Eywa: Provenance-Grounded Long-Term Memory for AI Agents
Pith reviewed 2026-06-28 23:12 UTC · model grok-4.3
The pith
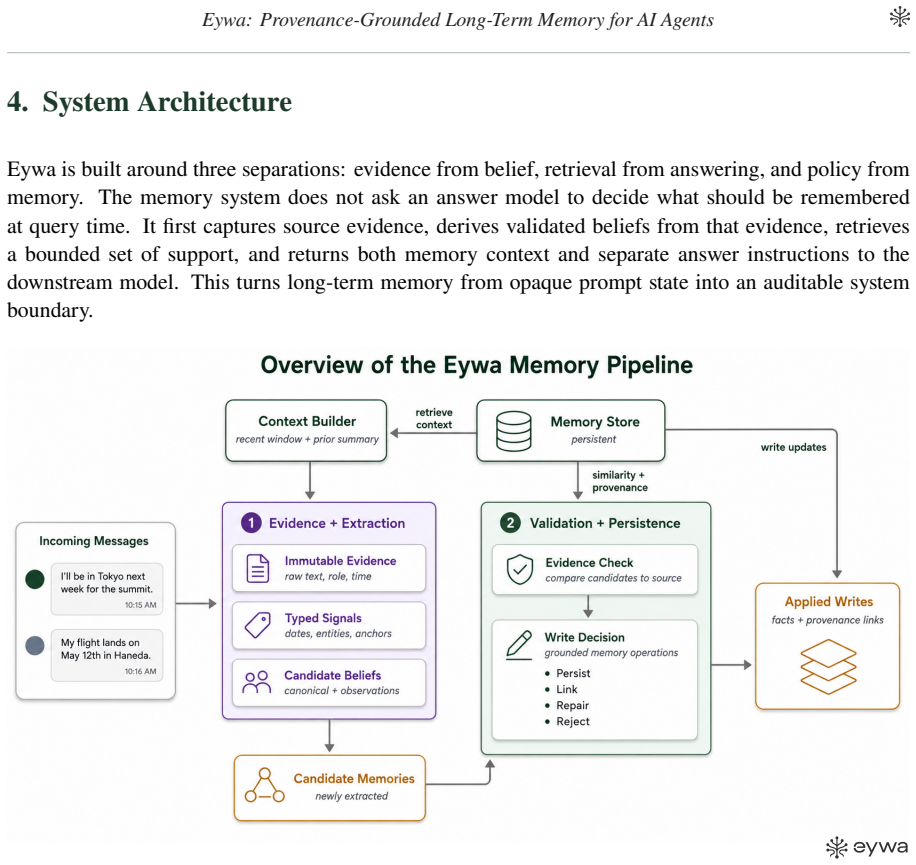
Eywa stores immutable source evidence before deriving facts to enable auditable, deterministic retrieval for persistent AI agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
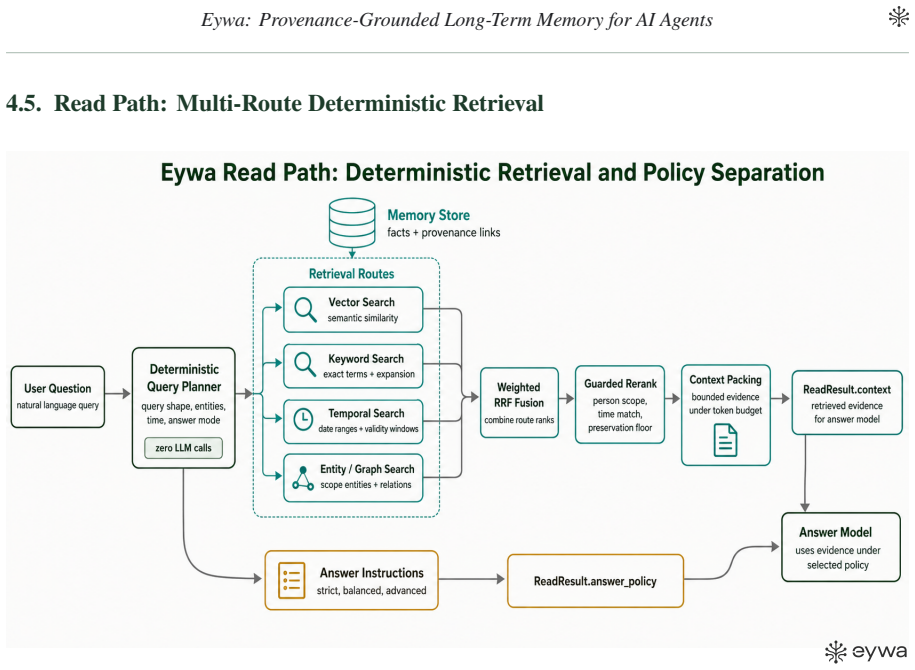
Eywa stores immutable source evidence before deriving canonical facts, validates extracted memories against typed signals and source support, and retrieves bounded memory context through a deterministic multi-route read path with zero LLM calls inside retrieval. Retrieved context is returned separately from answer instructions, allowing the same memory substrate to be evaluated across frontier, budget, and local answer models.
