PhiBE-Q-Learning: Bridging Off-Policy Reinforcement Learning and Continuous-Time Control
Pith reviewed 2026-06-26 11:57 UTC · model grok-4.3
The pith
A new state-action value function in continuous-time control enables off-policy Q-learning from discrete data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce a new definition of the state-action value function in CTRL and derive its governing equation. Building on the PhiBE approximation, we propose iterative algorithms to approximate the optimal Q-function in both model-based and model-free settings using only discrete-time off-policy data. Under linear function approximation, we establish convergence guarantees and derive explicit convergence rates for the proposed method.
What carries the argument
New state-action value function whose governing equation is discretized and solved via the PhiBE approximation to produce off-policy Q-updates from discrete samples.
If this is right
- Model-based and model-free iterative schemes recover the optimal Q from off-policy discrete trajectories.
- Explicit convergence rates hold whenever linear function approximation is used.
- Off-policy learning becomes possible in CTRL even though the classical Q-function is undefined.
- Only discrete-time samples are required; continuous-time derivatives need not be observed.
Where Pith is reading between the lines
- The same construction may allow off-policy updates in other continuous-time settings once an analogous governing equation can be written.
- Hybrid discrete-continuous controllers could be trained by switching between the new Q and existing discrete Q-functions on the same trajectory data.
- If the linear approximation error can be bounded for wider function classes, the method may extend beyond the linear case without changing the sampling requirement.
Load-bearing premise
The newly defined state-action value function exists, satisfies a usable governing equation, and can be approximated by PhiBE from discrete off-policy data.
What would settle it
