AnyMatch: Supercharging Universal Multi-Modal Image Matching with Large-Scale Single-View Images
Pith reviewed 2026-07-02 20:10 UTC · model grok-4.3
The pith
AnyMatch turns single-view images into large-scale multi-modal training pairs with explicit 3D geometric consistency for image matching networks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
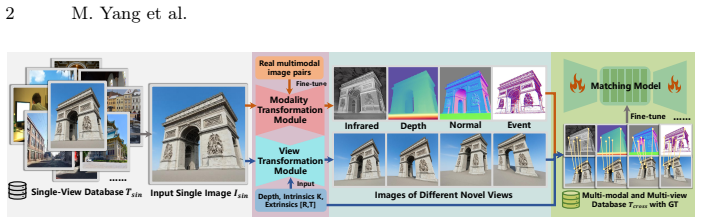
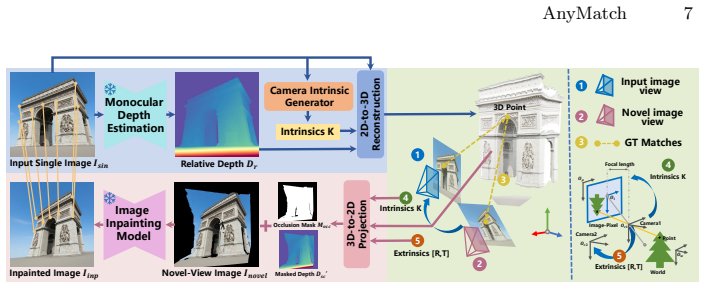
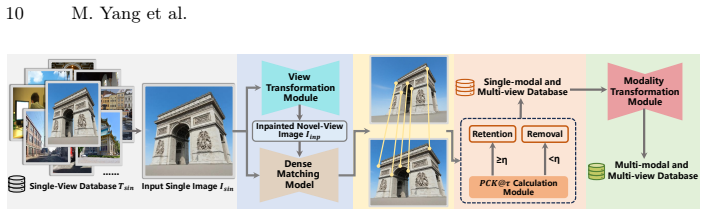
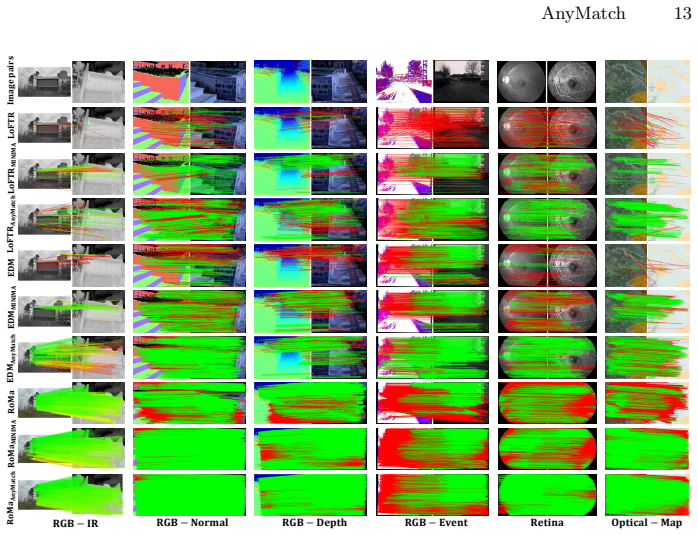
AnyMatch generates multi-modal image pairs by feeding single-view images through monocular depth estimation, 3D reprojection to create consistent multi-view geometry, diffusion-based inpainting, and cross-modal translation; the resulting Any-syn dataset supplies training pairs whose 3D correspondences are guaranteed by the reprojection step, enabling matching networks to achieve substantial performance gains on multi-modal benchmarks when fine-tuned on this data.
What carries the argument
AnyMatch synthesis pipeline that enforces 3D geometric consistency through explicit monocular-depth-driven reprojection before cross-modal translation.
If this is right
- Matching networks fine-tuned on Any-syn exhibit higher accuracy and robustness on multi-modal benchmarks than networks trained on prior real or synthetic collections.
- The explicit 3D reprojection step removes the need for error-prone SfM-MVS pipelines in data preparation.
- Scene diversity and annotation difficulty can be controlled by varying the input single-view images and chosen camera parameters.
- Large-scale multi-modal training data becomes obtainable at low cost from existing single-view photo collections.
