FlowCodec: One-Step Flow Prior for Generative Image Compression
Pith reviewed 2026-06-26 13:26 UTC · model grok-4.3
The pith
FlowCodec integrates pretrained text-to-image priors into compression via one-step latent transport without extra conditioning or auxiliary networks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
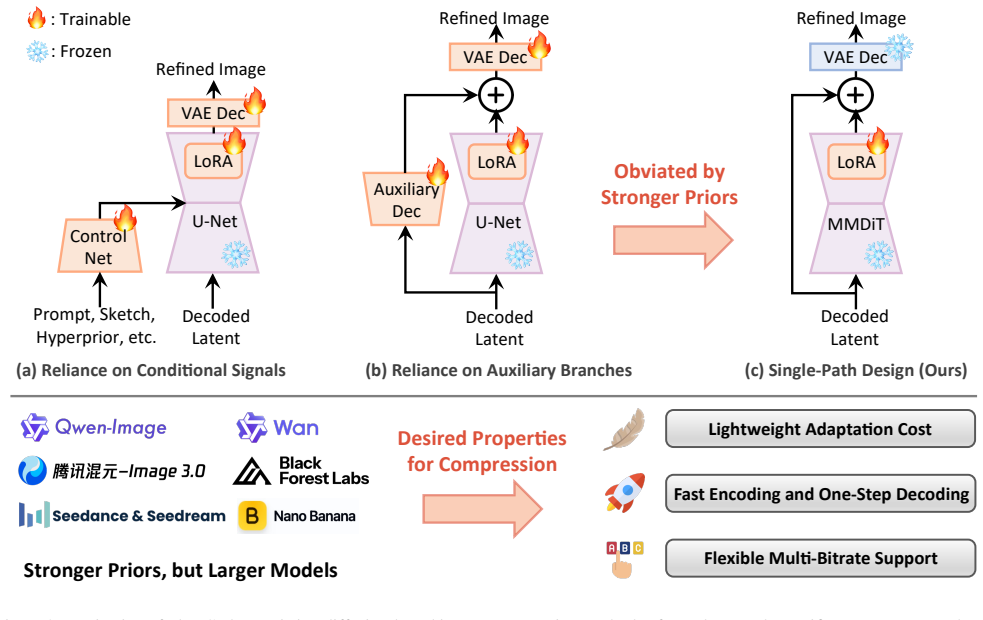
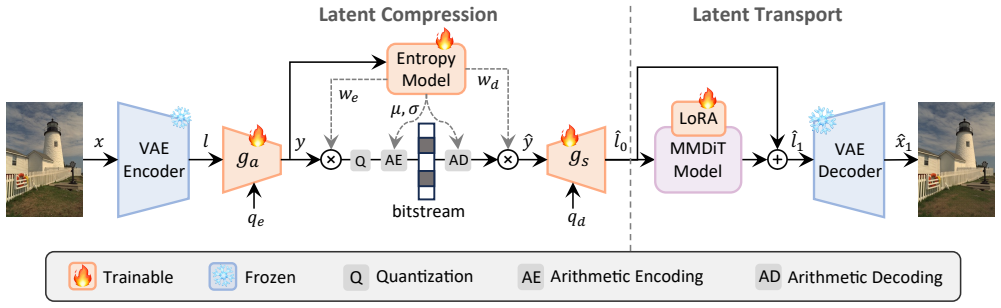
FlowCodec shows that pretrained text-to-image priors can be inserted directly into an image codec by decoupling latent compression from a single-step latent transport, with no additional conditioning signals or auxiliary networks needed, and that lightweight adaptation alone supports multiple bitrates while keeping trainable parameters below 0.54 percent of the backbone.