Numerical runs on a simple linear SDE where the proposed linear-function-approximation iteration fails to approach the true optimal Q as the number of discrete samples grows.
Figures
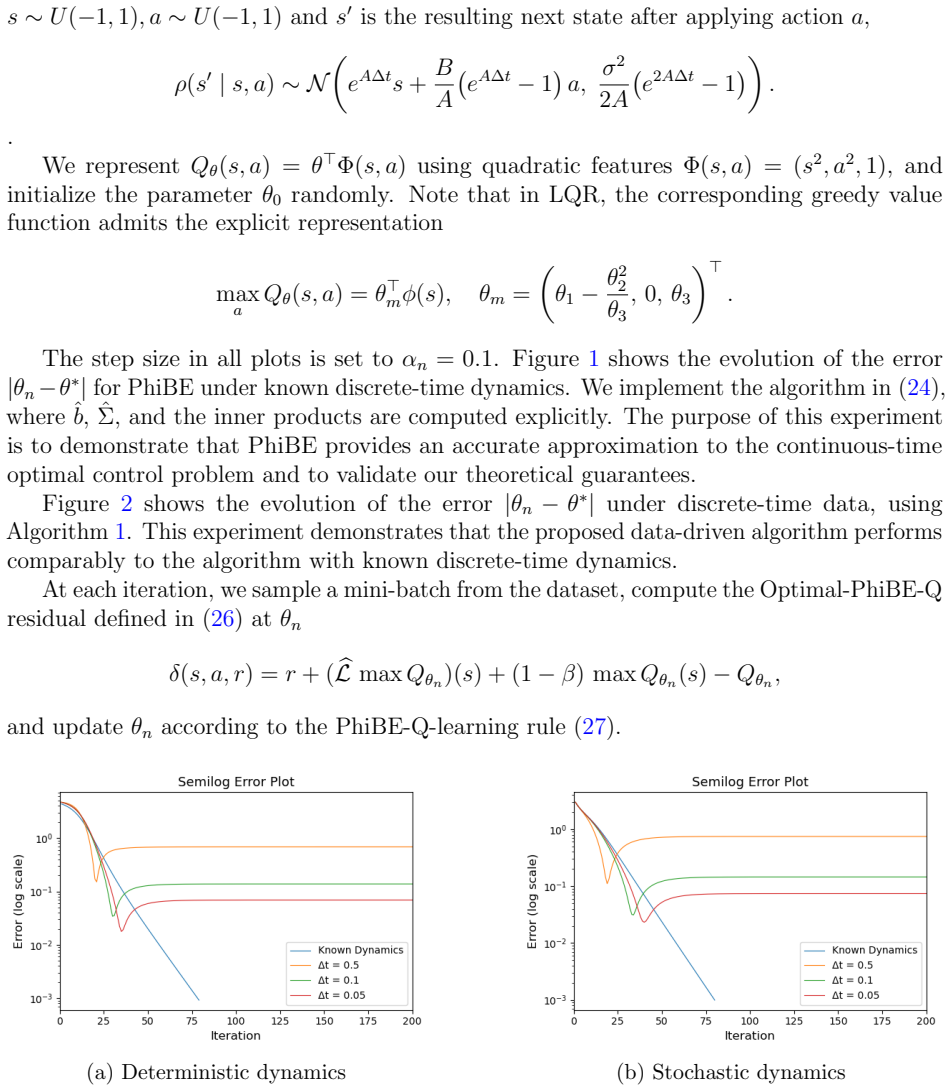
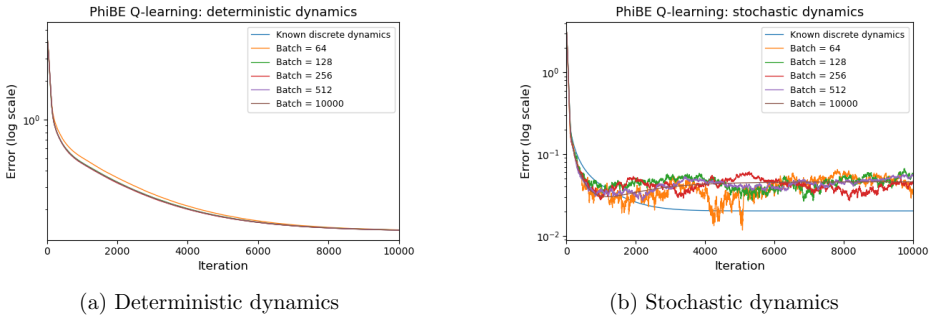
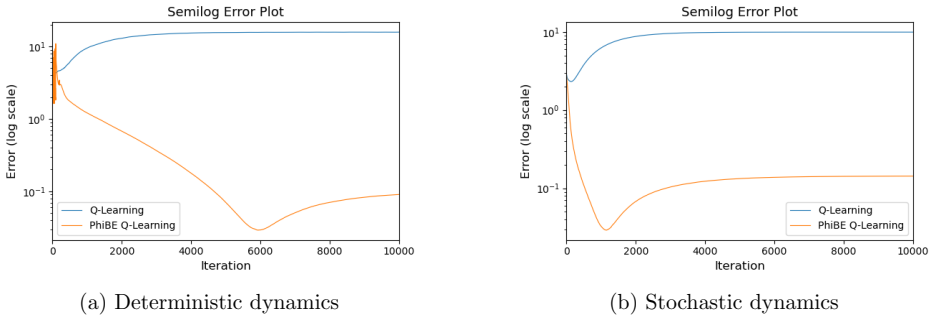
read the original abstract
In this paper, we develop an off-policy method for continuous-time reinforcement learning (CTRL), where the system dynamics are governed by an unknown stochastic differential equation (SDE) and only discrete-time trajectory data are available. A central challenge is that the classical state-action value function $Q(s,a)$, which enables off-policy learning in discrete-time RL, does not exist in CTRL (Baird, 1994; Jia and Zhou, 2023; Tallec et al., 2019). On the other hand, continuous-time control provides local notions such as the instantaneous advantage function $q(s,a)$, but these typically rely on state value function $V(s)$. To address this, we introduce a new definition of the state-action value function in CTRL and derive its governing equation. Building on the PhiBE approximation (Zhu, 2024; Zhu et al., 2025), we propose iterative algorithms to approximate the optimal $Q$-function in both model-based and model-free settings using only discrete-time off-policy data. Under linear function approximation, we establish convergence guarantees and derive explicit convergence rates for the proposed method.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce a new definition of the state-action value function for continuous-time reinforcement learning (CTRL) governed by unknown SDEs, where the classical Q(s,a) does not exist. It derives the governing equation for this new Q, then applies the PhiBE approximation to develop iterative PhiBE-Q-Learning algorithms for model-based and model-free off-policy approximation of the optimal Q from discrete-time trajectory data only. Under linear function approximation, convergence guarantees and explicit rates are established.