Where Pith is reading between the lines
- The same reprojection-based consistency mechanism could be applied to generate training pairs for other geometry-sensitive tasks such as stereo depth or visual odometry.
- If the synthesis artifacts prove negligible, the approach reduces dependence on expensive synchronized multi-sensor captures for future dataset creation.
- Controllable camera parameters in the pipeline may allow targeted generation of hard matching cases to stress-test specific failure modes of current networks.
Load-bearing premise
The images produced by depth estimation, reprojection, inpainting, and translation are close enough in geometry and appearance to real multi-modal captures that fine-tuning on them produces genuine generalization rather than overfitting to synthesis artifacts.
What would settle it
Fine-tuned matching networks show no accuracy improvement, or show degraded performance, when evaluated on held-out real multi-modal image pairs captured by actual sensors.
Figures
read the original abstract
Multi-modal image matching is essential for visual localization and multi-sensor fusion, but it is hindered by the scarcity of large-scale training data with precise geometric annotations. Existing real-world datasets suffer from prohibitive costs, limited scene diversity, and errors in SfM-MVS pipelines, while synthetic methods struggle to maintain 3D geometric consistency or achieve photorealistic appearance. To address this, we propose AnyMatch, a novel framework that leverages abundant, easily accessible single-view images at minimal cost to generate rich multi-modal training data. AnyMatch integrates monocular depth estimation, 3D reprojection, diffusion-based inpainting, and crossmodal image translation to synthesize multi-view, multi-modal image pairs with 3D geometric fidelity. Crucially, our method provides annotations that strictly adhere to 3D geometric consistency through explicit 3D reprojection, avoiding SfM-MVS error accumulation. Furthermore, AnyMatch offers strong scalability, enabling controllable scene diversity and annotation difficulty via adjustable input and camera parameters. We construct Any-syn, a large-scale synthetic multi-modal dataset using AnyMatch. Experimental results show that matching networks (e.g., LoFTR, EDM, RoMa) fine-tuned on Any-syn achieve substantial performance gains on multi-modal benchmarks, exhibiting superior generalization and robustness compared to models trained on existing data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AnyMatch, a pipeline that generates large-scale synthetic multi-modal image pairs and correspondences from single-view images by combining monocular depth estimation, 3D reprojection, diffusion-based inpainting, and cross-modal translation. It constructs the Any-syn dataset and reports that fine-tuning standard matching networks (LoFTR, EDM, RoMa) on Any-syn yields substantial gains in performance, generalization, and robustness on multi-modal benchmarks relative to models trained on existing real or synthetic data. The central selling point is that the generated annotations maintain strict 3D geometric consistency via explicit reprojection while offering controllable scale and diversity at low cost.
Significance. If the synthesized data truly delivers geometric fidelity and appearance distributions that support genuine generalization rather than artifact overfitting, the work would be significant: it offers a scalable route to training data that bypasses the cost and error accumulation of real SfM-MVS pipelines. The controllability of scene diversity and annotation difficulty via input parameters is a concrete practical strength.
major comments (3)
- [Abstract, §3] Abstract and §3 (Method description): The repeated claim that annotations 'strictly adhere to 3D geometric consistency through explicit 3D reprojection, avoiding SfM-MVS error accumulation' is load-bearing for the central argument that Any-syn is superior to real data. However, the pipeline begins with monocular depth estimation; any depth error (known to reach 10-30% under domain shift) propagates directly into the reprojected correspondences. The manuscript provides no quantitative bound on reprojection error induced by the depth estimator, nor a comparison against real SfM baselines on the same scenes.
- [§4] §4 (Experiments): The abstract and results section assert 'substantial performance gains' and 'superior generalization' for networks fine-tuned on Any-syn, yet the provided description contains no numerical values for the key metrics (e.g., AUC@5°, mAA, or matching score), no statistical significance tests, and no ablation isolating the contribution of geometric consistency versus appearance translation. Without these, it is impossible to verify that gains arise from the claimed 3D fidelity rather than synthesis artifacts.
- [§3.2] §3.2 (Data generation pipeline): The weakest assumption—that monocular depth plus reprojection plus inpainting produces pairs whose geometric and photometric statistics match real multi-modal captures—is not stress-tested. A controlled experiment comparing Any-syn correspondences against ground-truth SfM on a held-out real multi-modal sequence would directly address whether depth-estimator artifacts are being learned.
minor comments (2)
- [§3] Notation for camera parameters and reprojection equations in §3 should be made fully explicit (e.g., define the exact form of the 3D-to-2D projection used after depth lifting).
