Practical and Optimal Algorithm for Linear Contextual Bandits with Rare Parameter Updates
Pith reviewed 2026-06-28 16:41 UTC · model grok-4.3
The pith
Two algorithms achieve minimax-optimal regret for linear contextual bandits using only O(log log T) parameter updates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
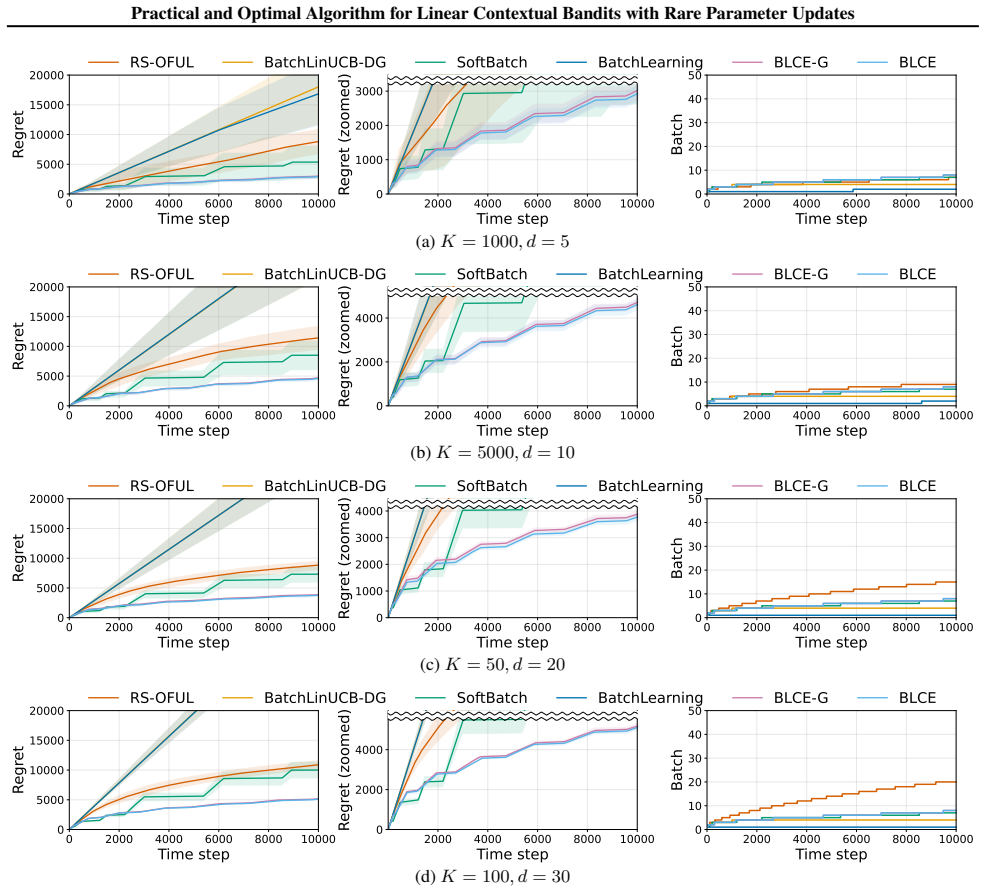
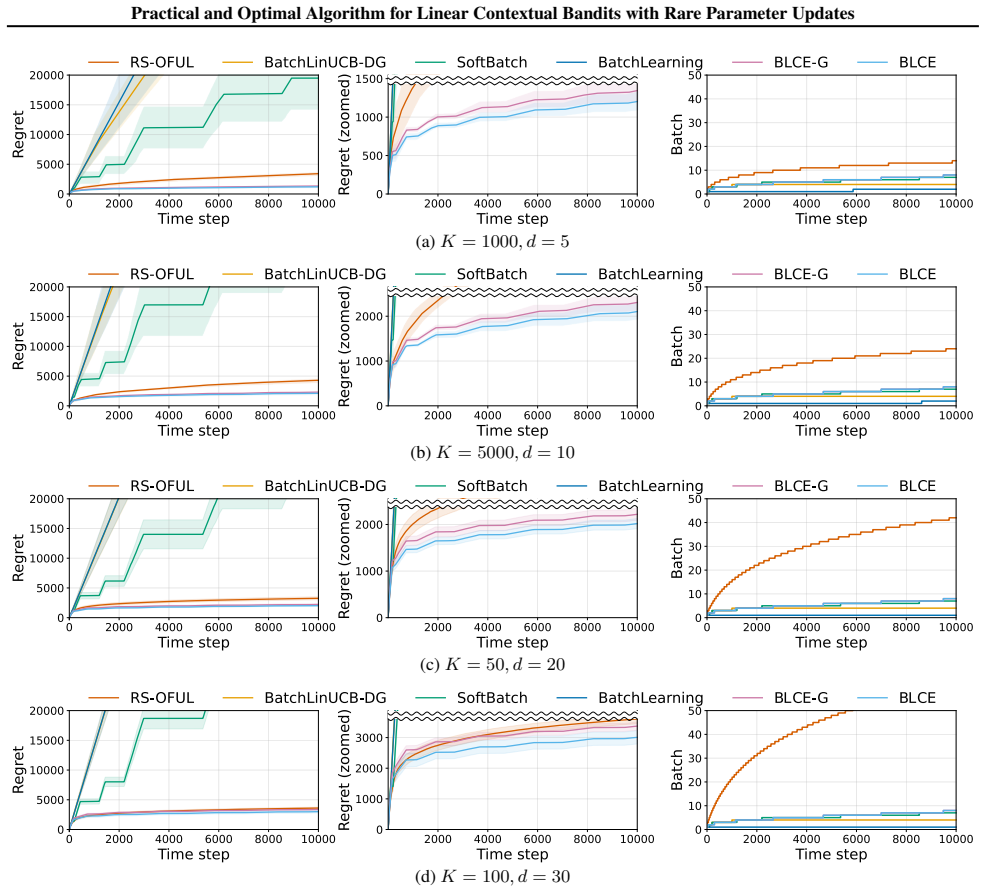
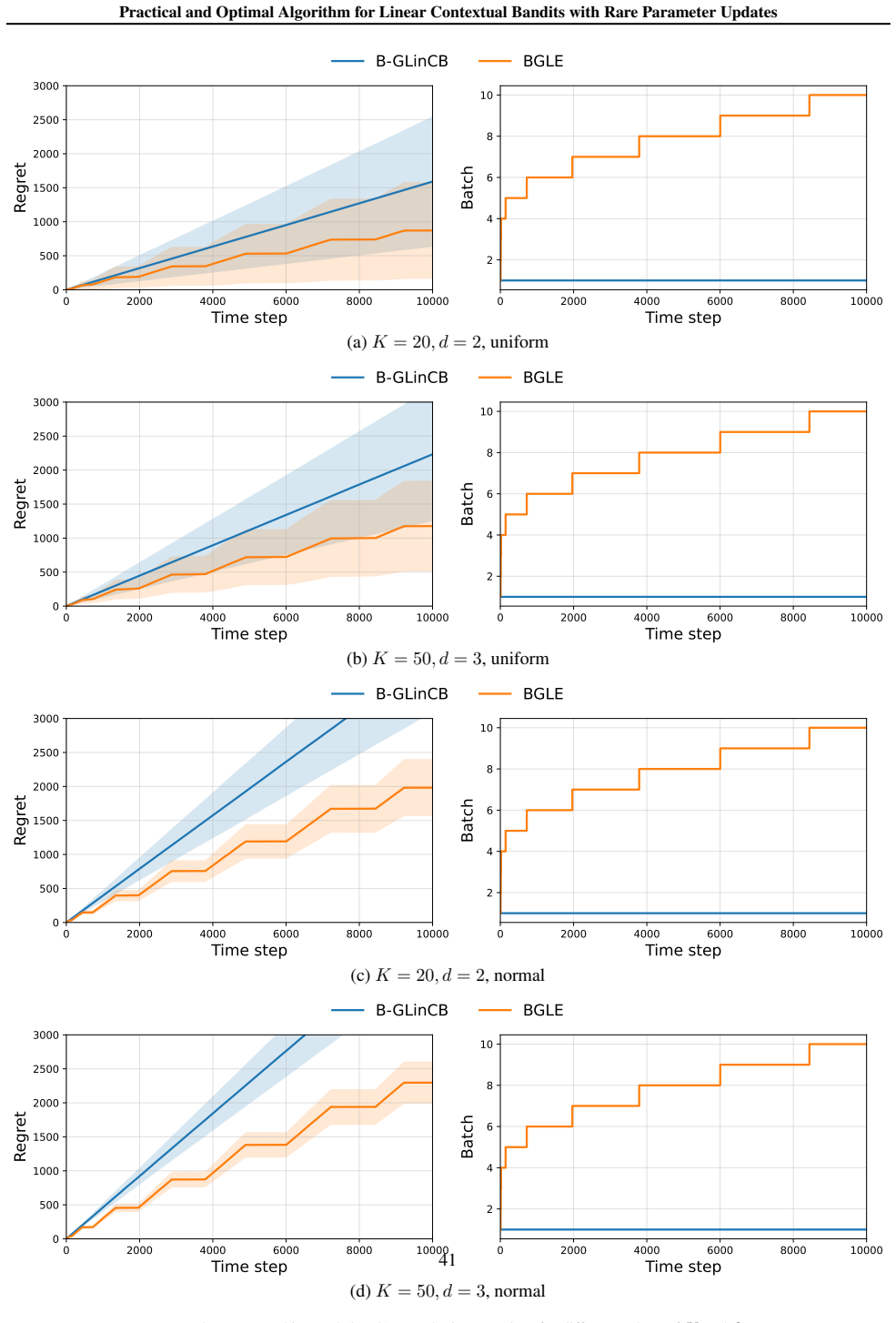
