Nonlinear Estimator: Dual Bayesian Affine Estimators for Parameter Learning
Pith reviewed 2026-06-27 17:32 UTC · model grok-4.3
The pith
Coupling two affine MMSE estimators in a fixed-point loop yields a nonlinear parameter estimator with the lowest error for Wiener-type state-space models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
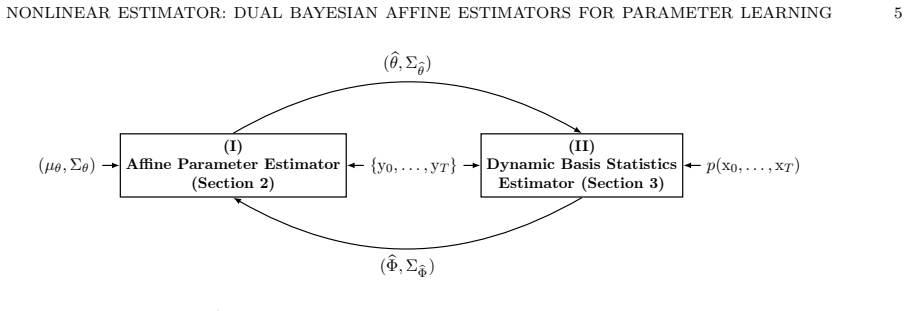
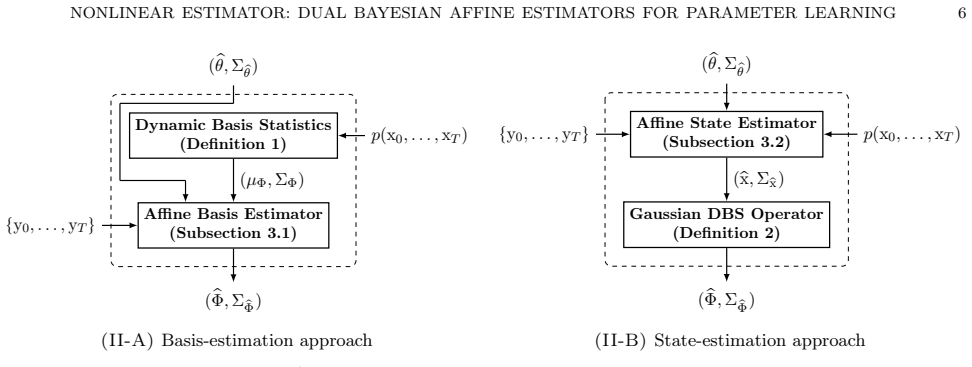
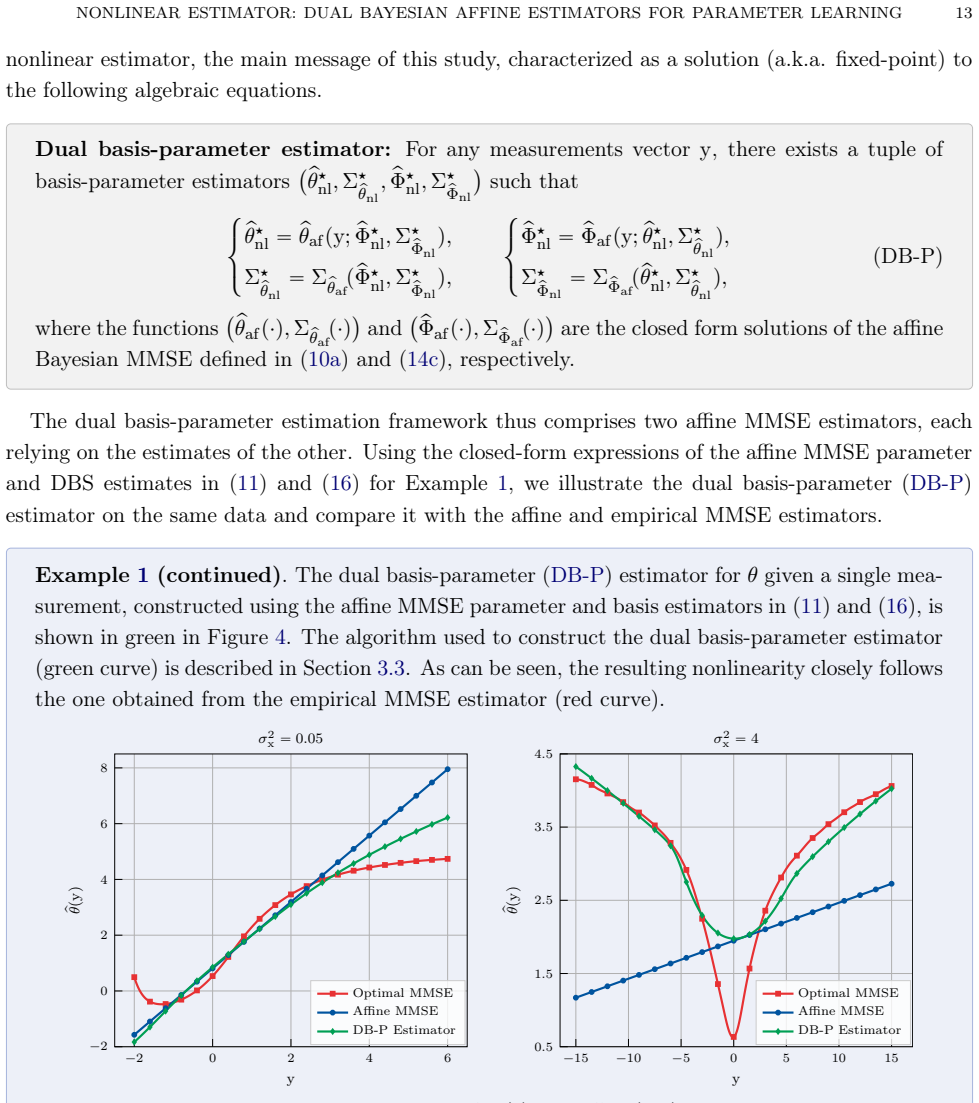
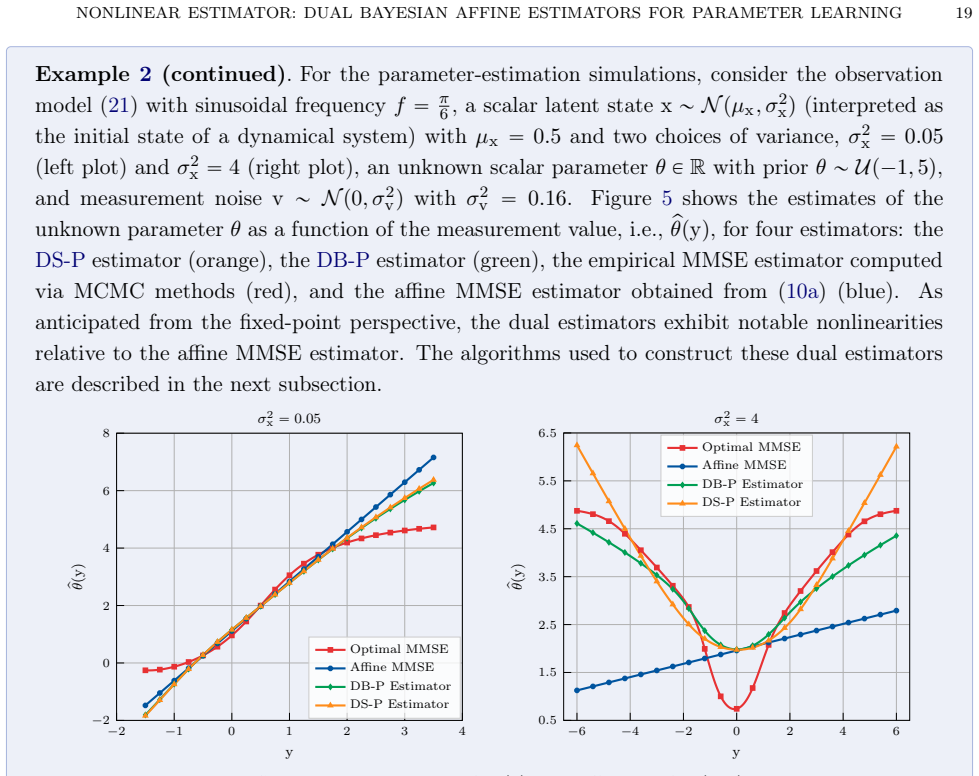
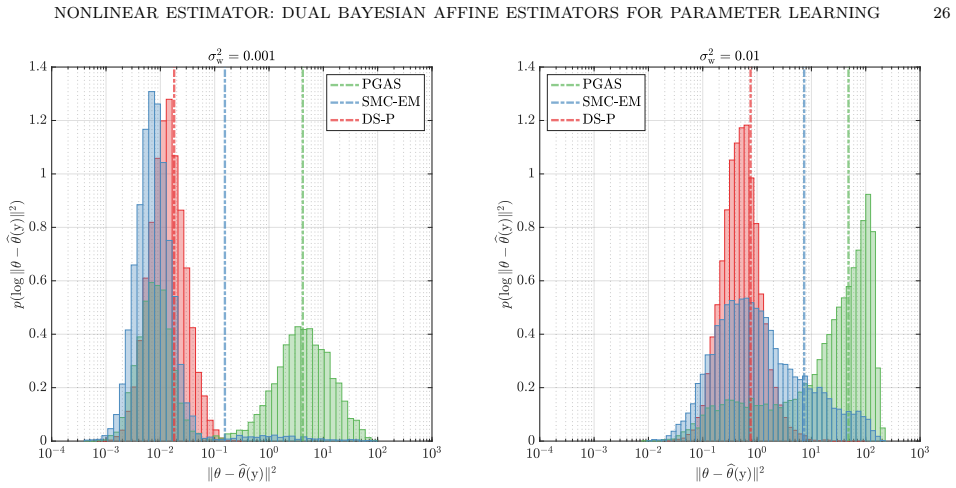
The dual state-parameter estimator achieves the lowest parameter mean-squared error by first computing affine state estimates and their covariances, mapping these through a Gaussian Dynamic Basis Statistics operator, and then alternating with the affine parameter estimator in a fixed-point iteration that uses plug-in statistics from the previous iteration; this performance is superior to that of the dual basis-parameter estimator, the purely affine parameter estimator, and sequential Monte Carlo variants of Particle Gibbs and Expectation-Maximization schemes.
What carries the argument
The fixed-point architecture coupling an affine minimum mean-squared error estimator for parameters with one for latent variables via Dynamic Basis Statistics estimates that summarize nonlinear basis-function evaluations.
If this is right
- The dual state-parameter estimator attains lower parameter mean-squared error than the dual basis-parameter estimator.
- The dual state-parameter estimator attains lower parameter mean-squared error than the purely affine parameter estimator.
- The dual state-parameter estimator attains lower parameter mean-squared error than sequential Monte Carlo variants of Particle Gibbs and Expectation-Maximization.
- Both the dual basis-parameter and dual state-parameter estimators admit fixed-point characterizations that alternate between the two components.
Where Pith is reading between the lines
- The fixed-point method could be applied to parameter estimation in other nonlinear state-space model classes.
