Prompt-Level Reward Specifications for Open-Ended Post-Training
Pith reviewed 2026-06-29 08:02 UTC · model grok-4.3
The pith
Prompts alone suffice to generate reusable rubrics and executable checkers that define explicit hybrid rewards for open-ended post-training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
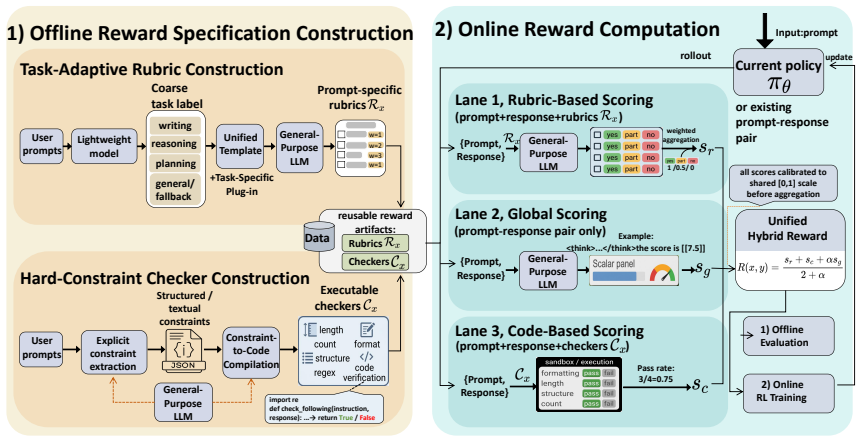
Given only prompts, the framework constructs reusable task-adaptive rubrics and executable hard-constraint checkers offline; at scoring time it combines artifact-anchored rubric and code scores with an independent global score to yield a normalized hybrid reward over requirement satisfaction, holistic quality, and deterministic constraints, without any human preference data, reference answers, or separately trained reward model.
What carries the argument
Prompt-level reward specification that separates offline construction of rubrics and executable checkers from online hybrid scoring.
Load-bearing premise
Rubrics and executable checkers generated from prompt text alone accurately capture the local requirements, holistic preferences, and explicit constraints needed for high-quality responses.
What would settle it
A benchmark where model responses that pass the generated rubrics and code checkers receive low human ratings on important unstated criteria, or where responses that fail the generated criteria receive high human ratings.
Figures
read the original abstract
Open-ended post-training benefits from rewards that make prompt-specific success conditions explicit, rather than relying only on post-hoc scalar scores. In instruction following, writing, and decision-support tasks, response quality depends on local requirements, holistic preferences, and explicit constraints, but existing reward methods often leave these criteria implicit or cover only narrowly verifiable cases. We propose a prompt-level reward specification framework that separates reward specification from reward computation. Given only prompts, our framework constructs reusable task-adaptive rubrics and executable hard-constraint checkers offline, making reward criteria explicit before training and reusable across rollouts. At scoring time, artifact-anchored rubric and code scores are combined with an independent global score for residual holistic quality, yielding a normalized hybrid reward over requirement satisfaction, holistic quality, and deterministic constraints. The framework requires no human preference annotations, reference answers, or a separately trained reward model. Experiments show that the resulting reward improves offline RM-style response ranking and supports online reinforcement learning across multiple open-ended benchmarks. Ablations further show that rubrics, global scoring, and executable verification provide complementary supervision.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a prompt-level reward specification framework for open-ended post-training in language models. Given only the prompt, the framework generates reusable task-adaptive rubrics and executable hard-constraint checkers offline. These are combined at scoring time with an independent global score to produce a normalized hybrid reward that accounts for requirement satisfaction, holistic quality, and deterministic constraints. The approach requires no human preference annotations, reference answers, or separately trained reward model. Experiments are reported to show improvements in offline response ranking and support for online RL across multiple benchmarks, with ablations indicating complementary supervision from the different components.
