Layer-wise Derivative Controlled Networks Achieve Competitive Accuracy and Gradient Stability Across Data Regimes
Pith reviewed 2026-06-27 20:30 UTC · model grok-4.3
The pith
Layer-wise derivative control produces competitive accuracy and stable gradients across data regimes and domains.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
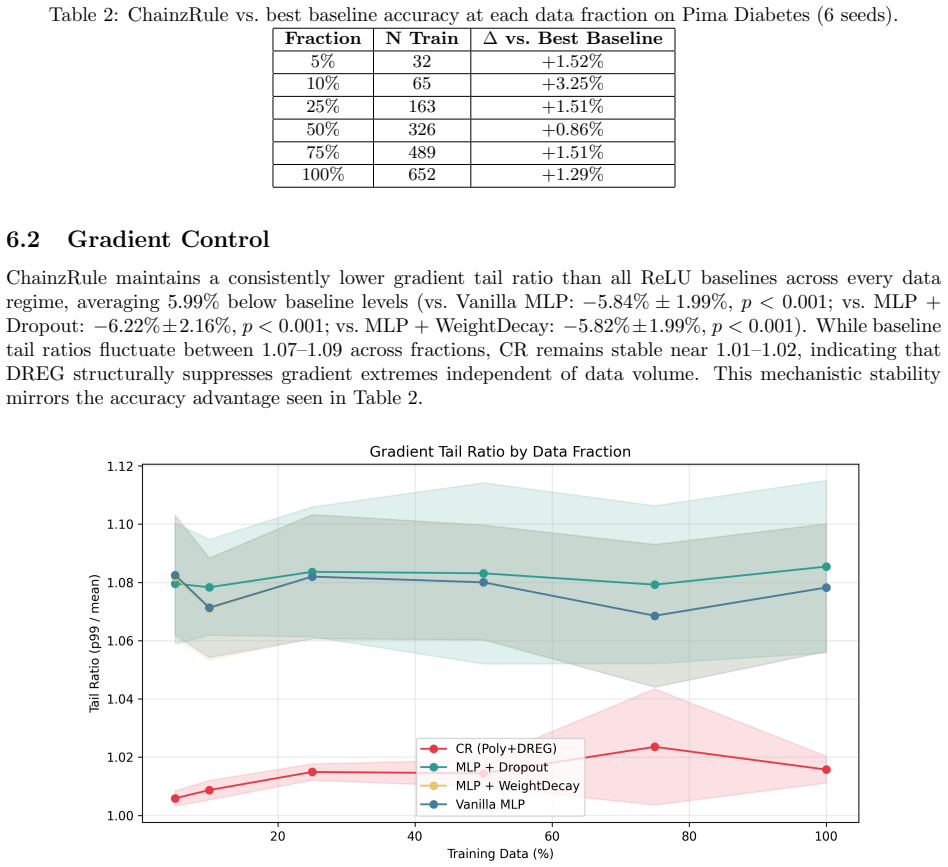
Derivative-controlled networks based on ChainzRule combine cubic polynomial layers with a lightweight forward-mode per-layer Jacobian penalty. On the Pima Diabetes dataset the approach maintains an accuracy edge from 5 percent to 100 percent training data while producing gradient tail ratios of roughly 1.01-1.02 versus 1.07-1.09 for ReLU networks. On SST-5 the same networks match or exceed published BERT baselines in both frozen-embedding and fine-tuning regimes despite using less training data. The results are reported as statistically significant and are presented as evidence that layer-wise derivative control creates a structural bias toward stable, low-frequency representations that gene
What carries the argument
The DREG penalty, a forward-mode per-layer Jacobian penalty applied inside ChainzRule networks that use cubic polynomial layers, which enforces derivative control at each layer.
If this is right
- CR networks retain an accuracy advantage over baselines on Pima Diabetes across the full range from 5 percent to 100 percent training data.
- Gradient tail ratios stay near 1.01-1.02 under CR while ReLU networks reach 1.07-1.09 on the same tasks.
- On SST-5, CR matches or beats prior BERT baselines in frozen-embedding and fine-tuned settings while using substantially less training data.
- The best annealing schedule for the DREG coefficient shifts depending on how noisy the input representations are.
Where Pith is reading between the lines
- The gradient tail ratio could be checked on other architectures to test whether it predicts generalization beyond the networks studied here.
- If the low-frequency bias is real, the method might reduce sensitivity to label noise in domains where only small labeled sets are available.
Load-bearing premise
The observed accuracy and stability gains are produced by the layer-wise derivative penalty rather than by the cubic layer shape or other implementation details that were not fully ablated.
