SVR-MAD: A Bayesian-Inspired Framework for Posterior-Guided Multi-Agent Debate
Pith reviewed 2026-05-25 04:49 UTC · model grok-4.3
The pith
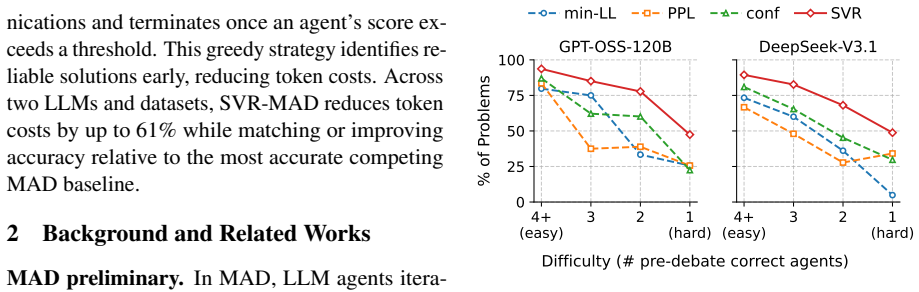
SVR-MAD treats debate outcomes as Bayesian posterior evidence to prune unreliable agent communications and cut token use by up to 61 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SVR-MAD is a Bayesian-inspired framework that models pre-debate signals as priors and uses debate outcomes as posterior-style evidence to estimate agent correctness, then incrementally builds a sparse communication graph that prioritizes agents whose answers withstand peer challenges; experiments show this reduces token cost by up to 61 percent while matching or exceeding the accuracy of the strongest competing MAD baseline.
What carries the argument
Posterior-guided incremental graph construction that replaces prior-only pruning with evidence drawn from debate survival.
If this is right
- MAD systems can scale to larger agent populations without quadratic growth in context length.
- Accuracy holds steady or improves on benchmarks even when initial agent signals are noisy.
- Token budgets can be reallocated from redundant exchanges to additional debate rounds or verification steps.
- The same evidence-updating logic can replace hand-tuned thresholds in other pruning-based multi-agent protocols.
Where Pith is reading between the lines
- If debate evidence proves robust, the method could be combined with external fact-checking or tool-use agents to further tighten the posterior estimates.
- The framework suggests a general template for any multi-agent loop in which interaction results can be treated as likelihood updates rather than discarded after one round.
- Extending the same prior-to-posterior update to dynamic agent addition or removal might allow open-ended debate without fixed team size.
Load-bearing premise
Debate outcomes supply more reliable evidence of agent correctness than the pre-debate signals the method replaces, even when hallucinations occur.
What would settle it
A controlled run in which the same set of agent answers and debates are fed to both SVR-MAD and a prior-only baseline, but debate outcomes are randomly flipped so that incorrect agents appear to win; if SVR-MAD then shows no cost reduction or lower accuracy than the baseline, the central claim fails.
Figures


read the original abstract
Multi-Agent Debate (MAD) improves LLM-agent accuracy but suffers from rapid context growth, limiting scalability in larger multi-agent settings. Existing methods prune low-utility communications using prior signals, such as token-level log-likelihoods or LLM self-reported confidence. However, these signals become unreliable under hallucination, degrading the accuracy of MAD methods that rely on them. We propose SVR-MAD, a Bayesian-inspired MAD framework that treats pre-debate signals as priors and debate outcomes as posterior-style evidence for estimating agent correctness. SVR-MAD uses this evidence to incrementally construct the communication graph, prioritizing agents whose answers survive peer challenges. Experiments across multiple LLMs and benchmarks show that SVR-MAD reduces token cost by up to 61% while matching or improving accuracy relative to the most accurate competing MAD baseline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SVR-MAD, a Bayesian-inspired framework for multi-agent debate (MAD) that treats pre-debate signals (e.g., log-likelihoods or self-reported confidence) as priors and debate outcomes as posterior-style evidence of agent correctness. This evidence is used to incrementally construct and prune the communication graph by prioritizing agents whose answers survive peer challenges, with the goal of mitigating rapid context growth. Experiments across multiple LLMs and benchmarks are reported to show up to 61% token cost reduction while matching or improving accuracy relative to the strongest competing MAD baseline.
Significance. If the empirical results are robust, the framework offers a principled mechanism to improve MAD scalability by replacing unreliable prior signals with posterior evidence from debate dynamics, potentially enabling larger agent teams without proportional increases in token usage.
major comments (2)
- [Abstract / Experiments] The central claim that debate outcomes supply meaningfully superior evidence to pre-debate signals (especially under hallucination) is load-bearing for the reported accuracy and cost gains, yet the abstract provides no information on experimental design, number of agents, benchmarks, baselines, or statistical tests; without these details it is impossible to evaluate whether the 61% reduction follows from the Bayesian mechanism rather than from a heuristic pruning rule.