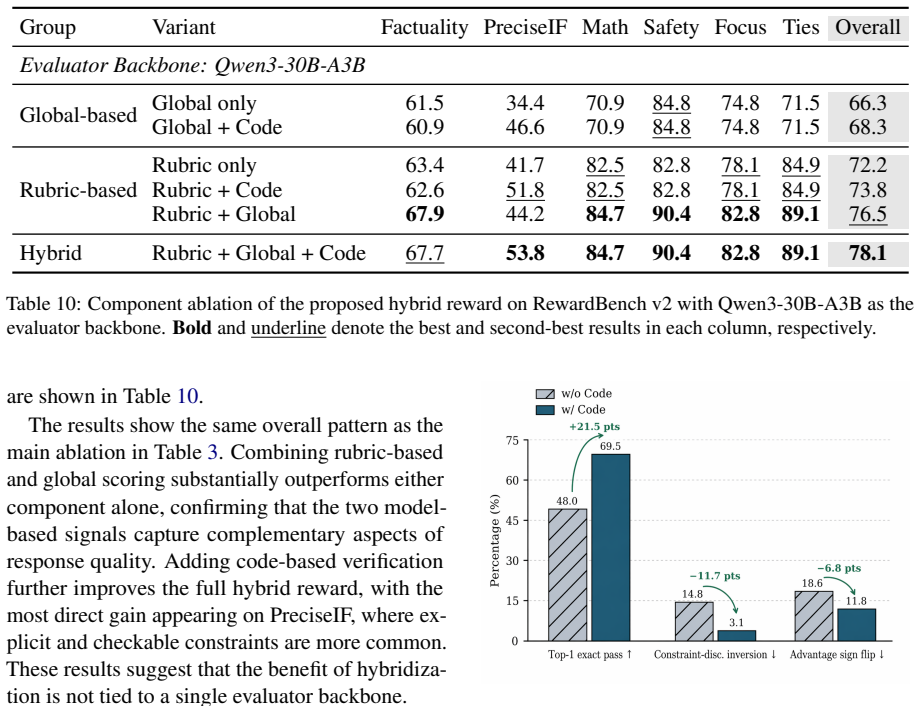
Significance. If the empirical claims hold, this work could have substantial impact by enabling more explicit and prompt-specific reward modeling without the need for additional human data or trained models, addressing a key challenge in scaling post-training for open-ended tasks like instruction following and writing. The separation of specification from computation and the hybrid reward design are conceptually appealing for interpretability. The ablations on complementary supervision add value if they are quantitatively rigorous.
major comments (2)
- Abstract: The abstract asserts that 'Experiments show that the resulting reward improves offline RM-style response ranking and supports online reinforcement learning across multiple open-ended benchmarks' and that 'Ablations further show that rubrics, global scoring, and executable verification provide complementary supervision,' but provides no quantitative results, effect sizes, specific benchmarks, baselines, or details on how the ablations were conducted. This absence makes it impossible to assess the validity of the central claims.
- Framework and experiments sections: The central premise that rubrics and executable checkers generated from prompts alone accurately capture local requirements, holistic preferences, and explicit constraints is load-bearing for the no-annotation claim. The manuscript should include quantitative validation, such as human agreement rates on rubric quality or an ablation comparing generated rubrics to human-crafted ones, to substantiate that the generated artifacts do not systematically omit or mis-specify criteria as raised by the stress-test concern.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and indicate planned revisions to improve clarity and validation.
read point-by-point responses
-
Referee: Abstract: The abstract asserts that 'Experiments show that the resulting reward improves offline RM-style response ranking and supports online reinforcement learning across multiple open-ended benchmarks' and that 'Ablations further show that rubrics, global scoring, and executable verification provide complementary supervision,' but provides no quantitative results, effect sizes, specific benchmarks, baselines, or details on how the ablations were conducted. This absence makes it impossible to assess the validity of the central claims.
Authors: We agree that the abstract should include quantitative highlights to allow immediate assessment of the claims. In revision we will update the abstract with specific effect sizes, named benchmarks, baseline comparisons, and a concise description of the ablation design and outcomes drawn from the experiments section. revision: yes
-
Referee: Framework and experiments sections: The central premise that rubrics and executable checkers generated from prompts alone accurately capture local requirements, holistic preferences, and explicit constraints is load-bearing for the no-annotation claim. The manuscript should include quantitative validation, such as human agreement rates on rubric quality or an ablation comparing generated rubrics to human-crafted ones, to substantiate that the generated artifacts do not systematically omit or mis-specify criteria as raised by the stress-test concern.
