Where You Inject Diversity Matters: A Unified Framework for Diverse Generation
Pith reviewed 2026-06-27 13:34 UTC · model grok-4.3
The pith
Diversity should be injected by first generating varied specifications then conditioning responses on them.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
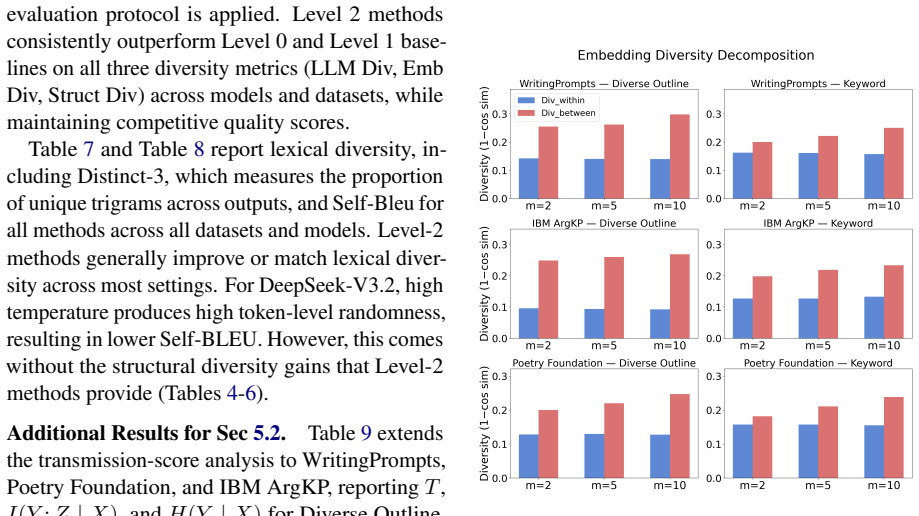
Specification-level diversity injection, achieved by generating diverse intermediate specifications and conditioning final responses on them, produces more varied outputs than other test-time diversity methods across multiple tasks and models. The framework shows that effective diversity depends on both the diversity present in the source and how well it transmits to the output.
What carries the argument
A framework classifying diversity methods by their diversity source together with a transmission score that measures the passage of variation to the final output.
If this is right
- Specification-level injection achieves higher diversity scores than baselines.
- Output quality stays comparable to non-diversity methods.
- Automated generation of specifications works without human oversight or tuning.
- Design of diversity sources and their realization in output are key design choices.
Where Pith is reading between the lines
- The framework could guide development of diversity methods for new tasks not tested here.
- Enhancing transmission might require changes in how models interpret specifications.
- Similar injection points could be explored in other modalities like image generation.
- The transmission score might serve as a diagnostic tool for existing diversity techniques.
Load-bearing premise
The transmission score validly measures how variation from the diversity source reaches the final output and automated specification generation reliably produces meaningful diversity without additional human oversight or task-specific tuning.
What would settle it
Running specification-level injection on the five open-ended tasks and four models yields no measurable increase in diversity scores or shows a drop in quality relative to the test-time baselines.
Figures



read the original abstract
Open-ended generation tasks often require a set of meaningfully different outputs, yet large language models often produce similar generations. Existing test-time diversity methods operate at different stages of generation with varying effectiveness, but it remains unclear what design choices lead to meaningful diversity in the output. We introduce a framework that characterizes test-time diverse generation methods by the diversity source introduced during generation and provide a transmission score for measuring how effectively variation in the source reaches the final output. Guided by this framework, we propose fully automated specification-level generation methods that first generate diverse intermediate specifications and then condition on them to produce final responses. Across five open-ended tasks and four backbone models, specification-level injection improves output diversity over test-time baselines while maintaining comparable quality. Our analysis shows that successful diversity injection depends on both the diversity of the sources and their transmission to the output, highlighting source design and source-to-output realization as two key levers for building more diverse generation systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a unified framework for test-time diverse generation that characterizes methods according to the diversity source introduced and defines a transmission score to quantify how variation from that source reaches the final output. It proposes fully automated specification-level injection methods that generate diverse intermediate specifications before conditioning the model on them. Experiments across five open-ended tasks and four backbone models show that specification-level injection yields higher output diversity than existing test-time baselines while preserving comparable quality; analysis attributes success to both source diversity and transmission.
Significance. If the transmission score is shown to track human-perceived meaningful diversity, the framework supplies a principled lens for comparing and designing diversity methods, isolating source design and source-to-output realization as actionable levers. The empirical demonstration that specification-level injection outperforms test-time baselines on multiple tasks and models would be a concrete, reproducible contribution to open-ended generation.
major comments (2)
- [Methods (transmission score definition and § on analysis)] The transmission score (defined via source-output divergence in the methods section) is load-bearing for the central claim that specification-level injection improves diversity; the manuscript provides no correlation study, human rating experiment, or ablation demonstrating that elevated scores correspond to semantically meaningful variety rather than superficial lexical or syntactic changes.
- [§ on specification-level generation methods] The automated specification generation procedure is presented as reliable without task-specific tuning, yet the paper reports no human oversight or validation that the generated specifications are meaningfully diverse and on-topic; this assumption underpins both the diversity gains and the claim of full automation.
minor comments (2)
- [Abstract] The abstract states empirical gains but omits the concrete diversity metrics, quality metrics, number of samples per condition, and statistical tests; these details should be added for immediate readability.
- [Framework section] Notation for the transmission score and the diversity source should be introduced with an explicit equation or pseudocode early in the framework section to avoid ambiguity when comparing methods.