What carries the argument
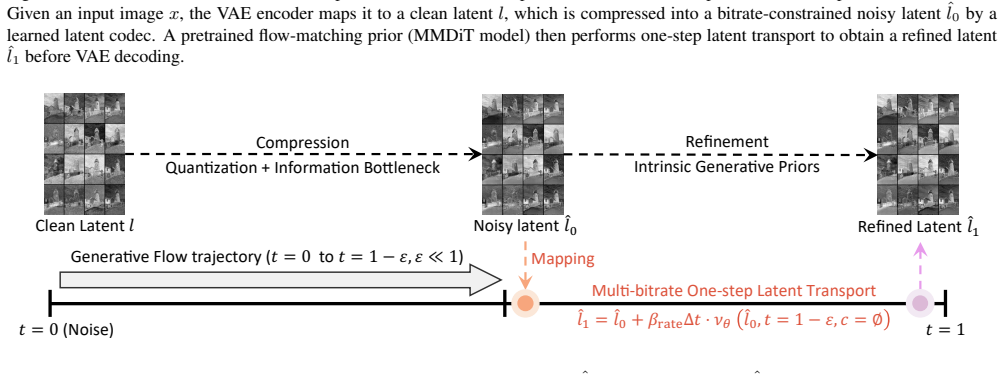
The one-step latent transport stage, which uses the pretrained flow prior to refine bitrate-constrained noisy latents toward clean ones.
If this is right
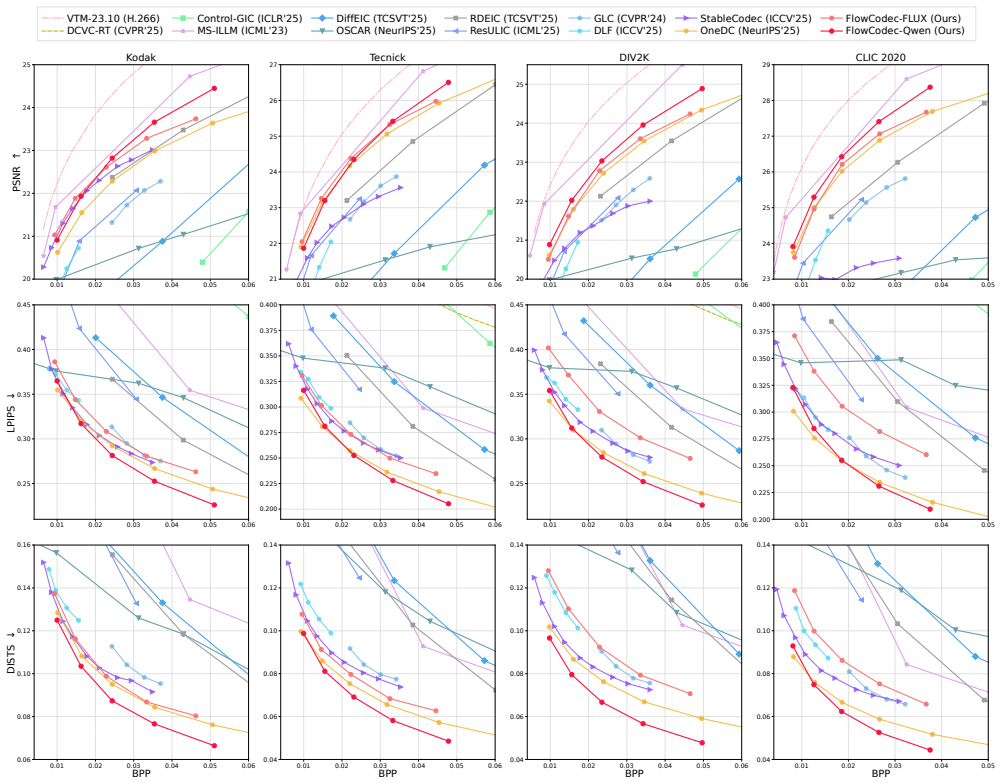
- High visual quality is preserved at bitrates below 0.05 bits per pixel.
- The Qwen-image variant outperforms existing methods on LPIPS and DISTS.
- Both variants achieve higher PSNR and faster encoding than existing one-step diffusion-based methods.
