SyncCache: Exploiting Asymmetric Dynamics for Fast Audio-Driven Portrait Animation
Pith reviewed 2026-07-01 06:10 UTC · model grok-4.3
The pith
SyncCache accelerates DiT-based audio portrait animation up to 4x by caching stable background residuals while recomputing audio blocks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
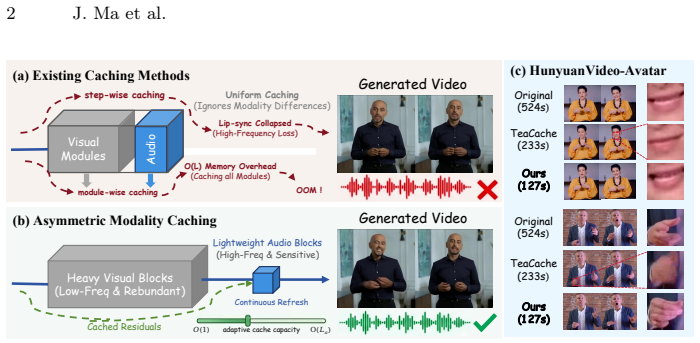
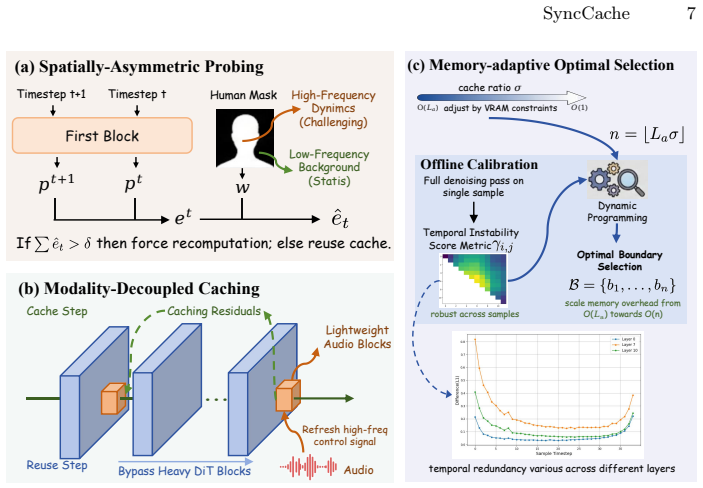
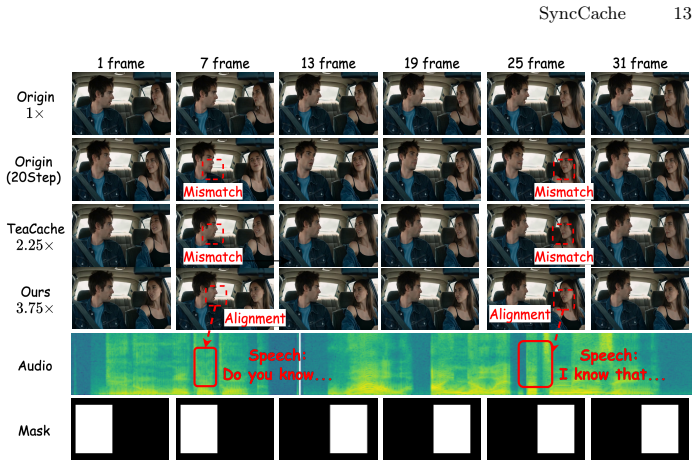
SyncCache exploits asymmetric dynamics in audio-driven portrait animation, where high-frequency changes driven by audio are concentrated in human regions while the visual background remains low-frequency. It applies Spatially-Asymmetric Probing to prioritize error sensitivity in dynamic human areas and Modality-Decoupled Caching to bypass heavy DiT blocks by reusing stable inter-block residuals for visuals while continuously recomputing lightweight audio blocks to preserve synchronization. Cache capacity is controlled by a ratio formulated as an offline dynamic programming problem.
What carries the argument
Modality-Decoupled Caching with Spatially-Asymmetric Probing, which separates reuse of stable visual residuals from recomputation of audio-driven parts.
If this is right
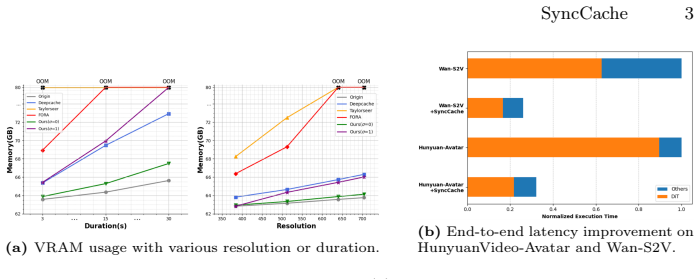
- Achieves up to 4.12x acceleration on HunyuanVideo-Avatar with near-lossless visual fidelity and precise audio alignment.