What would settle it
Running the same Pima Diabetes and SST-5 experiments after removing only the DREG penalty and finding that both the accuracy advantage and the low gradient tail ratios disappear.
Figures
read the original abstract
Derivative-controlled networks based on ChainzRule (CR) combine cubic polynomial layers with a lightweight forward-mode per-layer Jacobian penalty (DREG). In this second paper of a multi-part series, we evaluate the generalization properties of CR across data regimes. We ablate the shape of the DREG coefficient schedule, demonstrating that the optimal annealing range depends on representation noise. On the Pima Diabetes dataset, CR achieves strong low-data performance and maintains a consistent accuracy advantage over baselines from 5\% to 100\% training data, supported by exceptionally stable gradient tail ratios ($\sim$1.01--1.02 vs. 1.07--1.09 for ReLU networks). Extensions to SST-5 show competitive or superior results in both frozen-embedding and BERT fine-tuned regimes, including outperforming prior BERT baselines despite substantially less training data. These results are statistically significant: CR achieves superior accuracy over the strongest published baselines we could identify on both datasets ($p < 0.05$). These results establish that layer-wise derivative control induces a structural inductive bias toward low-frequency, stable representations that generalizes robustly across tabular and NLP domains, data volumes, and representation qualities. The gradient tail ratio serves as a reliable, label-free diagnostic of generalization capability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents Derivative-controlled networks using ChainzRule (CR), which integrate cubic polynomial layers with a forward-mode per-layer Jacobian penalty termed DREG. It evaluates these networks on the Pima Diabetes tabular dataset and SST-5 NLP task across varying data regimes, reporting consistent accuracy improvements over baselines, exceptionally stable gradient tail ratios, and statistical significance (p<0.05). The authors conclude that layer-wise derivative control provides a structural inductive bias toward low-frequency stable representations, with the gradient tail ratio serving as a label-free diagnostic of generalization.
Significance. If the reported accuracy and stability advantages can be isolated to the DREG penalty, the work would demonstrate a practical mechanism for inducing robust low-frequency representations that generalizes across tabular and NLP domains and data volumes. The gradient tail ratio would then function as a useful label-free diagnostic. However, the current evidence does not yet separate the contribution of the derivative penalty from other architectural and training choices.
major comments (2)
- [Abstract] Abstract: The ablation is performed only over the shape of the DREG coefficient annealing schedule. No control experiment is described that disables the Jacobian penalty while keeping the cubic polynomial layers, initialization, optimizer settings, and training protocol identical; without this isolation the attribution of accuracy gains and gradient-tail-ratio stability (1.01--1.02 vs. 1.07--1.09) specifically to layer-wise derivative control cannot be verified.
- [Abstract] Abstract: Claims of statistical significance (p<0.05) and consistent advantage from 5% to 100% training data are stated without error bars, standard deviations, exact data splits, baseline implementation details, or full experimental protocol, preventing independent assessment of the reported superiority over the strongest published baselines.
minor comments (1)
- [Abstract] Abstract: The precise definition and computation of the gradient tail ratio are not supplied, making it impossible to reproduce the diagnostic or confirm its label-free character.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback emphasizing the need to isolate the DREG penalty's contribution and to improve experimental reporting for reproducibility. We agree these points strengthen the manuscript and will incorporate the requested changes.
read point-by-point responses
-
Referee: [Abstract] Abstract: The ablation is performed only over the shape of the DREG coefficient annealing schedule. No control experiment is described that disables the Jacobian penalty while keeping the cubic polynomial layers, initialization, optimizer settings, and training protocol identical; without this isolation the attribution of accuracy gains and gradient-tail-ratio stability (1.01--1.02 vs. 1.07--1.09) specifically to layer-wise derivative control cannot be verified.
Authors: We agree that the current ablations do not fully isolate the Jacobian penalty from the cubic layers. In the revised manuscript we will add a control experiment that disables the DREG penalty entirely while retaining the cubic polynomial layers, identical initialization, optimizer, and training protocol. This will directly test whether the reported accuracy and gradient-tail-ratio advantages are attributable to layer-wise derivative control. revision: yes
-
Referee: [Abstract] Abstract: Claims of statistical significance (p<0.05) and consistent advantage from 5% to 100% training data are stated without error bars, standard deviations, exact data splits, baseline implementation details, or full experimental protocol, preventing independent assessment of the reported superiority over the strongest published baselines.