Significance. If the new definition is internally consistent and the PhiBE transfer holds with the stated error bounds, the work would provide a concrete bridge between off-policy discrete-time RL methods and continuous-time control, enabling learning from sampled trajectories without requiring the instantaneous advantage or state-value function. The explicit convergence rates under linear FA and the model-free setting are notable strengths if the derivations are rigorous.
major comments (2)
- [Abstract and the section introducing the new Q definition] The central claim rests on the new state-action value function definition (introduced after the discussion of Baird 1994, Jia and Zhou 2023, and Tallec et al. 2019) and its governing equation. The manuscript must explicitly derive this equation from the SDE and demonstrate that the definition is independent of V(s) while still permitting off-policy updates; without this, the reduction to PhiBE (Zhu 2024; Zhu et al. 2025) risks inheriting the same non-existence issues rather than circumventing them.
- [Convergence analysis section] § on convergence analysis: the stated convergence guarantees and rates under linear function approximation are load-bearing for the algorithmic contribution. The proof must be checked for hidden dependence on the specific form of the new Q and for whether the PhiBE approximation error is controlled uniformly across the discrete-time sampling; any unstated assumptions on the SDE coefficients or the function class would undermine the rates.
minor comments (2)
- [Introduction] The abstract and introduction cite the non-existence results but should include a short self-contained paragraph contrasting the new Q with both the classical Q and the instantaneous advantage q(s,a) to improve readability for readers unfamiliar with the CTRL literature.
- [Notation and algorithm sections] Notation for the new Q-function should be introduced with an explicit equation number at first use and kept consistent throughout the model-based and model-free algorithm sections.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments. We address each major comment point by point below, indicating where we will revise the manuscript to improve clarity and rigor.
read point-by-point responses
-
Referee: [Abstract and the section introducing the new Q definition] The central claim rests on the new state-action value function definition (introduced after the discussion of Baird 1994, Jia and Zhou 2023, and Tallec et al. 2019) and its governing equation. The manuscript must explicitly derive this equation from the SDE and demonstrate that the definition is independent of V(s) while still permitting off-policy updates; without this, the reduction to PhiBE (Zhu 2024; Zhu et al. 2025) risks inheriting the same non-existence issues rather than circumventing them.
Authors: We agree that an explicit derivation from the SDE is necessary to fully substantiate the central claim. In the revised manuscript we will expand the relevant section with a complete, step-by-step derivation of the governing equation directly from the controlled SDE, beginning from the proposed definition of the new Q-function. We will also add a dedicated paragraph demonstrating independence from V(s) and showing how the definition supports off-policy updates. These additions will make clear that the subsequent reduction to PhiBE does not inherit the classical non-existence issues. revision: yes
-
Referee: [Convergence analysis section] § on convergence analysis: the stated convergence guarantees and rates under linear function approximation are load-bearing for the algorithmic contribution. The proof must be checked for hidden dependence on the specific form of the new Q and for whether the PhiBE approximation error is controlled uniformly across the discrete-time sampling; any unstated assumptions on the SDE coefficients or the function class would undermine the rates.