- Improved parameter accuracy may enhance performance in related tasks such as state filtering or prediction.
- Convergence properties of the iterations could be analyzed to determine conditions for guaranteed improvement.
- The approach offers a deterministic alternative that may scale better than particle methods for large data sets.
Load-bearing premise
The fixed-point iterations that alternate between the two affine estimators using plug-in statistics from the previous iteration converge to a useful solution that improves upon the purely affine estimator.
What would settle it
Monte Carlo experiments on Wiener-type state-space models in which the dual state-parameter estimator does not achieve the lowest parameter mean-squared error compared to the dual basis-parameter estimator, the purely affine estimator, and the particle-based methods.
Figures
read the original abstract
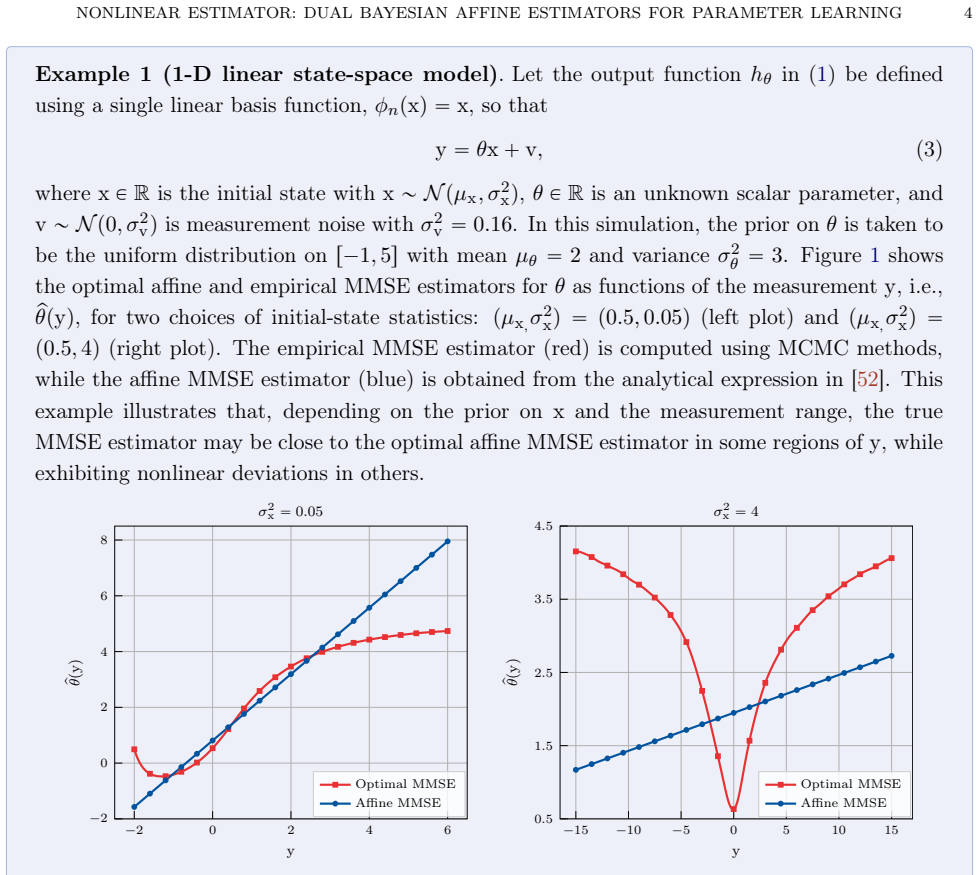
This paper presents a nonlinear parameter estimator for Wiener-type state-space models obtained as a fixed-point architecture that couples two affine minimum mean-squared error (MMSE) estimators: one for the unknown parameters and one for latent variables. The architecture retains the functional structure of the optimal affine MMSE parameter estimator while incorporating Dynamic Basis Statistics (DBS) estimates that summarize nonlinear basis-function evaluations. Two DBS construction strategies are developed, leading to two nonlinear estimator frameworks. The dual basis-parameter estimator combines an affine basis estimator