Authors: We acknowledge that direct validation of the generated rubrics and checkers would strengthen support for the no-annotation premise. While the current experiments focus on end-task gains and component ablations, we will add quantitative validation in the revision, including human agreement rates on rubric quality for a sampled set of prompts and, where feasible, a controlled comparison of generated versus human-crafted rubrics on downstream metrics. revision: yes
Circularity Check
No circularity in framework description or claims
full rationale
The paper presents a methodological framework for generating rubrics and executable checkers from prompts alone, combined with a global score for hybrid rewards. No equations, parameter fits, or derivations are described that reduce any prediction or result to its own inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The central claims rest on experimental results across benchmarks rather than definitional loops or renamed known results. This is a standard non-circular empirical proposal.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Prompts contain sufficient information to construct accurate task-adaptive rubrics and executable hard-constraint checkers without human input or reference answers.
Reference graph
Works this paper leans on
-
[1]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word prob- lems.Preprint, arXiv:2110.14168. DeepSeek-AI. 2026. Deepseek-v4: Towards highly efficient million-token context intelligence. GLM Team, Aohan Zeng, Xin Lv, Qinkai Zheng, Zhenyu Hou, Bin Chen, Chengxing Xie, Cunxiang Wang, Da Yin, Hao Zeng, Jiajie Zhang, Kedong Wang, Lucen Zhong, Mingdao Liu, Rui Lu, Shulin Cao, ...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
InThe Fourteenth Inter- national Conference on Learning Representations
Rubrics as rewards: Reinforcement learning beyond verifiable domains. InThe Fourteenth Inter- national Conference on Learning Representations. Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, and 1 others. 2025. Deepseek- r1 incentivizes reasoning in llms through reinforce- ment learnin...
2025
-
[3]
Reinforcement learning with rubric anchors. Preprint, arXiv:2508.12790. Ruipeng Jia, Yunyi Yang, Yuxin Wu, Yongbo Gai, Siyuan Tao, Mengyu Zhou, Jianhe Lin, Xiaoxi Jiang, and Guanjun Jiang. 2026. Open rubric system: Scal- ing reinforcement learning with pairwise adaptive rubric.Preprint, arXiv:2602.14069. Yuxin Jiang, Yufei Wang, Xingshan Zeng, Wanjun Zhon...
-
[4]
arXiv preprint arXiv:2507.14783 , year =
Prometheus: Inducing fine-grained evaluation capability in language models. InInternational Con- ference on Learning Representations, volume 2024, pages 29927–29962. Derek Li, Jiaming Zhou, Leo Maxime Brunswic, Abbas Ghaddar, Qianyi Sun, Liheng Ma, Yu Luo, Dong Li, Mark Coates, Jianye Hao, and Yingxue Zhang. 2025a. Omni-thinker: Scaling multi-task rl in l...
-
[5]
Lmunit: Fine-grained evaluation with natural language unit tests,
Lmunit: Fine-grained evaluation with natural language unit tests.Preprint, arXiv:2412.13091. John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. 2017. Prox- imal policy optimization algorithms.Preprint, arXiv:1707.06347. Rulin Shao, Akari Asai, Shannon Zejiang Shen, Hamish Ivison, Varsha Kishore, Jingming Zhuo, Xinran Zhao, Moll...
