Differential Unfolding: Efficient Unfolding Reconstruction for Video Snapshot Compressive Imaging
Pith reviewed 2026-06-26 01:35 UTC · model grok-4.3
The pith
Differential Unfolding replaces uniform repetition in deep unfolding networks with sparse high-parameter anchoring stages and lightweight differential evolution stages to improve the accuracy-efficiency trade-off for video snapshot compress
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that partitioning the unfolding process into structural anchoring (high-parameter general stages placed sparsely) and differential evolution (lightweight stages driven by the Differential Representation Prior) allows the network to focus computation on meaningful cross-stage variations instead of redundant static representations, thereby delivering a better accuracy-efficiency balance than uniform deep unfolding networks.
What carries the argument
The Differential Evolutionary Framework (DEF), which assigns complementary roles of structural anchoring to sparse high-parameter stages and differential evolution to lightweight stages equipped with Differential Representation Attention and Differential Modulated FFN inside the Differential Representation Prior.
If this is right
- Video SCI reconstruction can reach higher fidelity at lower parameter and FLOPs budgets than uniform DUN baselines.
- Cross-stage feature variations can be modeled explicitly with lightweight modules rather than by repeating full-capacity priors.
- The same heterogeneous anchoring-plus-evolution pattern may apply to other iterative reconstruction tasks that exhibit convergence to static representations.
Where Pith is reading between the lines
- If the differential mechanism proves robust, similar stage-wise differentiation could be tested in non-SCI domains such as iterative solvers for inverse problems in medical imaging.
- The approach implicitly questions whether all stages in any unfolding network need identical capacity once early stages have stabilized the representation.
- An open extension would be to learn the placement and depth of the sparse anchoring stages rather than fixing them manually.
Load-bearing premise
The premise that optimization trajectories in existing deep unfolding networks converge toward static states, producing representation stagnation that uniform repetition cannot avoid.
What would settle it
A controlled comparison in which a uniform deep unfolding network is trained on the same video SCI data and shows no measurable stagnation in feature updates across stages, or where the differential stages fail to improve the accuracy-compute curve.
Figures
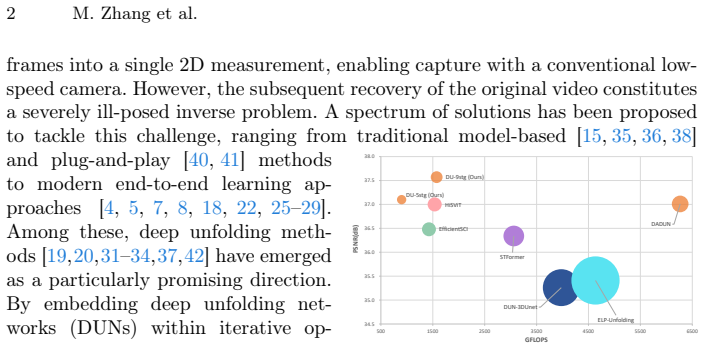
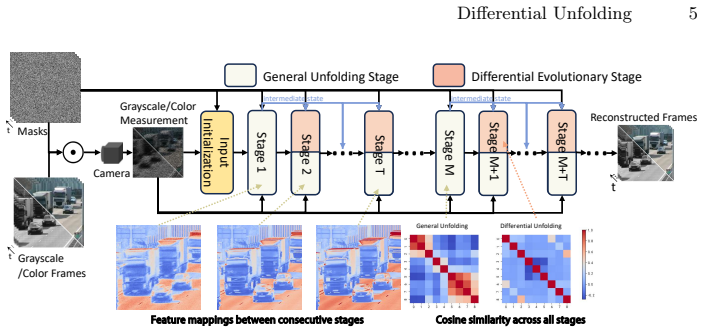
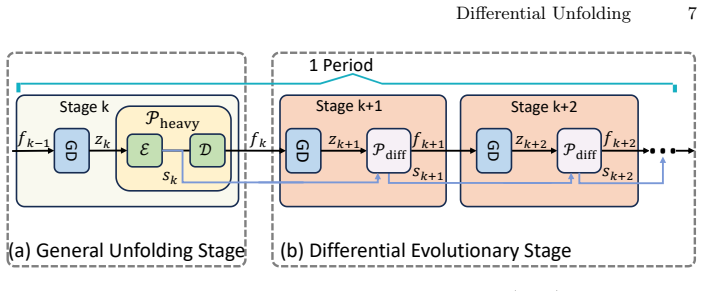
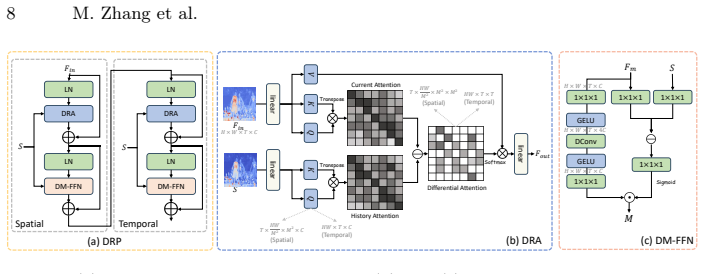


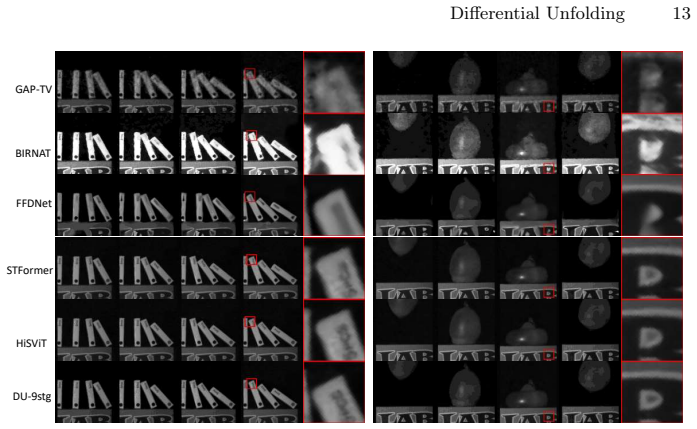
read the original abstract
