Model Merging to Evolution: Parameter Space Exploration for Expert Models
Pith reviewed 2026-06-30 11:17 UTC · model grok-4.3
The pith
MERGEvolve initializes evolutionary search from a merged expert model to reach performance regions outside the convex combination space.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MERGEvolve unifies merging and evolution by treating the output of a merging procedure as the initial individual in an evolution strategy; expert models supply a strong deterministic seed, after which random perturbations explore the parameter space, and analysis confirms the reachable set properly contains the convex combination space of the experts.
What carries the argument
Evolution phase initialized at the merged model, using additive random noise to generate offspring that lie outside the convex hull.
If this is right
- Model merging no longer needs to be the final step; it can serve as a reliable seed for further parameter-space search.
- Performance gains become available in regions that cannot be expressed as any linear combination of the original experts.
- The same evolutionary loop can be applied after any existing merging method without retraining the experts.
- Ablation results imply that improving the merging stage directly improves the efficiency of the subsequent evolutionary stage.
Where Pith is reading between the lines
- The framework suggests that many current merging algorithms could be wrapped inside an evolutionary loop to escape their own convex-hull limitation.
- Similar initialization-plus-noise strategies might apply to other high-dimensional search problems where a good deterministic seed is cheaper than exhaustive sampling.
- If the noise schedule can be adapted to the geometry of the loss landscape, the method could become less sensitive to the precise quality of the merged seed.
Load-bearing premise
A high-quality merged model supplies an initial point from which random perturbations can reach superior regions outside the convex hull rather than simply wandering.
What would settle it
An experiment in which evolutionary search started from the merged model fails to produce models outside the convex hull or fails to match baseline merging performance when the initial merged point is replaced by a random or inferior seed.
Figures

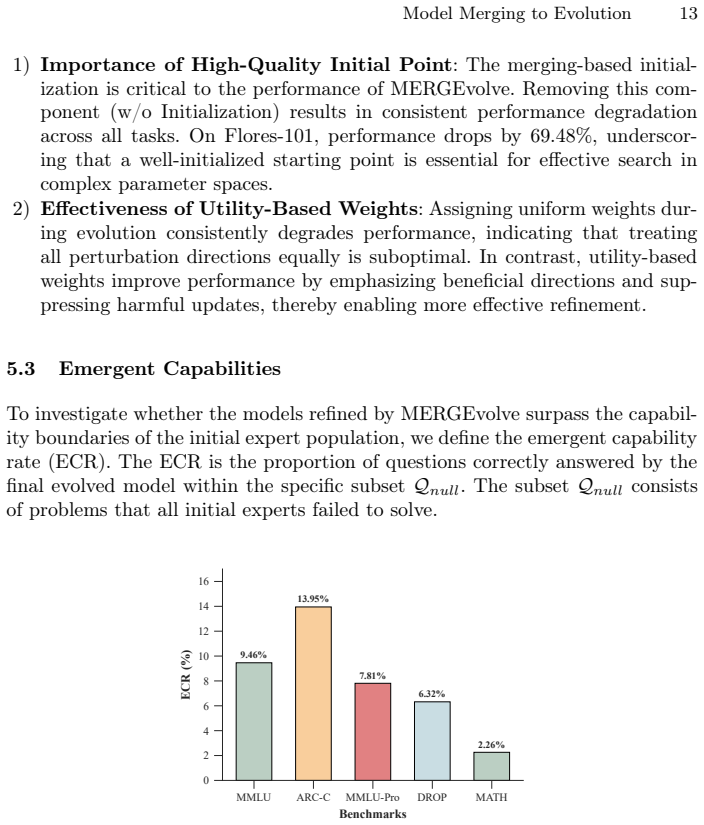
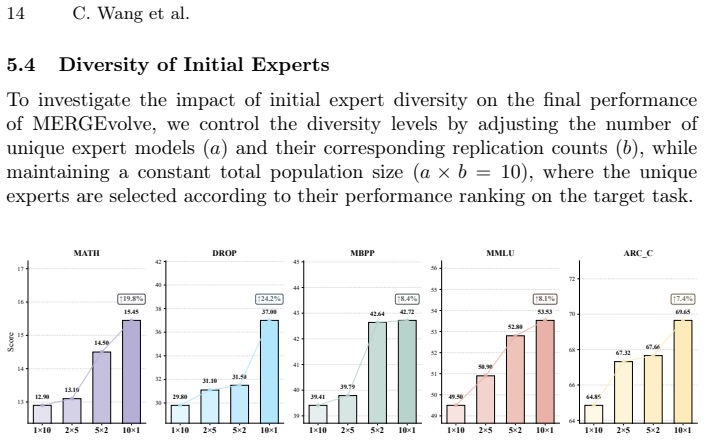
read the original abstract
Model merging integrates the capabilities of multiple expert models to create strong models for multiple tasks without additional training, thereby reducing computational resource requirements. However, existing methods operate within the convex combination space of expert models, failing to explore high-performance regions outside this space. This paper proposes the MERGEvolve framework, which unifies model merging and evolution within an evolution strategy by treating the merged model as the initialization for evolutionary exploration of the parameter space. During the merging phase, expert models act as deterministic sources to build a strong initial point. The evolution phase then explores the parameter space using random noise. Theoretical analysis shows that MERGEvolve explores regions outside the convex combination space. Extensive experiments on single-task and multi-task benchmarks demonstrate that MERGEvolve consistently achieves performance competitive with advanced model merging baselines. Ablation studies confirm that a high-quality initial point is critical for efficient exploration of the parameter space.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MERGEvolve, a framework that unifies model merging and evolutionary strategies by initializing an evolution strategy with a merged model (built from expert models as deterministic sources) and then applying random noise for parameter-space exploration. It claims that this enables exploration outside the convex combination space of the experts (supported by theoretical analysis) and reports competitive performance against advanced merging baselines on single-task and multi-task benchmarks, with ablations confirming the importance of a high-quality initial point.