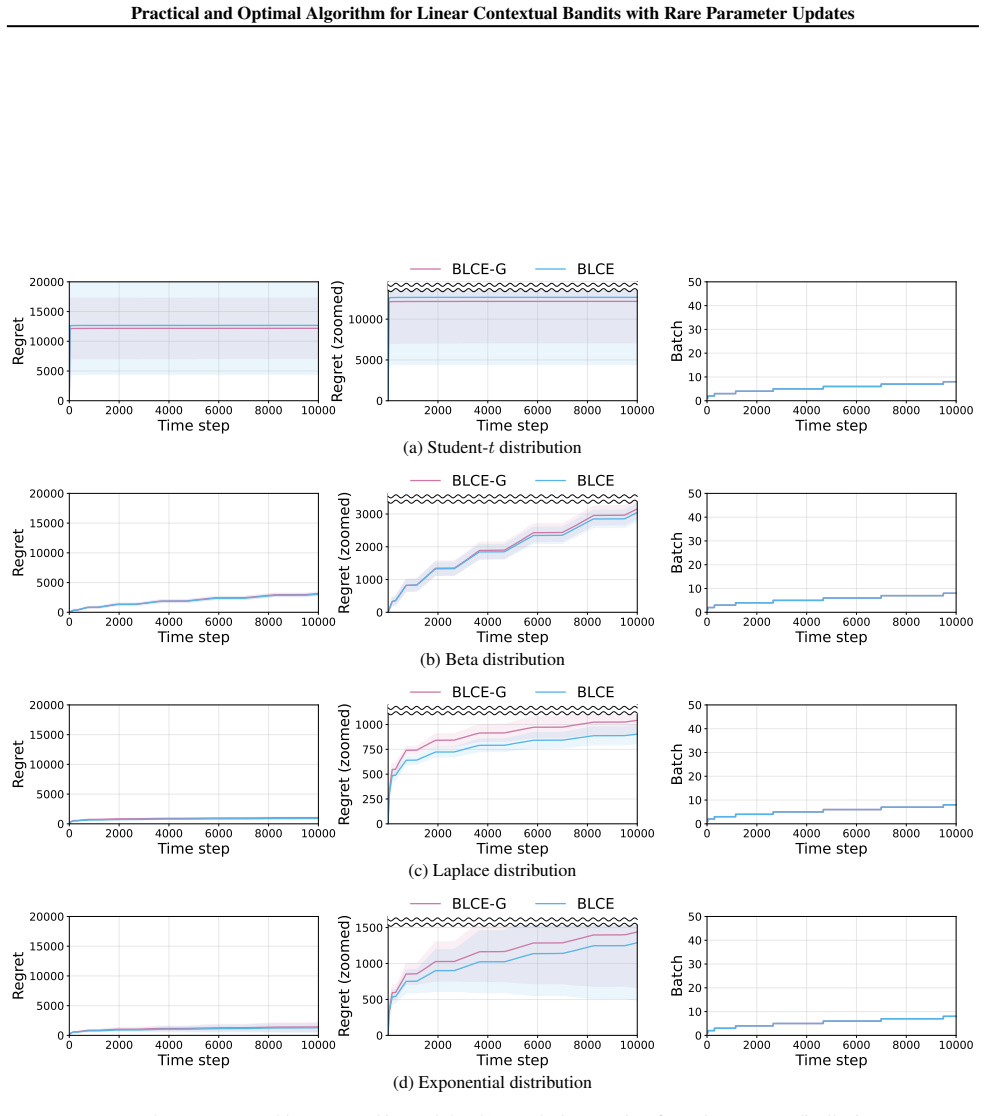
Under a static schedule of O(log log T) update times, the BLCE-G algorithm attains minimax-optimal regret up to polylogarithmic factors in T simultaneously for small and large action sets, while the BLCE algorithm removes the near G-optimal design computation, preserves the same regret guarantee, and records the lowest known runtime among optimal algorithms for the setting.
What carries the argument
A static grid of O(log log T) update times that divides the horizon into intervals inside which the policy can still adapt to the realized sequence of contexts and actions.
If this is right
- Minimax-optimal regret holds simultaneously across small-K and large-K regimes under the same static schedule.
- The dominant computational cost of near G-optimal design can be removed without sacrificing the optimal regret rate.