While Deep Unfolding Networks (DUNs) dominate video Snapshot Compressive Imaging (SCI), they remain constrained by a uniform design philosophy. Existing methods repeatedly stack high-complexity priors with identical structures, ignoring the fact that optimization trajectories converge toward static states. This results in representation stagnation, where high-cost computations are wasted on minimal feature updates. To address this inefficiency, we present Differential Unfolding (DU), a heterogeneous framework that replaces uniform repetition with dynamic evolution. Central to DU is the Differential Evolutionary Framework (DEF), which partitions the unfolding process into two complementary roles: structural anchoring and differential evolution. In this scheme, high-parameter general stages are sparsely deployed to generate high-fidelity feature foundations. Complementing these, lightweight differential stages employ a Differential Representation Prior (DRP) to propagate and refine these foundational features through a differential mechanism. By integrating Differential Representation Attention (DRA) for evolving attention maps and a Differential Modulated FFN (DM-FFN) for feature rectification, DRP effectively models cross-stage variations with minimal overhead. By focusing computational resources on dynamic evolution rather than static redundancy, DU achieves a superior trade-off between accuracy and efficiency. Extensive experiments verify that our method establishes new state-of-the-art results while significantly slashing computational overhead. https://github.com/Muyuan-Zhang/DU
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Differential Unfolding (DU) for video Snapshot Compressive Imaging (SCI), replacing the uniform stacking of identical high-complexity priors in Deep Unfolding Networks (DUNs) with a heterogeneous Differential Evolutionary Framework (DEF). This partitions unfolding into sparse high-parameter anchoring stages and lightweight differential stages that use a Differential Representation Prior (DRP) incorporating Differential Representation Attention (DRA) and Differential Modulated FFN (DM-FFN) to model cross-stage variations. The central claim is that this addresses representation stagnation in optimization trajectories, yielding new state-of-the-art accuracy with substantially lower computational overhead, as verified by experiments; code is released at https://github.com/Muyuan-Zhang/DU.
Significance. If the accuracy-efficiency gains hold under rigorous verification, the work could meaningfully advance efficient DUN designs for SCI by shifting compute from redundant static stages to dynamic evolution. The open-source implementation supports reproducibility, which strengthens the contribution.
major comments (3)
- [Abstract / §1] Abstract and §1 (motivation): The claim that 'optimization trajectories converge toward static states' producing 'representation stagnation' is load-bearing for the entire DEF design (sparse anchoring + DRP/DRA/DM-FFN), yet no supporting measurement—such as per-stage feature delta norms, gradient magnitudes, or activation change statistics across uniform DUN baselines—is provided. Without this, the differential mechanism risks being an architectural search artifact rather than a principled response to observed stagnation.