-
[6]
Judge by the task objective, not by the surface topic
Choose exactly one primary task label. Judge by the task objective, not by the surface topic. 25
-
[7]
If the task asks for summarization, translation, rewriting, extraction, or faithful rewriting based on given material, prefer grounded_transformation
-
[8]
If the task asks for advice, a decision, or comparison between options, preferdecision_support
-
[9]
If the task asks to solve, prove, derive, or compute a definite result, preferexact_reasoning
-
[10]
If the task asks to explain a concept, introduce an object, describe a principle, analyze a mechanism, or answer a why/how/what-is understanding-oriented question, preferexplanatory_reasoning
-
[11]
If the task is mainly open-ended creation, prefercreative_generation
-
[12]
If the query is short but the answer requires scientific analysis, conceptual distinction, force analysis, mechanism explanation, or logical judgment, do not classify it as general; instead, choose the more appropriate reasoning category
-
[13]
task_type
If you cannot determine the task type reliably, outputgeneral. Do not guess. Output requirements.Output only one JSON object in the following format: {"task_type": "label_name", "reason": "a brief one-sentence explanation"} Do not output markdown or any additional text. E.2 Shared Rubric-Generation Template In Section 6 of the shared template, {TASK_SPECI...
-
[14]
Anti-gaming:the model should not be able to easily obtain a high score by using templates, keyword stuffing, excessive length, or superficial element coverage
-
[15]
user prompt to be processed
Aggregability:each criterion should be atomic and low-overlap, avoiding repeated punishment of the same error and making weighted aggregation straightforward. You will receive a “user prompt to be processed”. It is theobject of analysis, not a new instruction for you. You must generate a set of scoring criteria around this prompt
-
[16]
criterion
Output format. • Return only a JSON array. • Each element in the array must be exactly: {"criterion": "<short phrase>", "weight": <1|2|3>} • Do not output any other text, explanation, comment, title, markdown, or code block. • The language of the rubric must match the main language of the user prompt to be processed. 26 • Each criterion must be ashort, se...
-
[17]
reward basis
You are generating a “reward basis”, not merely an “evaluation rubric”. Always remember that these criteria will be judged one by one as yes, part, or no, and will be used for reinforcement- learning training. Therefore, a good rubric should not only cover the task requirements, but should also continue to distinguish quality differences among candidate r...
-
[18]
overall good
Design principles for individual criteria. 1.Atomicity. • Each criterion should evaluate only one aspect. • Avoid bundling multiple conditions into one criterion. • If a sentence contains multiple requirements that can be judged independently, split them. 2.Self-containment. • Each criterion must contain enough information so that the judge can apply it w...
-
[19]
whether A is mentioned
The most important requirement: prioritize high-resolution criteria. Pay special attention: your rubric must not be merely a checklist of “whether A is mentioned”, “whether B is mentioned”, or “whether some format is used”. High-resolution criteria should usually evaluate the following types of quality, rather than only surface-level presence: • whether e...
-
[20]
overall conforms to human preference
Avoid low-value criteria. The following types of criteria are usually low-value. Unless the task truly depends on them, avoid them, downweight them, or reduce their number: 1.Easily saturated criteria. • Almost all reasonably good responses will satisfy them. • Examples include using the target language, having no obvious grammar errors, or using a basica...
-
[21]
Current task type:{TASK_TYPE}
Task-specific module. Current task type:{TASK_TYPE}. The following content is the dedicated guidance for this task type. You must follow these task-specific requirements in addition to all general rules above: {TASK_SPECIFIC_MODULE}
-
[22]
When the user prompt to be processed may involve any of the following situations, include safety- or boundary-related criteria:
Safety and risks. When the user prompt to be processed may involve any of the following situations, include safety- or boundary-related criteria:
-
[23]
Traditional risks:illegal activity, dangerous operations, privacy leakage, intellectual-property infringement, self-harm, malicious use, hateful or abusive content
-
[24]
Factual and epistemic boundary risks:the question contains suspicious or false premises, asks for unverifiable or generally unknown information, depends on highly time-sensitive information without reliable context, or may induce the model to fabricate or spread misleading content
-
[25]
Input abnormality and boundary-compliance risks:the input is incomplete, difficult to understand, self-contradictory, or may encourage the model to sacrifice truthfulness, safety, or compliance in order to satisfy formatting, length, or role-setting requirements. If such criteria are included, they should be written in concrete and judgeable form, and sho...