- Achieves 3.75x acceleration on Wan-S2V under the same conditions.
- Allows memory-adaptive cache selection via an offline dynamic programming step with no online overhead.
- Preserves precise lip synchronization by continuous recomputation of lightweight audio blocks.
Where Pith is reading between the lines
- The same separation of high-frequency conditional signals from stable backgrounds could be tested in other conditional video tasks such as text-to-video with moving foregrounds.
- If human-region detection remains reliable, the approach might extend directly to full-body animation without retraining the underlying model.
- The offline cache-ratio optimization could be adapted to other memory-bounded inference pipelines that reuse intermediate transformer states.
Load-bearing premise
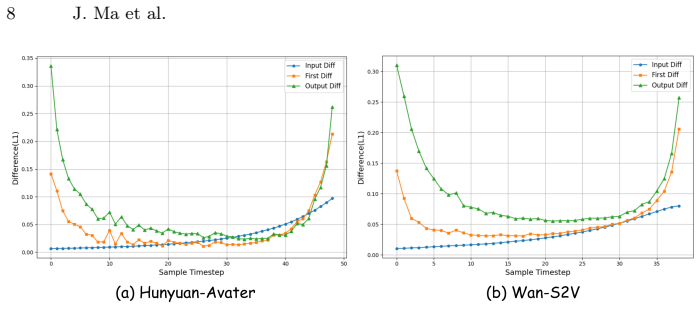
High-frequency audio-driven dynamics in human regions differ enough from low-frequency backgrounds that stable inter-block residuals can be reused without harming synchronization or introducing visible errors.
What would settle it
A test video in which background motion increases or audio-driven changes spread outside detected human regions at high cache ratios would show whether artifacts or lip desync appear.
Figures

read the original abstract
Diffusion Transformers (DiTs) have significantly advanced audio-driven portrait animation, but their high computational cost leads to substantial inference latency. Although training-free diffusion caching accelerates inference significant, existing methods are primarily developed for text-conditioned generation and overlook the spatial and modality imbalances inherent in audio-driven portrait animation. In this paper, we propose SyncCache, a training-free caching acceleration method tailored for DiT-based portrait animation that explicitly exploits asymmetric dynamics. Specifically, high-frequency dynamics driven by audio conditions and concentrated in human regions are more challenging and critical to cache and reuse than the low-frequency visual background in portrait animation. First, we introduce Spatially-Asymmetric Probing to prioritize error sensitivity in dynamic human region. Second, through Modality-Decoupled Caching, we bypass heavy DiT block by reusing stable inter-block residuals, while continuously recomputing lightweight audio blocks to preserve precise lip synchronization. Furthermore, we introduce a cache ratio to control cache capacity and formulate memory-adaptive cache selection as an offline dynamic programming problem without online overhead. Extensive experiments demonstrate that SyncCache achieves superior speed-quality trade-offs, delivering up to 4.12x acceleration on HunyuanVideo-Avatar and 3.75x on Wan-S2V with near-lossless visual fidelity and precise audio alignment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SyncCache, a training-free caching acceleration method for Diffusion Transformer (DiT) models in audio-driven portrait animation. It exploits spatial asymmetry (high-frequency audio-driven dynamics concentrated in human regions vs. low-frequency backgrounds) via Spatially-Asymmetric Probing and modality asymmetry via Modality-Decoupled Caching (reusing stable inter-block residuals in heavy DiT blocks while recomputing lightweight audio blocks). A cache ratio is controlled via offline dynamic programming. Experiments claim up to 4.12x acceleration on HunyuanVideo-Avatar and 3.75x on Wan-S2V with near-lossless fidelity and precise audio alignment.
Significance. If the empirical speed-quality trade-offs hold under the stated assumptions, the work provides a practical, training-free technique for reducing inference latency in a growing application area (real-time portrait animation) without sacrificing synchronization. The modality-decoupled design and dynamic-programming cache selection are notable strengths that could generalize to other conditioned DiT pipelines.
major comments (3)
- [Abstract, §3] Abstract and §3 (Modality-Decoupled Caching): the central acceleration claim (4.12x / 3.75x) and "precise audio alignment" guarantee rest on the assumption that inter-block residuals remain stable and reusable under audio conditioning while only audio blocks are recomputed. No quantitative analysis of residual variation or accumulated lip-sync error (e.g., LSE or SyncNet scores over long sequences) is referenced; if residuals vary more than assumed, the near-lossless claim fails even if background caching succeeds.