- [§3] §3 (DEF and DRP): The differential mechanism is asserted to 'effectively model cross-stage variations with minimal overhead,' but the manuscript does not derive or bound the complexity reduction relative to uniform repetition (e.g., no FLOPs or parameter comparison that isolates the effect of DRP versus simply using fewer total stages). This leaves the efficiency claim unanchored.
- [Experiments] Experiments section (SOTA claims): The abstract states 'new state-of-the-art results while significantly slashing computational overhead,' but without reported error bars, multiple random seeds, or explicit baseline re-implementations with identical training protocols, it is impossible to assess whether the reported gains exceed typical variance in SCI reconstruction benchmarks.
minor comments (2)
- [§3] Notation for the new modules (DRP, DRA, DM-FFN) should be introduced with explicit equations in §3 before their use in the overall architecture diagram.
- The GitHub link is provided; confirming that the released code reproduces the exact tables and figures would strengthen the submission.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our contributions. We address each major comment below and indicate planned revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract / §1] Abstract and §1 (motivation): The claim that 'optimization trajectories converge toward static states' producing 'representation stagnation' is load-bearing for the entire DEF design (sparse anchoring + DRP/DRA/DM-FFN), yet no supporting measurement—such as per-stage feature delta norms, gradient magnitudes, or activation change statistics across uniform DUN baselines—is provided. Without this, the differential mechanism risks being an architectural search artifact rather than a principled response to observed stagnation.
Authors: We agree that quantitative support for the stagnation phenomenon would strengthen the motivation. In the revised manuscript we will add a short analysis subsection (or appendix) reporting per-stage feature delta norms (L2) and activation change statistics computed on a representative uniform DUN baseline, confirming the observed convergence toward static states. This will directly tie the DEF design to the measured behavior rather than leaving it as an unverified premise. revision: yes
-
Referee: [§3] §3 (DEF and DRP): The differential mechanism is asserted to 'effectively model cross-stage variations with minimal overhead,' but the manuscript does not derive or bound the complexity reduction relative to uniform repetition (e.g., no FLOPs or parameter comparison that isolates the effect of DRP versus simply using fewer total stages). This leaves the efficiency claim unanchored.
Authors: The efficiency advantage arises because high-parameter anchoring stages are used only sparsely while the majority of stages employ the lightweight DRP. Although overall FLOPs and parameter counts are reported in the experiments, we acknowledge that an explicit isolation (e.g., a controlled comparison of uniform vs. differential designs at matched total complexity) is missing. We will add such a comparison table and brief derivation in §3 of the revision to anchor the overhead reduction claim. revision: yes
-
Referee: [Experiments] Experiments section (SOTA claims): The abstract states 'new state-of-the-art results while significantly slashing computational overhead,' but without reported error bars, multiple random seeds, or explicit baseline re-implementations with identical training protocols, it is impossible to assess whether the reported gains exceed typical variance in SCI reconstruction benchmarks.
Authors: Our reported numbers follow the evaluation protocol common in the SCI literature (single training run per method, averaged over test sequences). To address the concern we will (i) rerun the proposed method and key baselines with three random seeds and report mean ± std, and (ii) explicitly state in the revision which baselines were re-trained under identical protocols versus taken from original papers. This will allow readers to judge whether gains exceed typical variance. revision: partial
Circularity Check
No circularity: structural redesign with independent premise
full rationale
The paper's central claim is a heterogeneous unfolding architecture (DEF with DRP/DRA/DM-FFN) motivated by an unverified premise about stagnation in uniform DUNs. No equations, parameter fits, or self-citations are shown that reduce the claimed accuracy-efficiency gains to the inputs by construction. The derivation chain consists of a design choice justified by the premise rather than any self-referential reduction, making the framework self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Optimization trajectories in deep unfolding networks converge toward static states, causing representation stagnation when identical high-complexity priors are repeated.