- The rare-update construction extends directly to generalized linear contextual bandits.
- The resulting runtime is the lowest known among all algorithms that achieve the minimax rate.
Where Pith is reading between the lines
- If the static schedule works, then full online parameter updates are unnecessary for optimality, which could reduce communication overhead in distributed or federated deployments.
- The same interval structure might transfer to other online decision problems where model refits are expensive.
- Empirical checks on large-scale recommendation data could test whether the polylog factors remain small in practice.
Load-bearing premise
A fixed non-adaptive schedule of O(log log T) updates is enough to recover minimax-optimal regret when action selection inside each interval can still depend on the realized contexts.
What would settle it
A concrete lower-bound construction or numerical simulation in which any algorithm limited to o(log log T) updates incurs regret strictly larger than the known minimax rate by more than polylog factors.
Figures
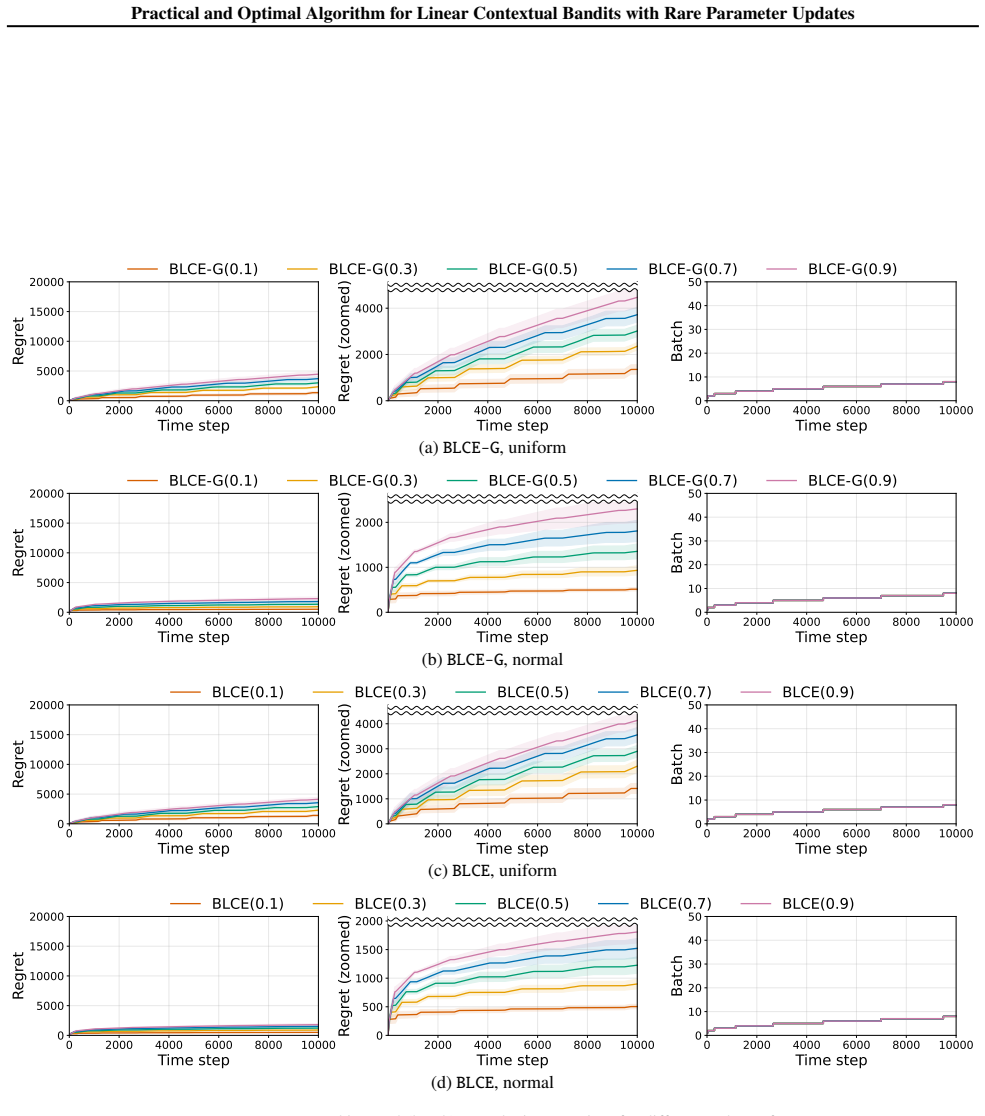
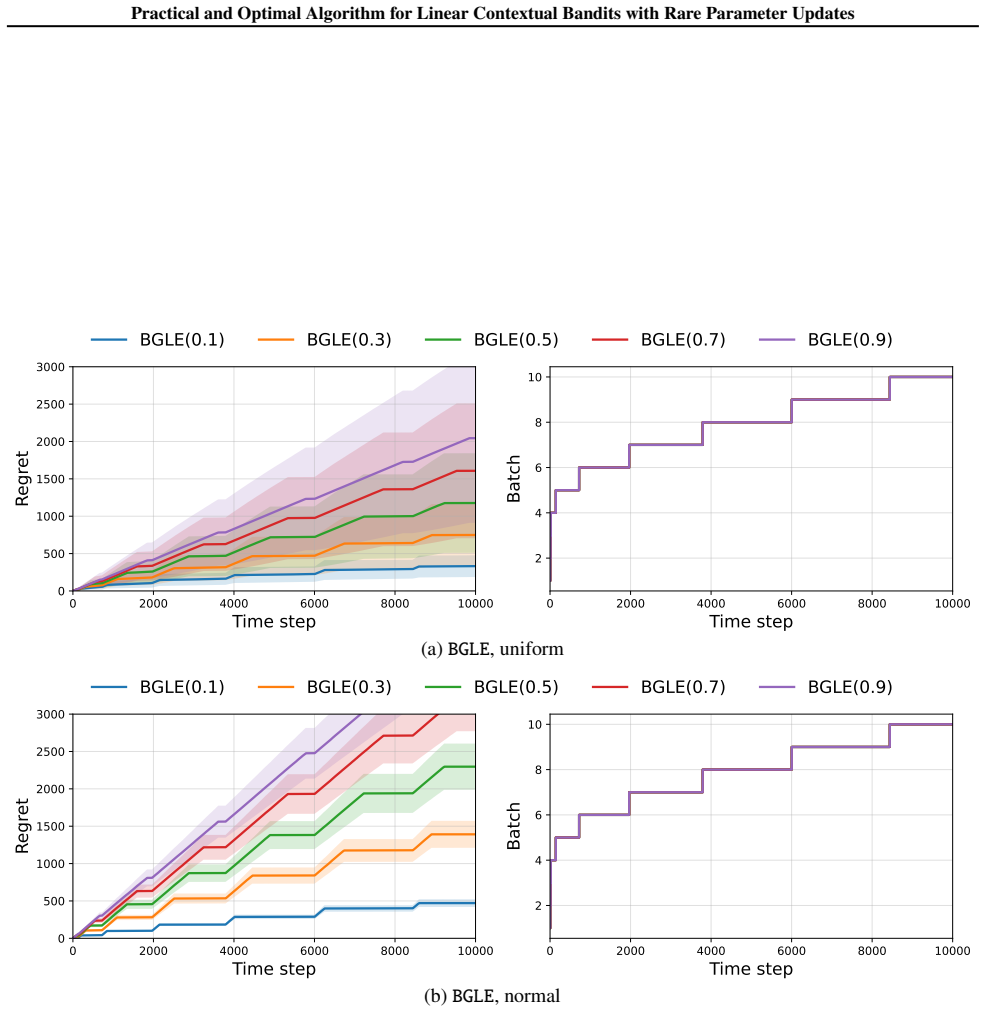
read the original abstract
We study linear contextual bandits under rare parameter updates: the learner may incorporate reward feedback into its parameter estimate only at a small number of update times, while still observing contexts online and selecting actions sequentially. This viewpoint clarifies a practical distinction that is often blurred in the literature: many "strictly batched" methods additionally restrict within-interval context adaptivity, meaning that the action rule inside an interval cannot depend on the sequence of realized contexts/actions in that interval (beyond the current round's context). For linear contextual bandits, we propose two practical algorithms with only $O(\log\log T)$ parameter updates. Our first algorithm BLCE-G attains minimax-optimal regret (up to polylogarithmic factors in $T$) simultaneously in both the small-$K$ and large-$K$ regimes under a static schedule. Our second algorithm BLCE removes the near G-optimal design step -- a dominant computational bottleneck in prior strictly batched static-grid methods -- yet preserves minimax-optimal regret and achieves the lowest known runtime complexity among optimal algorithms. We further extend these rare-update and computational principles to generalized linear contextual bandits. Overall, our results yield statistically optimal algorithms under $O(\log\log T)$ parameter updates that are also computationally efficient in practice.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript studies linear contextual bandits where parameter updates are restricted to a small number of times (O(log log T)) under a static schedule, while still permitting context-dependent action selection within each interval. It introduces BLCE-G, which attains minimax-optimal regret (up to polylog factors in T) simultaneously for small-K and large-K regimes, and BLCE, which eliminates the near G-optimal design computation while preserving the same regret guarantee and achieving the lowest known runtime among optimal methods. The approach is extended to generalized linear contextual bandits.