Significance. If the theoretical claim holds and the experiments are reproducible with proper controls, the work could meaningfully connect model merging (which stays inside the convex hull) to evolutionary search (which can escape it), offering a training-free route to higher-performance regions in parameter space. The explicit ablation on initialization quality is a positive feature.
major comments (3)
- [Abstract / §3] The abstract asserts a 'theoretical analysis' showing exploration outside the convex combination space, yet supplies no equations, definitions of the noise distribution, or proof sketch. The central claim that MERGEvolve reaches regions unreachable by convex merging is therefore unverifiable from the provided material; the full manuscript must include the derivation (likely in §3 or §4) with explicit bounds or a concrete counter-example.
- [Abstract / §5] The abstract states 'extensive experiments' with 'competitive' results but reports neither datasets, baselines, number of runs, error bars, nor exclusion criteria. Without these, it is impossible to assess whether the competitive claim is load-bearing or whether the evolutionary phase actually contributes beyond the merged initialization.
- [Ablation studies] The weakest assumption—that random noise from a high-quality merged point reliably reaches higher-performance regions outside the convex hull—is stated but not stress-tested against cases where the merged point itself lies near a local optimum or where noise variance is insufficient to escape the hull.
minor comments (2)
- [Abstract] Notation for the merged initialization and the evolutionary perturbation should be introduced once and used consistently; the abstract switches between 'merged model' and 'initial point' without definition.
- [Abstract] The phrase 'parameter-free' or 'deterministic sources' appears without clarifying whether any hyperparameters (noise scale, population size, selection pressure) remain.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point-by-point below. Where the comments identify gaps in clarity or completeness, we have revised the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract / §3] The abstract asserts a 'theoretical analysis' showing exploration outside the convex combination space, yet supplies no equations, definitions of the noise distribution, or proof sketch. The central claim that MERGEvolve reaches regions unreachable by convex merging is therefore unverifiable from the provided material; the full manuscript must include the derivation (likely in §3 or §4) with explicit bounds or a concrete counter-example.
Authors: We agree that the abstract and main text would benefit from greater explicitness. Section 3 already contains the core argument that additive random noise (defined as zero-mean Gaussian perturbations) produces a distribution whose support is not contained in the convex hull of the expert parameters. To make this verifiable without requiring the reader to reconstruct the argument, we will insert a short proof sketch, the precise noise distribution, and a simple counter-example showing a point outside the hull that becomes reachable after perturbation. revision: yes
-
Referee: [Abstract / §5] The abstract states 'extensive experiments' with 'competitive' results but reports neither datasets, baselines, number of runs, error bars, nor exclusion criteria. Without these, it is impossible to assess whether the competitive claim is load-bearing or whether the evolutionary phase actually contributes beyond the merged initialization.