invented entities (4)
-
Differential Evolutionary Framework (DEF)
no independent evidence
-
Differential Representation Prior (DRP)
no independent evidence
-
Differential Representation Attention (DRA)
no independent evidence
-
Differential Modulated FFN (DM-FFN)
no independent evidence
Reference graph
Works this paper leans on
-
[2]
(eds.) Proceedings of the 38th In- ternational Conference on Machine Learning
Bertasius, G., Wang, H., Torresani, L.: Is space-time attention all you need for video understanding? In: Meila, M., Zhang, T. (eds.) Proceedings of the 38th In- ternational Conference on Machine Learning. Proceedings of Machine Learning Research, vol. 139, pp. 813–824. PMLR (18–24 Jul 2021)
2021
-
[3]
In: Koyejo, S., Mohamed, S., Agarwal, A., Belgrave, D., Cho, K., Oh, A
Cai, Y., Lin, J., Wang, H., Yuan, X., Ding, H., Zhang, Y., Timofte, R., Gool, L.V.:Degradation-awareunfoldinghalf-shuffletransformerforspectralcompressive imaging. In: Koyejo, S., Mohamed, S., Agarwal, A., Belgrave, D., Cho, K., Oh, A. (eds.) Advances in Neural Information Processing Systems. vol. 35, pp. 37749– 37761. Curran Associates, Inc. (2022)
2022
-
[4]
In: Proceedings of the 32nd ACM International Conference on Multimedia
Cao, M., Wang, L., Wang, H., Wang, G., Yuan, X.: Towards real-time video com- pressive sensing on mobile devices. In: Proceedings of the 32nd ACM International Conference on Multimedia. p. 11080–11088. MM ’24, Association for Computing Machinery, New York, NY, USA (2024).https://doi.org/10.1145/3664647. 3680561
-
[5]
In: Leonardis, A., Ricci, E., Roth, S., Russakovsky, O., Sattler, T., Varol, G
Cao, M., Wang, L., Wang, H., Yuan, X.: A simple low-bit quantization framework for video snapshot compressive imaging. In: Leonardis, A., Ricci, E., Roth, S., Russakovsky, O., Sattler, T., Varol, G. (eds.) Computer Vision – ECCV 2024. pp. 112–129. Springer Nature Switzerland, Cham (2025)
2024
-
[6]
International Journal of Computer Vision pp
Cao, M., Wang, L., Zhu, M., Yuan, X.: Hybrid cnn-transformer architecture for efficient large-scale video snapshot compressive imaging. International Journal of Computer Vision pp. 1–20 (2024)
2024
-
[7]
2021 IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR) pp
Cheng, Z., Chen, B., Liu, G., Zhang, H., Lu, R., Wang, Z., Yuan, X.: Memory- efficient network for large-scale video compressive sensing. 2021 IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR) pp. 16241–16250 (2021)
2021
-
[8]
Cheng, Z., Chen, B., Lu, R., Wang, Z., Zhang, H., Meng, Z., Yuan, X.: Recurrent neural networks for snapshot compressive imaging. IEEE Transactions on Pattern Analysis and Machine Intelligence45(2), 2264–2281 (2023).https://doi.org/10. 1109/TPAMI.2022.3161934
arXiv 2023
-
[9]
In: International Conference on Learning Representations (2021)
Chu, X., Tian, Z., Zhang, B., Wang, X., Shen, C.: Conditional positional encodings for vision transformers. In: International Conference on Learning Representations (2021)
2021
-
[10]
Donoho,D.:Compressedsensing.IEEETransactionsonInformationTheory52(4), 1289–1306 (2006).https://doi.org/10.1109/TIT.2006.871582
-
[11]
ICLR (2021)
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., Houlsby, N.: An image is worth 16x16 words: Transformers for image recognition at scale. ICLR (2021)
2021
-
[12]
Nature516(7529), 74–77 (Dec 2014).https://doi.org/10.1038/nature14005
Gao, L., Liang, J., Li, C., Wang, L.V.: Single-shot compressed ultrafast photog- raphy at one hundred billion frames per second. Nature516(7529), 74–77 (Dec 2014).https://doi.org/10.1038/nature14005
-
[13]
In: 2011 International Conference on Computer Vision
Hitomi, Y., Gu, J., Gupta, M., Mitsunaga, T., Nayar, S.K.: Video from a sin- gle coded exposure photograph using a learned over-complete dictionary. In: 2011 International Conference on Computer Vision. pp. 287–294 (2011).https: //doi.org/10.1109/ICCV.2011.6126254 16 M. Zhang et al