- [Introduction / Framework description] The motivation states that priors become unreliable under hallucination, but the framework description does not address or test the case in which hallucinations are correlated across agents (so that peer challenges fail to surface contradictions); if this occurs, the incremental graph construction reduces to a signal no stronger than the baselines it claims to outperform.
minor comments (2)
- [Method] Notation for the prior and posterior quantities is introduced without an explicit equation or update rule, making it difficult to verify that the method is truly Bayesian rather than a heuristic reweighting of debate outcomes.
- [Abstract] The abstract claims results 'across multiple LLMs and benchmarks' but does not name them; adding this information would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment point-by-point below. We agree that the abstract would benefit from additional experimental details and will revise it accordingly. We also acknowledge the need to discuss the edge case of correlated hallucinations and will add a limitations paragraph.
read point-by-point responses
-
Referee: [Abstract / Experiments] The central claim that debate outcomes supply meaningfully superior evidence to pre-debate signals (especially under hallucination) is load-bearing for the reported accuracy and cost gains, yet the abstract provides no information on experimental design, number of agents, benchmarks, baselines, or statistical tests; without these details it is impossible to evaluate whether the 61% reduction follows from the Bayesian mechanism rather than from a heuristic pruning rule.
Authors: We agree the abstract is too concise. In the revision we will expand it to state that experiments used 3–7 agents on GSM8K, MATH, and MMLU with GPT-4, Llama-3, and Mixtral, comparing against AgentVerse, standard MAD, and prior-only pruning baselines. Results are reported as means over five independent runs with paired t-tests for significance. Ablation studies (Section 4.3) isolate the contribution of the posterior update: removing it increases token usage by 30–40% while lowering accuracy, confirming the reported gains derive from the Bayesian mechanism rather than generic pruning. revision: yes
-
Referee: [Introduction / Framework description] The motivation states that priors become unreliable under hallucination, but the framework description does not address or test the case in which hallucinations are correlated across agents (so that peer challenges fail to surface contradictions); if this occurs, the incremental graph construction reduces to a signal no stronger than the baselines it claims to outperform.
Authors: The reported benchmarks contain instances of hallucination, and SVR-MAD still matches or exceeds baseline accuracy, indicating that debate-derived evidence remains informative. We nevertheless accept that the manuscript does not explicitly construct or test a controlled scenario of fully correlated hallucinations. We will add a paragraph to the Discussion section noting this limitation and stating that under complete correlation the method would revert to prior-based selection, performing no better than the baselines. This does not alter the core empirical findings on the tested benchmarks. revision: partial
Circularity Check
No circularity: framework is heuristic with experimental validation, no derivations or self-referential reductions present
full rationale
The provided manuscript text contains no equations, derivations, or parameter-fitting steps. The SVR-MAD description treats debate outcomes as external evidence for graph construction without claiming a first-principles derivation that reduces to its inputs. Claims rest on empirical results across LLMs and benchmarks rather than any self-definitional, fitted-prediction, or self-citation chain. No load-bearing uniqueness theorems or ansatzes are invoked. This is the normal case of an applied framework whose correctness is externally falsifiable via the reported accuracy and token-cost metrics.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
and Mordatch, Igor , title =
Du, Yilun and Li, Shuang and Torralba, Antonio and Tenenbaum, Joshua B. and Mordatch, Igor , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
2024
-
[2]
Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =
Li, Guohao and Al Kader Hammoud, Hasan Abed and Itani, Hani and Khizbullin, Dmitrii and Ghanem, Bernard , title =. Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =. 2023 , publisher =
2023
-
[3]
AutoGen: Enabling Next-Gen
Qingyun Wu and Gagan Bansal and Jieyu Zhang and Yiran Wu and Beibin Li and Erkang Zhu and Li Jiang and Xiaoyun Zhang and Shaokun Zhang and Jiale Liu and Ahmed Hassan Awadallah and Ryen W White and Doug Burger and Chi Wang , booktitle=. AutoGen: Enabling Next-Gen. 2024 , url=
2024
-
[5]
2025 , eprint=
SID: Multi-LLM Debate Driven by Self Signals , author=. 2025 , eprint=
2025
-
[6]
2025 , eprint=
GroupDebate: Enhancing the Efficiency of Multi-Agent Debate Using Group Discussion , author=. 2025 , eprint=
2025
-
[7]
2026 , eprint=
Demystifying Multi-Agent Debate: The Role of Confidence and Diversity , author=. 2026 , eprint=
2026
-
[9]
2026 , url=
Philippe Laban and Hiroaki Hayashi and Yingbo Zhou and Jennifer Neville , booktitle=. 2026 , url=
2026
-
[10]
2025 , eprint=
Why Language Models Hallucinate , author=. 2025 , eprint=
2025
-
[11]
CoRR , volume =
Jacob Devlin and Ming. CoRR , volume =. 2018 , url =
2018
-
[13]
2025 , eprint=
gpt-oss-120b & gpt-oss-20b Model Card , author=. 2025 , eprint=
2025
-
[14]
o zdenur and Martinez, Dakotah and Pageler, Ben and Zhou, Kevin and Soori, Saeed and Press, Ori and Tang, Henry and Rissone, Paolo and Green, Sean R and Br \
Phan, Long and Gatti, Alice and Li, Nathaniel and Khoja, Adam and Kim, Ryan and Ren, Richard and Hausenloy, Jason and Zhang, Oliver and Mazeika, Mantas and Hendrycks, Dan and Han, Ziwen and Hu, Josephina and Zhang, Hugh and Zhang, Chen Bo Calvin and Shaaban, Mohamed and Ling, John and Shi, Sean and Choi, Michael and Agrawal, Anish and Chopra, Arnav and Na...