Authors: We acknowledge the importance of verifying that the convergence rates are free of hidden dependencies and that the approximation error is controlled uniformly. In the revised version we will augment the convergence analysis section and the appendix with additional intermediate steps that explicitly track the dependence on the new Q-form, establish uniform bounds on the PhiBE error with respect to the discrete sampling interval, and list all assumptions on the SDE coefficients and the linear function class. These clarifications will strengthen the presentation without altering the stated rates. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces a new definition of the state-action value function for continuous-time control and derives its governing equation as an independent step. Algorithms are then built using the PhiBE approximation from prior author works, but the abstract explicitly states that convergence guarantees and explicit rates are established for the proposed method under linear function approximation. No load-bearing step reduces the central claims (new Q-definition or derived rates) to a self-citation or fitted input by construction; the self-citation supplies a tool rather than the result itself. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption System dynamics governed by unknown SDE with only discrete-time trajectory data available
- domain assumption Classical state-action value function Q(s,a) does not exist in CTRL
invented entities (1)
-
New definition of state-action value function in CTRL
no independent evidence
Reference graph
Works this paper leans on
-
[1]
PhiBE: A PDE-based Bellman equation for continuous time policy evaluation
PhiBe: A PDE-based Bellman equation for continuous time policy evaluation , author=. arXiv preprint arXiv:2405.12535 , year=
-
[2]
arXiv preprint arXiv:2509.02267 , year=
A deep learning-driven iterative scheme for high-dimensional HJB equations in portfolio selection with exogenous and endogenous costs , author=. arXiv preprint arXiv:2509.02267 , year=
-
[3]
IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics) , volume=
Discrete-time nonlinear HJB solution using approximate dynamic programming: Convergence proof , author=. IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics) , volume=. 2008 , publisher=
2008
-
[4]
Machine learning , volume=
Q-learning , author=. Machine learning , volume=. 1992 , publisher=
1992
-
[5]
Journal of Machine Learning Research , volume=
Policy gradient and actor-critic learning in continuous time and space: Theory and algorithms , author=. Journal of Machine Learning Research , volume=
-
[6]
Journal of Machine Learning Research , volume=
Policy evaluation and temporal-difference learning in continuous time and space: A martingale approach , author=. Journal of Machine Learning Research , volume=
-
[7]
Journal of Machine Learning Research , volume=
q-Learning in continuous time , author=. Journal of Machine Learning Research , volume=
-
[8]
Journal of Machine Learning Research , volume=
Hamilton-jacobi deep q-learning for deterministic continuous-time systems with lipschitz continuous controls , author=. Journal of Machine Learning Research , volume=
-
[9]
nature , volume=
Grandmaster level in StarCraft II using multi-agent reinforcement learning , author=. nature , volume=. 2019 , publisher=
2019
-
[10]
nature , volume=
Mastering the game of Go with deep neural networks and tree search , author=. nature , volume=. 2016 , publisher=
2016
-
[11]
Nature , volume =
DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning , author =. Nature , volume =. 2025 , doi =
2025
-
[12]
Proceedings of Thirty Third Conference on Learning Theory , pages =
Model-Based Reinforcement Learning with a Generative Model is Minimax Optimal , author =. Proceedings of Thirty Third Conference on Learning Theory , pages =. 2020 , editor =
2020
-
[13]
Learning for Dynamics and Control , pages=
Hamilton-Jacobi-Bellman equations for Q-learning in continuous time , author=. Learning for Dynamics and Control , pages=. 2020 , organization=
2020
-
[14]
2012 , publisher=
Dynamic programming and optimal control: Volume I , author=. 2012 , publisher=
2012
-
[15]
On Bellman equations for continuous-time policy evaluation I: Discretization and approximation
On Bellman equations for continuous-time policy evaluation: discretization and approximation , author=. arXiv preprint arXiv:2407.05966 , year=
-
[16]
