Edge-indexed network time series with graph Ornstein-Uhlenbeck dynamics
Pith reviewed 2026-05-19 19:11 UTC · model grok-4.3
The pith
Lévy-driven graph Ornstein-Uhlenbeck models extend continuous-time dynamics to edge-indexed network time series.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce a class of Lévy-driven graph Ornstein-Uhlenbeck models for edge-indexed network time series by extending generalized network autoregressive processes to continuous time and adapting graph Ornstein-Uhlenbeck dynamics from the node-indexed to the edge-indexed setting; the resulting models accommodate general Lévy noise and therefore capture both Brownian and jump behavior, with parameters estimated via a maximum-likelihood framework whose asymptotic properties are derived, and with finite-sample and empirical performance illustrated on simulated data and high-frequency financial networks.
What carries the argument
The graph Ornstein-Uhlenbeck dynamics adapted to edge-indexed processes, which couples each edge's evolution to the network adjacency structure and is driven by Lévy noise.
If this is right
- The model supports maximum-likelihood estimation with established asymptotic properties for edge-indexed network series.
- General Lévy noise allows the processes to exhibit both diffusive and jump behavior on edges.
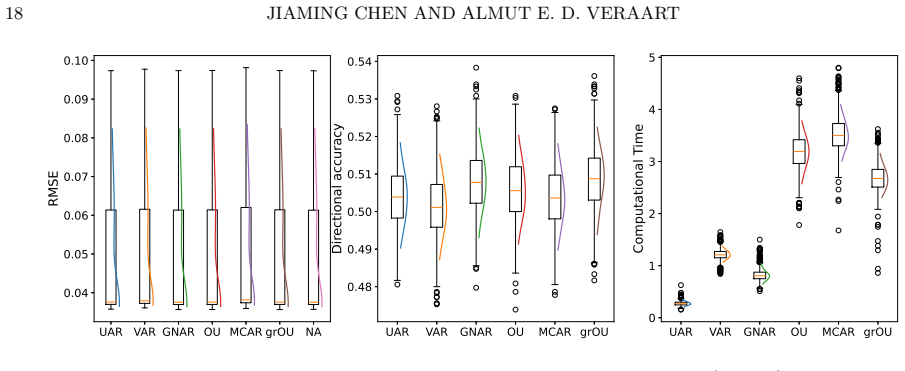
- Forecasting accuracy improves relative to standard benchmarks in the reported simulations and financial application.
- Computational time is reduced while robustness is maintained through the network-based parametrization.
Where Pith is reading between the lines
- The same edge-indexed construction could be used to model transaction volumes or traffic counts observed at irregular times.
- Because the parametrization is inherited from the network, the framework may scale to larger graphs without a combinatorial explosion in parameters.
- Extensions that replace the Ornstein-Uhlenbeck drift with other mean-reverting mechanisms would remain compatible with the existing estimation theory.
Load-bearing premise
Adapting the graph Ornstein-Uhlenbeck dynamics from node-indexed to edge-indexed processes preserves the stationarity and estimability properties needed for the maximum-likelihood estimator and its asymptotic results to hold.
What would settle it
A simulation study or the financial application in which the maximum-likelihood estimates do not converge at the claimed rate or in which out-of-sample forecast accuracy fails to exceed that of standard discrete-time network autoregressive benchmarks would undermine the central claim.