What carries the argument
Provenance-grounded memory architecture that stores immutable source evidence before belief and performs deterministic multi-route retrieval without LLM calls.
If this is right
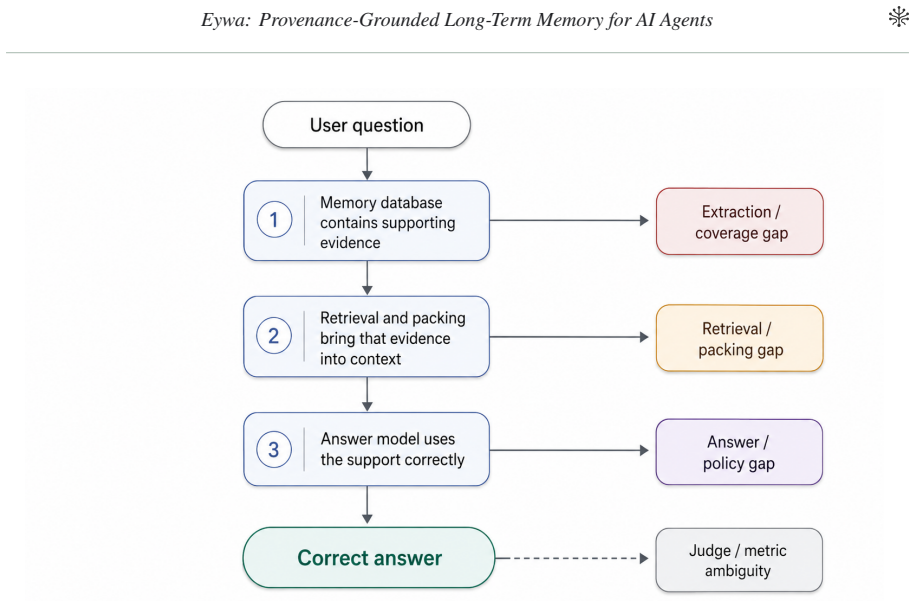
- Answer failures can be traced to specific stages: missing evidence, unsupported extraction, stale state, retrieval loss, or answer-model behavior.
- The memory substrate can be swapped across different answer models without retraining or reconfiguring retrieval.
- Full per-question artifacts including questions, gold answers, model answers, retrieved context, and labels are published for independent verification.
- Bounded context retrieval keeps memory usage predictable even as the agent accumulates long-term data.
Where Pith is reading between the lines
- The separation of evidence, facts, and retrieval paths could make memory easier to audit in settings that require regulatory compliance or error tracing.
- Deterministic retrieval without LLM calls inside the read path may reduce variability compared with retrieval methods that rely on model sampling at query time.
- The same architecture could be tested on additional long-horizon agent tasks beyond the reported benchmarks to check whether the accuracy numbers generalize.
Load-bearing premise
The chosen benchmarks and judge-based accuracy metrics accurately reflect real-world long-term memory performance and failure modes for AI agents in open-ended use.
What would settle it
A new test set or open-ended agent scenario in which Eywa's high benchmark scores fail to produce correct answers because of unmodeled issues such as stale evidence, unsupported policy decisions, or retrieval loss not captured by the existing judge metrics.