Advances in neural information processing systems , volume=
Conservative q-learning for offline reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[17]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Deep Reinforcement Learning with Double Q-learning , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[18]
Proceedings of the 33rd International Conference on Machine Learning , year=
Dueling Network Architectures for Deep Reinforcement Learning , author=. Proceedings of the 33rd International Conference on Machine Learning , year=
-
[19]
International Conference on Machine Learning , year=
Addressing Function Approximation Error in Actor-Critic Methods , author=. International Conference on Machine Learning , year=
-
[20]
International Conference on Machine Learning , year=
Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning , author=. International Conference on Machine Learning , year=
-
[21]
Advances in Neural Information Processing Systems , year=
Safe and Efficient Off-Policy Reinforcement Learning , author=. Advances in Neural Information Processing Systems , year=
-
[22]
International Conference on Machine Learning , year=
Doubly Robust Off-policy Value Evaluation for Reinforcement Learning , author=. International Conference on Machine Learning , year=
-
[23]
nature , volume=
Human-level control through deep reinforcement learning , author=. nature , volume=. 2015 , publisher=
2015
-
[24]
Fine-Tuning Language Models from Human Preferences
Daniel M. Ziegler and Nisan Stiennon and Jeffrey Wu and Tom Brown and Alec Radford and Dario Amodei and Paul F. Christiano , title =. arXiv preprint arXiv:1909.08593 , year =
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[25]
Journal of Biomedical Informatics , volume=
Offline reinforcement learning for safer blood glucose control in people with type 1 diabetes , author=. Journal of Biomedical Informatics , volume=. 2023 , publisher=
2023
-
[26]
IEEE reviews in biomedical engineering , volume=
Diabetes: models, signals, and control , author=. IEEE reviews in biomedical engineering , volume=. 2009 , publisher=
2009
-
[27]
Advances in neural information processing systems , volume=
A minimalist approach to offline reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[28]
Diabetes care , volume=
Clinical targets for continuous glucose monitoring data interpretation: recommendations from the international consensus on time in range , author=. Diabetes care , volume=. 2019 , publisher=
2019
-
[29]
2009 , PAGES =
Pham, Huy\^en , TITLE =. 2009 , PAGES =
2009
-
[30]
1999 , PAGES =
Yong, Jiongmin and Zhou, Xun Yu , TITLE =. 1999 , PAGES =
1999
-
[31]
2013 , publisher=
Computer-controlled systems: theory and design , author=. 2013 , publisher=
2013
-
[32]
2018 , publisher=
Applied optimal control: optimization, estimation and control , author=. 2018 , publisher=
2018
-
[33]
Communications of the ACM , volume=
Temporal difference learning and TD-Gammon , author=. Communications of the ACM , volume=
-
[34]
Machine learning , volume=
Linear least-squares algorithms for temporal difference learning , author=. Machine learning , volume=. 1996 , publisher=
1996
-
[35]
Neural computation , volume=
Reinforcement learning in continuous time and space , author=. Neural computation , volume=. 2000 , publisher=
2000
-
[36]
Journal of Machine Learning Research , volume=
Reinforcement learning in continuous time and space: A stochastic control approach , author=. Journal of Machine Learning Research , volume=
-
[37]
Mathematical Finance , volume=
Continuous-time mean--variance portfolio selection: A reinforcement learning framework , author=. Mathematical Finance , volume=. 2020 , publisher=
2020
-
[38]
SIAM Journal on Control and Optimization , volume=
Optimal scheduling of entropy regularizer for continuous-time linear-quadratic reinforcement learning , author=. SIAM Journal on Control and Optimization , volume=. 2024 , publisher=
2024
-
[39]
Journal of Machine Learning Research , volume=
Logarithmic regret for episodic continuous-time linear-quadratic reinforcement learning over a finite-time horizon , author=. Journal of Machine Learning Research , volume=
-
[40]
arXiv preprint arXiv:2112.10264 , year=
Exploration-exploitation trade-off for continuous-time episodic reinforcement learning with linear-convex models , author=. arXiv preprint arXiv:2112.10264 , year=
-
[41]
Proceedings of 1994 IEEE International Conference on Neural Networks (ICNN'94) , volume=