- Multiple bitrates can be supported while training under 0.54 percent of the generative backbone parameters.
Where Pith is reading between the lines
- The same decoupled compression-plus-transport pattern could be tested on video or audio using corresponding pretrained priors.
- Larger backbones might yield further gains at the same low adaptation cost.
- Direct prior reuse may reduce task-specific retraining needs in other low-rate generative tasks.
Load-bearing premise
That pretrained text-to-image models can directly refine noisy latents into high-quality clean images in one step with only lightweight adaptation and no extra conditioning signals.
What would settle it
A side-by-side test of whether removing the lightweight adaptation or forcing multi-step transport produces a measurable drop in LPIPS, DISTS, or PSNR at the same bitrate.
Figures









read the original abstract
Diffusion-based image compression methods, leveraging powerful generative priors, have demonstrated remarkable perceptual quality at ultra-low bitrates. However, adapting modern generative models to image compression often relies on carefully engineered conditioning or auxiliary branches, together with substantial retraining, and these costs grow as the models scale. This motivates an open question: Can stronger generative priors be integrated into compression through a simpler, more extensible design? To answer this, we propose FlowCodec, a streamlined framework that plugs pretrained large-scale text-to-image priors (e.g., Qwen-image-2512 and FLUX.1-dev) into ultra-low-bitrate codecs. FlowCodec decomposes the pipeline into two decoupled stages: (1) Latent Compression, which maps clean latents to bitrate-constrained noisy latents; and (2) Latent Transport, which leverages the pretrained prior to refine the noisy latents toward the clean ones in a single step. Notably, FlowCodec requires neither additional conditioning signals nor auxiliary networks. Furthermore, with lightweight adaptation, it can flexibly support multiple bitrates while keeping the number of trainable parameters below 0.54% of the generative backbone. Experiments show that FlowCodec preserves high visual quality at bitrates below 0.05 bits per pixel. The Qwen-image variant significantly outperforms existing methods in terms of LPIPS and DISTS, while both variants deliver higher PSNR and clearly faster encoding than existing one-step diffusion-based methods, with the FLUX variant also maintaining competitive decoding speed.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes FlowCodec, a two-stage framework for generative image compression at ultra-low bitrates that decouples latent compression (mapping clean latents to bitrate-constrained noisy latents) from single-step latent transport (using a pretrained text-to-image prior such as Qwen-image-2512 or FLUX.1-dev to refine noisy latents to clean ones). The design requires no additional conditioning signals or auxiliary networks, supports multiple bitrates via lightweight adaptation with <0.54% trainable parameters relative to the generative backbone, and claims to deliver high visual quality below 0.05 bpp while outperforming prior one-step diffusion methods in LPIPS, DISTS, PSNR, and encoding speed.
Significance. If the central claims are substantiated by the experiments, the work would offer a meaningful simplification for incorporating large-scale generative priors into compression codecs, reducing the engineering overhead of conditioning design and retraining while preserving extensibility and efficiency through the single-step transport mechanism. This could facilitate broader adoption of powerful pretrained models for perceptual compression tasks.
minor comments (2)
- The abstract references specific performance metrics (LPIPS, DISTS, PSNR) and bitrate thresholds but does not indicate the evaluation datasets or number of test images; adding this information would strengthen reproducibility claims.
- The description of 'lightweight adaptation' for multi-bitrate support would benefit from a brief statement on the adaptation mechanism (e.g., whether it involves LoRA-style updates or other parameter-efficient methods) to clarify the <0.54% parameter claim.
Simulated Author's Rebuttal
We thank the referee for their careful reading and for recognizing the potential of FlowCodec to simplify the integration of large-scale generative priors into compression codecs. The report raises no specific major comments or requests for clarification, so we provide no point-by-point rebuttals below. We remain available to supply additional experimental details or address any unlisted concerns the referee may have.