with the affine parameter estimator, whereas the dual state-parameter estimator first computes affine state estimates and their covariances, then maps these state-estimate statistics through a Gaussian DBS operator to obtain DBS estimates. Both dual estimators admit fixed-point characterizations that alternate between estimating each component using the updated prior of the other, obtained from that component's plug-in estimate statistics from the previous iteration. The efficacy of the proposed methods is examined via extensive Monte Carlo experiments, showing that the dual basis-parameter estimator attains parameter mean-squared errors comparable to those of the purely affine parameter estimator, while the dual state-parameter estimator achieves the lowest parameter mean-squared error, outperforming both the dual basis-parameter and purely affine parameter estimators, as well as sequential Monte Carlo variants of classical Particle Gibbs and Expectation-Maximization schemes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
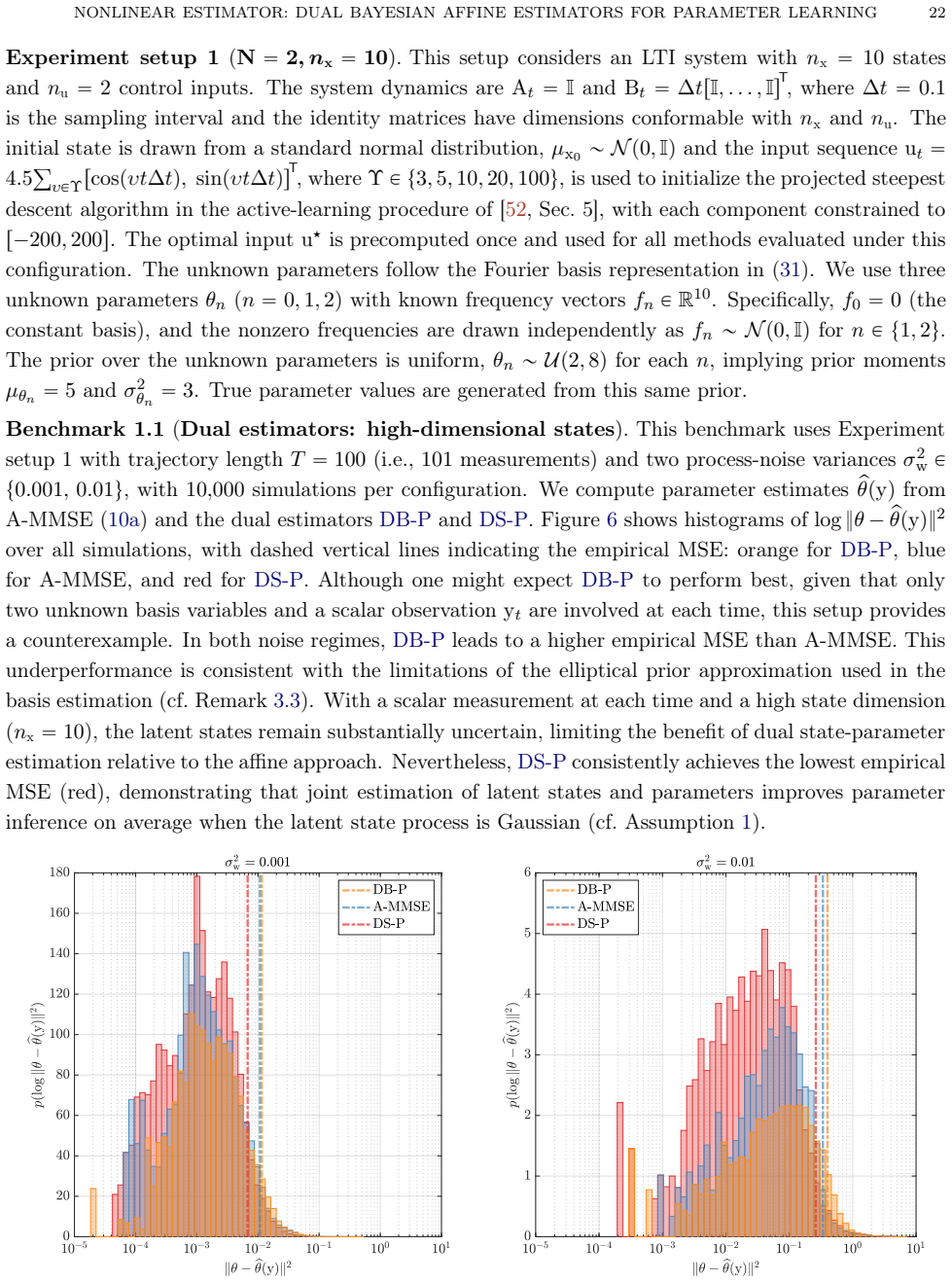
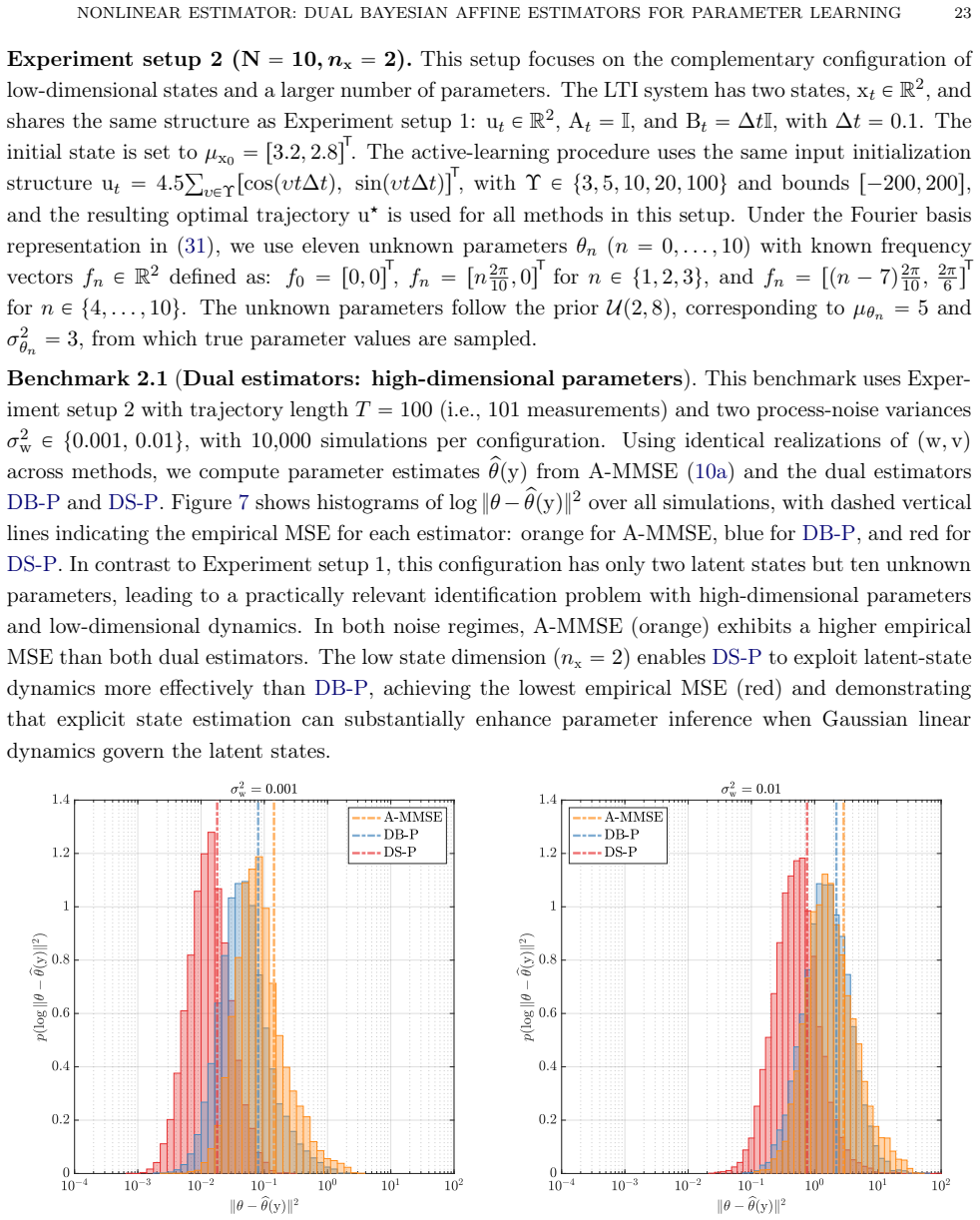
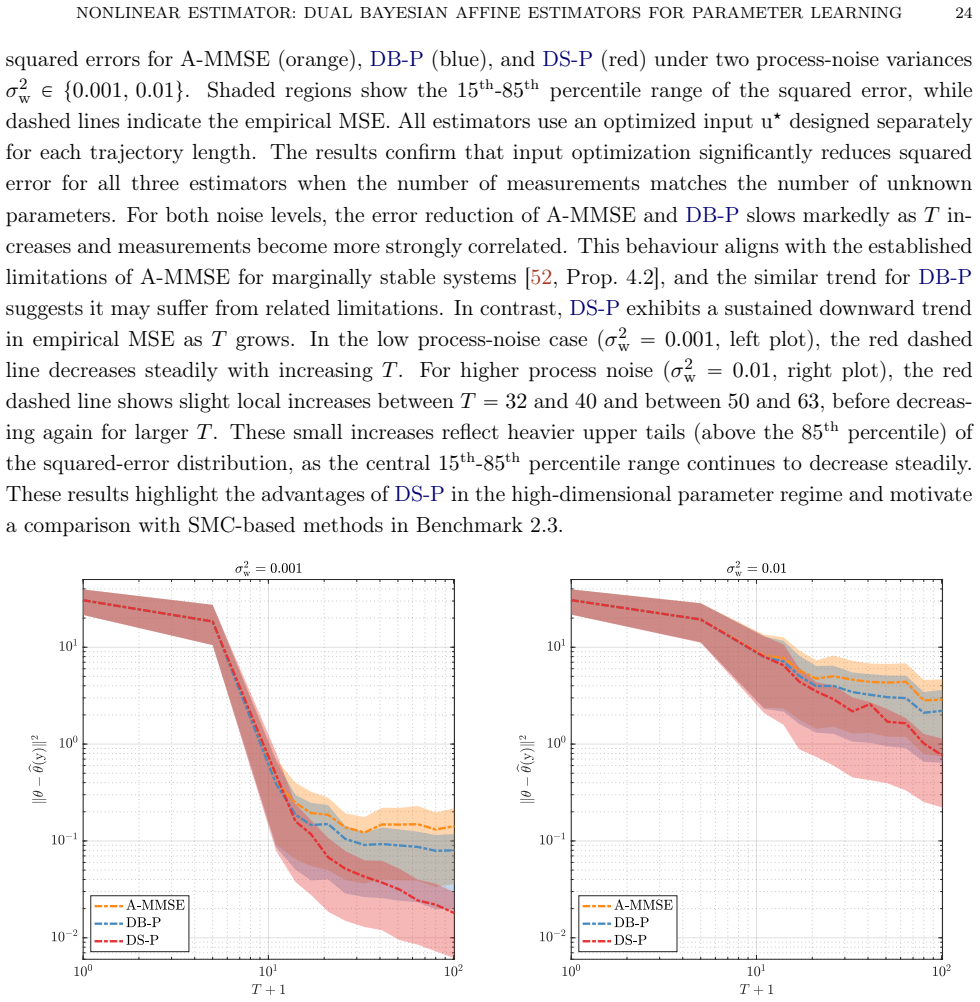
Summary. The manuscript proposes nonlinear parameter estimators for Wiener-type state-space models constructed by coupling two affine MMSE estimators (one for parameters, one for latent states or basis functions) through Dynamic Basis Statistics (DBS) operators. Two frameworks are developed: the dual basis-parameter estimator and the dual state-parameter estimator. Both are realized via fixed-point iterations that alternate between the component estimators using plug-in statistics from the prior iterate. Monte Carlo experiments are reported to show that the dual state-parameter estimator attains the lowest parameter mean-squared error, outperforming the dual basis-parameter estimator, the purely affine parameter estimator, and SMC variants of Particle Gibbs and EM.
Significance. If the fixed-point iterations are shown to converge reliably to points that improve upon the affine baseline, the approach could supply an efficient nonlinear estimator that reuses existing affine MMSE components rather than requiring full particle methods. The reported empirical ordering is potentially useful for parameter learning in nonlinear state-space models, but the lack of supporting analysis limits the strength of the performance claims.
major comments (2)
- [Abstract] Abstract (paragraph on fixed-point characterizations): The central empirical claim—that the dual state-parameter estimator achieves the lowest parameter MSE—rests on fixed-point iterations that alternate between the affine state and parameter estimators using plug-in DBS statistics from the previous iterate. No contraction argument, Lyapunov function, convergence rate, or even empirical diagnostics (e.g., iteration trajectories or stability checks) are supplied to establish that the map reaches a useful fixed point that improves on the purely affine estimator. Without such analysis the reported Monte Carlo superiority cannot be guaranteed to follow from the stated procedure.