Authors: The abstract is intentionally concise; the required details (benchmarks, baselines, number of independent runs, error bars, and run-exclusion rules) appear in Section 5. We will nevertheless expand the abstract to list the primary benchmarks, the number of runs, and the presence of error bars so that the experimental claims can be evaluated from the abstract alone. revision: yes
-
Referee: [Ablation studies] The weakest assumption—that random noise from a high-quality merged point reliably reaches higher-performance regions outside the convex hull—is stated but not stress-tested against cases where the merged point itself lies near a local optimum or where noise variance is insufficient to escape the hull.
Authors: We accept that additional stress tests would strengthen the ablation section. We will add experiments that (i) deliberately initialize from lower-quality merges and (ii) sweep noise variance across a range that includes values too small to exit the hull, reporting whether performance gains persist or degrade under these conditions. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper defines MERGEvolve explicitly as merging experts to form an initial point followed by random-noise evolutionary steps; the claim that this explores outside the convex hull follows directly from the noise addition but is presented as a separate theoretical analysis without any quoted equations, self-citations, or fitted parameters that reduce the result to its own inputs by construction. Experiments and ablations are reported as empirical validation of performance and the value of the initial point, not as the source of the theoretical claim. No self-citation load-bearing steps, ansatz smuggling, or renaming of known results are evident from the provided material. The derivation chain is therefore self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Nature Machine Intelligence7(2), 195–204 (2025)
Akiba, T., Shing, M., Tang, Y., Sun, Q., Ha, D.: Evolutionary optimization of model merging recipes. Nature Machine Intelligence7(2), 195–204 (2025)
2025
-
[2]
Program Synthesis with Large Language Models
Austin, J., Odena, A., Nye, M., Bosma, M., Michalewski, H., Dohan, D., Jiang, E., Cai, C., Terry, M., Le, Q., et al.: Program synthesis with large language models. arXiv preprint arXiv:2108.07732 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[3]
In: Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., Lin, H
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J.D., Dhariwal, P., Nee- lakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-Voss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D., Wu, J., Winter, C., Hesse, C., Chen, M., Sigler, E., Litwin, M., Gray, S., Chess, B., Clark, J., Berner, C., McCandlish, S., Radford, A....
1901
-
[4]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Clark, P., Cowhey, I., Etzioni, O., Khot, T., Sabharwal, A., Schoenick, C., Tafjord, O.: Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv preprint arXiv:1803.05457 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[5]
Training Verifiers to Solve Math Word Problems
Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
In: Burstein, J., Doran, C., Solorio, T
Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: DROP: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Burstein, J., Doran, C., Solorio, T. (eds.) Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 ...
2019
-
[7]
Nature521(7553), 476–482 (2015)
Eiben, A.E., Smith, J.: From evolutionary computation to the evolution of things. Nature521(7553), 476–482 (2015)
2015
-
[8]
In: Forty-second International Conference on Machine Learning (2025)
Feng, S., Wang, Z., Wang, Y., Ebrahimi, S., Palangi, H., Miculicich, L., Kul- shrestha, A., Rauschmayr, N., Choi, Y., Tsvetkov, Y., Lee, C.Y., Pfister, T.: Model swarms: Collaborative search to adapt LLM experts via swarm intelligence. In: Forty-second International Conference on Machine Learning (2025)
2025
-
[9]
Transactions of the Association for Computational Linguistics10, 522–538 (2022)
Goyal, N., Gao, C., Chaudhary, V., Chen, P.J., Wenzek, G., Ju, D., Krishnan, S., Ranzato, M., Guzmán, F., Fan, A.: The Flores-101 evaluation benchmark for low- resource and multilingual machine translation. Transactions of the Association for Computational Linguistics10, 522–538 (2022)
2022
-
[10]
The CMA Evolution Strategy: A Tutorial
Hansen, N.: The cma evolution strategy: A tutorial. arXiv preprint arXiv:1604.00772 (2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[11]