Authors: We acknowledge that the abstract and main text lack these supporting details. The revised manuscript will report error bars and standard deviations across runs, specify exact data splits and seeds, provide full baseline implementation details (including any re-implementations of published models), and include the complete experimental protocol to allow independent verification of the p<0.05 claims and performance advantages. revision: yes
Circularity Check
No circularity in derivation or claims; results are empirical measurements
full rationale
The paper reports experimental results on accuracy and gradient tail ratios across datasets and regimes, with an ablation only on the DREG coefficient schedule. These quantities are directly measured from training runs rather than derived from equations that reduce to the inputs by construction. No self-definitional steps, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or described chain. The gradient tail ratio is explicitly an observed diagnostic, and the inductive-bias conclusion is presented as following from the empirical comparisons, not from a tautological redefinition. This is a standard non-circular empirical evaluation.
Axiom & Free-Parameter Ledger
free parameters (1)
- DREG coefficient annealing schedule
axioms (1)
- domain assumption Gradient tail ratio near 1.0 indicates reliable generalization capability
Reference graph
Works this paper leans on
-
[1]
Layer-wise Derivative Controlled Networks
Rowan Martnishn. Derivative-controlled networks: Layer-wise Jacobian penalties induce stable repre- sentations (Phase 1).arXiv preprint arXiv:2605.15463, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Region-based fitting of a 3d morphable model to a 2d image
Stamatis Karatsiolis and Christos Schizas. Region-based fitting of a 3d morphable model to a 2d image. InProceedings of the 8th Hellenic Conference on AI, 2012.https://gnosis.library.ucy.ac.cy/ handle/7/54226
2012
-
[3]
Performance comparison of machine learning techniques for diabetes prediction
Yangin. Performance comparison of machine learning techniques for diabetes prediction. Master’s thesis, 2019.https://hdl.handle.net/20.500.14124/1152
2019
-
[4]
Comparative analysis of machine learning algorithms for diabetes predic- tion.Neural Computing and Applications, 2023.https://link.springer.com/article/10.1007/ s00521-022-07049-z
Chang et al. Comparative analysis of machine learning algorithms for diabetes predic- tion.Neural Computing and Applications, 2023.https://link.springer.com/article/10.1007/ s00521-022-07049-z
2023
-
[5]
AMNN + KAN + XGBoost preprint. Advanced multi-modal neural network for diabetes prediction, 2025.https://www.medrxiv.org/content/10.1101/2025.09.20.25336250v1.full
-
[6]
Manning, Andrew Ng, and Christopher Potts
Richard Socher, Alex Perelygin, Jean Wu, Jason Chuang, Christopher D. Manning, Andrew Ng, and Christopher Potts. Recursive deep models for semantic compositionality over a sentiment treebank. In Proceedings of EMNLP, 2013.https://aclanthology.org/D13-1170/. 9
2013
-
[7]
Dropout: A simple way to prevent neural networks from overfitting.Journal of Machine Learning Research, 15(1):1929–1958, 2014.https://jmlr.org/papers/v15/srivastava14a.html
Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov. Dropout: A simple way to prevent neural networks from overfitting.Journal of Machine Learning Research, 15(1):1929–1958, 2014.https://jmlr.org/papers/v15/srivastava14a.html
1929
-
[8]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017.https://arxiv.org/abs/1711.05101
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[9]
Spectral Normalization for Generative Adversarial Networks
Takeru Miyato, Toshiki Kataoka, Masanori Koyama, and Yuichi Yoshida. Spectral normalization for generative adversarial networks.arXiv preprint arXiv:1802.05957, 2018.https://arxiv.org/abs/ 1802.05957
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[10]
Improving generalization performance using double backpropagation
Harris Drucker and Yann LeCun. Improving generalization performance using double backpropagation. IEEE Transactions on Neural Networks, 3(6):991–997, 1992
1992
-
[11]
Sobolev Training for Neural Networks
Wojciech Czarnecki, Simon Osindero, Max Jaderberg, Grzegorz Swirszcz, and Razvan Pascanu. Sobolev training for neural networks. InAdvances in Neural Information Processing Systems (NeurIPS), 2017. https://arxiv.org/abs/1706.04859
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[12]
KAN: Kolmogorov-Arnold Networks
Ziming Liu, Yixuan Wang, Sachin Vaidya, Fabian Ruehle, James Halverson, Marin Soljacic, Thomas Y. Hou, and Max Tegmark. KAN: Kolmogorov-Arnold Networks.arXiv preprint arXiv:2404.19756, 2024. https://arxiv.org/abs/2404.19756
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Munikar et al. Fine-grained sentiment classification using BERT.arXiv preprint arXiv:1910.03474, 2019.https://arxiv.org/abs/1910.03474. 10
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.