-
[14]
Kingma, D.P., Ba, J.: Adam: A method for stochastic optimization. CoRR abs/1412.6980(2014)
Pith/arXiv arXiv 2014
-
[15]
Liu, Y., Yuan, X., Suo, J., Brady, D.J., Dai, Q.: Rank minimization for snapshot compressive imaging. IEEE Transactions on Pattern Analysis and Machine Intelli- gence41(12), 2990–3006 (2019).https://doi.org/10.1109/TPAMI.2018.2873587
-
[16]
Optics Express21(9), 10526 (Apr 2013).https://doi.org/10.1364/oe.21.010526
Llull, P., Liao, X., Yuan, X., Yang, J., Kittle, D., Carin, L., Sapiro, G., Brady, D.J.: Coded aperture compressive temporal imaging. Optics Express21(9), 10526 (Apr 2013).https://doi.org/10.1364/oe.21.010526
-
[17]
arXiv: Learning (2016)
Loshchilov, I., Hutter, F.: Sgdr: Stochastic gradient descent with warm restarts. arXiv: Learning (2016)
2016
-
[18]
Lu,R.,Cheng,Z.,Chen,B.,Yuan,X.:Motion-awaredynamicgraphneuralnetwork forvideocompressivesensing.IEEETransactionsonPatternAnalysisandMachine Intelligence46(12), 7850–7866 (2024).https://doi.org/10.1109/TPAMI.2024. 3395804
-
[19]
In: 2019 IEEE/CVF International Conference on Computer Vision (ICCV)
Ma, J., Liu, X.Y., Shou, Z., Yuan, X.: Deep tensor admm-net for snapshot compres- sive imaging. In: 2019 IEEE/CVF International Conference on Computer Vision (ICCV). pp. 10222–10231 (2019).https://doi.org/10.1109/ICCV.2019.01032
-
[20]
Meng, Z., Yuan, X., Jalali, S.: Deep Unfolding for Snapshot Compressive Imaging. International Journal of Computer Vision131(11), 2933–2958 (Nov 2023).https: //doi.org/10.1007/s11263-023-01844-4
-
[21]
Pont-Tuset, J., Perazzi, F., Caelles, S., Arbeláez, P., Sorkine-Hornung, A., Gool, L.V.: The 2017 davis challenge on video object segmentation. ArXiv abs/1704.00675(2017)
Pith/arXiv arXiv 2017
-
[22]
APL Photonics5(3), 030801 (Mar 2020).https://doi.org/10.1063/1.5140721
Qiao, M., Meng, Z., Ma, J., Yuan, X.: Deep learning for video compressive sensing. APL Photonics5(3), 030801 (Mar 2020).https://doi.org/10.1063/1.5140721
-
[23]
Reddy, D., Veeraraghavan, A., Chellappa, R.: P2c2: Programmable pixel com- pressive camera for high speed imaging. In: CVPR 2011. pp. 329–336 (2011). https://doi.org/10.1109/CVPR.2011.5995542
-
[24]
Sun, Y., Yuan, X., Pang, S.: Compressive high-speed stereo imaging. Opt. Express 25(15), 18182–18190 (Jul 2017).https://doi.org/10.1364/OE.25.018182
-
[25]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp
Wang, L., Cao, M., Yuan, X.: Efficientsci: Densely connected network with space- time factorization for large-scale video snapshot compressive imaging. In: 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 18477–18486 (2023).https://doi.org/10.1109/CVPR52729.2023.01772
-
[27]
doi: 10.1109/ICCV51070.2023.00649
Wang, P., Wang, L., Yuan, X.: Deep optics for video snapshot compressive imaging. In: 2023 IEEE/CVF International Conference on Computer Vision (ICCV). pp. 10612–10622 (2023).https://doi.org/10.1109/ICCV51070.2023.00977
-
[28]
In: Leonardis, A., Ricci, E., Roth, S., Rus- sakovsky, O., Sattler, T., Varol, G
Wang, P., Zhang, Y., Wang, L., Yuan, X.: Hierarchical separable video transformer for snapshot compressive imaging. In: Leonardis, A., Ricci, E., Roth, S., Rus- sakovsky, O., Sattler, T., Varol, G. (eds.) Computer Vision – ECCV 2024. pp. 104–122. Springer Nature Switzerland, Cham (2025)
2024
-
[29]
2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp
Wang, Z., Zhang, H., Cheng, Z., Chen, B., Yuan, X.: Metasci: Scalable and adap- tive reconstruction for video compressive sensing. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp. 2083–2092 (2021)
2021
-
[30]
Image quality assessment: from error visibility to structural similarity