Circularity Check
No significant circularity
full rationale
The provided abstract and description contain no equations, fitted parameters presented as predictions, or self-citations that bear the central claims. The method is described as plugging in external pretrained models (Qwen-image, FLUX) with lightweight adaptation, and performance is evaluated against external benchmarks. No load-bearing step reduces by construction to an input defined within the paper itself. This is the common case of a self-contained empirical proposal relying on independent external priors and comparative experiments.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ntire 2017 challenge on single image super-resolution: Dataset and study
Eirikur Agustsson and Radu Timofte. Ntire 2017 challenge on single image super-resolution: Dataset and study. InIEEE Conf. Comput. Vis. Pattern Recog. Worksh., pages 126–135,
2017
-
[2]
Testimages: A large- scale archive for testing visual devices and basic image pro- cessing algorithms
Nicola Asuni, Andrea Giachetti, et al. Testimages: A large- scale archive for testing visual devices and basic image pro- cessing algorithms. InSTAG: Smart Tools and Applications in Computer Graphics, pages 63–70, 2014. 7, 1, 3
2014
-
[3]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-VL technical report.arXiv preprint arXiv:2511.21631, 2025. 10
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Variational image compression with a scale hyperprior
Johannes Ball ´e, David Minnen, Saurabh Singh, Sung Jin Hwang, and Nick Johnston. Variational image compression with a scale hyperprior. InInt. Conf. Learn. Represent., 2018. 3
2018
-
[5]
Jean B ´egaint, Fabien Racap ´e, Simon Feltman, and Akshay Pushparaja. CompressAI: A pytorch library and evalua- tion platform for end-to-end compression research.arXiv preprint arXiv:2011.03029, 2020. 6
-
[6]
Calculation of average PSNR differences between RD-curves.ITU-T SG16, Doc
Gisle Bjontegaard. Calculation of average PSNR differences between RD-curves.ITU-T SG16, Doc. VCEG-M33, 2001. 7, 1
2001
-
[7]
The perception-distortion tradeoff
Yochai Blau and Tomer Michaeli. The perception-distortion tradeoff. InIEEE Conf. Comput. Vis. Pattern Recog., pages 6228–6237, 2018. 1
2018
-
[8]
Rethinking lossy compres- sion: The rate-distortion-perception tradeoff
Yochai Blau and Tomer Michaeli. Rethinking lossy compres- sion: The rate-distortion-perception tradeoff. InInt. Conf. Mach. Learn., pages 675–685, 2019. 1
2019
-
[9]
HunyuanImage 3.0 Technical Report
Siyu Cao, Hangting Chen, Peng Chen, Yiji Cheng, Yutao Cui, Xinchi Deng, Ying Dong, Kipper Gong, Tianpeng Gu, Xiusen Gu, et al. HunyuanImage 3.0 technical report.arXiv preprint arXiv:2509.23951, 2025. 2, 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Towards image compression with per- fect realism at ultra-low bitrates
Marlene Careil, Matthew J Muckley, Jakob Verbeek, and St´ephane Lathuili`ere. Towards image compression with per- fect realism at ultra-low bitrates. InInt. Conf. Learn. Repre- sent., 2023. 2, 3
2023
-
[11]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. InIEEE Conf. Comput. Vis. Pattern Recog., pages 248–255. IEEE, 2009. 6
2009
-
[12]
Arcface: Additive angular margin loss for deep face recognition
Jiankang Deng, Jia Guo, Niannan Xue, and Stefanos Zafeiriou. Arcface: Additive angular margin loss for deep face recognition. InCVPR, 2019. 1
2019
-
[13]
Image quality assessment: Unifying structure and texture similarity.IEEE Trans