- [§3.1] §3.1 (Spatially-Asymmetric Probing): the premise that error sensitivity is concentrated in human regions (allowing safe bypassing of heavy blocks) is load-bearing for the spatially asymmetric design. The paper supplies no ablation comparing error maps or quality metrics when probing is replaced by uniform or text-conditioned baselines, leaving the asymmetry claim unverified against the skeptic concern.
- [Experiments] Experiments section (tables reporting speedups): the reported maxima (4.12x, 3.75x) are presented without accompanying average metrics, standard deviations, or per-dataset ablation on cache ratio; this makes it impossible to assess whether the speed-quality trade-off is robust or sensitive to the offline DP solution.
minor comments (2)
- [Abstract] The abstract states "extensive experiments" but supplies no table or figure references for the quantitative results; adding explicit citations to the results tables would improve readability.
- [§3.3] Notation for the cache ratio and dynamic-programming formulation could be introduced with a short equation in §3.3 to make the offline selection procedure clearer.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below with clarifications and note planned revisions to strengthen the empirical support.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (Modality-Decoupled Caching): the central acceleration claim (4.12x / 3.75x) and "precise audio alignment" guarantee rest on the assumption that inter-block residuals remain stable and reusable under audio conditioning while only audio blocks are recomputed. No quantitative analysis of residual variation or accumulated lip-sync error (e.g., LSE or SyncNet scores over long sequences) is referenced; if residuals vary more than assumed, the near-lossless claim fails even if background caching succeeds.
Authors: The Modality-Decoupled Caching design recomputes audio blocks at every timestep precisely to safeguard lip synchronization while reusing residuals only where they remain stable. The reported results already show that this yields near-lossless fidelity and precise alignment under the evaluated conditions. We agree that explicit residual-variation analysis and long-sequence SyncNet/LSE tracking would further substantiate the assumption; we will add these quantitative plots and metrics in the revision. revision: yes
-
Referee: [§3.1] §3.1 (Spatially-Asymmetric Probing): the premise that error sensitivity is concentrated in human regions (allowing safe bypassing of heavy blocks) is load-bearing for the spatially asymmetric design. The paper supplies no ablation comparing error maps or quality metrics when probing is replaced by uniform or text-conditioned baselines, leaving the asymmetry claim unverified against the skeptic concern.
Authors: Section 3.1 motivates the design from the spatial concentration of audio-driven dynamics in human regions. While the submission did not include direct uniform or text-conditioned probing ablations, the error-sensitivity maps support the asymmetry. We will add the requested comparative ablations (uniform probing and text-conditioned baselines) with corresponding error maps and quality metrics in the revised manuscript. revision: yes
-
Referee: [Experiments] Experiments section (tables reporting speedups): the reported maxima (4.12x, 3.75x) are presented without accompanying average metrics, standard deviations, or per-dataset ablation on cache ratio; this makes it impossible to assess whether the speed-quality trade-off is robust or sensitive to the offline DP solution.