Figures
read the original abstract
AI agents that persist across sessions need memory they can retrieve, audit, update, and erase. Existing memory systems often collapse source evidence, extracted facts, retrieved context, and answer policy into one opaque prompt path, making failures difficult to diagnose: a wrong answer may come from missing evidence, unsupported extraction, stale state, retrieval loss, or answer-model behavior. We present Eywa, a provenance-grounded memory architecture built around evidence before belief. Eywa stores immutable source evidence before deriving canonical facts, validates extracted memories against typed signals and source support, and retrieves bounded memory context through a deterministic multi-route read path with zero LLM calls inside retrieval. Retrieved context is returned separately from answer instructions, allowing the same memory substrate to be evaluated across frontier, budget, and local answer models. Under a frozen, artifact-recorded retrieval configuration, Eywa reaches 90.19% judge accuracy on the LoCoMo C1-C4 split with Claude Sonnet 4.6 write and QA roles. On LongMemEval-S, it reaches 88.2% retrieval-sufficiency accuracy. On BEAM, a 700-question technical-memory stress benchmark, it reaches 81.45% mean nugget score and 85.29% pass@score >= 0.5. Full per-question artifacts, including questions, gold answers, model answers, retrieved context, and labels, are published at https://eywa.to/research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Eywa, a provenance-grounded memory architecture for persistent AI agents. It stores immutable source evidence prior to deriving canonical facts, applies typed validation against source support, and performs retrieval via a deterministic multi-route path containing zero LLM calls. Retrieved context is returned separately from answer instructions to support cross-model evaluation. Under a frozen, artifact-recorded configuration, the system reports 90.19% judge accuracy on the LoCoMo C1-C4 split (Claude Sonnet 4.6 write/QA roles), 88.2% retrieval-sufficiency accuracy on LongMemEval-S, and 81.45% mean nugget score with 85.29% pass@score >= 0.5 on the BEAM benchmark; full per-question artifacts are published.
Significance. If the reported results hold under the stated frozen configuration, the work offers a verifiable, auditable approach to long-term memory that separates the memory substrate from answer-model behavior and enables diagnosis of failure modes (missing evidence vs. retrieval loss vs. answer policy). The explicit publication of per-question artifacts (questions, gold answers, retrieved context, labels) is a clear strength for reproducibility and external verification. The architecture's design directly addresses the opacity problem identified in existing systems.
minor comments (3)
- The abstract and evaluation sections should explicitly state the exact model versions, temperature settings, and prompt templates used for the write and QA roles on LoCoMo to allow exact reproduction of the 90.19% figure.
- Figure or table presenting the multi-route retrieval paths would benefit from a diagram showing the deterministic routing logic and how zero-LLM calls are enforced at each step.
- The BEAM benchmark description should include a brief characterization of question types and why the 700-question set constitutes a 'technical-memory stress' test, to strengthen the claim that the 81.45% nugget score generalizes.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation, the emphasis on reproducibility through published artifacts, and the recommendation of minor revision. No major comments were raised in the report.
Circularity Check
No significant circularity
full rationale
The paper describes an implemented provenance-grounded memory architecture and reports empirical results on external benchmarks (LoCoMo, LongMemEval-S, BEAM) with published per-question artifacts. No equations, derivations, fitted parameters, uniqueness theorems, or self-citation chains appear in the provided text or abstract. The architecture is presented as a concrete system whose retrieval path is deterministic and zero-LLM, with performance measured against independent judge models and gold labels; the evaluation does not reduce to self-definition or renaming of inputs.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Eywa provenance-grounded memory architecture
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Storage Is Not Memory: A Retrieval-Centered Architecture for Agent Recall
Joshua Adler and Guy Zehavi. Storage is not memory: A retrieval-centered architecture for agent recall. arXivpreprint,2026. doi:10.48550/arXiv.2605.04897. URLhttps://arxiv.org/abs/2605. 04897. Susan Bluck, Nicole Alea, Tilmann Habermas, and David C. Rubin. A TALE of three functions: The self-reported uses of autobiographical memory.Social Cognition, 23(1):91–117,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2605.04897 2026
-
[2]
URLhttps://doi.org/10.1521/soco.23.1.91.59198
doi: 10.1521/soco.23.1.91.59198. URLhttps://doi.org/10.1521/soco.23.1.91.59198. Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. Mem0: Building production-ready AI agents with scalable long-term memory.arXiv preprint,
-
[3]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
doi:10.48550/ arXiv.2504.19413. URLhttps://arxiv.org/abs/2504.19413. Herbert H. Clark and Susan E. Brennan. Grounding in communication. In Lauren B. Resnick, John M. Levine, andStephanieD.Teasley, editors,PerspectivesonSociallySharedCognition, pages127–149. 25 Eywa: Provenance-Grounded Long-Term Memory for AI Agents American Psychological Association, Was...