Keyan Ding, Kede Ma, Shiqi Wang, and Eero P Simoncelli. Image quality assessment: Unifying structure and texture similarity.IEEE Trans. Pattern Anal. Mach. Intell., 44(5): 2567–2581, 2020. 2, 7
2020
-
[14]
Scaling rec- tified flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas M ¨uller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, Dustin Podell, Tim Dockhorn, Zion English, and Robin Rombach. Scaling rec- tified flow transformers for high-resolution image synthesis. InInt. Conf. Mach. Learn., pages 12606–12633, 2024. 4
2024
-
[15]
Linear attention model- ing for learned image compression
Donghui Feng, Zhengxue Cheng, Shen Wang, Ronghua Wu, Hongwei Hu, Guo Lu, and Li Song. Linear attention model- ing for learned image compression. InIEEE Conf. Comput. Vis. Pattern Recog., pages 7623–7632, 2025. 3
2025
-
[16]
Yu Gao, Lixue Gong, Qiushan Guo, Xiaoxia Hou, Zhichao Lai, Fanshi Li, Liang Li, Xiaochen Lian, Chao Liao, Liyang Liu, et al. Seedream 3.0 technical report.arXiv preprint arXiv:2504.11346, 2025. 2, 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Generative adversarial nets
Ian J Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. InAdv. Neural Inform. Process. Syst.Curran Associates, Inc., 2014. 1, 2, 5
2014
-
[18]
OSCAR: One- step diffusion codec across multiple bit-rates
Jinpei Guo, Yifei Ji, Zheng Chen, Kai Liu, Min Liu, Wang Rao, Wenbo Li, Yong Guo, and Yulun Zhang. OSCAR: One- step diffusion codec across multiple bit-rates. InAdv. Neural Inform. Process. Syst.Curran Associates, Inc., 2025. 1, 2, 3, 4, 5, 7
2025
-
[19]
ELIC: Efficient learned image compres- sion with unevenly grouped space-channel contextual adap- tive coding
Dailan He, Ziming Yang, Weikun Peng, Rui Ma, Hongwei Qin, and Yan Wang. ELIC: Efficient learned image compres- sion with unevenly grouped space-channel contextual adap- tive coding. InIEEE Conf. Comput. Vis. Pattern Recog., pages 5718–5727, 2022. 3, 6
2022
-
[20]
Denoising dif- fusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising dif- fusion probabilistic models. InAdv. Neural Inform. Process. Syst., pages 6840–6851. Curran Associates, Inc., 2020. 4
2020
-
[21]
Lora: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models. Int. Conf. Learn. Represent., 1(2):3, 2022. 3
2022
-
[22]
Generative latent coding for ultra-low bitrate image com- pression
Zhaoyang Jia, Jiahao Li, Bin Li, Houqiang Li, and Yan Lu. Generative latent coding for ultra-low bitrate image com- pression. InIEEE Conf. Comput. Vis. Pattern Recog., pages 26088–26098, 2024. 1, 3, 7
2024
-
[23]
Towards practical real-time neu- ral video compression
Zhaoyang Jia, Bin Li, Jiahao Li, Wenxuan Xie, Linfeng Qi, Houqiang Li, and Yan Lu. Towards practical real-time neu- ral video compression. InIEEE Conf. Comput. Vis. Pattern Recog., pages 12543–12552, 2025. 1, 3, 5, 7
2025
-
[24]
Ultra lowrate image compression with semantic residual coding and compression-aware diffu- sion
Anle Ke, Xu Zhang, Tong Chen, Ming Lu, Chao Zhou, Ji- awen Gu, and Zhan Ma. Ultra lowrate image compression with semantic residual coding and compression-aware diffu- sion. InInt. Conf. Mach. Learn., pages 29626–29650, 2025. 2, 3, 7, 1
2025
-
[25]
Musiq: Multi-scale image quality transformer
Junjie Ke, Qifei Wang, Yilin Wang, Peyman Milanfar, and Feng Yang. Musiq: Multi-scale image quality transformer. InICCV, 2021. 1
2021
-
[26]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980,