- [§4] Figure captions and axis labels in the experimental figures should include the exact benchmark names and metric definitions to allow direct comparison with prior work.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, providing honest responses and indicating planned revisions to the manuscript where the concerns are valid.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (Method description): The repeated claim that annotations 'strictly adhere to 3D geometric consistency through explicit 3D reprojection, avoiding SfM-MVS error accumulation' is load-bearing for the central argument that Any-syn is superior to real data. However, the pipeline begins with monocular depth estimation; any depth error (known to reach 10-30% under domain shift) propagates directly into the reprojected correspondences. The manuscript provides no quantitative bound on reprojection error induced by the depth estimator, nor a comparison against real SfM baselines on the same scenes.
Authors: We agree that errors from monocular depth estimation propagate into the reprojected correspondences. The core claim is that, by construction, all correspondences remain strictly consistent with the single estimated depth map and the synthetically chosen camera parameters, thereby avoiding the additional sources of error inherent to SfM-MVS (feature matching failures, drift, and scale inconsistencies across views). We did not provide a quantitative bound or direct SfM comparison in the original manuscript. In the revision we will add an analysis of depth-induced reprojection error on standard depth benchmarks together with a discussion of how this compares to typical SfM-MVS error accumulation. revision: yes
-
Referee: [§4] §4 (Experiments): The abstract and results section assert 'substantial performance gains' and 'superior generalization' for networks fine-tuned on Any-syn, yet the provided description contains no numerical values for the key metrics (e.g., AUC@5°, mAA, or matching score), no statistical significance tests, and no ablation isolating the contribution of geometric consistency versus appearance translation. Without these, it is impossible to verify that gains arise from the claimed 3D fidelity rather than synthesis artifacts.
Authors: The experimental section contains tables reporting AUC@5°, mAA, and matching scores for LoFTR, EDM, and RoMa on the multi-modal benchmarks. To improve clarity we will quote the key numerical improvements directly in the text of §4. We also acknowledge the absence of statistical tests and a dedicated ablation. In the revision we will add paired statistical significance tests on the reported gains and an ablation that isolates the 3D reprojection component (e.g., by replacing it with 2D homography-based warping while keeping appearance translation fixed). revision: yes
-
Referee: [§3.2] §3.2 (Data generation pipeline): The weakest assumption—that monocular depth plus reprojection plus inpainting produces pairs whose geometric and photometric statistics match real multi-modal captures—is not stress-tested. A controlled experiment comparing Any-syn correspondences against ground-truth SfM on a held-out real multi-modal sequence would directly address whether depth-estimator artifacts are being learned.
Authors: We agree that a direct comparison against real SfM ground truth on held-out multi-modal sequences would be the most rigorous validation. Such sequences are, however, precisely the scarce and costly resource our method seeks to circumvent. Our current evidence rests on downstream benchmark gains and qualitative geometric checks. In the revision we will expand the discussion of this limitation and outline why the suggested controlled experiment is difficult to realize at scale without reintroducing the original data-acquisition bottleneck. revision: partial
Circularity Check
No circularity; independent data synthesis and external evaluation
full rationale
The paper describes an independent pipeline (monocular depth estimation + 3D reprojection + diffusion inpainting + cross-modal translation) to synthesize Any-syn data from single-view images, then reports empirical gains when fine-tuning existing matchers (LoFTR, EDM, RoMa) on that data and testing on separate multi-modal benchmarks. No equations, fitted parameters, or self-citations are presented that reduce the claimed generalization gains to a definitional identity or to the synthesis inputs themselves. The central result remains an external empirical claim rather than a self-referential construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Monocular depth estimation yields depth maps accurate enough for 3D reprojection across diverse scenes without systematic bias.
- domain assumption Diffusion inpainting and cross-modal translation preserve 3D structure and produce photorealistic outputs without introducing matching-irrelevant artifacts.
