Towards Continuous Power Forecasting: Practical Continual Learning for Real-World Energy Systems in Nonstationary Time Series
Pith reviewed 2026-06-26 00:50 UTC · model grok-4.3
The pith
Continual learning enables power forecasting models to adapt to evolving data distributions without large-scale historical data storage.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Power forecasting models deployed in real-world energy markets must operate under nonstationary conditions where data distributions evolve due to weather, infrastructure, and consumption changes; by framing the task as continual learning and applying an adaptive framework for regression, models can self-adapt to distributional drift, accumulate knowledge, and mitigate catastrophic forgetting without relying on large-scale historical data storage.
What carries the argument
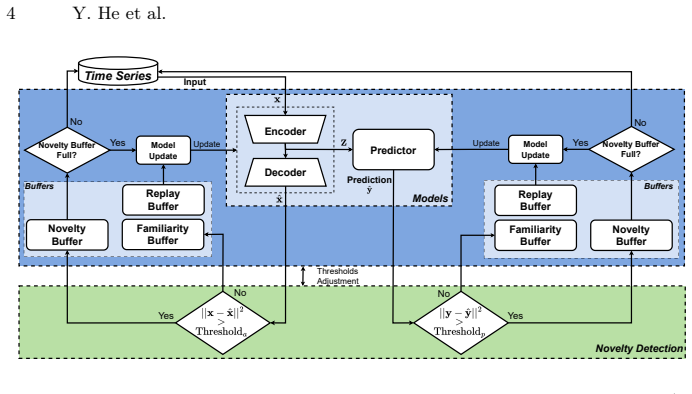
Adaptive continual learning framework for regression that systematically tests six representative approaches from three methodological categories under varying data accessibility and update policies.
If this is right
- Forecasting models can self-adapt to distributional drift from weather variability, infrastructure upgrades, and changing behaviors.
- Knowledge accumulates over time without dependence on large historical data storage.
- Catastrophic forgetting is mitigated during uninterrupted long-term service.
- The framework yields practical insights into stability and adaptation behaviors of different continual learning approaches under operational constraints.
- Continual learning integrates pragmatically into industrial power forecasting pipelines for scalable long-term deployment in dynamic environments.
Where Pith is reading between the lines
- This setup could lower storage and compute requirements for maintaining energy forecasting systems over years.
- The same continual learning structure might extend to other nonstationary forecasting tasks such as load prediction in transportation networks.
- Reduced need for historical data retention could support deployments with stricter privacy or regulatory limits on data holding.
Load-bearing premise
The six representative continual learning approaches from three methodological categories are sufficient to demonstrate practical effectiveness under different realistic assumptions regarding data accessibility and update policies.
What would settle it
A controlled test in which none of the six continual learning methods shows measurable gains in adaptation accuracy or forgetting reduction relative to standard retraining on new data batches alone would falsify the claim of practical effectiveness.
Figures
read the original abstract
Power forecasting models deployed in real-world energy markets must operate under nonstationary conditions, where data distributions continually evolve due to weather variability, infrastructure upgrades, and changing consumption behaviors. In practice, these models face strict operational constraints: historical data may be limited or unavailable for repeated retraining, and uninterrupted long-term service is often required. This paper addresses these challenges by proposing the paradigm of Continuous Power Forecasting, which views power forecasting as a continual learning problem rather than a static offline task. Based on an adaptive continual learning framework for regression, we systematically investigate the practical effectiveness of six representative continual learning approaches from three methodological categories. These approaches are evaluated under different realistic assumptions regarding data accessibility and update policies. Experimental validation on real-world power datasets demonstrates that continual learning enables forecasting models to self-adapt to distributional drift, accumulate knowledge over time, and mitigate catastrophic forgetting without relying on large-scale historical data storage. Beyond performance gains, our study provides practical insights into the stability and adaptation behaviors of different continual learning approaches under realistic operational constraints. Overall, this work illustrates how continual learning can be pragmatically integrated into industrial power forecasting pipelines, offering a scalable and sustainable solution for long-term deployment in dynamic environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Continuous Power Forecasting paradigm, reframing power forecasting as a continual learning problem to handle nonstationarity arising from weather, infrastructure, and consumption changes. It evaluates six representative continual learning methods drawn from replay, regularization, and architecture-based categories within an adaptive regression framework. These are tested under explicit assumptions about data accessibility and update policies on real-world power datasets, with results indicating successful adaptation to distributional drift, knowledge accumulation over time, and mitigation of catastrophic forgetting without requiring large-scale historical storage. The work also extracts practical insights on stability and adaptation behaviors for industrial pipelines.