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Auto-Encoding Variational Bayes
Diederik P Kingma and Max Welling. Auto-encoding varia- tional bayes.arXiv preprint arXiv:1312.6114, 2013. 3
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[28]
http://r0k.us/graphics/kodak/, 1993
Kodak lossless true color image suite. http://r0k.us/graphics/kodak/, 1993. 7, 1, 3
1993
-
[29]
Alina Kuznetsova, Hassan Rom, Neil Alldrin, Jasper Ui- jlings, Ivan Krasin, Jordi Pont-Tuset, Shahab Kamali, Stefan Popov, Matteo Malloci, Alexander Kolesnikov, et al. The open images dataset v4: Unified image classification, object detection, and visual relationship detection at scale.Interna- tional journal of computer vision, 128(7):1956–1981, 2020. 6 10
1956
-
[30]
Black Forest Labs. Flux. https://github.com/black-forest- labs/flux, 2024. 2, 5, 6
2024
-
[31]
Flux.1 kontext: Flow matching for in-context image generation and editing in latent space,
Black Forest Labs, Stephen Batifol, Andreas Blattmann, Frederic Boesel, Saksham Consul, Cyril Diagne, Tim Dock- horn, Jack English, Zion English, Patrick Esser, Sumith Ku- lal, Kyle Lacey, Yam Levi, Cheng Li, Dominik Lorenz, Jonas M¨uller, Dustin Podell, Robin Rombach, Harry Saini, Axel Sauer, and Luke Smith. Flux.1 kontext: Flow matching for in-context i...
-
[32]
Text+ sketch: Image compression at ultra low rates
Eric Lei, Yigit Berkay Uslu, Hamed Hassani, and Shirin Saeedi Bidokhti. Text+ sketch: Image compression at ultra low rates. InInt. Conf. Mach. Learn. Worksh., 2023. 2, 3
2023
-
[33]
Once-for-All: Controllable generative image compression with dynamic granularity adaptation
Anqi Li, Feng Li, Yuxi Liu, Runmin Cong, Yao Zhao, and Huihui Bai. Once-for-All: Controllable generative image compression with dynamic granularity adaptation. InInt. Conf. Learn. Represent., 2025. 2, 3, 7, 1
2025
-
[34]
Neural video compression with diverse contexts
Jiahao Li, Bin Li, and Yan Lu. Neural video compression with diverse contexts. InIEEE Conf. Comput. Vis. Pattern Recog., pages 22616–22626, 2023. 5
2023
-
[35]
Neural video compression with feature modulation
Jiahao Li, Bin Li, and Yan Lu. Neural video compression with feature modulation. InIEEE Conf. Comput. Vis. Pattern Recog., pages 26099–26108, 2024. 5, 6
2024
-
[36]
Towards extreme image compression with latent feature guidance and diffusion prior.IEEE Trans
Zhiyuan Li, Yanhui Zhou, Hao Wei, Chenyang Ge, and Jing- wen Jiang. Towards extreme image compression with latent feature guidance and diffusion prior.IEEE Trans. Circuit Syst. Video Technol., 35(1):888–899, 2025. 2, 3, 7, 1
2025
-
[37]
RDEIC: Accelerating diffusion-based extreme image compression with relay residual diffusion.IEEE Trans
Zhiyuan Li, Yanhui Zhou, Hao Wei, Chenyang Ge, and Aj- mal Mian. RDEIC: Accelerating diffusion-based extreme image compression with relay residual diffusion.IEEE Trans. Circuit Syst. Video Technol., 35(11):11540–11552,
-
[38]
Flow matching for generative modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximil- ian Nickel, and Matthew Le. Flow matching for generative modeling. InInt. Conf. Learn. Represent., 2022. 4
2022
-
[39]
Learned im- age compression with mixed transformer-cnn architectures
Jinming Liu, Heming Sun, and Jiro Katto. Learned im- age compression with mixed transformer-cnn architectures. InIEEE Conf. Comput. Vis. Pattern Recog., pages 14388– 14397, 2023. 3
2023
-
[40]
Flow straight and fast: Learning to generate and transfer data with rectified flow
