When Do Fewer Coordinates Suffice in DP-SGD?
Pith reviewed 2026-06-28 07:01 UTC · model grok-4.3
The pith
When a criterion holds, DP-SGD can restrict updates to k coordinates so noise scales with k rather than full dimension d.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We give a criterion characterizing when coordinate restriction can be beneficial, show via a nonconvex stationarity bound that under this condition the relevant noise term scales with the active dimension k rather than the full parameter dimension d, and provide a lower bound on the reliability of warm-up-based coordinate ranking.
What carries the argument
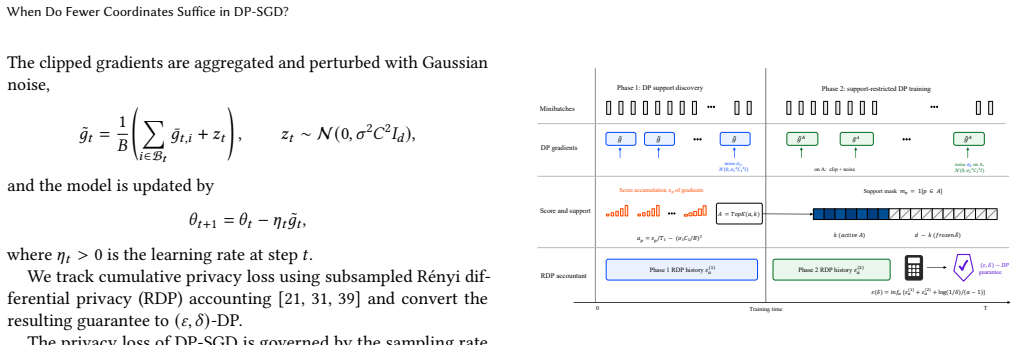
TP-TopK, the two-phase method that runs a private warm-up phase to identify a coordinate support for the main training phase.
If this is right
- Under the stated criterion the noise term in the stationarity bound scales with k rather than d.
- Learned coordinate supports from the warm-up retain more gradient energy than size-matched random supports.
- The largest gains appear when the active dimension is small and the warm-up scores are informative.
- A lower bound is given on the reliability of warm-up-based coordinate ranking.
Where Pith is reading between the lines
- If the criterion can be verified cheaply it would let private training automatically drop uninformative coordinates to lower total noise.
- The same warm-up idea could be tested in other per-coordinate noise mechanisms beyond DP-SGD.
- Checking whether the criterion holds on large language models would show whether the k-scaling benefit survives beyond the image-classification regimes examined.
Load-bearing premise
The private warm-up phase must produce coordinate scores informative enough that the selected support retains sufficient gradient energy for the main optimization phase to succeed.
What would settle it
An experiment in which the nonconvex stationarity bound fails to improve when restricting to the warm-up-selected k coordinates, or in which the warm-up ranking reliability falls below the stated lower bound on real models.
Figures
read the original abstract
Differentially private stochastic gradient descent (DP-SGD) injects noise into every updated coordinate, making the injected noise energy scale with the ambient parameter dimension \(d\). We ask when private training can update fewer coordinates without losing the signal needed for optimization. We propose \textsc{TP-TopK} (Two-Phase TopK DP-SGD), a two-phase method for coordinate-sparse private training without public data, in which a private warm-up phase identifies a coordinate support used to guide the main training phase. We give a criterion characterizing when coordinate restriction can be beneficial, show via a nonconvex stationarity bound that under this condition the relevant noise term scales with the active dimension \(k\) rather than the full parameter dimension \(d\), and provide a lower bound on the reliability of warm-up-based coordinate ranking. Experiments on MNIST, FMNIST, and CIFAR-10 show that learned coordinate supports can retain more gradient energy than size-matched random supports, with the largest gains when the active dimension is small and warm-up scores are informative.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TP-TopK, a two-phase DP-SGD algorithm consisting of a private warm-up phase that ranks and selects a coordinate support of size k, followed by a main training phase restricted to those coordinates. It states a criterion under which coordinate restriction is beneficial, derives a non-convex stationarity bound showing that the noise term then scales with k rather than the full dimension d, supplies a lower bound on the reliability of the warm-up ranking, and reports experiments on MNIST, FMNIST, and CIFAR-10 in which learned supports retain more gradient energy than size-matched random supports, with larger gains at small k when warm-up scores are informative.