Significance. If the reported empirical outcomes hold under the stated constraints, the contribution is significant for demonstrating pragmatic integration of continual learning into energy forecasting systems that must operate indefinitely under operational limits on data retention and retraining. The explicit enumeration of data-access and update-policy assumptions, together with the multi-category method comparison, supplies actionable guidance beyond generic CL benchmarks. The emphasis on real-world datasets and long-term deployment constraints distinguishes the work from purely theoretical CL studies.
major comments (2)
- [§4] §4 (Experimental Setup): The manuscript reports performance gains and forgetting mitigation on real-world power datasets, yet provides neither the precise dataset identifiers (e.g., source, temporal coverage, or preprocessing steps) nor the quantitative metrics (MAE, RMSE, or normalized scores) with error bars or statistical tests. Without these, the central claim that continual learning “enables … self-adapt to distributional drift” cannot be independently verified or compared to prior energy-forecasting baselines.
- [§3.1–3.2] §3.1–3.2 (Adaptive CL Framework): The regression-specific adaptation of the six methods is described at a high level, but the precise form of the regularization term or replay buffer sampling policy for the regression loss is not given. This omission is load-bearing because the headline result—that the methods “mitigate catastrophic forgetting without relying on large-scale historical data storage”—depends on these implementation choices being both realistic and effective.
minor comments (3)
- [Abstract] Abstract: The phrase “six representative continual learning approaches from three methodological categories” is repeated without naming the categories or methods; a parenthetical list would improve immediate readability.
- [Figures] Figure captions: Several figures lack axis labels or units (e.g., “error” vs. “MAE in MW”), making it difficult to interpret the stability/adaptation plots without cross-referencing the text.
- [§3] Notation: The symbols used for the continual-learning loss components (e.g., L_reg, L_replay) are introduced inconsistently between §3 and the experimental tables; a consolidated notation table would help.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will incorporate the suggested clarifications in the revised manuscript.
read point-by-point responses
-
Referee: [§4] §4 (Experimental Setup): The manuscript reports performance gains and forgetting mitigation on real-world power datasets, yet provides neither the precise dataset identifiers (e.g., source, temporal coverage, or preprocessing steps) nor the quantitative metrics (MAE, RMSE, or normalized scores) with error bars or statistical tests. Without these, the central claim that continual learning “enables … self-adapt to distributional drift” cannot be independently verified or compared to prior energy-forecasting baselines.
Authors: We agree that the current presentation of results in §4 lacks sufficient detail for independent verification. In the revision we will add the precise dataset identifiers (sources, temporal coverage, and preprocessing steps), report MAE, RMSE and normalized scores with error bars, and include statistical tests comparing against baselines. These additions will directly support the central claims. revision: yes
-
Referee: [§3.1–3.2] §3.1–3.2 (Adaptive CL Framework): The regression-specific adaptation of the six methods is described at a high level, but the precise form of the regularization term or replay buffer sampling policy for the regression loss is not given. This omission is load-bearing because the headline result—that the methods “mitigate catastrophic forgetting without relying on large-scale historical data storage”—depends on these implementation choices being both realistic and effective.
Authors: We acknowledge that the high-level description in §§3.1–3.2 leaves the exact regularization terms and replay sampling policies underspecified. The revised sections will include the precise mathematical forms of the regularization terms and the concrete replay buffer sampling policies used for the regression loss, ensuring the implementation details are fully reproducible. revision: yes
Circularity Check
No significant circularity
full rationale
The paper is an empirical study proposing the 'Continuous Power Forecasting' paradigm and evaluating six existing continual learning methods (replay/regularization/architecture categories) on real-world power datasets under explicit data-access and update-policy assumptions. No equations, derivations, fitted parameters renamed as predictions, or self-definitional steps appear in the provided text. Central claims rest on experimental outcomes from external datasets rather than quantities defined by the authors' own inputs or self-citation chains. The argument is self-contained against real data benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Power forecasting data distributions continually evolve due to weather, infrastructure, and consumption changes.