Reinforcement learning in continuous time: Advantage updating , author=. Proceedings of 1994 IEEE International Conference on Neural Networks (ICNN'94) , volume=. 1994 , organization=
1994
-
[42]
International Conference on Machine Learning , pages=
Making deep q-learning methods robust to time discretization , author=. International Conference on Machine Learning , pages=. 2019 , organization=
2019
-
[43]
arXiv preprint arXiv:2312.11797 , year=
Learning merton's strategies in an incomplete market: recursive entropy regularization and biased gaussian exploration , author=. arXiv preprint arXiv:2312.11797 , year=
-
[44]
Accuracy of discretely sampled stochastic policies in continuous-time reinforcement learning
Accuracy of discretely sampled stochastic policies in continuous-time reinforcement learning , author=. arXiv preprint arXiv:2503.09981 , year=
-
[45]
SIAM Journal on Control and Optimization , volume=
Convergence of policy gradient methods for finite-horizon exploratory linear-quadratic control problems , author=. SIAM Journal on Control and Optimization , volume=. 2024 , publisher=
2024
-
[46]
arXiv preprint arXiv:2505.14821 , year=
Sample and Computationally Efficient Continuous-Time Reinforcement Learning with General Function Approximation , author=. arXiv preprint arXiv:2505.14821 , year=
-
[47]
arXiv preprint arXiv:2501.15910 , year=
The Sample Complexity of Online Reinforcement Learning: A Multi-model Perspective , author=. arXiv preprint arXiv:2501.15910 , year=
-
[48]
Journal of Scientific Computing , volume=
An accelerated method for nonlinear elliptic PDE , author=. Journal of Scientific Computing , volume=. 2016 , publisher=
2016
-
[49]
siam REVIEW , volume=
Recent developments in numerical methods for fully nonlinear second order partial differential equations , author=. siam REVIEW , volume=. 2013 , publisher=
2013
-
[50]
Contributions to the theory of optimal control , author=. Bol. soc. mat. mexicana , volume=
-
[51]
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[52]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Llama 2: Open foundation and fine-tuned chat models , author=. arXiv preprint arXiv:2307.09288 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[53]
Proceedings of the 38th International Conference on Machine Learning , pages =
Continuous-time Model-based Reinforcement Learning , author =. Proceedings of the 38th International Conference on Machine Learning , pages =. 2021 , editor =
2021
-
[54]
International Journal of Control , volume=
Reinforcement learning for adaptive optimal control of unknown continuous-time nonlinear systems with input constraints , author=. International Journal of Control , volume=. 2014 , publisher=
2014
-
[55]
Automatica , volume=
Model-based reinforcement learning for approximate optimal regulation , author=. Automatica , volume=. 2016 , publisher=
2016
-
[56]
and Soner, H
Fleming, Wendell H. and Soner, H. Mete , TITLE =. 2006 , PAGES =
2006
-
[57]
Advances in Neural Information Processing Systems , volume=
Time discretization-invariant safe action repetition for policy gradient methods , author=. Advances in Neural Information Processing Systems , volume=
-
[58]
arXiv preprint arXiv:2506.05208 , year=
Optimal-PhiBE: A PDE-based Model-free framework for Continuous-time Reinforcement Learning , author=. arXiv preprint arXiv:2506.05208 , year=
-
[59]
Foundations and Trends
Online learning and online convex optimization , author=. Foundations and Trends. 2025 , publisher=
2025
-
[60]
The Thirty Sixth Annual Conference on Learning Theory , pages=
Sharper model-free reinforcement learning for average-reward markov decision processes , author=. The Thirty Sixth Annual Conference on Learning Theory , pages=. 2023 , organization=
2023
-
[61]
1998 , publisher=
Reinforcement learning: An introduction , author=. 1998 , publisher=
1998
-
[62]
Proceedings of The Web Conference 2020 , pages=
Off-policy learning in two-stage recommender systems , author=. Proceedings of The Web Conference 2020 , pages=
2020
-
[63]
2013 , publisher=
Stochastic differential equations: an introduction with applications , author=. 2013 , publisher=
2013
-
[64]
2006 , publisher=
Controlled Markov processes and viscosity solutions , author=. 2006 , publisher=
2006
-
[65]
2003 , publisher=
Iterative methods for sparse linear systems , author=. 2003 , publisher=
2003
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.