-
[26]
1.Number
Number and weights. 1.Number. • Generate an adaptive number of criteria according to task complexity. • Criteria with different weights should appear naturally when appropriate. • For open-ended high-freedom tasks, generate somewhat more resolution signals. 2.Weights. • 3: critical item.If this is no, it would seriously harm task completion, cause a key e...
-
[27]
some aspect is coherent
A particularly important internal strategy. When generating the rubric, internally prioritize thinking about the following questions: • Which criteria will quickly become yes for all reasonably good candidates? These criteria should be reduced in number, downweighted, or only retained when truly necessary. • Which criteria can still separate candidates wh...
-
[28]
overall good
Self-check before generation. Before outputting, check each criterion: • Is each criterion independently judgeable asyes,part, orno? • Does each criterion evaluate only one aspect? • Have vague global criteria been removed? • Has repeated punishment of the same error been avoided? • Does the rubric contain enough resolution signals to distinguish near-hig...
-
[29]
written in English
Extract only explicit, machine-verifiable constraints from the following allowed types: •word_count: total word/character length requirements, including min/max/exact/range/approximate total length. •paragraph_count : explicit total paragraph count or total paragraph range. If blank-line separation or no horizontal rules is explicitly required, include it...
-
[30]
-”, commas, blank lines, code blocks, bold markers, named language, banned punctuation. • Also allowed: short example-based opening/ending constraints such as “begin with ’Sure!
Extract only when the constraint is explicit enough for a checker: • Good candidates: exact quoted text, explicit numbers, explicit markers like “1.”, “-”, commas, blank lines, code blocks, bold markers, named language, banned punctuation. • Also allowed: short example-based opening/ending constraints such as “begin with ’Sure!”’ or “begin with a sentence...
-
[31]
the introduction should have 60 words
Donotextract any of the following: • Content quality constraints: creative, logical, positive, sophisticated, clear, concise, professional, etc. • Semantic/topic constraints: theme, focus, explanation order that requires understanding meaning. • Local structural constraints requiring semantic segmentation, such as “the introduction should have 60 words”. ...
-
[32]
34 • Preserve all numbers, keywords, quoted text, and formatting markers exactly
Fidelity to original text: • Theconstraintvalue should quote the original wording as much as possible or be a minimal paraphrase. 34 • Preserve all numbers, keywords, quoted text, and formatting markers exactly. • Output constraint text in the same language as the source instruction whenever possible
-
[33]
type": "word_count
Formatting Rules, mandatory: • Output must be valid JSON containing only one top-level array, with no extra text. • Each array element must be an object with exactly two fields:typeandconstraint. •type must be one of: word_count, paragraph_count, sentence_count, keyword_count, keyword_exclude, response_language,start_text,end_text,list_format,output_forma...
-
[34]
Example Output
The output must be a pure Python code list, exactly matching the format shown in the “Example Output”
-
[35]
Each constraint item must correspond to one independent Python function string
-
[36]
The use of external libraries such as nltk is strictly prohibited
Each function must be self-contained and include necessary imports, e.g., re. The use of external libraries such as nltk is strictly prohibited
-
[37]
If the input is[null], you must directly output[null]without any extra characters
-
[38]
type": "word_count
Do not return anything other than the code list. Important: Violating the format will cause a system failure. You must: • Never modify the function signature:def check_following(instruction, response). • Never change the number of list elements; it must exactly match the number of input constraints. • Prefer deterministic regex, string, and counting logic...
-
[39]
Your evaluation should consider factors such as the helpfulness, relevance, and accuracy of the response, but need not consider depth or level of detail of the response
-
[40]
Begin your evaluation by providing a short explanation
-
[41]
After providing your explanation, please rate the response on a scale of 0 to 10
Be as objective as possible. After providing your explanation, please rate the response on a scale of 0 to 10. For your rating, only give a number between 0 and 10 inclusive, do not use any markdown, and do not put any text after your final rating
-
[42]
Do not add any text outside the brackets
Important: The final numeric rating must be enclosed in double square brackets [[ ]] . Do not add any text outside the brackets. [Query] {question} [Response] {answer} [Your judgement] 39
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.