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the IEEE International Conference on Robotics and Automation
Aditya, N., Dhruval, P., et al.: Thermal voyager: A comparative study of rgb and thermal cameras for night-time autonomous navigation. In: Proceedings of the IEEE International Conference on Robotics and Automation. pp. 14116–14122 (2024)
2024
-
[2]
In: Proceedings of the European Conference on Computer Vision
Bay, H., Tuytelaars, T., Van Gool, L.: SURF: Speeded up robust features. In: Proceedings of the European Conference on Computer Vision. pp. 404–417 (2006)
2006
-
[3]
In: Proceedings of the Asian Conference on Computer Vision
Cadar, F., Potje, G., Martins, R., Demonceaux, C., Nascimento, E.R.: Leveraging semantic cues from foundation vision models for enhanced local feature correspon- dence. In: Proceedings of the Asian Conference on Computer Vision. pp. 1268–1283 (2024)
2024
-
[4]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition
Dai, A., Chang, A.X., Savva, M., Halber, M., Funkhouser, T., Nießner, M.: Scan- Net: Richly-annotated 3d reconstructions of indoor scenes. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 5828–5839 (2017)
2017
-
[5]
IEEE Transactions on Pattern Analysis and Machine Intelligence46(8), 5725–5742 (2024)
Deng, X., Liu, E., Gao, C., Li, S., Gu, S., Xu, M.: CrossHomo: Cross-modality and cross-resolution homography estimation. IEEE Transactions on Pattern Analysis and Machine Intelligence46(8), 5725–5742 (2024)
2024
-
[6]
IEEE Transactions on Image Processing32, 591–602 (2022)
Deng, Y., Ma, J.: Redfeat: Recoupling detection and description for multimodal feature learning. IEEE Transactions on Image Processing32, 591–602 (2022)
2022
-
[7]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition
Edstedt, J., Sun, Q., Bökman, G., Wadenbäck, M., Felsberg, M.: RoMa: Robust dense feature matching. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 19790–19800 (2024)
2024
-
[8]
Communi- cations of the ACM24(6), 381–395 (1981)
Fischler, M.A., Bolles, R.C.: Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography. Communi- cations of the ACM24(6), 381–395 (1981)
1981
-
[9]
In: Pro- ceedings of the IEEE Winter Conference on Applications of Computer Vision
Frolov, A., Rodehorst, V.: Patch your matcher: Correspondence-aware image-to- image translation unlocks cross-modal matching via single-modality priors. In: Pro- ceedings of the IEEE Winter Conference on Applications of Computer Vision. pp. 7913–7924 (2026)
2026
-
[10]
In: Proceedings of the IEEE International Conference on Computer Vision
Gao, C., Li, W., Weng, D.: HOMO-feature: Cross-arbitrary-modal image matching with homomorphism of organized major orientation. In: Proceedings of the IEEE International Conference on Computer Vision. pp. 10538–10548 (2025)
2025
-
[11]
In: Proceedings of the IEEE Conference on Computer Vision and Pat- tern Recognition
Greff, K., Belletti, F., Beyer, L., Doersch, C., Du, Y., Duckworth, D., Fleet, D.J., Gnanapragasam, D., Golemo, F., Herrmann, C., et al.: Kubric: A scalable dataset generator. In: Proceedings of the IEEE Conference on Computer Vision and Pat- tern Recognition. pp. 3749–3761 (2022)
2022
-
[12]
In: Proceedings of the IEEE International Conference on Computer Vision
Han, Z., Mao, C., Jiang, Z., Pan, Y., Zhang, J.: Stylebooth: Image style editing with multimodal instruction. In: Proceedings of the IEEE International Conference on Computer Vision. pp. 1947–1957 (2025)
1947
-
[13]
arXiv preprint arXiv:2501.07556 (2025)
He, X., Yu, H., Peng, S., Tan, D., Shen, Z., Bao, H., Zhou, X.: MatchAnything: Uni- versal cross-modality image matching with large-scale pre-training. arXiv preprint arXiv:2501.07556 (2025)
-
[14]
Information Fusion102, 102027 (2024)
Hou,Z.,Liu,Y.,Zhang,L.:POS-GIFT:Ageometricandintensity-invariantfeature transformation for multimodal images. Information Fusion102, 102027 (2024)
2024
-
[15]
In: Proceedings of the International Conference on Learning Representations (2022) AnyMatch 17
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., et al.: LoRA: Low-Rank adaptation of large language models. In: Proceedings of the International Conference on Learning Representations (2022) AnyMatch 17
