GrapNet: A Programmable Dynamic-Architecture Neural Graph Substrate
Pith reviewed 2026-06-26 21:07 UTC · model grok-4.3
The pith
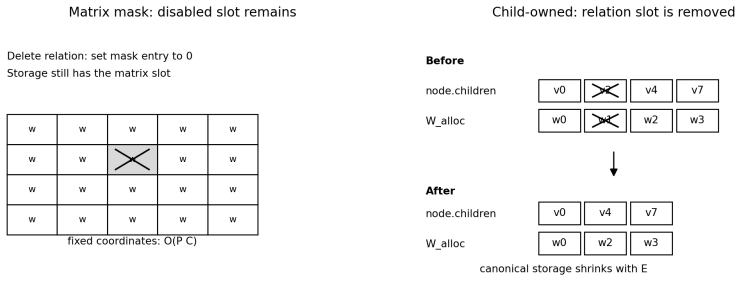
GrapNet treats the computation graph itself as an editable neural program where nodes own child references and allocation vectors so that deleting a relation removes both the link and its coordinate.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
GrapNet studies the graph-as-network setting in which the graph is the architecture and executable program. Each compute node owns its next-layer child references and a trainable allocation vector aligned with those references; deleting a relation physically removes both the child reference and the corresponding allocation coordinate. Structural rules and execution policies live outside the node core, so the same child-owned graph can be grown, frozen, structurally edited, grouped into trainable family blocks, routed by attention over active relations, or lowered to dense snapshots after topology stabilizes. GrapNet composes with conventional modules through a vector-valued parent interface.
What carries the argument
Node-owned child references paired with trainable allocation vectors, where coordinate deletion physically removes the corresponding relation.
If this is right
- A plastic GrapNet+ER head reaches 63.16 percent seen-class accuracy on Split Fashion-MNIST versus 51.08 percent for a larger dense MLP+ER under matched loss and replay memory.
- On Split CIFAR-10 with a frozen ImageNet ResNet-18 encoder the same substrate improves the online head over MLP-256 by 3.81 points.
- The substrate supports direct composition with dense layers, CNN encoders, ResNet extractors, attention blocks, and transformer representations via a vector-valued parent interface.
- Structural operations such as freezing a subgraph or changing the execution backend become native graph edits rather than parameter surgery.
Where Pith is reading between the lines
- The design could support runtime auditing of local functions by inspecting active relations without retraining the entire model.
- Attention routing over active relations may enable dynamic task-specific subgraphs that stabilize after initial growth.
- Converting stabilized topologies to dense snapshots suggests a path for deploying learned structures in resource-constrained settings while retaining editability during training.
- The same node-owned reference mechanism might generalize to other continual-learning regimes where topology changes must preserve gradient semantics.
Load-bearing premise
Coordinate deletion from the allocation vector removes the relation exactly, without hidden side effects on gradient flow or memory layout.
What would settle it
A controlled test showing that after a relation is deleted the gradient updates on the remaining connections deviate from those of an equivalent manually pruned dense network would falsify faithful execution.
Figures
read the original abstract
Programmability is a missing first-class interface in fixed-tensor neural networks: editing a relation, freezing a subgraph, auditing a local function, or changing the execution backend should be an operation on the neural program rather than ad-hoc parameter surgery. GrapNet studies this graph-as-network setting. The graph is the architecture and executable program, not an input data graph. Each compute node owns its next-layer child references and a trainable allocation vector aligned with those references; deleting a relation physically removes both the child reference and the corresponding allocation coordinate. Structural rules and execution policies live outside the node core, so the same child-owned graph can be grown, frozen, structurally edited, grouped into trainable family blocks, routed by attention over active relations, or lowered to dense snapshots after topology stabilizes. GrapNet composes with conventional modules through a vector-valued parent interface: dense layers, CNN encoders, ResNet feature extractors, attention blocks, and transformer representations can all feed one sensory GrapNode per coordinate. The evaluation is organized as a programmability stress suite rather than as a new replay benchmark. In a matched ten-seed Split Fashion-MNIST study, a plastic GrapNet+ER head reaches 63.16 percent seen-class accuracy versus 51.08 percent for a parameter-larger dense MLP+ER under the same seen-class loss and replay memory, with paired delta 12.08 points and p=1.3e-5. On Split CIFAR-10 with a frozen ImageNet ResNet-18 encoder, the same substrate improves the online head over MLP-256 by 3.81 points, with p=0.0026. These results support GrapNet as an editable neural graph substrate whose core value is structural programmability with faithful execution views.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GrapNet, a neural graph substrate in which the graph itself is the architecture and executable program. Each node owns child references and a trainable allocation vector; deleting a relation removes both the reference and the matching allocation coordinate. Structural rules and execution policies are external to the node core, enabling growth, freezing, editing, and composition with standard modules (dense layers, CNNs, ResNet, transformers). Evaluation on continual-learning splits shows a plastic GrapNet+ER head reaching 63.16% seen-class accuracy on Split Fashion-MNIST (vs. 51.08% for a larger dense MLP+ER, delta 12.08, p=1.3e-5) and a 3.81-point gain on Split CIFAR-10 with a frozen ResNet-18 encoder (p=0.0026).