Simulated Author's Rebuttal
Thank you for the detailed review. We address the major comments regarding the validation of the transmission score and the automation of specification generation. We believe our framework provides a useful lens, and we will incorporate clarifications and additional analyses where appropriate.
read point-by-point responses
-
Referee: [Methods (transmission score definition and § on analysis)] The transmission score (defined via source-output divergence in the methods section) is load-bearing for the central claim that specification-level injection improves diversity; the manuscript provides no correlation study, human rating experiment, or ablation demonstrating that elevated scores correspond to semantically meaningful variety rather than superficial lexical or syntactic changes.
Authors: The transmission score is defined as a measure of divergence between the source and the output to quantify transmission of variation. Our analysis in the paper shows that specification-level methods achieve higher transmission scores, which align with higher output diversity metrics. While we have not performed human ratings to validate semantic meaningfulness, the score is not claimed to directly measure human perception but rather to isolate the transmission mechanism. We can revise the manuscript to include a clearer discussion of its limitations as a proxy and perhaps add an ablation on different divergence measures. revision: partial
-
Referee: [§ on specification-level generation methods] The automated specification generation procedure is presented as reliable without task-specific tuning, yet the paper reports no human oversight or validation that the generated specifications are meaningfully diverse and on-topic; this assumption underpins both the diversity gains and the claim of full automation.
Authors: The specification generation uses a general prompt to the LLM to create diverse specifications without task-specific tuning, as described in the methods. We include qualitative examples in the supplementary material demonstrating that they are on-topic and diverse. The success across multiple tasks and models supports their effectiveness. However, we agree that explicit human validation would strengthen the claim of full automation and will add a note on this or additional examples in the revision. revision: partial
Circularity Check
No significant circularity: framework and transmission score are new analytical constructs; central empirical claims rest on independent task/model comparisons.
full rationale
The paper introduces a characterization of diversity methods via sources and defines a transmission score as a measurement tool, then reports empirical gains from specification-level injection on standard diversity/quality metrics across five tasks and four models. No quoted equations or definitions reduce the transmission score or output diversity metrics to the proposed injection method by construction, nor do any self-citations load-bear the main result. The derivation chain remains self-contained against external benchmarks and does not exhibit any of the enumerated circular patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Diversity sources can be characterized by injection point and their variation can be quantified by a transmission score that predicts output diversity.
Reference graph
Works this paper leans on
-
[1]
Avoidance decoding for diverse multi-branch story generation. InProceedings of the 2025 Con- ference on Empirical Methods in Natural Language Processing, pages 7489–7505, Suzhou, China. Asso- ciation for Computational Linguistics. Poetry Foundation. 2023. Poetryfoundation.org: Data summary. Public online archive. Nils Reimers and Iryna Gurevych. 2019. Sen...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 9226–9242, Mi- ami, Florida, USA
Improving diversity of commonsense genera- tion by large language models via in-context learning. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 9226–9242, Mi- ami, Florida, USA. Association for Computational Linguistics. 10 Yiming Zhang, Harshita Diddee, Susan Holm, Hanchen Liu, Xinyue Liu, Vinay Samuel, Barry Wang, and Da...
2024
-
[3]
instructional tone
Each outline is a compact list of 4–6 keywords/phrases capturing: tone, format, perspective, and key focus. Good examples: “instructional tone”, “bullet-point for- mat”, “second-person”, “focus on failure cases”
-
[4]
Maximize diversity: no two outlines should share more than 1 keyword
-
[5]
outlines
Keywords must be task-specific — encode what makes each approach different for this particular request. Output JSON only: { "outlines": [ { "id": 1, "keywords": ["keyword1", ..., "keyword4"] }, ... ] } User Prompt Task: {TASK} Figure 7: Prompt used to generate m diverse keyword outlines in one batch call in Diverse Outline. 12 Table 4: Diversity and quali...
-
[7]
Let each keyword shape the tone, format, and focus of your response
-
[9]
Output ONLY the final response text
Do not list or explain the keywords. Output ONLY the final response text. Figure 8: Prompt used to generate outputs conditioned on a Diverse Outline specification. 15 Table 8: Lexical diversity (Distinct-3 and Self-BLEU) on WritingPrompts, IBM ArgKP, and Poetry Foundation. Methods are grouped by injection level. DeepSeek-V3.2 and Qwen3-4B include a high-t...
-
[10]
axes": [ {
Draw a random combination c1 uniformly from the full space as the seed. 16 System Prompt — Axis Generation You are a creative diversity planner. Generate {N_KEYS} independent structural dimensions (axes) that capture the most impactful creative choices for responses to the given task. For each axis, generate {N_V ALUES} distinct values representing meanin...
-
[11]
, m : select the candidate c∗ that maximizes itsminimumHamming distance to all already-selected combinations, ci = arg max c/∈S min c′∈S dH (c,c ′), where S={c 1,
For i= 2, . . . , m : select the candidate c∗ that maximizes itsminimumHamming distance to all already-selected combinations, ci = arg max c/∈S min c′∈S dH (c,c ′), where S={c 1, . . . ,ci−1} is the set of already- selected combinations. Ties are broken ran- domly. This max-min criterion acts as a greedy farthest- point sampler in Hamming space, ensuring ...
-
[12]
Strictly follow any constraints in the Task
-
[13]
A reader should be able to identify every axis value directly from your text without being told
EACH axis value in the Outline MUST be clearly and visibly present in your response. A reader should be able to identify every axis value directly from your text without being told
-
[14]
Keep your response to approximately 200 words
-
[15]
Give one popular name for a baby boy in Papua New Guinea
Do not list or explain the axis values. Output ONLY the final response text. Figure 10: Prompt used to generate outputs conditioned on a Keyword specification. baby boy in Papua New Guinea."). The Direct base- line collapses to a single template across all 20 out- puts, producing only 2 distinct equivalence classes, while both Level 2 methods produce resp...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.