2022
-
[16]
Information Fusion73, 22–71 (2021)
Jiang, X., Ma, J., Xiao, G., Shao, Z., Guo, X.: A review of multimodal image matching: Methods and applications. Information Fusion73, 22–71 (2021)
2021
-
[17]
In: Proceedings of the IEEE International Conference on Computer Vision
Kirillov, A., Mintun, E., Ravi, N., Mao, H., Rolland, C., Gustafson, L., Xiao, T., Whitehead, S., Berg, A.C., Lo, W.Y., et al.: Segment anything. In: Proceedings of the IEEE International Conference on Computer Vision. pp. 4015–4026 (2023)
2023
-
[18]
IEEE Transactions on Image Processing 29, 3296–3310 (2019)
Li, J., Hu, Q., Ai, M.: RIFT: Multi-modal image matching based on radiation- variation insensitive feature transform. IEEE Transactions on Image Processing 29, 3296–3310 (2019)
2019
-
[19]
ISPRS Journal of Photogrammetry and Remote Sensing204, 77–88 (2023)
Li, J., Hu, Q., Zhang, Y.: Multimodal image matching: A scale-invariant algorithm and an open dataset. ISPRS Journal of Photogrammetry and Remote Sensing204, 77–88 (2023)
2023
-
[20]
In: Proceedings of the IEEE International Conference on Computer Vision
Li, X., Rao, T., Pan, C.: EDM: Efficient deep feature matching. In: Proceedings of the IEEE International Conference on Computer Vision. pp. 26198–26208 (2025)
2025
-
[21]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition
Li, Z., Snavely, N.: Megadepth: Learning single-view depth prediction from internet photos. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 2041–2050 (2018)
2041
-
[22]
In: Proceedings of the European Conference on Computer Vision
Lin, T.Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft coco: Common objects in context. In: Proceedings of the European Conference on Computer Vision. pp. 740–755 (2014)
2014
-
[23]
A Survey on Hallucination in Large Vision-Language Models
Liu, H., Xue, W., Chen, Y., Chen, D., Zhao, X., Wang, K., Hou, L., Li, R., Peng, W.: A survey on hallucination in large vision-language models. arXiv preprint arXiv:2402.00253 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition
Liu, J., Fan, X., Huang, Z., Wu, G., Liu, R., Zhong, W., Luo, Z.: Target-aware dual adversarial learning and a multi-scenario multi-modality benchmark to fuse infrared and visible for object detection. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 5802–5811 (2022)
2022
-
[25]
Interna- tional Journal of Computer Vision60(2), 91–110 (2004)
Lowe, D.G.: Distinctive image features from scale-invariant keypoints. Interna- tional Journal of Computer Vision60(2), 91–110 (2004)
2004
-
[26]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition
Mayer, N., Ilg, E., Hausser, P., Fischer, P., Cremers, D., Dosovitskiy, A., Brox, T.: A large dataset to train convolutional networks for disparity, optical flow, and scene flow estimation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 4040–4048 (2016)
2016
-
[27]
DINOv2: Learning Robust Visual Features without Supervision
Oquab, M., Darcet, T., Moutakanni, T., Vo, H., Szafraniec, M., Khalidov, V., Fernandez,P.,Haziza,D.,Massa,F.,El-Nouby,A.,etal.:DINOv2:Learningrobust visual features without supervision. arXiv preprint arXiv:2304.07193 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
arXiv preprint arXiv:2503.19012 (2025)
Ran,L.,Wang,L.,Wang,G.,Wang,P.,Zhang,Y.:DiffV2IR:visible-to-infrareddif- fusion model via vision-language understanding. arXiv preprint arXiv:2503.19012 (2025)
-
[29]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Ren,J.,Jiang,X.,Li,Z.,Liang,D.,Zhou,X.,Bai,X.:MINIMA:Modalityinvariant image matching. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 23059–23068 (2025)
2025
-
[30]
In: Proceedings of the IEEE Confer- ence on Computer Vision and Pattern Recognition
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE Confer- ence on Computer Vision and Pattern Recognition. pp. 10684–10695 (2022)
2022
-
[31]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition
Schönberger, J.L., Frahm, J.M.: Structure-from-motion revisited. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 4104– 4113 (2016)
2016
-
[32]