- [Monte Carlo experiments] Monte Carlo experiments section: The performance ordering is supported only by Monte Carlo experiments whose details (number of trials, data-generation parameters, error-bar reporting, and exclusion criteria) are not fully specified. This makes it impossible to assess whether the observed advantage of the dual state-parameter estimator is robust or sensitive to implementation choices in the fixed-point loop.
minor comments (2)
- The definition and construction of the DBS operators (both strategies) should be stated with explicit equations early in the manuscript so that the plug-in usage in the fixed-point iterations is immediately verifiable.
- Notation for the two dual estimators and the Gaussian DBS operator should be made consistent between the abstract and the main text to avoid reader confusion.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on convergence and experimental reproducibility. We address each major point below and commit to revisions that strengthen the presentation without altering the core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract (paragraph on fixed-point characterizations): The central empirical claim—that the dual state-parameter estimator achieves the lowest parameter MSE—rests on fixed-point iterations that alternate between the affine state and parameter estimators using plug-in DBS statistics from the previous iterate. No contraction argument, Lyapunov function, convergence rate, or even empirical diagnostics (e.g., iteration trajectories or stability checks) are supplied to establish that the map reaches a useful fixed point that improves on the purely affine estimator. Without such analysis the reported Monte Carlo superiority cannot be guaranteed to follow from the stated procedure.
Authors: We agree that the manuscript provides no theoretical convergence analysis (contraction mapping, Lyapunov function, or rate) for the fixed-point iteration. The iteration is constructed by alternating the two affine MMSE estimators with plug-in DBS statistics from the prior iterate, which preserves the optimality of each component under the current statistics. To strengthen the empirical claim, we will add iteration-trajectory plots and stability checks across random initializations in the revised Monte Carlo section. These diagnostics will show rapid convergence to points that improve on the affine baseline. A full contraction argument would require additional model assumptions and is beyond the present scope. revision: partial
-
Referee: [Monte Carlo experiments] Monte Carlo experiments section: The performance ordering is supported only by Monte Carlo experiments whose details (number of trials, data-generation parameters, error-bar reporting, and exclusion criteria) are not fully specified. This makes it impossible to assess whether the observed advantage of the dual state-parameter estimator is robust or sensitive to implementation choices in the fixed-point loop.
Authors: We acknowledge that the experimental protocol was not described at the required level of detail. In the revision we will explicitly state: 500 independent Monte Carlo trials, the precise Wiener-model parameters (nonlinearity, process and measurement noise variances, basis-function dimension), reporting of mean and standard-deviation error bars across trials, and confirmation that no trials were excluded on the basis of convergence failure. These additions will permit direct assessment of robustness to the fixed-point implementation. revision: yes
Circularity Check
No circularity: construction and empirical comparison are independent of target quantities.
full rationale
The paper defines the dual estimators explicitly as fixed-point couplings of standard affine MMSE estimators with newly introduced DBS operators; the fixed-point characterization is a definitional property of the iteration, not a reduction of the performance claim. Parameter MSE superiority is asserted only via Monte Carlo comparison against Particle Gibbs, EM, and purely affine baselines, with no equations that fit parameters to the target MSE or rename fitted statistics as predictions. No self-citation load-bearing steps, uniqueness theorems, or ansatz smuggling appear in the provided derivation chain. The architecture is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Affine MMSE estimators are optimal under the linear-Gaussian assumptions implicit in the Wiener model components
invented entities (1)
-
Dynamic Basis Statistics (DBS)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Particle Markov chain Monte Carlo methods.Journal of the Royal Statistical Society Series B: Statistical Methodology, 72:269–342, 2010
Christophe Andrieu, Arnaud Doucet, and Roman Holenstein. Particle Markov chain Monte Carlo methods.Journal of the Royal Statistical Society Series B: Statistical Methodology, 72:269–342, 2010
2010
-
[2]
Wainwright, and Bin Yu
Sivaraman Balakrishnan, Martin J. Wainwright, and Bin Yu. Statistical guarantees for the EM algorithm: From population to sample-based analysis.The Annals of Statistics, 45:77–120, 2017
2017
-
[3]
On Markov chain Monte Carlo methods for tall data.Journal of Machine Learning Research, 18:1–43, 2017