Authors: The reported figures are the peak accelerations obtained at the cache ratios selected by the offline dynamic program. To demonstrate robustness, we will augment the experiments with average speedups, standard deviations across sequences, and per-dataset cache-ratio ablations in the revised version. revision: yes
Circularity Check
No circularity: acceleration claims rest on empirical design and benchmarks
full rationale
The paper introduces SyncCache via two design components (Spatially-Asymmetric Probing and Modality-Decoupled Caching) motivated by domain observations about audio-driven dynamics. These are presented as engineering choices, not derived from equations that reduce to their own inputs. Performance numbers (4.12x / 3.75x) are reported from direct experiments on external models; no fitted parameters are renamed as predictions, no self-citation chains justify uniqueness, and no ansatz is smuggled. The derivation chain is therefore self-contained and externally falsifiable via the reported runtime and quality metrics.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: The Fourteenth International Conference on Learning Representations (2026)
Bu, J., Ling, P., Zhou, Y., Wang, Y., Zang, Y., Lin, D., Wang, J.: Dicache: Let dif- fusion model determine its own cache. In: The Fourteenth International Conference on Learning Representations (2026)
2026
-
[2]
International Journal of Computer Vision134(6), 276 (2026)
Chen, P., Shen, M., Ye, P., Cao, J., Tu, C., Bouganis, C.S., Zhao, Y., Chen, T.: $\delta$-dit: Accelerating diffusion transformers without training via denoising property alignment. International Journal of Computer Vision134(6), 276 (2026)
2026
-
[3]
arXiv preprint arXiv:2505.20156 (2025)
Chen, Y., Liang, S., Zhou, Z., Huang, Z., Ma, Y., Tang, J., Lin, Q., Zhou, Y., Lu, Q.: Hunyuanvideo-avatar: High-fidelity audio-driven human animation for multiple characters. arXiv preprint arXiv:2505.20156 (2025)
-
[4]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Chen, Z., Cao, J., Chen, Z., Li, Y., Ma, C.: Echomimic: Lifelike audio-driven portrait animations through editable landmark conditions. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 2403–2410 (2025)
2025
-
[5]
In: Pro- ceedings of the IEEE/CVF International Conference on Computer Vision
Chu, H., Wu, W., Feng, G., Zhang, Y.: Omnicache: A trajectory-oriented global perspective on training-free cache reuse for diffusion transformer models. In: Pro- ceedings of the IEEE/CVF International Conference on Computer Vision. pp. 16302–16312 (2025) 16 J. Ma et al
2025
-
[6]
In: Asian conference on computer vision
Chung, J.S., Zisserman, A.: Out of time: automated lip sync in the wild. In: Asian conference on computer vision. pp. 251–263. Springer (2016)
2016
-
[7]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Cui, J., Li, H., Zhan, Y., Shang, H., Cheng, K., Ma, Y., Mu, S., Zhou, H., Wang, J., Zhu, S.: Hallo3: Highly dynamic and realistic portrait image animation with video diffusion transformer. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 21086–21095 (2025)
2025
-
[8]
Advances in neural information pro- cessing systems35, 16344–16359 (2022)
Dao, T., Fu, D., Ermon, S., Rudra, A., Ré, C.: Flashattention: Fast and memory- efficient exact attention with io-awareness. Advances in neural information pro- cessing systems35, 16344–16359 (2022)
2022
-
[9]
arXiv preprint arXiv:2508.16984 (2025)
Feng, L., Zheng, S., Liu, J., Lin, Y., Zhou, Q., Cai, P., Wang, X., Chen, J., Zou, C., Ma, Y., et al.: Hicache: Training-free acceleration of diffusion models via hermite polynomial-based feature caching. arXiv preprint arXiv:2508.16984 (2025)
-
[10]
arXiv preprint arXiv:2505.22167 (2025)
Feng, W., Yang, C., Qin, H., Li, X., Wang, Y., An, Z., Huang, L., Diao, B., Zhao, Z., Xu, Y., et al.: Q-vdit: Towards accurate quantization and distillation of video- generation diffusion transformers. arXiv preprint arXiv:2505.22167 (2025)
-
[11]
arXiv preprint arXiv:2506.18866 (2025)
Gan, Q., Yang, R., Zhu, J., Xue, S., Hoi, S.: Omniavatar: Efficient audio- driven avatar video generation with adaptive body animation. arXiv preprint arXiv:2506.18866 (2025)
-
[12]
arXiv preprint arXiv:2508.18621 (2025)
Gao, X., Hu, L., Hu, S., Huang, M., Ji, C., Meng, D., Qi, J., Qiao, P., Shen, Z., Song, Y., et al.: Wan-s2v: Audio-driven cinematic video generation. arXiv preprint arXiv:2508.18621 (2025)
-
[13]
Knowledge-Based Systems p