Xingchao Liu, Chengyue Gong, et al. Flow straight and fast: Learning to generate and transfer data with rectified flow. In Int. Conf. Learn. Represent., 2023. 4
2023
-
[41]
High-fidelity generative image compres- sion
Fabian Mentzer, George D Toderici, Michael Tschannen, and Eirikur Agustsson. High-fidelity generative image compres- sion. InAdv. Neural Inform. Process. Syst., pages 11913– 11924. Curran Associates, Inc., 2020. 2, 3
2020
-
[42]
completely blind
Anish Mittal, Rajiv Soundararajan, and Alan C. Bovik. Mak- ing a “completely blind” image quality analyzer.SPL, 2013. 1
2013
-
[43]
Improving statistical fi- delity for neural image compression with implicit local like- lihood models
Matthew J Muckley, Alaaeldin El-Nouby, Karen Ullrich, Herv´e J ´egou, and Jakob Verbeek. Improving statistical fi- delity for neural image compression with implicit local like- lihood models. InInt. Conf. Mach. Learn., pages 25426– 25443. PMLR, 2023. 2, 3, 6, 7, 1
2023
-
[44]
High-resolution image syn- thesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj¨orn Ommer. High-resolution image syn- thesis with latent diffusion models. InIEEE Conf. Comput. Vis. Pattern Recog., pages 10684–10695, 2022. 2, 3, 4, 9
2022
-
[45]
Adversarial diffusion distillation
Axel Sauer, Dominik Lorenz, Andreas Blattmann, and Robin Rombach. Adversarial diffusion distillation. InEur. Conf. Comput. Vis., pages 87–103, 2024. 3
2024
-
[46]
Seedance 1.5 pro: A Native Audio-Visual Joint Generation Foundation Model
Team Seedance, Heyi Chen, Siyan Chen, Xin Chen, Yan- fei Chen, Ying Chen, Zhuo Chen, Feng Cheng, Tianheng Cheng, Xinqi Cheng, et al. Seedance 1.5 pro: A native audio- visual joint generation foundation model.arXiv preprint arXiv:2512.13507, 2025. 2, 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
Very Deep Convolutional Networks for Large-Scale Image Recognition
Karen Simonyan and Andrew Zisserman. Very deep convo- lutional networks for large-scale image recognition.arXiv preprint arXiv:1409.1556, 2014. 7
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[48]
A hybrid scheme for face video compres- sion.ACM Trans
Anni Tang, Zhiyu Zhang, Chen Zhu, Jun Ling, Rong Xie, and Li Song. A hybrid scheme for face video compres- sion.ACM Trans. Multimedia Comput. Commun. Appl., 22 (1), 2026. 3
2026
-
[49]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean- Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023. 2, 4
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[50]
StableCodec: Taming one-step diffusion for extreme image compression
Zhang Tianyu, Luo Xin, Li Li, and Liu Dong. StableCodec: Taming one-step diffusion for extreme image compression. InInt. Conf. Comput. Vis., 2025. 1, 2, 3, 4, 7
2025
-
[51]
Workshop and challenge on learned image compression (clic2020)
George Toderici, Wenzhe Shi, Radu Timofte, Lucas Theis, Johannes Balle, Eirikur Agustsson, Nick Johnston, and Fabian Mentzer. Workshop and challenge on learned image compression (clic2020). InIEEE Conf. Comput. Vis. Pattern Recog., 2020. 7, 1, 3
2020
-
[52]
https://vcgit.hhi.fraunhofer.de/jvet/VVCSoftware VTM/
VTM-23.10. https://vcgit.hhi.fraunhofer.de/jvet/VVCSoftware VTM/. Accessed: 2026-03-02. 3, 7, 1
2026
-
[53]
G.K. Wallace. The jpeg still picture compression standard. IEEE Transactions on Consumer Electronics, 38(1), 1992. 3
1992
-
[54]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video gen- erative models.arXiv preprint arXiv:2503.20314, 2025. 2, 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