Rémi Bardenet, Arnaud Doucet, and Chris Holmes. On Markov chain Monte Carlo methods for tall data.Journal of Machine Learning Research, 18:1–43, 2017
2017
-
[4]
Bauschke and Patrick L
Heinz H. Bauschke and Patrick L. Combettes.Convex Analysis and Monotone Operator Theory in Hilbert Spaces. Springer, Cham, 2nd edition, 2017
2017
-
[5]
Beal and Zoubin Ghahramani
Matthew J. Beal and Zoubin Ghahramani. The variational Bayesian EM algorithm for incomplete data: with application to scoring graphical model structures.Bayesian Statistics, 7:453–463, 2003
2003
-
[6]
Curse-of-dimensionality revisited: Collapse of the particle filter in very large scale systems
Thomas Bengtsson, Peter Bickel, and Bo Li. Curse-of-dimensionality revisited: Collapse of the particle filter in very large scale systems. InProbability and Statistics: Essays in Honor of David A. Freedman, pages 316–335. Institute of Mathematical Statistics, 2008
2008
-
[7]
Bishop.Pattern Recognition and Machine Learning
Christopher M. Bishop.Pattern Recognition and Machine Learning. Springer, 2006. NONLINEAR ESTIMATOR: DUAL BAYESIAN AFFINE ESTIMATORS FOR PARAMETER LEARNING 31
2006
-
[8]
Blei, Alp Kucukelbir, and Jon D
David M. Blei, Alp Kucukelbir, and Jon D. McAuliffe. Variational inference: A review for statisticians.Journal of the American statistical Association, 112:859–877, 2017
2017
-
[9]
Improved particle approximations to the joint smoothing distribution using Markov chain Monte Carlo.IEEE Transactions on Signal Processing, 61:956–963, 2012
Pete Bunch and Simon Godsill. Improved particle approximations to the joint smoothing distribution using Markov chain Monte Carlo.IEEE Transactions on Signal Processing, 61:956–963, 2012
2012
-
[10]
Burden and J
Richard L. Burden and J. Douglas Faires.Numerical Analysis. Brooks/Cole, 9th edition, 2010
2010
-
[11]
Springer, 2005
Olivier Cappé, Eric Moulines, and Tobias Rydén.Inference in Hidden Markov Models. Springer, 2005
2005
-
[12]
Carlin and Thomas A
Bradley P. Carlin and Thomas A. Louis.Bayes and Empirical Bayes Methods for Data Analysis. Chapman and Hall/CRC, 2nd edition, 2000
2000
-
[13]
Carlton and Jay L
Matthew A. Carlton and Jay L. Devore.Probability with Applications in Engineering, Science, and Technology. Springer, 2017
2017
-
[14]
Springer International Publishing, 2020
Nicolas Chopin and Omiros Papaspiliopoulos.An Introduction to Sequential Monte Carlo. Springer International Publishing, 2020
2020
-
[15]
Nicolas Chopin and Sumeetpal S. Singh. On particle Gibbs sampling.Bernoulli, 21:1855–1883, 2015
2015
-
[16]
Wills, Thomas B
Jarrad Courts, Adrian G. Wills, Thomas B. Schön, and Brett Ninness. Variational system identification for nonlinear state-space models.Automatica, 147:110687, 2023
2023
-
[17]
On backward smoothing algorithms.The Annals of Statistics, 51:2145—-2169, 2023
Hai-Dang Dau and Nicolas Chopin. On backward smoothing algorithms.The Annals of Statistics, 51:2145—-2169, 2023
2023
-
[18]
Convergence of a stochastic approximation version of the EM algorithm.The Annals of Statistics, 27:94–128, 1999
Bernard Delyon, Marc Lavielle, and Eric Moulines. Convergence of a stochastic approximation version of the EM algorithm.The Annals of Statistics, 27:94–128, 1999
1999
-
[19]
Dempster, Nan M
Arthur P. Dempster, Nan M. Laird, and Donald B. Rubin. Maximum likelihood from incomplete data via the EM algorithm.Journal of the Royal Statistical Society: Series B (Methodological), 39:1–38, 1977
1977
-
[20]
Springer, 2001
Arnaud Doucet, Nando De Freitas, and Neil Gordon.Sequential Monte Carlo Methods in Practice. Springer, 2001
2001
-
[21]
On sequential Monte Carlo sampling methods for Bayesian filtering.Statistics and Computing, 10:197–208, 2000
Arnaud Doucet, Simon Godsill, and Christophe Andrieu. On sequential Monte Carlo sampling methods for Bayesian filtering.Statistics and Computing, 10:197–208, 2000
2000
-
[22]
Hidden Markov processes.IEEE Transactions on Information Theory, 48:1518– 1569, 2002
Yariv Ephraim and Neri Merhav. Hidden Markov processes.IEEE Transactions on Information Theory, 48:1518– 1569, 2002
2002
-
[23]
Lower and upper bounds on the minimum mean-square error in composite source signal estimation.IEEE transactions on Information Theory, 38:1709–1724, 2002
Yariv Ephraim and Neri Merhav. Lower and upper bounds on the minimum mean-square error in composite source signal estimation.IEEE transactions on Information Theory, 38:1709–1724, 2002
2002
-
[24]
Bayesian system ID: optimal management of parameter, model, and measurement uncertainty.Nonlinear Dynamics, 102:241–267, 2020
Nicholas Galioto and Alex Arkady Gorodetsky. Bayesian system ID: optimal management of parameter, model, and measurement uncertainty.Nonlinear Dynamics, 102:241–267, 2020
2020
-
[25]
Gelfand and Adrian F
Alan E. Gelfand and Adrian F. M. Smith. Sampling-based approaches to calculating marginal densities.Journal of the American Statistical Association, 85:398–409, 1990
1990
-
[26]
Carlin, Hal S
Andrew Gelman, John B. Carlin, Hal S. Stern, David B. Dunson, Aki Vehtari, and Donald B. Rubin.Bayesian Data Analysis. CRC Press, 3rd edition, 2013
2013
-
[27]
Parameter estimation for linear dynamical systems.Technical Report, University of Toronto:CRG–TR–96–2, 1996