Significance. If the stationarity bound holds under the stated criterion and the warm-up lower bound is shown to guarantee sufficient retained gradient energy, the work would offer a concrete, public-data-free route to reducing the noise penalty in high-dimensional DP-SGD. The explicit criterion, the non-convex analysis, and the direct comparison of learned versus random supports are positive features; the absence of public data makes the approach relevant to settings where auxiliary data are unavailable.
major comments (2)
- [stationarity bound and reliability lower bound] The non-convex stationarity bound (abstract and the derivation referenced in the main text): the bound is stated to deliver a k-versus-d noise improvement only under the paper's criterion, yet the criterion itself presupposes that the selected support retains enough gradient energy. The supplied lower bound on warm-up ranking reliability is described only as 'partial support' for this premise; it is not shown whether the bound guarantees a (1-ε) fraction of total gradient energy with high probability, which is required for the k-scaling claim to remain load-bearing when selection error is present.
- [experiments on MNIST, FMNIST, CIFAR-10] Experimental section: results are reported without error bars, without the exact values of k tested, and without an explicit statement of the exclusion rule or energy metric used to declare that 'learned supports retain more gradient energy.' These omissions prevent assessment of whether the observed gains are statistically reliable or whether they occur in the regime where the k-versus-d benefit is theoretically predicted.
minor comments (1)
- Notation for the active dimension k and the reliability probability should be introduced once and used consistently; the abstract uses both without an explicit definition of the energy-retention threshold.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of the paper's potential contribution. We address each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [stationarity bound and reliability lower bound] The non-convex stationarity bound (abstract and the derivation referenced in the main text): the bound is stated to deliver a k-versus-d noise improvement only under the paper's criterion, yet the criterion itself presupposes that the selected support retains enough gradient energy. The supplied lower bound on warm-up ranking reliability is described only as 'partial support' for this premise; it is not shown whether the bound guarantees a (1-ε) fraction of total gradient energy with high probability, which is required for the k-scaling claim to remain load-bearing when selection error is present.
Authors: The stationarity bound is derived under an explicit criterion that the selected support must retain sufficient gradient energy for the k-scaling to hold; this is presented as a sufficient condition rather than an unconditional claim. The lower bound on warm-up reliability is offered as partial analytical support for the criterion being plausible, showing that the ranking procedure has non-trivial reliability properties, but it does not claim or prove a high-probability (1-ε) energy retention guarantee. We will revise the manuscript to more explicitly separate the criterion (under which the bound applies) from the reliability analysis and to discuss the effect of possible selection error on the noise scaling. Strengthening the reliability result to a full (1-ε) guarantee would require additional assumptions on gradient distributions that are outside the current scope. revision: partial
-
Referee: [experiments on MNIST, FMNIST, CIFAR-10] Experimental section: results are reported without error bars, without the exact values of k tested, and without an explicit statement of the exclusion rule or energy metric used to declare that 'learned supports retain more gradient energy.' These omissions prevent assessment of whether the observed gains are statistically reliable or whether they occur in the regime where the k-versus-d benefit is theoretically predicted.
Authors: We agree that the experimental reporting lacks these details. In the revised version we will add error bars computed over multiple independent runs, list the precise k values used for each dataset, and provide an explicit definition of the gradient energy metric together with any coordinate exclusion rules applied when computing retained energy. These additions will make it possible to evaluate statistical reliability and alignment with the theoretical regime. revision: yes
- The lower bound on warm-up ranking reliability does not currently guarantee retention of a (1-ε) fraction of total gradient energy with high probability; providing such a guarantee would require further assumptions or analysis not present in the manuscript.