Significance. If the central claims hold, the work is significant because it delivers statistically optimal algorithms that are also practical under rare updates, explicitly separating the setting from strictly batched baselines by allowing within-interval adaptivity. This addresses a common practical constraint in deployment while matching known minimax bounds, and the runtime improvement in BLCE is a concrete computational contribution.
minor comments (3)
- [Abstract] Abstract: the phrase 'lowest known runtime complexity among optimal algorithms' would be strengthened by an explicit big-O expression for the per-round or total runtime of BLCE.
- [Introduction] The distinction between the proposed static schedule with within-interval adaptivity and strictly batched methods is central; a short clarifying paragraph or table contrasting the two (e.g., what information is available for action selection inside an interval) would improve readability.
- [Preliminaries] Notation for the update times and the intervals between them is used repeatedly; ensuring a single, consistently referenced definition (perhaps in a preliminary section) would reduce ambiguity for readers.
Simulated Author's Rebuttal
We thank the referee for the positive summary, recognition of the significance of separating rare-update linear contextual bandits from strictly batched settings, and the recommendation for minor revision. No specific major comments were provided in the report.
Circularity Check
No significant circularity; derivation self-contained
full rationale
The paper introduces BLCE-G and BLCE algorithms for linear contextual bandits under rare (O(log log T)) parameter updates, claiming minimax-optimal regret (up to polylog factors) in both small-K and large-K regimes. The abstract and description separate the method from strictly batched baselines by allowing within-interval context-adaptive action selection, but the optimality claim rests on standard regret analysis rather than any reduction of the target bound to a fitted quantity, self-definition, or self-citation chain. No equations or steps in the provided text exhibit self-definitional equivalence, fitted inputs renamed as predictions, or load-bearing self-citations. The result is presented as an extension of known minimax bounds to the rare-update setting without internal circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Linear reward model with sub-Gaussian noise
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems , volume=
An analysis of ensemble sampling , author=. Advances in Neural Information Processing Systems , volume=
-
[2]
Advances in Neural Information Processing Systems , volume=
Ensemble sampling , author=. Advances in Neural Information Processing Systems , volume=
-
[3]
Proceedings of the 17th ACM Conference on Recommender Systems , pages=
Deep exploration for recommendation systems , author=. Proceedings of the 17th ACM Conference on Recommender Systems , pages=
-
[4]
arXiv preprint arXiv:2311.08376 , year=
Ensemble sampling for linear bandits: small ensembles suffice , author=. arXiv preprint arXiv:2311.08376 , year=
-
[5]
Journal of the American Statistical Association , pages=
Stochastic low-rank tensor bandits for multi-dimensional online decision making , author=. Journal of the American Statistical Association , pages=. 2024 , publisher=
2024
-
[6]
International Conference on Machine Learning , pages=
Multiplier bootstrap-based exploration , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[7]
Abeille, Marc and Lazaric, Alessandro , year = 2017, booktitle =
2017
-
[8]
Annals of statistics , pages=
Adaptive estimation of a quadratic functional by model selection , author=. Annals of statistics , pages=. 2000 , publisher=
2000
-
[9]
Advances in Neural Information Processing Systems , volume=
Deep exploration via bootstrapped DQN , author=. Advances in Neural Information Processing Systems , volume=
-
[10]
Advances in Neural Information Processing Systems , volume=
Randomized prior functions for deep reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[11]
Proceedings of the 12th ACM Conference on Recommender Systems , pages=
Efficient online recommendation via low-rank ensemble sampling , author=. Proceedings of the 12th ACM Conference on Recommender Systems , pages=
-
[12]
International Conference on Artificial Intelligence and Statistics , pages=
Exploration via linearly perturbed loss minimisation , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2024 , organization=
2024
-
[13]
Advances in Neural Information Processing Systems , volume=
Scalable representation learning in linear contextual bandits with constant regret guarantees , author=. Advances in Neural Information Processing Systems , volume=
-
[14]
Advances in Neural Information Processing Systems , volume=
Model selection for contextual bandits , author=. Advances in Neural Information Processing Systems , volume=
-
[15]
International Conference on Artificial Intelligence and Statistics , pages=
Osom: A simultaneously optimal algorithm for multi-armed and linear contextual bandits , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2020 , organization=
2020
-
[16]
International Conference on Artificial Intelligence and Statistics , pages=
Stochastic linear contextual bandits with diverse contexts , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2020 , organization=
2020
-
[17]
2017 International Conference on Sampling Theory and Applications (SampTA) , pages=