-
[15]
The Eleventh International Conference on Learning Representations , year=
Self-Consistency Improves Chain of Thought Reasoning in Language Models , author=. The Eleventh International Conference on Learning Representations , year=
-
[16]
Enhancing Multi-Agent Debate System Performance via Confidence Expression
Lin, Zijie and Hooi, Bryan. Enhancing Multi-Agent Debate System Performance via Confidence Expression. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.343
-
[17]
2025 , eprint=
Debate Only When Necessary: Adaptive Multiagent Collaboration for Efficient LLM Reasoning , author=. 2025 , eprint=
2025
-
[18]
2024 , eprint=
DeepSeek-V3 Technical Report , author=. 2024 , eprint=
2024
- [19]
-
[20]
DeepSeek-AI. 2024. https://arxiv.org/abs/2412.19437 Deepseek-v3 technical report . Preprint, arXiv:2412.19437
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Tenenbaum, and Igor Mordatch
Yilun Du, Shuang Li, Antonio Torralba, Joshua B. Tenenbaum, and Igor Mordatch. 2024. Improving factuality and reasoning in language models through multiagent debate. In Proceedings of the 41st International Conference on Machine Learning, ICML'24. JMLR.org
2024
- [22]
-
[23]
Why Language Models Hallucinate
Adam Tauman Kalai, Ofir Nachum, Santosh S. Vempala, and Edwin Zhang. 2025. https://arxiv.org/abs/2509.04664 Why language models hallucinate . Preprint, arXiv:2509.04664
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Philippe Laban, Hiroaki Hayashi, Yingbo Zhou, and Jennifer Neville. 2026. https://openreview.net/forum?id=VKGTGGcwl6 LLM s get lost in multi-turn conversation . In The Fourteenth International Conference on Learning Representations
2026
-
[25]
Guohao Li, Hasan Abed Al Kader Hammoud, Hani Itani, Dmitrii Khizbullin, and Bernard Ghanem. 2023. Camel: communicative agents for "mind" exploration of large language model society. In Proceedings of the 37th International Conference on Neural Information Processing Systems, NIPS '23, Red Hook, NY, USA. Curran Associates Inc
2023
-
[26]
Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2024. https://doi.org/10.1162/tacl_a_00638 Lost in the middle: How language models use long contexts . Transactions of the Association for Computational Linguistics, 12:157--173
- [27]
-
[28]
Thang Luong, Dawsen Hwang, Hoang H Nguyen, Golnaz Ghiasi, Yuri Chervonyi, Insuk Seo, Junsu Kim, Garrett Bingham, Jonathan Lee, Swaroop Mishra, Alex Zhai, Huiyi Hu, Henryk Michalewski, Jimin Kim, Jeonghyun Ahn, Junhwi Bae, Xingyou Song, Trieu Hoang Trinh, Quoc V Le, and Junehyuk Jung. 2025. https://doi.org/10.18653/v1/2025.emnlp-main.1794 Towards robust ma...
-
[29]
OpenAI. 2025. https://arxiv.org/abs/2508.10925 gpt-oss-120b & gpt-oss-20b model card . Preprint, arXiv:2508.10925
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Long Phan, Alice Gatti, Nathaniel Li, Adam Khoja, Ryan Kim, Richard Ren, Jason Hausenloy, Oliver Zhang, Mantas Mazeika, Dan Hendrycks, Ziwen Han, Josephina Hu, Hugh Zhang, Chen Bo Calvin Zhang, Mohamed Shaaban, John Ling, Sean Shi, Michael Choi, Anish Agrawal, and 281 others. 2026. A benchmark of expert-level academic questions to assess AI capabilities. ...
2026
-
[31]
Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2023. https://openreview.net/forum?id=1PL1NIMMrw Self-consistency improves chain of thought reasoning in language models . In The Eleventh International Conference on Learning Representations
2023
-
[32]
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, Ahmed Hassan Awadallah, Ryen W White, Doug Burger, and Chi Wang. 2024. https://openreview.net/forum?id=BAakY1hNKS Autogen: Enabling next-gen LLM applications via multi-agent conversations . In First Conference on Language Modeling
2024
-
[33]
Yuting Zeng, Weizhe Huang, Lei Jiang, Tongxuan Liu, XiTai Jin, Chen Tianying Tiana, Jing Li, and Xiaohua Xu. 2025. https://doi.org/10.18653/v1/2025.naacl-long.475 S ^2 - MAD : Breaking the token barrier to enhance multi-agent debate efficiency . In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computation...
- [34]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.