Guan,X.,Jiang,L.,Chen,H.,Zhang,X.,Yan,J.,Wang,G.,Liu,Y.,Zhang,Z.,Wu, Y.: Forecasting when to forecast: Accelerating diffusion models with confidence- gated taylor. Knowledge-Based Systems p. 114635 (2025)
2025
-
[14]
Advances in neural information processing systems30(2017)
Heusel,M.,Ramsauer,H.,Unterthiner,T.,Nessler,B.,Hochreiter,S.:Ganstrained by a two time-scale update rule converge to a local nash equilibrium. Advances in neural information processing systems30(2017)
2017
-
[15]
Hore, A., Ziou, D.: Image quality metrics: Psnr vs. ssim. In: 2010 20th international conference on pattern recognition. pp. 2366–2369. IEEE (2010)
2010
-
[16]
In: The Thirteenth In- ternational Conference on Learning Representations (2025)
Jiang, J., Liang, C., Yang, J., Lin, G., Zhong, T., Zheng, Y.: Loopy: Taming audio- driven portrait avatar with long-term motion dependency. In: The Thirteenth In- ternational Conference on Learning Representations (2025)
2025
-
[17]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Kong, W., Tian, Q., Zhang, Z., Min, R., Dai, Z., Zhou, J., Xiong, J., Li, X., Wu, B., Zhang, J., et al.: Hunyuanvideo: A systematic framework for large video generative models. arXiv preprint arXiv:2412.03603 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025)
Kong, Z., Gao, F., Zhang, Y., Kang, Z., Wei, X., Cai, X., Chen, G., Luo, W.: Let them talk: Audio-driven multi-person conversational video generation. In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025)
2025
-
[19]
arXiv preprint arXiv:2508.20210 (2025)
Li, X., Xie, P., Ren, Y., Gan, Q., Zhang, C., Kong, F., Yin, X., Peng, B., Yuan, Z.: Infinityhuman: Towards long-term audio-driven human. arXiv preprint arXiv:2508.20210 (2025)
-
[20]
Flow Matching for Generative Modeling
Lipman, Y., Chen, R.T., Ben-Hamu, H., Nickel, M., Le, M.: Flow matching for generative modeling. arXiv preprint arXiv:2210.02747 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[21]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Liu, F., Zhang, S., Wang, X., Wei, Y., Qiu, H., Zhao, Y., Zhang, Y., Ye, Q., Wan, F.: Timestep embedding tells: It’s time to cache for video diffusion model. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 7353–7363 (2025)
2025
-
[22]
arXiv preprint arXiv:2510.08669 (2025) SyncCache 17
Liu, J., Cai, P., Zhou, Q., Lin, Y., Kong, D., Huang, B., Pan, Y., Xu, H., Zou, C., Tang, J., et al.: Freqca: Accelerating diffusion models via frequency-aware caching. arXiv preprint arXiv:2510.08669 (2025) SyncCache 17
-
[23]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Liu, J., Zou, C., Lyu, Y., Chen, J., Zhang, L.: From reusing to forecasting: Ac- celerating diffusion models with taylorseers. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 15853–15863 (2025)
2025
-
[24]
In: Proceedings of the 33rd ACM International Conference on Multimedia
Liu, J., Zou, C., Lyu, Y., Ren, F., Wang, S., Li, K., Zhang, L.: Speca: Accelerating diffusion transformers with speculative feature caching. In: Proceedings of the 33rd ACM International Conference on Multimedia. pp. 10024–10033 (2025)
2025
-
[25]
Advances in neural information processing systems35, 5775–5787 (2022)
Lu, C., Zhou, Y., Bao, F., Chen, J., Li, C., Zhu, J.: Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps. Advances in neural information processing systems35, 5775–5787 (2022)
2022
-
[26]
Advances in Neural Information Processing Systems 38, 34348–34380 (2026)
Ma, Z., Wei, L., Wang, F., Zhang, S., Tian, Q.: Magcache: Fast video generation with magnitude-aware cache. Advances in Neural Information Processing Systems 38, 34348–34380 (2026)
2026
-
[27]
In: Proceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition
Meng, C., Rombach, R., Gao, R., Kingma, D., Ermon, S., Ho, J., Salimans, T.: On distillation of guided diffusion models. In: Proceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition. pp. 14297–14306 (2023)
2023
-
[28]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Meng, R., Zhang, X., Li, Y., Ma, C.: Echomimicv2: Towards striking, simplified, and semi-body human animation. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 5489–5498 (2025)
2025
-
[29]
Peebles,W.,Xie,S.:Scalablediffusionmodelswithtransformers.In:Proceedingsof the IEEE/CVF international conference on computer vision. pp. 4195–4205 (2023)
2023
-
[30]
arXiv preprint arXiv:2407.01425 (2024)