- domain assumption Continual learning methods developed for classification can be directly applied to regression tasks in time series.
invented entities (1)
-
Continuous Power Forecasting paradigm
no independent evidence
Reference graph
Works this paper leans on
-
[1]
In: 2020 International Joint Conference on Neural Networks (IJCNN)
Cossu, A., Carta, A., Bacciu, D.: Continual learning with gated incremental mem- ories for sequential data processing. In: 2020 International Joint Conference on Neural Networks (IJCNN). pp. 1–8. IEEE (2020)
2020
-
[2]
IEEE Transactions on Pattern Analysis and Machine Intelli- gence44(7), 3366–3385 (2021)
De Lange, M., Aljundi, R., Masana, M., Parisot, S., Jia, X., Leonardis, A., Slabaugh, G., Tuytelaars, T.: A continual learning survey: Defying forgetting in classification tasks. IEEE Transactions on Pattern Analysis and Machine Intelli- gence44(7), 3366–3385 (2021)
2021
-
[3]
ACM Computing Surveys46(4), 1–37 (2014)
Gama, J., Žliobait˙ e, I., Bifet, A., Pechenizkiy, M., Bouchachia, A.: A survey on concept drift adaptation. ACM Computing Surveys46(4), 1–37 (2014)
2014
-
[4]
IFAC-PapersOnLine53(2), 12175– 12182 (2020)
He, Y., Henze, J., Sick, B.: Continuous learning of deep neural networks to im- prove forecasts for regional energy markets. IFAC-PapersOnLine53(2), 12175– 12182 (2020)
2020
-
[5]
Hierarchical attention transformer networks for long document classification
He, Y., Huang, Z., Sick, B.: Toward application of continuous power forecasts in a regional flexibility market. In: 2021 International Joint Conference on Neural Networks (IJCNN). pp. 1–8. IEEE (2021). https://doi.org/10.1109/IJCNN52387.2021.9533626
-
[6]
AI Perspectives3(1), 2 (Jul 2021) 16 Y
He, Y., Sick, B.: CLeaR: An adaptive continual learning framework for regression tasks. AI Perspectives3(1), 2 (Jul 2021) 16 Y. He et al
2021
-
[7]
arXiv preprint arXiv:1810.12488 (2018)
Hsu, Y.C., Liu, Y.C., Ramasamy, A., Kira, Z.: Re-evaluating continual learn- ing scenarios: A categorization and case for strong baselines. arXiv preprint arXiv:1810.12488 (2018)
Pith/arXiv arXiv 2018
-
[8]
Proceedings of the National Academy of Sciences (PNAS)114(13), 3521–3526 (2017)
Kirkpatrick, J., Pascanu, R., Rabinowitz, N., Veness, J., Desjardins, G., Rusu, A.A., Milan, K., Quan, J., Ramalho, T., Grabska-Barwinska, A., et al.: Overcoming catastrophic forgetting in neural networks. Proceedings of the National Academy of Sciences (PNAS)114(13), 3521–3526 (2017)
2017
-
[9]
The Journal of Machine Learning Research8, 2755–2790 (2007)
Kolter, J.Z., Maloof, M.A.: Dynamic weighted majority: An ensemble method for drifting concepts. The Journal of Machine Learning Research8, 2755–2790 (2007)
2007
-
[10]
In: Proceedings of the 1st Annual Conference on Robot Learning (CoRL)
Lomonaco, V., Maltoni, D.: Core50: a new dataset and benchmark for continu- ous object recognition. In: Proceedings of the 1st Annual Conference on Robot Learning (CoRL). pp. 17–26. PMLR (2017)
2017
-
[11]
IEEE transactions on knowledge and data engineering31(12), 2346–2363 (2018)
Lu, J., Liu, A., Dong, F., Gu, F., Gama, J., Zhang, G.: Learning under concept drift: A review. IEEE transactions on knowledge and data engineering31(12), 2346–2363 (2018)