Figures






















read the original abstract
We introduce a class of L\'evy-driven graph Ornstein-Uhlenbeck (grOU) models for edge-indexed network time series. The proposed framework extends generalized network autoregressive (GNAR) processes for edge-indexed network time series to continuous time and adapts graph Ornstein-Uhlenbeck dynamics, originally developed for node-indexed processes, to the edge-indexed setting. The model accommodates general L\'evy noise and therefore captures both Brownian and jump behavior. We show that the model parameters can be estimated via a maximum-likelihood framework and derive the asymptotic properties of the estimator. We examine the finite-sample performance of the methodology through simulation studies and illustrate its practical relevance in an empirical application to high-frequency financial data. The results indicate that grOU models for edge-indexed network time series improve forecasting accuracy and reduce computational time relative to standard benchmarks while maintaining robustness through their network-based parametrization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Lévy-driven graph Ornstein-Uhlenbeck (grOU) models for edge-indexed network time series. It extends generalized network autoregressive (GNAR) processes to continuous time and adapts graph Ornstein-Uhlenbeck dynamics from node-indexed to edge-indexed settings. The framework accommodates general Lévy noise to capture both Brownian and jump behavior. Parameters are estimated via maximum likelihood, with asymptotic properties derived for the estimator. Finite-sample performance is examined through simulation studies, and practical relevance is illustrated via an empirical application to high-frequency financial data. The results claim improved forecasting accuracy and reduced computational time relative to benchmarks, with robustness from the network-based parametrization.
Significance. If the adaptation of grOU dynamics to the edge-indexed setting preserves stationarity, ergodicity, and the conditions for MLE consistency, the work could provide a valuable continuous-time extension for modeling network time series with jumps, offering potential gains in forecasting for applications such as financial networks.
major comments (1)
- [Abstract] Abstract: The claim that parameters can be estimated via maximum likelihood with derived asymptotic properties requires that the edge-indexed Lévy-driven SDE inherits a unique stationary distribution and ergodicity. This depends on the drift matrix (constructed via the graph operator on edges, e.g., line-graph Laplacian or incidence-matrix quadratic form) having eigenvalues with strictly positive real parts. The manuscript invokes the node-indexed case by analogy without re-deriving or bounding the spectrum for the edge setting; this is load-bearing for the MLE consistency and asymptotic normality results.
minor comments (1)
- The abstract refers to 'simulation studies' and 'an empirical application to high-frequency financial data' without specifying the network topologies, sample sizes, or data characteristics used to support the forecasting claims.
Simulated Author's Rebuttal
We thank the referee for their careful reading of the manuscript and for identifying this important point regarding the foundations of our asymptotic results. We address the comment directly below and will strengthen the paper accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that parameters can be estimated via maximum likelihood with derived asymptotic properties requires that the edge-indexed Lévy-driven SDE inherits a unique stationary distribution and ergodicity. This depends on the drift matrix (constructed via the graph operator on edges, e.g., line-graph Laplacian or incidence-matrix quadratic form) having eigenvalues with strictly positive real parts. The manuscript invokes the node-indexed case by analogy without re-deriving or bounding the spectrum for the edge setting; this is load-bearing for the MLE consistency and asymptotic normality results.
Authors: We agree that an explicit verification is required for rigor. The edge-indexed grOU is defined via a drift operator on the line graph (or equivalently via the quadratic form of the incidence matrix), which is itself a valid graph. Under the maintained assumption that the original undirected graph is connected, the spectrum of this edge-drift matrix inherits the strict positive real-part property from the standard graph Laplacian theory applied to the line graph. In the revision we will insert a short lemma (with proof) immediately before the MLE consistency theorem that (i) recalls the relevant spectral result for line graphs and (ii) verifies that the same Lyapunov-type condition used in the node-indexed case continues to hold, thereby justifying stationarity, ergodicity, and the subsequent asymptotic statements without relying on analogy alone. revision: yes
Circularity Check
No significant circularity detected in the derivation chain.