Sparse linear contextual bandits via relevance vector machines , author=. 2017 International Conference on Sampling Theory and Applications (SampTA) , pages=. 2017 , organization=
2017
-
[18]
Artificial Intelligence and Statistics , pages=
Online-to-confidence-set conversions and application to sparse stochastic bandits , author=. Artificial Intelligence and Statistics , pages=. 2012 , organization=
2012
-
[19]
Mobile health: sensors, analytic methods, and applications , pages=
From ads to interventions: Contextual bandits in mobile health , author=. Mobile health: sensors, analytic methods, and applications , pages=. 2017 , publisher=
2017
-
[20]
arXiv preprint arXiv:1904.10040 , year=
A survey on practical applications of multi-armed and contextual bandits , author=. arXiv preprint arXiv:1904.10040 , year=
Pith/arXiv arXiv 1904
-
[21]
2020 , publisher=
Bandit algorithms , author=. 2020 , publisher=
2020
-
[22]
Proceedings of the 22nd ACM SIGKDD international conference on Knowledge discovery and data mining , pages=
Online context-aware recommendation with time varying multi-armed bandit , author=. Proceedings of the 22nd ACM SIGKDD international conference on Knowledge discovery and data mining , pages=
-
[23]
Proceedings of the 39th International ACM SIGIR conference on Research and Development in Information Retrieval , pages=
Collaborative filtering bandits , author=. Proceedings of the 39th International ACM SIGIR conference on Research and Development in Information Retrieval , pages=
-
[24]
Some aspects of the sequential design of experiments , author=
-
[25]
Journal of the American Statistical Association , pages=
Nearly dimension-independent sparse linear bandit over small action spaces via best subset selection , author=. Journal of the American Statistical Association , pages=. 2022 , publisher=
2022
-
[26]
Bayesian linear regression with sparse priors , author=
-
[27]
arXiv preprint arXiv:1002.1583 , year=
Thresholded Lasso for high dimensional variable selection and statistical estimation , author=. arXiv preprint arXiv:1002.1583 , year=
-
[28]
Biometrics , volume=
Doubly robust estimation in missing data and causal inference models , author=. Biometrics , volume=. 2005 , publisher=
2005
-
[29]
Nearly unbiased variable selection under minimax concave penalty , author=
-
[30]
Probability Theory and Related Fields , volume=
The lower tail of random quadratic forms with applications to ordinary least squares , author=. Probability Theory and Related Fields , volume=. 2016 , publisher=
2016
-
[31]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=
Regression shrinkage and selection via the lasso , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=. 1996 , publisher=
1996
-
[32]
Management Science , volume=
Mostly exploration-free algorithms for contextual bandits , author=. Management Science , volume=. 2021 , publisher=
2021
-
[33]
International Conference on Machine Learning , pages=
Leveraging good representations in linear contextual bandits , author=. International Conference on Machine Learning , pages=. 2021 , organization=
2021
-
[34]
Stochastic Systems , volume=
A linear response bandit problem , author=. Stochastic Systems , volume=. 2013 , publisher=
2013
-
[35]
International Conference on Machine Learning , pages=
A simple unified framework for high dimensional bandit problems , author=. International Conference on Machine Learning , pages=. 2022 , organization=
2022
-
[36]
International Conference on Artificial Intelligence and Statistics , pages=
Adaptive exploration in linear contextual bandit , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2020 , organization=
2020
-
[37]
International Conference on Machine Learning , pages=
Minimax concave penalized multi-armed bandit model with high-dimensional covariates , author=. International Conference on Machine Learning , pages=. 2018 , organization=
2018
-
[38]
International Conference on Machine Learning , pages=
Thresholded lasso bandit , author=. International Conference on Machine Learning , pages=. 2022 , organization=
2022
-
[39]
Advances in Neural Information Processing Systems , volume=
High-dimensional sparse linear bandits , author=. Advances in Neural Information Processing Systems , volume=
-
[40]
Electronic Journal of Statistics , volume=
Regret lower bound and optimal algorithm for high-dimensional contextual linear bandit , author=. Electronic Journal of Statistics , volume=. 2021 , publisher=
2021
-
[41]
International Conference on Machine Learning , pages=
Thompson sampling for high-dimensional sparse linear contextual bandits , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[42]
2011 , publisher=
Statistics for high-dimensional data: methods, theory and applications , author=. 2011 , publisher=
2011
-
[43]
Finite-time analysis of kernelised contextual bandits , author =
-
[44]
, author =
X-Armed Bandits. , author =
-
[45]
Conference on Learning Theory , pages=
Towards minimax policies for online linear optimization with bandit feedback , author=. Conference on Learning Theory , pages=. 2012 , organization=
2012
-
[46]
Doubly-robust lasso bandit , author =
-
[47]
Operations Research , publisher =
Online decision making with high-dimensional covariates , author =. Operations Research , publisher =
-
[48]
International Joint Conference on Artificial Intelligence , url =
Perturbed-History Exploration in Stochastic Multi-Armed Bandits , author =. International Joint Conference on Artificial Intelligence , url =
-
[49]