Selvaraju, P., Ding, T., Chen, T., Zharkov, I., Liang, L.: Fora: Fast-forward caching in diffusion transformer acceleration. arXiv preprint arXiv:2407.01425 (2024)
-
[31]
In: European Conference on Computer Vision
Tian, L., Wang, Q., Zhang, B., Bo, L.: Emo: Emote portrait alive generating ex- pressive portrait videos with audio2video diffusion model under weak conditions. In: European Conference on Computer Vision. pp. 244–260. Springer (2024)
2024
-
[32]
Unterthiner, T., Van Steenkiste, S., Kurach, K., Marinier, R., Michalski, M., Gelly, S.: Fvd: A new metric for video generation (2019)
2019
-
[33]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.W., Chen, D., Yu, F., Zhao, H., Yang, J., et al.: Wan: Open and advanced large-scale video generative models. arXiv preprint arXiv:2503.20314 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
In: Proceedings of the 33rd ACM International Conference on Multimedia
Wang, M., Wang, Q., Jiang, F., Fan, Y., Zhang, Y., Qi, Y., Zhao, K., Xu, M.: Fantasytalking: Realistic talking portrait generation via coherent motion synthesis. In: Proceedings of the 33rd ACM International Conference on Multimedia. pp. 9891–9900 (2025)
2025
-
[35]
arXiv preprint arXiv:2312.09109 (2023)
Wang, X., Zhang, S., Zhang, H., Liu, Y., Zhang, Y., Gao, C., Sang, N.: Videolcm: Video latent consistency model. arXiv preprint arXiv:2312.09109 (2023)
-
[36]
IEEE transactions on image processing 13(4), 600–612 (2004)
Wang, Z., Bovik, A.C., Sheikh, H.R., Simoncelli, E.P.: Image quality assessment: from error visibility to structural similarity. IEEE transactions on image processing 13(4), 600–612 (2004)
2004
-
[37]
arXiv preprint arXiv:2403.17694 (2024)
Wei, H., Yang, Z., Wang, Z.: Aniportrait: Audio-driven synthesis of photorealistic portrait animation. arXiv preprint arXiv:2403.17694 (2024)
-
[38]
Xi, H., Yang, S., Zhao, Y., Xu, C., Li, M., Li, X., Lin, Y., Cai, H., Zhang, J., Li, D., et al.: Sparse videogen: Accelerating video diffusion transformers with spatial- temporal sparsity. arXiv preprint arXiv:2502.01776 (2025)
-
[39]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Xia, Y., Ling, S., Fu, F., Wang, Y., Li, H., Xiao, X., Cui, B.: Training-free and adaptive sparse attention for efficient long video generation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 15982–15993 (2025)
2025
-
[40]
arXiv preprint arXiv:2406.08801 (2024) 18 J
Xu, M., Li, H., Su, Q., Shang, H., Zhang, L., Liu, C., Wang, J., Yao, Y., Zhu, S.: Hallo: Hierarchical audio-driven visual synthesis for portrait image animation. arXiv preprint arXiv:2406.08801 (2024) 18 J. Ma et al
-
[41]
In: Proceedings of the Com- puter Vision and Pattern Recognition Conference
Zhang, H., Gao, T., Shao, J., Wu, Z.: Blockdance: Reuse structurally similar spatio- temporal features to accelerate diffusion transformers. In: Proceedings of the Com- puter Vision and Pattern Recognition Conference. pp. 12891–12900 (2025)
2025
-
[42]
In: Forty-second International Conference on Machine Learning (2025)
Zhang, J., Xiang, C., Huang, H., Xi, H., Zhu, J., Chen, J., et al.: Spargeattention: Accurate and training-free sparse attention accelerating any model inference. In: Forty-second International Conference on Machine Learning (2025)
2025
-
[43]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable effectiveness of deep features as a perceptual metric. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 586–595 (2018)
2018
-
[44]
In: The Thirteenth International Conference on Learning Representations (2025)
Zhao, T., Fang, T., Huang, H., Wan, R., Soedarmadji, W., Liu, E., Li, S., Lin, Z., Dai, G., Yan, S., et al.: Vidit-q: Efficient and accurate quantization of diffusion transformers for image and video generation. In: The Thirteenth International Conference on Learning Representations (2025)
2025
-
[45]
In: Proceedings of the 33rd ACM International Conference on Multimedia
Zheng, Z., Wang, X., Zou, C., Wang, S., Zhang, L.: Compute only 16 tokens in one timestep: Accelerating diffusion transformers with cluster-driven feature caching. In: Proceedings of the 33rd ACM International Conference on Multimedia. pp. 10181–10189 (2025)
2025
-
[46]
arXiv preprint arXiv:2507.02860 (2025)
Zhou, X., Liang, D., Chen, K., Feng, T., Chen, X., Lin, H., Ding, Y., Tan, F., Zhao, H., Bai, X.: Less is enough: Training-free video diffusion acceleration via runtime-adaptive caching. arXiv preprint arXiv:2507.02860 (2025)
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.