Wang, Z., Bovik, A., Sheikh, H., Simoncelli, E.: Image quality assessment: from error visibility to structural similarity. IEEE Transactions on Image Processing 13(4), 600–612 (2004).https://doi.org/10.1109/TIP.2003.819861 Differential Unfolding 17
-
[31]
In: 2021 IEEE/CVF International Conference on Computer Vision (ICCV)
Wt, Z., Zhangt, J., Mou, C.: Dense deep unfolding network with 3d-cnn prior for snapshot compressive imaging. In: 2021 IEEE/CVF International Conference on Computer Vision (ICCV). pp. 4872–4881 (2021).https://doi.org/10.1109/ ICCV48922.2021.00485
arXiv 2021
-
[32]
Induced and reduced unbounded operator algebras
Wu, Z., Zhang, Z., Song, J., Zhang, M.: Spatial-temporal synergic prior driven unfolding network for snapshot compressive imaging. In: 2021 IEEE International Conference on Multimedia and Expo (ICME). pp. 1–6 (2021).https://doi.org/ 10.1109/ICME51207.2021.9428320
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1109/icme51207.2021.9428320 2021
-
[33]
Xie, S., Huang, Y., Qu, G., Ge, Y.: Sampling-priors-augmented deep unfolding net- workforrobustvideocompressivesensing.JournaloftheFranklinInstitute362(3), 107545 (2025).https://doi.org/https://doi.org/10.1016/j.jfranklin.2025. 107545
-
[34]
arXiv e-prints arXiv:2201.10419 (Jan 2022)
Yang, C., Zhang, S., Yuan, X.: Ensemble learning priors unfolding for scal- able Snapshot Compressive Sensing. arXiv e-prints arXiv:2201.10419 (Jan 2022). https://doi.org/10.48550/arXiv.2201.10419
-
[35]
IEEE Transactions on Image Processing24(1), 106–119 (2015).https://doi.org/10
Yang, J., Liao, X., Yuan, X., Llull, P., Brady, D.J., Sapiro, G., Carin, L.: Com- pressive sensing by learning a gaussian mixture model from measurements. IEEE Transactions on Image Processing24(1), 106–119 (2015).https://doi.org/10. 1109/TIP.2014.2365720
arXiv 2015
-
[36]
Yang,J.,Yuan,X.,Liao,X.,Llull,P.,Brady,D.J.,Sapiro,G.,Carin,L.:Videocom- pressive sensing using gaussian mixture models. IEEE Transactions on Image Pro- cessing23(11), 4863–4878 (2014).https://doi.org/10.1109/TIP.2014.2344294
-
[37]
Selective review of offline change point detection methods,
Yin, J., Wang, N., Hu, B., Wang, Y., Wang, Q.: Degradation-aware deep unfolding network with transformer prior for video compressive imaging. Signal Processing 227, 109660 (2025).https://doi.org/https://doi.org/10.1016/j.sigpro. 2024.109660
-
[38]
In: 2016 IEEE International Conference on Image Processing (ICIP)
Yuan, X.: Generalized alternating projection based total variation minimization for compressive sensing. In: 2016 IEEE International Conference on Image Processing (ICIP). pp. 2539–2543 (2016).https://doi.org/10.1109/ICIP.2016.7532817
-
[39]
Snapshot Compressive Imaging: Theory, Algorithms, and Applications,
Yuan, X., Brady, D.J., Katsaggelos, A.K.: Snapshot compressive imaging: The- ory, algorithms, and applications. IEEE Signal Processing Magazine38(2), 65–88 (2021).https://doi.org/10.1109/MSP.2020.3023869
-
[40]
In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Yuan, X., Liu, Y., Suo, J., Dai, Q.: Plug-and-play algorithms for large-scale snap- shot compressive imaging. In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 1444–1454 (2020).https://doi.org/10. 1109/CVPR42600.2020.00152
arXiv 2020
-
[41]
Yuan, X., Liu, Y., Suo, J., Durand, F., Dai, Q.: Plug-and-play algorithms for video snapshot compressive imaging. IEEE Transactions on Pattern Analysis and Ma- chine Intelligence44(10), 7093–7111 (2022).https://doi.org/10.1109/TPAMI. 2021.3099035
-
[42]
doi: 10.1109/ICCV51070.2023.00649
Zheng, S., Yuan, X.: Unfolding framework with prior of convolution-transformer mixture and uncertainty estimation for video snapshot compressive imaging. In: 2023IEEE/CVFInternationalConferenceonComputerVision(ICCV).pp.12692– 12703 (2023).https://doi.org/10.1109/ICCV51070.2023.01170
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.