2018
-
[12]
arXiv preprint arXiv:2211.14730 (2022)
Nie, Y., Nguyen, N.H., Sinthong, P., Kalagnanam, J.: A time series is worth 64 words: Long-term forecasting with Transformers. arXiv preprint arXiv:2211.14730 (2022)
Pith/arXiv arXiv 2022
-
[13]
In: Proceedings of the IEEE Conference on Com- puter Vision and Pattern Recognition (CVPR)
Rebuffi, S.A., Kolesnikov, A., Sperl, G., Lampert, C.H.: iCaRL: Incremental classi- fier and representation learning. In: Proceedings of the IEEE Conference on Com- puter Vision and Pattern Recognition (CVPR). pp. 2001–2010 (2017)
2001
-
[14]
Advances in Neural Information Processing Systems (NeurIPS) 32(2019)
Rolnick, D., Ahuja, A., Schwarz, J., Lillicrap, T., Wayne, G.: Experience replay for continual learning. Advances in Neural Information Processing Systems (NeurIPS) 32(2019)
2019
-
[15]
arXiv preprint arXiv:1606.04671 (2016)
Rusu, A.A., Rabinowitz, N.C., Desjardins, G., Soyer, H., Kirkpatrick, J., Kavukcuoglu, K., Pascanu, R., Hadsell, R.: Progressive neural networks. arXiv preprint arXiv:1606.04671 (2016)
Pith/arXiv arXiv 2016
-
[16]
arXiv preprint arXiv:1711.03705 (2017)
Sahoo, D., Pham, Q., Lu, J., Hoi, S.C.H.: Online deep learning: Learning deep neural networks on the fly. arXiv preprint arXiv:1711.03705 (2017)
Pith/arXiv arXiv 2017
-
[17]
In: Proceedings of the 35th International Conference on Machine Learn- ing (ICML)
Schwarz, J., Czarnecki, W., Luketina, J., Grabska-Barwinska, A., Teh, Y.W., Pas- canu, R., Hadsell, R.: Progress & compress: A scalable framework for continual learning. In: Proceedings of the 35th International Conference on Machine Learn- ing (ICML). pp. 4528–4537. PMLR (2018)
2018
-
[18]
Advances in Neural Information Processing Systems (NeurIPS)30(2017)
Shin, H., Lee, J.K., Kim, J., Kim, J.: Continual learning with deep generative replay. Advances in Neural Information Processing Systems (NeurIPS)30(2017)
2017
-
[19]
arXiv preprint arXiv:1809.10635 (2018)
Van de Ven, G.M., Tolias, A.S.: Generative replay with feedback connections as a general strategy for continual learning. arXiv preprint arXiv:1809.10635 (2018)
Pith/arXiv arXiv 2018
-
[20]
Advances in Neural Information Processing Systems (NeurIPS)34, 22419–22430 (2021)
Wu, H., Xu, J., Wang, J., Long, M.: Autoformer: Decomposition transformers with auto-correlation for long-term series forecasting. Advances in Neural Information Processing Systems (NeurIPS)34, 22419–22430 (2021)
2021
-
[21]
In: Proceedings of the 34th International Conference on Machine Learning (ICML)
Zenke, F., Poole, B., Ganguli, S.: Continual learning through synaptic intelligence. In: Proceedings of the 34th International Conference on Machine Learning (ICML). pp. 3987–3995. PMLR (2017)
2017
-
[22]
In: Proceed- ings of the AAAI Conference on Artificial Intelligence
Zhou, H., Zhang, S., Peng, J., Zhang, S., Li, J., Xiong, H., Zhang, W.: Informer: Beyond efficient transformer for long sequence time-series forecasting. In: Proceed- ings of the AAAI Conference on Artificial Intelligence. vol. 35(12), pp. 11106–11115 (2021) Practical Continual Learning for Real-World Energy Systems 17 Appendix This appendix provides algo...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.