Significance. If the deletion operator preserves gradient isolation, GrapNet would supply a concrete mechanism for first-class structural programmability in neural networks, with direct utility for continual learning, modular editing, and dynamic architectures. The reported matched-seed experiments with explicit p-values and replay-memory controls provide a falsifiable empirical anchor for the programmability claim.
major comments (2)
- [Abstract / §3] Abstract and §3 (architecture description): the central claim that coordinate deletion on the allocation vector 'physically removes' the relation without side effects on gradient flow is load-bearing for attributing the 12-point accuracy gain to structural editing rather than altered optimization dynamics. No derivation, isolation lemma, or post-deletion gradient-norm check is supplied to confirm that deleted coordinates contribute zero gradient or that memory layout remains consistent.
- [§4] §4 (Split Fashion-MNIST experiment): the comparison states that the dense MLP+ER baseline is 'parameter-larger' yet the GrapNet head still outperforms it; however, the paper does not report the exact parameter counts, the precise allocation-vector dimensionality at each step, or whether the MLP receives an equivalent number of active connections, making it impossible to isolate the contribution of structural programmability from capacity or regularization differences.
minor comments (2)
- [§3] Notation for the allocation vector and child-reference alignment should be introduced with an explicit equation (e.g., Eq. (X)) rather than prose only, to allow readers to verify the claimed one-to-one correspondence.
- [§4] The abstract reports ten seeds and paired p-values; the main text should include a table or appendix listing per-seed accuracies and the exact statistical test used.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the central claims and experimental controls. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract / §3] Abstract and §3 (architecture description): the central claim that coordinate deletion on the allocation vector 'physically removes' the relation without side effects on gradient flow is load-bearing for attributing the 12-point accuracy gain to structural editing rather than altered optimization dynamics. No derivation, isolation lemma, or post-deletion gradient-norm check is supplied to confirm that deleted coordinates contribute zero gradient or that memory layout remains consistent.
Authors: The deletion is realized by removing the child reference and truncating the allocation vector, which excludes those parameters from the active computation graph. We agree that the manuscript lacks an explicit isolation argument or gradient verification. In revision we will insert a short derivation in §3 establishing that deleted coordinates receive zero gradient by construction, together with post-deletion gradient-norm statistics in the appendix. revision: yes
-
Referee: [§4] §4 (Split Fashion-MNIST experiment): the comparison states that the dense MLP+ER baseline is 'parameter-larger' yet the GrapNet head still outperforms it; however, the paper does not report the exact parameter counts, the precise allocation-vector dimensionality at each step, or whether the MLP receives an equivalent number of active connections, making it impossible to isolate the contribution of structural programmability from capacity or regularization differences.
Authors: The current text only states that the MLP is parameter-larger without supplying counts or allocation sizes. We will revise §4 to include a table listing exact parameter counts for both models, the allocation-vector dimensionality after each edit, and confirmation that the MLP baseline has at least as many active parameters as the GrapNet head at every stage. revision: yes
Circularity Check
No circularity: empirical results are direct measurements, not derived predictions
full rationale
The paper introduces GrapNet as a programmable graph substrate with node-owned references and allocation vectors, then reports experimental accuracies (e.g., 63.16% vs 51.08% on Split Fashion-MNIST) as measured outcomes under matched conditions. No derivation chain, first-principles prediction, or fitted parameter is claimed to produce these numbers; the performance deltas are presented as observed results from training runs. The core mechanism (coordinate deletion removing relations) is defined directly in the architecture description without self-referential fitting or self-citation load-bearing on the empirical claims. No steps reduce by construction to inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ansel, J.; Yang, E.; He, H.; Gimelshein, N.; Jain, A.; Voznesensky, M.; Bao, B.; Bell, P.; Berard, D.; Burovski, E.; and others. 2024. PyTorch 2: Faster Machine Learning Through Dynamic Python Bytecode Transformation and Graph Compilation. In Proceedings of the 29th ACM International Conference on Architectural Support for Programming Language and Operati...