In: International Conference on Learning Representations (2021) 16 C
Hendrycks,D.,Burns,C.,Basart,S.,Zou,A.,Mazeika,M.,Song,D.,Steinhardt,J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2021) 16 C. Wang et al
2021
-
[12]
In: Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2) (2021)
Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the MATH dataset. In: Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2) (2021)
2021
-
[13]
In: International Con- ference on Learning Representations (2022)
Hu, E.J., yelong shen, Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W.: LoRA: Low-rank adaptation of large language models. In: International Con- ference on Learning Representations (2022)
2022
-
[14]
In: First Conference on Lan- guage Modeling (2024)
Huang, C., Liu, Q., Lin, B.Y., Pang, T., Du, C., Lin, M.: Lorahub: Efficient cross- task generalization via dynamic loRA composition. In: First Conference on Lan- guage Modeling (2024)
2024
-
[15]
In: The Eleventh International Conference on Learning Representations (2023)
Ilharco, G., Ribeiro, M.T., Wortsman, M., Schmidt, L., Hajishirzi, H., Farhadi, A.: Editing models with task arithmetic. In: The Eleventh International Conference on Learning Representations (2023)
2023
-
[16]
arXiv , author =:2311.10702 , primaryclass =
Ivison, H., Wang, Y., Pyatkin, V., Lambert, N., Peters, M., Dasigi, P., Jang, J., Wadden, D., Smith, N.A., Beltagy, I., et al.: Camels in a changing climate: En- hancing lm adaptation with tulu 2. arXiv preprint arXiv:2311.10702 (2023)
-
[17]
In: Koyejo, S., Mohamed, S., Agarwal, A., Belgrave, D., Cho, K., Oh, A
Matena, M.S., Raffel, C.A.: Merging models with fisher-weighted averaging. In: Koyejo, S., Mohamed, S., Agarwal, A., Belgrave, D., Cho, K., Oh, A. (eds.) Ad- vances in Neural Information Processing Systems. vol. 35, pp. 17703–17716. Curran Associates, Inc. (2022)
2022
-
[18]
In: First Conference on Language Modeling (2024)
Mavromatis, C., Karypis, P., Karypis, G.: Pack of LLMs: Model fusion at test-time via perplexity optimization. In: First Conference on Language Modeling (2024)
2024
-
[19]
Sci- ence387(6735), eadp7478 (2025)
Miikkulainen, R.: Neuroevolution insights into biological neural computation. Sci- ence387(6735), eadp7478 (2025)
2025
-
[20]
In: Mishra, P., Muresan, S., Yu, T
Minut, A.R., Mencattini, T., Santilli, A., Crisostomi, D., Rodolà, E.: Mergenetic: a simple evolutionary model merging library. In: Mishra, P., Muresan, S., Yu, T. (eds.) Proceedings of the 63rd Annual Meeting of the Association for Computa- tional Linguistics (Volume 3: System Demonstrations). pp. 572–582. Association for Computational Linguistics, Vienn...
2025
-
[21]
In: The Thirteenth International Conference on Learning Representations (2025)
Mirzadeh, S.I., Alizadeh, K., Shahrokhi, H., Tuzel, O., Bengio, S., Farajtabar, M.: GSM-symbolic: Understanding the limitations of mathematical reasoning in large language models. In: The Thirteenth International Conference on Learning Representations (2025)
2025
-
[22]
In: Korhonen, A., Traum, D., Màrquez, L
Poria,S.,Hazarika,D.,Majumder,N.,Naik,G.,Cambria,E.,Mihalcea,R.:MELD: A multimodal multi-party dataset for emotion recognition in conversations. In: Korhonen, A., Traum, D., Màrquez, L. (eds.) Proceedings of the 57th Annual MeetingoftheAssociationforComputationalLinguistics.pp.527–536.Association for Computational Linguistics, Florence, Italy (Jul 2019)
2019
-
[23]
Evolution Strategies as a Scalable Alternative to Reinforcement Learning
Salimans, T., Ho, J., Chen, X., Sidor, S., Sutskever, I.: Evolution strategies as a scalable alternative to reinforcement learning. arXiv preprint arXiv:1703.03864 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[24]
In: The Eleventh International Conference on Learning Representations (2023)
Shi, F., Suzgun, M., Freitag, M., Wang, X., Srivats, S., Vosoughi, S., Chung, H.W., Tay, Y., Ruder, S., Zhou, D., Das, D., Wei, J.: Language models are multilingual chain-of-thought reasoners. In: The Eleventh International Conference on Learning Representations (2023)
2023
-
[25]
(eds.) Findings of the Association for Computational Linguistics: ACL 2023
Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowd- hery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whetherchain-of-thoughtcansolvethem.In:Rogers,A.,Boyd-Graber,J.,Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023. pp. 13003–13051. Association for Computational ...