full rationale
The paper introduces an extension of Lévy-driven graph Ornstein-Uhlenbeck dynamics from node-indexed to edge-indexed processes, specifies a maximum-likelihood estimation framework, derives asymptotic properties of the estimator, and validates performance via simulations and an empirical financial application. These steps constitute independent content: the model definition, the adaptation of the SDE to edges, the MLE procedure, and the reported forecasting gains are not shown to reduce by construction to fitted inputs or to unverified self-citations. The derivation remains self-contained against external benchmarks such as finite-sample simulations and real-data illustration, consistent with a normal non-circular finding.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Q ∈ M^-_LK ... unique strictly stationary solution ... both Xt and Yt are ergodic (Remark 2.2, Prop 2.1)
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Q := block matrix with −Q_L ... −Q_1 (Def 2.1); Lyapunov equation QΓ + ΓQ⊤ = −E Σ_L E⊤
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Barndorff-Nielsen, O. E. & Shephard, N. (2001), ‘Non-Gaussian Or nstein–Uhlenbeck-based models and some of their uses in financial economics’, Journal of the Royal Statistical Society: Series B (Statistical Methodology) 63(2), 167–241
work page 2001
-
[2]
Christensen, K., Kinnebrock, S. & Podolskij, M. (2010), ‘Pre-aver aging estimators of the ex-post covariance matrix in noisy diffusion models with non-synchro nous data’, Journal of econometrics 159(1), 116–133
work page 2010
-
[3]
Courgeau, V. & Veraart, A. E. (2022 a), ‘High-frequency estimation of the L´ evy-driven graph Ornstein-Uhlenbeck process’, Electronic Journal of Statistics 16(2), 4863–4925
work page 2022
-
[4]
Courgeau, V. & Veraart, A. E. (2022 b), ‘Likelihood theory for the graph Ornstein-Uhlenbeck process’, Statistical Inference for Stochastic Processes 25(2), 227–260
work page 2022
-
[5]
Epps, T. W. (1979), ‘Comovements in stock prices in the very short run’, Journal of the American Statistical Association 74(366a), 291–298. iti Sato, K. & Yamazato, M. (1984), ‘Operator-selfdecomposable distributions as limit dis- tributions of processes of Ornstein-Uhlenbeck type’, Stochastic Processes and their Appli- cations 17(1), 73–100
work page 1979
-
[6]
Jacod, J. & Shiryaev, A. (2013), Limit theorems for stochastic processes , Vol. 288, Springer Science & Business Media
work page 2013
-
[7]
Modelling, Detrending and Decorrelation of Network Time Series
Knight, M. I., Nunes, M. A. & Nason, G. P. (2016), ‘Modelling, detren ding and decorrelation of network time series’, arXiv preprint arXiv:1603.03221
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[8]
Knight, M., Leeming, K., Nason, G. & Nunes, M. (2020), ‘Generalized n etwork autoregressive processes and the GNAR package’, Journal of Statistical Software 96, 1–36. EDGE-INDEXED NETWORK TIME SERIES 35
work page 2020
-
[9]
Lucchese, L., Pakkanen, M. S. & Veraart, A. E. (2024), ‘The shor t-term predictability of returns in order book markets: A deep learning perspective’, International Journal of Forecasting40(4), 1587–1621
work page 2024
-
[10]
Lucchese, L., Pakkanen, M. S. & Veraart, A. E. (2026), ‘Estimatio n and inference for multivariate continuous-time autoregressive processes’, The Annals of Applied Probabil- ity 36(1), 703–743
work page 2026
-
[11]
Mantziou, A., Cucuringu, M., Meirinhos, V. & Reinert, G. (2023), ‘The GNAR-edge model: a network autoregressive model for networks with time-varying e dge weights’, Journal of Complex Networks 11(6), cnad039
work page 2023
-
[12]
Marquardt, T. & Stelzer, R. (2007), ‘Multivariate CARMA processe s’, Stochastic Processes and their Applications 117(1), 96–120
work page 2007
-
[13]
Nason, G. P. & Palasciano, H. A. (2025), ‘Forecasting UK consumer price inflation with RaGNAR: Random generalised network autoregressive processes ’, International Journal of Forecasting
work page 2025
-
[14]
Nason, G. P., Salnikov, D. & Cortina-Borja, M. (2026), ‘New tools fo r network time series with an application to COVID-19 hospitalizations’, Journal of the Royal Statistical Society Series A: Statistics in Society 189(1), 139–163
work page 2026
-
[15]
Zhu, X., Pan, R., Li, G., Liu, Y. & Wang, H. (2017), ‘Network vector au toregression’, The Annals of Statistics 45(3), 1096 – 1123. Department of Mathematics, Imperial College London, UK Email address : j.chen1@imperial.ac.uk Department of Mathematics, Imperial College London, UK Email address : a.veraart@imperial.ac.uk
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.