and James Hensman
Saleh Ashkboos, Amirkeivan Mohtashami, Maximilian L. Croci, Bo Li, Pashmina Cameron, Martin Jaggi, Dan Alistarh, Torsten Hoefler, and James Hensman. QuaRot: Outlier-Free 4-Bit Inference in Rotated LLMs.arXiv preprint arXiv:2404.00456, 2024.https://arxiv.org/abs/2404.00456
arXiv 2024
-
[4]
SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models
Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, and Song Han. SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models. InProceedings of the 40th International Conference on Machine Learning, volume 202 ofProceedings of Machine Learning Research, pages 38087–38099. PMLR, 2023. https://proceedings.mlr.press/ ...
2023
-
[5]
QLoRA: Efficient Finetuning of Quantized LLMs
Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. QLoRA: Efficient Finetuning of Quantized LLMs. InAdvances in Neural Information Processing Systems, volume 36, 2023. https://papers.neurips.cc/paper_files/paper/2023/hash/ 1feb87871436031bdc0f2beaa62a049b-Abstract-Conference.html
2023
-
[6]
SpinQuant: LLM Quantization with Learned Rotations
Zechun Liu, Changsheng Zhao, Igor Fedorov, Bilge Soran, Dhruv Choudhary, Raghuraman Kr- ishnamoorthi, Vikas Chandra, Yuandong Tian, and Tijmen Blankevoort. SpinQuant: LLM Quantization with Learned Rotations. InInternational Conference on Learning Represen- tations, 2025. https://proceedings.iclr.cc/paper_files/paper/2025/hash/ e5b1c0d4866f72393c522c8a00ee...
2025
-
[7]
FlatQuant: Flatness Matters for LLM Quantization
Yuxuan Sun, Ruikang Liu, Haoli Bai, Han Bao, Kang Zhao, Yuening Li, Jiaxin Hu, Xianzhi Yu, Lu Hou, Chun Yuan, Xin Jiang, Wulong Liu, and Jun Yao. FlatQuant: Flatness Matters for LLM Quantization. arXiv preprint arXiv:2410.09426, 2024.https://arxiv.org/abs/2410.09426
arXiv 2024
-
[8]
Rotate, Clip, and Partition: Towards W2A4KV4 Quantization by Integrating Rotation and Learnable Non-uniform Quantizer
Euntae Choi, Sumin Song, Woosang Lim, and Sungjoo Yoo. Rotate, Clip, and Partition: Towards W2A4KV4 Quantization by Integrating Rotation and Learnable Non-uniform Quantizer. InFindings of the Association for Computational Linguistics: EMNLP 2025, pages 7568–7590, 2025. https: //aclanthology.org/2025.findings-emnlp.400/
2025
-
[9]
QuIP#: Even Bet- ter LLM Quantization with Hadamard Incoherence and Lattice Codebooks
Albert Tseng, Jerry Chee, Qingyao Sun, V olodymyr Kuleshov, and Christopher De Sa. QuIP#: Even Bet- ter LLM Quantization with Hadamard Incoherence and Lattice Codebooks. InInternational Conference on Machine Learning, 2024.https://arxiv.org/abs/2402.04396
arXiv 2024
-
[10]
Extreme Compression of Large Language Models via Additive Quantization
Vage Egiazarian, Andrei Panferov, Denis Kuznedelev, Elias Frantar, Artem Babenko, and Dan Alistarh. Extreme Compression of Large Language Models via Additive Quantization. InInternational Conference on Machine Learning, 2024.https://arxiv.org/abs/2401.06118
arXiv 2024
-
[11]
AWQ: Activation-aware Weight Quantization for On-Device LLM Compression and Acceleration
Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, and Song Han. AWQ: Activation-aware Weight Quantization for On-Device LLM Compression and Acceleration. InProceedings of Machine Learning and Systems (MLSys), 2024. https://arxiv.org/abs/2306.00978
Pith/arXiv arXiv 2024
-
[12]
OmniQuant: Omnidirectionally Calibrated Quantization for Large Language Models
Wenqi Shao, Mengzhao Chen, Zhaoyang Zhang, Peng Xu, Lirui Zhao, Zhiqian Li, Kaipeng Zhang, Peng Gao, Yu Qiao, and Ping Luo. OmniQuant: Omnidirectionally Calibrated Quantization for Large Language Models. InInternational Conference on Learning Representations (ICLR), 2024. https: //arxiv.org/abs/2308.13137
arXiv 2024
-
[13]
LeanQuant: Accurate and Scalable Large Language Model Quantization with Loss-Error-Aware Grid
Tianyi Zhang and Anshumali Shrivastava. LeanQuant: Accurate and Scalable Large Language Model Quantization with Loss-Error-Aware Grid. InInternational Conference on Learning Representations, 2025.https://arxiv.org/abs/2407.10032
arXiv 2025
-
[14]
S. P. Lloyd. Least squares quantization in PCM.IEEE Transactions on Information Theory, 28(2):129– 137, 1982
1982
-
[15]
J. Max. Quantizing for minimum distortion.IRE Transactions on Information Theory, IT-6(1):7–12,
-
[16]
doi:10.1109/TIT.1960.1057548. 23
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.