2023
-
[26]
In: Burstein, J., Doran, C., Solorio, T
Talmor, A., Herzig, J., Lourie, N., Berant, J.: CommonsenseQA: A question an- swering challenge targeting commonsense knowledge. In: Burstein, J., Doran, C., Solorio, T. (eds.) Proceedings of the 2019 Conference of the North American Chap- ter of the Association for Computational Linguistics: Human Language Technolo- gies, Volume 1 (Long and Short Papers)...
2019
-
[27]
Gemma 2: Improving Open Language Models at a Practical Size
Team, G., Riviere, M., Pathak, S., Sessa, P.G., Hardin, C., Bhupatiraju, S., Hussenot, L., Mesnard, T., Shahriari, B., Ramé, A., et al.: Gemma 2: Improving open language models at a practical size. arXiv preprint arXiv:2408.00118 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Research8, 0646 (2025)
Wang, C., Zhao, J., Jiao, L., Li, L., Liu, F., Yang, S.: When large language models meet evolutionary algorithms: Potential enhancements and challenges. Research8, 0646 (2025)
2025
-
[29]
In: Globerson, A., Mackey, L., Belgrave, D., Fan, A., Paquet, U., Tomczak, J., Zhang, C
Wang, Y., Ma, X., Zhang, G., Ni, Y., Chandra, A., Guo, S., Ren, W., Arulraj, A., He, X., Jiang, Z., Li, T., Ku, M., Wang, K., Zhuang, A., Fan, R., Yue, X., Chen, W.: Mmlu-pro: A more robust and challenging multi-task language understand- ing benchmark. In: Globerson, A., Mackey, L., Belgrave, D., Fan, A., Paquet, U., Tomczak, J., Zhang, C. (eds.) Advances...
2024
-
[30]
arXiv preprint arXiv:2505.21226 (2025)
Wang, Z., Xu, X., Liu, Y., Zhang, Y., Lin, P., Feng, S., Yang, X., Wang, D., Schütze, H.: Why do more experts fail? a theoretical analysis of model merging. arXiv preprint arXiv:2505.21226 (2025)
-
[31]
The Journal of Machine Learning Research15(1), 949–980 (2014)
Wierstra, D., Schaul, T., Glasmachers, T., Sun, Y., Peters, J., Schmidhuber, J.: Natural evolution strategies. The Journal of Machine Learning Research15(1), 949–980 (2014)
2014
-
[32]
In: Chaudhuri, K., Jegelka, S., Song, L., Szepesvari, C., Niu, G., Sabato, S
Wortsman, M., Ilharco, G., Gadre, S.Y., Roelofs, R., Gontijo-Lopes, R., Morcos, A.S., Namkoong, H., Farhadi, A., Carmon, Y., Kornblith, S., Schmidt, L.: Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time. In: Chaudhuri, K., Jegelka, S., Song, L., Szepesvari, C., Niu, G., Sabato, S. (eds.) Proce...
2022
-
[33]
Advances in neural information processing systems36, 7093–7115 (2023)
Yadav, P., Tam, D., Choshen, L., Raffel, C.A., Bansal, M.: Ties-merging: Resolv- ing interference when merging models. Advances in neural information processing systems36, 7093–7115 (2023)
2023
-
[34]
ACM Comput
Yang, E., Shen, L., Guo, G., Wang, X., Cao, X., Zhang, J., Tao, D.: Model merging in llms, mllms, and beyond: Methods, theories, applications, and opportunities. ACM Comput. Surv.58(8) (Feb 2026)
2026
-
[35]
Emotion Detection on TV Show Transcripts with Sequence-based Convolutional Neural Networks
Zahiri, S.M., Choi, J.D.: Emotion detection on tv show transcripts with sequence- based convolutional neural networks. In: arXiv preprint arXiv:1708.04299 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[36]
arXiv preprint arXiv:2503.01155 (2025)
Zhang, Y., Ye, P., Yang, X., Feng, S., Zhang, S., Bai, L., Ouyang, W., Hu, S.: Nature-inspired population-based evolution of large language models. arXiv preprint arXiv:2503.01155 (2025)
-
[37]
In: Cao, Y., Feng, Y., Xiong, D
Zheng, Y., Zhang, R., Zhang, J., Ye, Y., Luo, Z.: LlamaFactory: Unified efficient fine-tuning of 100+ language models. In: Cao, Y., Feng, Y., Xiong, D. (eds.) Pro- ceedings of the 62nd Annual Meeting of the Association for Computational Lin- guistics (Volume 3: System Demonstrations). pp. 400–410. Association for Com- putational Linguistics, Bangkok, Thai...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.