Conference on learning theory , pages =
Analysis of thompson sampling for the multi-armed bandit problem , author =. Conference on learning theory , pages =
-
[50]
Proceedings of the 24th annual conference on learning theory , pages =
The KL-UCB algorithm for bounded stochastic bandits and beyond , author =. Proceedings of the 24th annual conference on learning theory , pages =
-
[51]
2013 IEEE Information Theory Workshop (ITW) , pages=
Informational confidence bounds for self-normalized averages and applications , author=. 2013 IEEE Information Theory Workshop (ITW) , pages=. 2013 , organization=
2013
-
[52]
Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics , pages=
Contextual bandit algorithms with supervised learning guarantees , author=. Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics , pages=. 2011 , organization=
2011
-
[53]
, author =
Minimax Policies for Adversarial and Stochastic Bandits. , author =. COLT , volume = 7, pages =
-
[54]
, author =
Action Elimination and Stopping Conditions for the Multi-Armed Bandit and Reinforcement Learning Problems. , author =
-
[55]
Proceedings of the 40th International Conference on Machine Learning , publisher =
Combinatorial Neural Bandits , author =. Proceedings of the 40th International Conference on Machine Learning , publisher =
-
[56]
Composite convex minimization involving self-concordant-like cost functions , author =
-
[57]
European Journal of Operational Research , publisher =
A tractable online learning algorithm for the multinomial logit contextual bandit , author =. European Journal of Operational Research , publisher =
-
[58]
Proceedings of the 2014 SIAM International Conference on Data Mining , pages =
Contextual combinatorial bandit and its application on diversified online recommendation , author =. Proceedings of the 2014 SIAM International Conference on Data Mining , pages =
2014
-
[59]
Self-concordant analysis for logistic regression , author =
-
[60]
Dynamic assortment optimization with changing contextual information , author =
-
[61]
International conference on machine learning , pages =
Why is posterior sampling better than optimism for reinforcement learning? , author =. International conference on machine learning , pages =
-
[62]
An empirical evaluation of thompson sampling , author =
-
[63]
The International Journal of Robotics Research , publisher =
Reinforcement learning in robotics: A survey , author =. The International Journal of Robotics Research , publisher =
-
[64]
Nature , publisher =
Discovering faster matrix multiplication algorithms with reinforcement learning , author =. Nature , publisher =
-
[65]
Science , publisher =
A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play , author =. Science , publisher =
-
[66]
nature , publisher =
Mastering the game of go without human knowledge , author =. nature , publisher =
-
[67]
nature , publisher =
Human-level control through deep reinforcement learning , author =. nature , publisher =
-
[68]
9th International Conference on Learning Representations,
Optimism in Reinforcement Learning with Generalized Linear Function Approximation , author =. 9th International Conference on Learning Representations,
-
[69]
Advances in Neural Information Processing Systems , volume = 31, pages =
On Oracle-Efficient PAC RL with Rich Observations , author =. Advances in Neural Information Processing Systems , volume = 31, pages =
-
[70]
Advances in Neural Information Processing Systems , volume = 29, pages =
PAC Reinforcement Learning with Rich Observations , author =. Advances in Neural Information Processing Systems , volume = 29, pages =
-
[71]
International Conference on Machine Learning , pages =
Provably efficient RL with rich observations via latent state decoding , author =. International Conference on Machine Learning , pages =
-
[72]
, author =
Eluder Dimension and the Sample Complexity of Optimistic Exploration. , author =. Advances in Neural Information Processing Systems , pages =
-
[73]
Learning for Dynamics and Control , pages =
Model-based reinforcement learning with value-targeted regression , author =. Learning for Dynamics and Control , pages =
-
[74]
Machine learning , publisher =
Linear least-squares algorithms for temporal difference learning , author =. Machine learning , publisher =
-
[75]
International Conference on Machine Learning , pages =
Provably efficient reinforcement learning for discounted mdps with feature mapping , author =. International Conference on Machine Learning , pages =
-
[76]
International Conference on Machine Learning , pages =
Logarithmic regret for reinforcement learning with linear function approximation , author =. International Conference on Machine Learning , pages =
-
[77]
Algorithmic Learning Theory , pages =
Exponential lower bounds for planning in mdps with linearly-realizable optimal action-value functions , author =. Algorithmic Learning Theory , pages =
-
[78]
Reinforcement Learning with General Value Function Approximation: Provably Efficient Approach via Bounded Eluder Dimension , author =
-
[79]
International Conference on Machine Learning , pages =
Provably efficient exploration in policy optimization , author =. International Conference on Machine Learning , pages =
-
[80]
8th International Conference on Learning Representations,
Is a Good Representation Sufficient for Sample Efficient Reinforcement Learning? , author =. 8th International Conference on Learning Representations,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.