In: Proceedings of the European Conference on Computer Vision
Schönberger, J.L., Zheng, E., Frahm, J.M., Pollefeys, M.: Pixelwise view selection for unstructured multi-view stereo. In: Proceedings of the European Conference on Computer Vision. pp. 501–518 (2016) 18 M. Yang et al
2016
-
[33]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition
Sun, J., Shen, Z., Wang, Y., Bao, H., Zhou, X.: LoFTR: Detector-free local feature matching with transformers. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 8922–8931 (2021)
2021
-
[34]
In: Proceedings of the IEEE Conference on Com- puter Vision and Pattern Recognition
Tuzcuoğlu, Ö., Köksal, A., Sofu, B., Kalkan, S., Alatan, A.A.: Xoftr: Cross-modal feature matching transformer. In: Proceedings of the IEEE Conference on Com- puter Vision and Pattern Recognition. pp. 4275–4286 (2024)
2024
-
[35]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition
Wang,R.,Xu,S.,Dai,C.,Xiang,J.,Deng,Y.,Tong,X.,Yang,J.:MoGe:Unlocking accurate monocular geometry estimation for open-domain images with optimal training supervision. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 5261–5271 (2025)
2025
-
[36]
In: Proceedings of the Advances in Neural Information Processing Systems
Wang, R., Xu, S., Dong, Y., Deng, Y., Xiang, J., Lv, Z., Sun, G., Tong, X., Yang, J.: MoGe-2: Accurate monocular geometry with metric scale and sharp details. In: Proceedings of the Advances in Neural Information Processing Systems. pp. 35928–35959 (2026)
2026
-
[37]
IEEE Transactions on Cybernetics54(3), 1997–2010 (2023)
Wang, X., Li, J., Zhu, L., Zhang, Z., Chen, Z., Li, X., Wang, Y., Tian, Y., Wu, F.: VisEvent: Reliable object tracking via collaboration of frame and event flows. IEEE Transactions on Cybernetics54(3), 1997–2010 (2023)
1997
-
[38]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition
Weyand, T., Araujo, A., Cao, B., Sim, J.: Google landmarks dataset v2-a large- scale benchmark for instance-level recognition and retrieval. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 2575–2584 (2020)
2020
-
[39]
IEEE Transactions on Image Processing34, 2097–2111 (2025)
Wu, J., Xu, R., Wood-Doughty, Z., Wang, C., Xu, S., Lam, E.Y.: Segment anything model is a good teacher for local feature learning. IEEE Transactions on Image Processing34, 2097–2111 (2025)
2097
-
[40]
IEEE Transactions on Pattern Analysis and Machine Intelligence 45(10), 12148–12166 (2023)
Xu, H., Yuan, J., Ma, J.: Murf: Mutually reinforcing multi-modal image registra- tion and fusion. IEEE Transactions on Pattern Analysis and Machine Intelligence 45(10), 12148–12166 (2023)
2023
-
[41]
In: Proceedings of the Advances in Neural Information Processing Systems
Yang, L., Kang, B., Huang, Z., Zhao, Z., Xu, X., Feng, J., Zhao, H.: Depth anything v2. In: Proceedings of the Advances in Neural Information Processing Systems. pp. 21875–21911 (2024)
2024
-
[42]
In: Proceedings of the International Joint Conference on Artificial Intelligence
Yang, M., Fan, F., Huang, J., Ma, Y., Mei, X., Cai, Z., Ma, J.: Multimodal image matching based on cross-modality completion pre-training. In: Proceedings of the International Joint Conference on Artificial Intelligence. pp. 2206–2214 (2025)
2025
-
[43]
Information Fusion76, 323–336 (2021)
Zhang, H., Xu, H., Tian, X., Jiang, J., Ma, J.: Image fusion meets deep learning: A survey and perspective. Information Fusion76, 323–336 (2021)
2021
-
[44]
In: Proceedings of the International Conference on Machine Learning (2024)
Zhang, K., Ma, J.: Sparse-to-dense multimodal image registration via multi-task learning. In: Proceedings of the International Conference on Machine Learning (2024)
2024
-
[45]
In: Pro- ceedings of the AAAI Conference on Artificial Intelligence
Zhou, K., Chen, C., Wang, B., Saputra, M.R.U., Trigoni, N., Markham, A.: VM- Loc: Variational fusion for learning-based multimodal camera localization. In: Pro- ceedings of the AAAI Conference on Artificial Intelligence. vol. 35, pp. 6165–6173 (2021) AnyMatch 19 Supplementary Material A Details of View Transformation The view transformation module in AnyM...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.