Zoubin Ghahramani and Geoffrey E Hinton. Parameter estimation for linear dynamical systems.Technical Report, University of Toronto:CRG–TR–96–2, 1996
1996
-
[28]
Godsill, Arnaud Doucet, and Mike West
Simon J. Godsill, Arnaud Doucet, and Mike West. Monte Carlo smoothing for nonlinear time series.Journal of the American Statistical Association, 99:156–168, 2004
2004
-
[29]
Keith Hastings
W. Keith Hastings. Monte Carlo sampling methods using Markov chains and their applications.Biometrika, 57:97– 109, 1970
1970
-
[30]
John Wiley & Sons, 2004
Simon Haykin.Kalman Filtering and Neural Networks. John Wiley & Sons, 2004
2004
-
[31]
Stein’s lemma for elliptical random vectors.Journal of Multivariate Analysis, 99:912–927, 2008
Zinoviy Landsman and Johanna Nešlehová. Stein’s lemma for elliptical random vectors.Journal of Multivariate Analysis, 99:912–927, 2008
2008
-
[32]
Levy.Principles of Signal Detection and Parameter Estimation
Bernard C. Levy.Principles of Signal Detection and Parameter Estimation. Springer, 2008
2008
-
[33]
Yifang Li and Sujit K. Ghosh. Efficient sampling methods for truncated multivariate Normal and Student-t distri- butions subject to linear inequality constraints.Journal of Statistical Theory and Practice, 9:712–732, 2015
2015
-
[34]
An efficient stochastic approximation EM algorithm using conditional particle filters
Fredrik Lindsten. An efficient stochastic approximation EM algorithm using conditional particle filters. InIEEE International Conference on Acoustics, Speech and Signal Processing, pages 6274–6278, 2013
2013
-
[35]
Jordan, and Thomas B
Fredrik Lindsten, Michael I. Jordan, and Thomas B. Schön. Particle Gibbs with ancestor sampling.Journal of Machine Learning Research, 15:2145–2184, 2014. NONLINEAR ESTIMATOR: DUAL BAYESIAN AFFINE ESTIMATORS FOR PARAMETER LEARNING 32
2014
-
[36]
Jun S. Liu. Siegel’s formula via Stein’s identities.Statistics & Probability Letters, 21:247–251, 1994
1994
-
[37]
Prentice Hall PTR, 2nd edition, 1999
Lennart Ljung.System Identification: Theory for the User. Prentice Hall PTR, 2nd edition, 1999
1999
-
[38]
David J. C. MacKay.Information Theory, Inference and Learning Algorithms. Cambridge University Press, 2003
2003
-
[39]
Rosenbluth, Marshall N
Nicholas Metropolis, Arianna W. Rosenbluth, Marshall N. Rosenbluth, Augusta H. Teller, and Edward Teller. Equation of state calculations by fast computing machines.The Journal of Chemical Physics, 21:1087–1092, 1953
1953
-
[40]
The Fubini theorem
Jan Mikusiński. The Fubini theorem. InThe Bochner Integral, pages 91–105. Springer, 1978
1978
-
[41]
Nested sequential Monte Carlo methods
Christian Naesseth, Fredrik Lindsten, and Thomas Schön. Nested sequential Monte Carlo methods. InInternational Conference on Machine Learning, pages 1292–1301, 2015
2015
-
[42]
Naesseth, Fredrik Lindsten, and Thomas B
Christian A. Naesseth, Fredrik Lindsten, and Thomas B. Schön. Elements of sequential Monte Carlo.Foundations and Trends in Machine Learning, 12:307–392, 2019
2019
-
[43]
Pitt, Ralph dos Santos Silva, Paolo Giordani, and Robert Kohn
Michael K. Pitt, Ralph dos Santos Silva, Paolo Giordani, and Robert Kohn. On some properties of Markov chain Monte Carlo simulation methods based on the particle filter.Journal of Econometrics, 171:134–151, 2012
2012
-
[44]
Bala Rajaratnam and Doug Sparks. MCMC-based inference in the era of big data: A fundamental analysis of the convergence complexity of high-dimensional chains.arXiv preprint arXiv:1508.00947, 2015
Pith/arXiv arXiv 2015
-
[45]
Robert and George Casella.Monte Carlo Statistical Methods
Christian P. Robert and George Casella.Monte Carlo Statistical Methods. Springer, 2nd edition, 2004
2004
-
[46]
Roberts and Jeffrey S
Gareth O. Roberts and Jeffrey S. Rosenthal. General state space Markov chains and MCMC algorithms.Probability Surveys, 1:20–71, 2004
2004
-
[47]
Cambridge University Press, 2013
Simo Särkkä.Bayesian Filtering and Smoothing. Cambridge University Press, 2013
2013
-
[48]
Schön, Adrian Wills, and Brett Ninness
Thomas B. Schön, Adrian Wills, and Brett Ninness. System identification of nonlinear state-space models.Auto- matica, 47:39–49, 2011
2011
-
[49]
Identification of block-oriented nonlinear systems starting from linear approxi- mations: A survey.Automatica, 85:272–292, 2017
Maarten Schoukens and Koen Tiels. Identification of block-oriented nonlinear systems starting from linear approxi- mations: A survey.Automatica, 85:272–292, 2017
2017
-
[50]
Charles M. Stein. Estimation of the mean of a multivariate Normal distribution.The Annals of Statistics, 9:1135– 1151, 1981
1981
-
[51]
Tokdar and Robert E
Surya T. Tokdar and Robert E. Kass. Importance sampling: A review.Wiley Interdisciplinary Reviews: Computa- tional Statistics, 2:54–60, 2010
2010
-
[52]
Sasan Vakili, Manuel Mazo Jr, and Peyman Mohajerin Esfahani. Optimal Bayesian affine estimator and active learning for the Wiener model.arXiv preprint arXiv:2504.05490, 2025
arXiv 2025
-
[53]
Dual Kalman filtering methods for nonlinear prediction, smoothing and estimation
Eric Wan and Alex Nelson. Dual Kalman filtering methods for nonlinear prediction, smoothing and estimation. In Advances in Neural Information Processing Systems, volume 9, pages 793–799, 1996
1996
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.