Circularity Check
No significant circularity; derivations follow from stated criterion and standard analysis
full rationale
The paper states a criterion for when coordinate restriction benefits DP-SGD, then derives a nonconvex stationarity bound under that criterion (showing noise scaling with active dimension k) and a lower bound on warm-up ranking reliability. These follow from the criterion plus standard non-convex analysis without any reduction by the paper's own equations to fitted quantities, self-citations, or definitional tautologies. No load-bearing step renames a fit as a prediction or imports uniqueness via author self-citation; the central claims remain independent of the paper's inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- active dimension k
axioms (1)
- domain assumption There exists a small coordinate support that captures sufficient gradient energy for optimization progress
Reference graph
Works this paper leans on
-
[1]
Brendan McMahan, Ilya Mironov, Kunal Talwar, and Li Zhang
Martin Abadi, Andy Chu, Ian Goodfellow, H. Brendan McMahan, Ilya Mironov, Kunal Talwar, and Li Zhang. 2016. Deep Learning with Differential Privacy. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security. ACM, 308–318
2016
-
[2]
Kamil Adamczewski, Yingchen He, and Mijung Park. 2023. Pre-Pruning and Gradient-Dropping Improve Differentially Private Image Classification.arXiv preprint arXiv:2306.11754(2023)
arXiv 2023
-
[3]
Brendan McMahan, and Swaroop Ramaswamy
Galen Andrew, Om Thakkar, H. Brendan McMahan, and Swaroop Ramaswamy
-
[4]
InAdvances in Neural Information Processing Systems, Vol
Differentially Private Learning with Adaptive Clipping. InAdvances in Neural Information Processing Systems, Vol. 34. 17455–17466
-
[5]
Raef Bassily, Vitaly Feldman, Kunal Talwar, and Abhradeep Guha Thakurta. 2019. Private Stochastic Convex Optimization with Optimal Rates. InAdvances in Neural Information Processing Systems, Vol. 32. 11282–11291
2019
-
[6]
Raef Bassily, Adam Smith, and Abhradeep Thakurta. 2014. Private Empirical Risk Minimization: Efficient Algorithms and Tight Error Bounds. InProceedings of the 2014 IEEE 55th Annual Symposium on Foundations of Computer Science. IEEE Computer Society, 464–473
2014
-
[7]
Philipp Benz et al. 2023. Equivariant Differentially Private Deep Learning: Why DP-SGD Needs Sparser Models.arXiv preprint arXiv:2301.13104(2023)
arXiv 2023
-
[8]
Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language Models are Few-Shot Learners.Advances in Neural Information Processing Systems33 (2020), 1877–1901
2020
-
[9]
Zhiqi Bu, Yu-Xiang Wang, Sheng Zha, and George Karypis. 2023. Au- tomatic Clipping: Differentially Private Deep Learning Made Easier and Stronger. InAdvances in Neural Information Processing Systems, Vol. 36. 41727–41764. https://proceedings.neurips.cc/paper_files/paper/2023/hash/ 8249b30d877c91611fd8c7aa6ac2b5fe-Abstract-Conference.html
2023
-
[10]
Nicholas Carlini, Steve Chien, Milad Nasr, Shuang Song, Andreas Terzis, and Florian Tramèr. 2022. Membership Inference Attacks From First Principles. In 2022 IEEE Symposium on Security and Privacy (SP). 1897–1914
2022
-
[11]
Lin Chen, Xiaofeng Ding, Mengqi Li, and Hai Jin. 2023. Differentially private fed- erated learning with importance client sampling.IEEE Transactions on Consumer Electronics70, 1 (2023), 3635–3649. When Do Fewer Coordinates Suffice in DP-SGD?
2023
-
[12]
Mia Xu Chen, Benjamin N Lee, Gagan Bansal, Yuan Cao, Shuyuan Zhang, Justin Lu, Jackie Tsay, Yinan Wang, Andrew M Dai, Zhifeng Chen, et al. 2019. Gmail smart compose: Real-time assisted writing. InProceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2287– 2295
2019
-
[13]
Christopher Choquette-Choo, Arun Ganesh, Saminul Haque, Thomas Steinke, and Abhradeep Guha Thakurta. 2025. Near-Exact Privacy Amplification for Matrix Mechanisms. InInternational Conference on Learning Representations. 98772–98802
2025
-
[14]
Choquette-Choo, Arun Ganesh, Ryan McKenna, H