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
URL https://doi.org/10.1037/10096-006
doi:10.1037/10096-006. URL https://doi.org/10.1037/10096-006. MartinA.ConwayandChristopherW.Pleydell-Pearce. Theconstructionofautobiographicalmemories intheself-memorysystem.PsychologicalReview,107(2):261–288,2000.doi:10.1037/0033-295X. 107.2.261. URLhttps://doi.org/10.1037/0033-295X.107.2.261. Gordon V. Cormack, Charles L. A. Clarke, and Stefan Buettcher...
-
[5]
DarrenEdge,HaTrinh,NewmanCheng,JoshuaBradley,AlexChao,ApurvaMody,StevenTruitt,Dasha Metropolitansky, Robert Osazuwa Ness, and Jonathan Larson
URLhttps://papers.nips.cc/paper_files/paper/2022/hash/ 67d57c32e20fd0a7a302cb81d36e40d5-Abstract-Conference.html. DarrenEdge,HaTrinh,NewmanCheng,JoshuaBradley,AlexChao,ApurvaMody,StevenTruitt,Dasha Metropolitansky, Robert Osazuwa Ness, and Jonathan Larson. From local to global: A graph RAG approach to query-focused summarization.arXiv preprint,
2022
-
[6]
doi:10.48550/arXiv.2404. 16130. URLhttps://arxiv.org/abs/2404.16130. Gemini Team, Petko Georgiev, Ving Ian Lei, Ryan Burnell, Libin Bai, Anmol Gulati, Garrett Tanzer, Damien Vincent, Zhufeng Pan, Shibo Wang, et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context.arXiv preprint,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2404
-
[7]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
doi:10.48550/arXiv.2403.05530. URLhttps://arxiv.org/abs/2403.05530. Cheng-PingHsieh,SimengSun,SamuelKriman,ShantanuAcharya,DimaRekesh,FeiJia,YangZhang, and Boris Ginsburg. RULER: What’s the real context size of your long-context language models? InFirst Conference on Language Modeling,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2403.05530
-
[8]
RULER: What's the Real Context Size of Your Long-Context Language Models?
doi:10.48550/arXiv.2404.06654. URL https://openreview.net/forum?id=kIoBbc76Sy. Yuyang Hu, Shichun Liu, Yanwei Yue, Guibin Zhang, et al. Memory in the age of AI agents.arXiv preprint,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2404.06654
-
[9]
Memory in the Age of AI Agents
doi:10.48550/arXiv.2512.13564. URLhttps://arxiv.org/abs/2512. 13564. ZhengdingHu,ZaifengPan,PrabhleenKaur,VibhaMurthy,ZhongkaiYu,YueGuan,ZhenWang,Steven Swanson,andYufeiDing. Pancake: Hierarchicalmemorysystemformulti-agentLLMserving.arXiv preprint,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2512.13564
-
[10]
doi:10.48550/arXiv.2602.21477. URLhttps://arxiv.org/abs/2602. 21477. Bernal Jiménez Gutiérrez, Yiheng Shu, Yu Gu, Michihiro Yasunaga, and Yu Su. Hip- poRAG: Neurobiologically inspired long-term memory for large language models. InAd- vances in Neural Information Processing Systems, volume 37,
-
[11]
52202 / 079017-1902
doi:10 . 52202 / 079017-1902. URLhttps://proceedings.neurips.cc/paper_files/paper/2024/hash/ 6ddc001d07ca4f319af96a3024f6dbd1-Abstract-Conference.html. Jiazheng Kang, Mingming Ji, Zhe Zhao, and Ting Bai. Memory OS of AI agent.arXiv preprint,
1902
-
[12]
URLhttps://arxiv.org/abs/2506.06326
doi:10.48550/arXiv.2506.06326. URLhttps://arxiv.org/abs/2506.06326. LangChain. LangMem: Memory management for LLM-based agents.https : / / github . com / langchain-ai/langmem,
-
[13]
Open-source memory layer for LangGraph agents. Accessed 2026- 05-27. 26 Eywa: Provenance-Grounded Long-Term Memory for AI Agents ChrisLatimer,NicolóBoschi,AndrewNeeser,ChrisBartholomew,GauravSrivastava,XuanWang,and Naren Ramakrishnan. Hindsight is 20/20: Building agent memory that retains, recalls, and reflects. arXivpreprint,2025. doi:10.48550/arXiv.2512...