Ex- ploring clip for assessing the look and feel of images
Jianyi Wang, Kelvin CK Chan, and Chen Change Loy. Ex- ploring clip for assessing the look and feel of images. In AAAI, 2023. 1
2023
-
[56]
One- shot free-view neural talking-head synthesis for video con- ferencing
Ting-Chun Wang, Arun Mallya, and Ming-Yu Liu. One- shot free-view neural talking-head synthesis for video con- ferencing. InIEEE Conf. Comput. Vis. Pattern Recog., pages 10039–10049, 2021. 3
2021
-
[57]
Multi- scale structural similarity for image quality assessment
Zhou Wang, Eero P Simoncelli, and Alan C Bovik. Multi- scale structural similarity for image quality assessment. In The thirty-seventh Asilomar Conference on Signals, Systems & Computers, 2003, pages 1398–1402. IEEE, 2003. 3
2003
-
[58]
Hunyuanvideo 1.5 technical report, 2025
Bing Wu, Chang Zou, Changlin Li, Duojun Huang, Fang Yang, Hao Tan, Jack Peng, Jianbing Wu, Jiangfeng Xiong, Jie Jiang, et al. Hunyuanvideo 1.5 technical report, 2025. 2, 4
2025
-
[59]
Qwen-image technical report, 2025
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng-ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, et al. Qwen-image technical report, 2025. 2, 4, 5, 6 11
2025
-
[60]
Enze Xie, Junsong Chen, Yuyang Zhao, Jincheng Yu, Ligeng Zhu, Chengyue Wu, Yujun Lin, Zhekai Zhang, Muyang Li, Junyu Chen, et al. Sana 1.5: Efficient scaling of training-time and inference-time compute in linear diffusion transformer. arXiv:2501.18427, 2025. 9
-
[61]
One-step diffusion-based image compression with semantic distillation
Naifu Xue, Zhaoyang Jia, Jiahao Li, Bin Li, Yuan Zhang, and Yan Lu. One-step diffusion-based image compression with semantic distillation. InAdv. Neural Inform. Process. Syst.Curran Associates, Inc., 2025. 1, 2, 3, 4, 7
2025
-
[62]
DLF: Extreme image compression with dual- generative latent fusion
Naifu Xue, Zhaoyang Jia, Jiahao Li, Bin Li, Yuan Zhang, and Yan Lu. DLF: Extreme image compression with dual- generative latent fusion. InInt. Conf. Comput. Vis., 2025. 3, 7, 1
2025
-
[63]
On perceptual lossy compression: The cost of perceptual re- construction and an optimal training framework
Zeyu Yan, Fei Wen, Rendong Ying, Chao Ma, and Peilin Liu. On perceptual lossy compression: The cost of perceptual re- construction and an optimal training framework. InInt. Conf. Mach. Learn., pages 11682–11692, 2021. 2, 3
2021
-
[64]
Lossy image compression with conditional diffusion models
Ruihan Yang and Stephan Mandt. Lossy image compression with conditional diffusion models. InAdv. Neural Inform. Process. Syst., pages 64971–64995. Curran Associates, Inc.,
-
[65]
Mambaic: State space models for high- performance learned image compression
Fanhu Zeng, Hao Tang, Yihua Shao, Siyu Chen, Ling Shao, and Yan Wang. Mambaic: State space models for high- performance learned image compression. InIEEE Conf. Comput. Vis. Pattern Recog., pages 18041–18050, 2025. 3
2025
-
[66]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InIEEE Conf. Comput. Vis. Pattern Recog., pages 586–595, 2018. 1, 2, 5, 7
2018
-
[67]
Jialong Zuo, Haoyou Deng, Hanyu Zhou, Jiaxin Zhu, Yicheng Zhang, Yiwei Zhang, Yongxin Yan, Kaixing Huang, Weisen Chen, Yongtai Deng, et al. Is nano banana pro a low-level vision all-rounder? a comprehensive evaluation on 14 tasks and 40 datasets.arXiv preprint arXiv:2512.15110,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.