2024
-
[2]
Boschini, M.; Bonicelli, L.; Buzzega, P.; Porrello, A.; and Calderara, S. 2023. Class-Incremental Continual Learning into the eXtended DER-verse. IEEE Transactions on Pattern Analysis and Machine Intelligence
2023
-
[3]
Buzzega, P.; Boschini, M.; Porrello, A.; Abati, D.; and Calderara, S. 2020. Dark Experience for General Continual Learning: A Strong, Simple Baseline. In NeurIPS
2020
-
[4]
K.; Torr, P
Chaudhry, A.; Rohrbach, M.; Elhoseiny, M.; Ajanthan, T.; Dokania, P. K.; Torr, P. H. S.; and Ranzato, M. 2019. On Tiny Episodic Memories in Continual Learning. In ICML Workshop
2019
-
[5]
Douillard, A.; Ram \'e , A.; Couairon, G.; and Cord, M. 2022. DyTox: Transformers for Continual Learning with Dynamic Token Expansion. In CVPR
2022
-
[6]
S.; and Elsen, E
Evci, U.; Gale, T.; Menick, J.; Castro, P. S.; and Elsen, E. 2020. Rigging the Lottery: Making All Tickets Winners. In ICML
2020
-
[7]
Fey, M.; and Lenssen, J. E. 2019. Fast Graph Representation Learning with PyTorch Geometric. In ICLR Workshop on Representation Learning on Graphs and Manifolds
2019
-
[8]
Frankle, J.; and Carbin, M. 2019. The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks. In ICLR
2019
-
[9]
He, K.; Zhang, X.; Ren, S.; and Sun, J. 2016. Deep Residual Learning for Image Recognition. In CVPR
2016
-
[10]
Kirkpatrick, J.; Pascanu, R.; Rabinowitz, N.; and others. 2017. Overcoming catastrophic forgetting in neural networks. PNAS, 114(13):3521--3526
2017
-
[11]
Krizhevsky, A. 2009. Learning Multiple Layers of Features from Tiny Images. Technical report, University of Toronto
2009
- [12]
-
[13]
Mallya, A.; and Lazebnik, S. 2018. PackNet: Adding Multiple Tasks to a Single Network by Iterative Pruning. In CVPR
2018
-
[14]
I.; Chaudhry, A.; Yin, D.; Nguyen, T.; Pascanu, R.; Gorur, D.; and Farajtabar, M
Mirzadeh, S. I.; Chaudhry, A.; Yin, D.; Nguyen, T.; Pascanu, R.; Gorur, D.; and Farajtabar, M. 2022. Architecture Matters in Continual Learning. arXiv:2202.00275
-
[15]
Paszke, A.; Gross, S.; Massa, F.; and others. 2019. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In NeurIPS
2019
-
[16]
Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; and others. 2011. Scikit-learn: Machine Learning in Python. Journal of Machine Learning Research, 12:2825--2830
2011
-
[17]
Prabhu, A.; Torr, P. H. S.; and Dokania, P. K. 2020. GDumb: A Simple Approach that Questions Our Progress in Continual Learning. In ECCV
2020
-
[18]
Rusu, A. A.; Rabinowitz, N. C.; Desjardins, G.; Soyer, H.; Kirkpatrick, J.; Kavukcuoglu, K.; Pascanu, R.; and Hadsell, R. 2016. Progressive Neural Networks. arXiv:1606.04671
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[19]
Serra, J.; Suris, D.; Miron, M.; and Karatzoglou, A. 2018. Overcoming Catastrophic Forgetting with Hard Attention to the Task. In ICML
2018
-
[20]
N.; Kaiser, L.; and Polosukhin, I
Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A. N.; Kaiser, L.; and Polosukhin, I. 2017. Attention Is All You Need. In NeurIPS
2017
-
[21]
Wang, M.; Yu, L.; Zheng, D.; and others. 2019. DGL: A Graph-Centric, Highly-Performant Package for Graph Neural Networks. arXiv:1909.01315
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[22]
Wang, Z.; Zhang, Z.; Lee, C.-Y.; Zhang, H.; Sun, R.; Ren, X.; Perot, V.; Dy, J.; and Pfister, T. 2022. Learning to Prompt for Continual Learning. In CVPR
2022
-
[23]
Wang, L.; Zhang, X.; Su, H.; and Zhu, J. 2024. A Comprehensive Survey of Continual Learning: Theory, Method and Application. IEEE Transactions on Pattern Analysis and Machine Intelligence
2024
-
[24]
Xiao, H.; Rasul, K.; and Vollgraf, R. 2017. Fashion-MNIST: A Novel Image Dataset for Benchmarking Machine Learning Algorithms. arXiv:1708.07747
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[25]
Yoon, J.; Yang, E.; Lee, J.; and Hwang, S. J. 2018. Lifelong Learning with Dynamically Expandable Networks. In ICLR
2018
-
[26]
Zenke, F.; Poole, B.; and Ganguli, S. 2017. Continual Learning Through Synaptic Intelligence. In ICML
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.