-
[14]
MemOS: A Memory OS for AI System
doi:10. 48550/arXiv.2507.03724. URLhttps://arxiv.org/abs/2507.03724. Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts.Transactions of the Association for Computational Linguistics, 12:157–173,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang
doi:10.1162/tacl_a_00638. URL https://aclanthology.org/2024.tacl-1.9/. AdyashaMaharana,Dong-HoLee,SergeyTulyakov,MohitBansal,FrancescoBarbieri,andYuweiFang. Evaluatingverylong-termconversationalmemoryofLLMagents. InProceedingsofthe62ndAnnual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13851– 13870. Association f...
-
[16]
URLhttps://aclanthology.org/2024.acl-long.747/
doi:10.18653/v1/2024.acl-long.747. URLhttps://aclanthology.org/2024.acl-long.747/. MemTensor.MemOSevaluationresults.https://huggingface.co/datasets/MemTensor/MemOS_ eval_result,2025. BenchmarkresultartifactforMemOSandcomparedmemorysystems.Accessed 2026-05-27. OpenAI. OpenAI memory.https : / / help . openai . com / en / articles / 8983136-what-is-memory,
-
[17]
Accessed 2026-05-27
ChatGPT memory help documentation. Accessed 2026-05-27. Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez. MemGPT: Towards LLMs as operating systems.arXiv preprint,
2026
-
[18]
MemGPT: Towards LLMs as Operating Systems
doi:10.48550/ arXiv.2310.08560. URLhttps://arxiv.org/abs/2310.08560. Joon Sung Park, Joseph C. O’Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. Generative agents: Interactive simulacra of human behavior. InProceedings of the 36th Annual ACM Symposium on User Interface Software and Technology, pages 1–22,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
doi: 10.1145/3586183.3606763. URLhttps://doi.org/10.1145/3586183.3606763. Preston Rasmussen, Pavlo Paliychuk, Travis Beauvais, Jack Ryan, and Daniel Chalef. Zep: A temporal knowledgegrapharchitectureforagentmemory.arXivpreprint,2025. doi:10.48550/arXiv.2501. 13956. URLhttps://arxiv.org/abs/2501.13956. Daniel L. Schacter, Donna Rose Addis, and Randy L. Buc...
-
[20]
URLhttps://doi.org/10.1038/nrn2213
doi:10.1038/ nrn2213. URLhttps://doi.org/10.1038/nrn2213. Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning.arXiv preprint,
-
[21]
Reflexion: Language Agents with Verbal Reinforcement Learning
doi: 10.48550/arXiv.2303.11366. URLhttps://arxiv.org/abs/2303.11366. 27 Eywa: Provenance-Grounded Long-Term Memory for AI Agents Supermemory. Supermemory: Memory api for ai applications.https://supermemory.ai,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.11366
-
[22]
com / supermemoryai / supermemory
Product documentation and open-source repository:https : / / github . com / supermemoryai / supermemory. Accessed 2026-05-27. Vectorize. Hindsight benchmark results.https : / / github . com / vectorize-io / hindsight-benchmarks,2025. LoCoMobenchmarkresulttablesforHindsight.Accessed2026-05-
2026
-
[23]
48550 / arXiv
doi:10 . 48550 / arXiv . 2410 . 10813. URLhttps : / / proceedings . iclr . cc / paper _ files / paper / 2025 / hash / d813d324dbf0598bbdc9c8e79740ed01-Abstract-Conference.html. Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang. A-MEM: Agentic memory for LLM agents. InAdvances in Neural Information Processing Systems,
2025
-
[24]
A-MEM: Agentic Memory for LLM Agents
doi:10. 48550/arXiv.2502.12110. URLhttps://arxiv.org/abs/2502.12110. Wanjun Zhong, Lianghong Guo, Qiqi Gao, He Ye, and Yanlin Wang. MemoryBank: Enhancing large language models with long-term memory. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 19724–19731,
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
URL https://ojs.aaai.org/index.php/AAAI/article/view/29946
doi:10.1609/aaai.v38i17.29946. URL https://ojs.aaai.org/index.php/AAAI/article/view/29946. Issue
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.