Christopher A. Choquette-Choo, Arun Ganesh, Ryan McKenna, H. Brendan McMahan, John Rush, Abhradeep Guha Thakurta, and Zheng Xu. 2023. (Ampli- fied) Banded Matrix Factorization: A Unified Approach to Private Training. In Advances in Neural Information Processing Systems, Vol. 36. 74856–74889
2023
-
[15]
Smith, and Borja Balle
Soham De, Leonard Berrada, Jamie Hayes, Samuel L. Smith, and Borja Balle. 2022. Unlocking High-Accuracy Differentially Private Image Classification through Scale. InProceedings of the 39th International Conference on Machine Learning (Proceedings of Machine Learning Research), Vol. 162. PMLR, 4815–4827
2022
-
[16]
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xi- aohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. 2021. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale.International Conference on Learning Representations (ICLR)(2021)
2021
-
[17]
Cynthia Dwork. 2006. Differential Privacy. InAutomata, Languages and Pro- gramming (Lecture Notes in Computer Science), Vol. 4052. Springer, 1–12
2006
-
[18]
Cynthia Dwork and Aaron Roth. 2014. The Algorithmic Foundations of Differ- ential Privacy.Foundations and Trends in Theoretical Computer Science9, 3–4 (2014), 211–407
2014
-
[19]
Jie Fu, Zhili Chen, and XinPeng Ling. 2022. SA-DPSGD: Differentially Private Stochastic Gradient Descent based on Simulated Annealing.arXiv preprint arXiv:2211.07218(2022). arXiv:2211.07218 https://arxiv.org/abs/2211.07218
arXiv 2022
-
[20]
Saeed Ghadimi and Guanghui Lan. 2013. Stochastic First- and Zeroth-Order Methods for Nonconvex Stochastic Programming.SIAM Journal on Optimization 23, 4 (2013), 2341–2368
2013
-
[21]
Badih Ghazi, Yangsibo Huang, Pritish Kamath, Ravi Kumar, Pasin Manurangsi, Amer Sinha, and Chiyuan Zhang. 2023. Sparsity-Preserving Differentially Pri- vate Training of Large Embedding Models. InAdvances in Neural Information Processing Systems, Vol. 36. 10951–10971
2023
-
[22]
Sivakanth Gopi, Yin Tat Lee, and Lukas Wutschitz. 2021. Numerical Composition of Differential Privacy. InAdvances in Neural Information Processing Systems, Vol. 34. 11631–11642
2021
-
[23]
Shlomi Hod, Lucas Rosenblatt, and Julia Stoyanovich. 2025. Do You Really Need Public Data? Surrogate Public Data for Differential Privacy on Tabular Data. arXiv preprint arXiv:2504.14368(2025)
arXiv 2025
-
[24]
Yu, and Xuyun Zhang
Hongsheng Hu, Zoran Salcic, Lichao Sun, Gillian Dobbie, Philip S. Yu, and Xuyun Zhang. 2022. Membership Inference Attacks on Machine Learning: A Survey. Comput. Surveys54, 11s (2022), 1–37
2022
-
[25]
Kaggle / EyePACS. 2015. EyePACS Diabetic Retinopathy Detection Dataset. https://www.kaggle.com/c/diabetic-retinopathy-detection
2015
-
[26]
Peter Kairouz, Brendan McMahan, Shuang Song, Om Thakkar, Abhradeep Thakurta, and Zheng Xu. 2021. Practical and Private (Deep) Learning with- out Sampling or Shuffling. InInternational Conference on Machine Learning (Proceedings of Machine Learning Research), Vol. 139. PMLR, 5213–5225
2021
-
[27]
Anastasia Koloskova, Hadrien Hendrikx, and Sebastian U. Stich. 2023. Revisit- ing Gradient Clipping: Stochastic Bias and Tight Convergence Guarantees. In International Conference on Machine Learning (Proceedings of Machine Learning Research), Vol. 202. PMLR, 17343–17363
2023
-
[28]
Yixuan Liu, Li Xiong, Yuhan Liu, Yujie Gu, Ruixuan Liu, and Hong Chen. 2024. DPDR: Gradient Decomposition and Reconstruction for Differentially Private Deep Learning.arXiv preprint arXiv:2406.02744(2024). arXiv:2406.02744 https: //arxiv.org/abs/2406.02744
arXiv 2024
-
[29]
Linyuan Lü, Matúš Medo, Chi Ho Yeung, Yi-Cheng Zhang, Zi-Ke Zhang, and Tao Zhou. 2012. Recommender systems.Physics reports519, 1 (2012), 1–49
2012
-
[30]
Alexander Selvikvåg Lundervold and Arvid Lundervold. 2019. An overview of deep learning in medical imaging focusing on MRI.Zeitschrift fuer medizinische Physik29, 2 (2019), 102–127
2019
-
[31]
Mehdi Makni, Kayhan Behdin, Gabriel Afriat, Zheng Xu, Sergei Vassilvitskii, Natalia Ponomareva, Rahul Mazumder, and Hussein Hazimeh. 2025. SPARTA: An Optimization Framework for Differentially Private Sparse Fine-Tuning. In Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining. ACM, 2090–2101
2025
-
[32]
Ilya Mironov. 2017. Rényi Differential Privacy. InProceedings of the 2017 IEEE 30th Computer Security Foundations Symposium. IEEE Computer Society, 263–275
2017
-
[33]
Marziyeh Mohammadi, Mohsen Vejdanihemmat, Mahshad Lotfinia, Mirabela Rusu, Daniel Truhn, Andreas Maier, and Soroosh Tayebi Arasteh. 2026. Differ- ential privacy for medical deep learning: methods, tradeoffs, and deployment implications.npj Digital Medicine9 (2026), 93
2026
-
[34]
Sabrina Mokhtari, Sara Kodeiri, Shubhankar Mohapatra, Florian Tramèr, and Gautam Kamath. 2026. Rethinking Benchmarks for Differentially Private Image Classification.arXiv preprint arXiv:2601.17189(2026)
arXiv 2026
-
[35]
Fahad Shamshad, Salman Khan, Syed Waqas Zamir, Muhammad Haris Khan, Munawar Hayat, Fahad Shahbaz Khan, and Huazhu Fu. 2023. Transformers in medical imaging: A survey.Medical Image Analysis88 (2023), 102802
2023
-
[36]
Reza Shokri and Vitaly Shmatikov. 2015. Privacy-preserving deep learning. In Proceedings of the 22nd ACM SIGSAC conference on computer and communications security. 1310–1321
2015
-
[37]
Reza Shokri, Marco Stronati, Congzheng Song, and Vitaly Shmatikov. 2017. Membership inference attacks against machine learning models. In2017 IEEE symposium on security and privacy. 3–18
2017
-
[38]
Shuang Song, Kamalika Chaudhuri, and Anand D. Sarwate. 2013. Stochastic Gra- dient Descent with Differentially Private Updates. In2013 IEEE Global Conference on Signal and Information Processing. IEEE, 245–248
2013
-
[39]
Florian Tramèr, Gautam Kamath, and Nicholas Carlini. 2024. Position: Consider- ations for Differentially Private Learning with Large-Scale Public Pretraining. InProceedings of the 41st International Conference on Machine Learning. PMLR, 48453–48467
2024
-
[40]
Yu-Xiang Wang, Borja Balle, and Shiva Prasad Kasiviswanathan. 2019. Sub- sampled Rényi Differential Privacy and Analytical Moments Accountant. In Proceedings of the Twenty-Second International Conference on Artificial Intelli- gence and Statistics (Proceedings of Machine Learning Research), Vol. 89. PMLR, 1226–1235. https://proceedings.mlr.press/v89/wang19b.html
2019
-
[41]
Likang Wu, Zhi Zheng, Zhaopeng Qiu, Hao Wang, Hongchao Gu, Tingjia Shen, Chuan Qin, Chen Zhu, Hengshu Zhu, Qi Liu, Hui Xiong, and Enhong Chen. 2024. A Survey on Large Language Models for Recommendation.World Wide Web (2024)
2024
-
[42]
Alvarez, Jan Kautz, and Pavlo Molchanov
Hongxu Yin, Arun Mallya, Arash Vahdat, Jose M. Alvarez, Jan Kautz, and Pavlo Molchanov. 2021. See Through Gradients: Image Batch Recovery via GradInver- sion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 16337–16346
2021
-
[43]
Da Yu, Huishuai Zhang, Wei Chen, and Tie-Yan Liu. 2021. Do Not Let Privacy Overbill Utility: Gradient Embedding Perturbation for Private Learning. InInter- national Conference on Learning Representations. https://openreview.net/forum? id=7aogOj_VYO0
2021
-
[44]
Da Yu, Huishuai Zhang, Wei Chen, Jian Yin, and Tie-Yan Liu. 2021. Large Scale Private Learning via Low-Rank Reparametrization. InProceedings of the 38th International Conference on Machine Learning (Proceedings of Machine Learning Research), Vol. 139. PMLR, 12208–12218. https://proceedings.mlr.press/v139/ yu21f.html
2021
-
[45]
Xinwei Zhang, Zhiqi Bu, Borja Balle, Mingyi Hong, Meisam Razaviyayn, and Vahab Mirrokni. 2025. DiSK: Differentially Private Optimizer with Simplified Kalman Filter for Noise Reduction. InInternational Conference on Learning Rep- resentations. https://openreview.net/forum?id=Lfy9q7Icp9
2025
-
[46]
Xinwei Zhang, Zhiqi Bu, Mingyi Hong, and Meisam Razaviyayn. 2024. DOPPLER: Differentially Private Optimizers with Low-Pass Filter for Privacy Noise Reduction. InAdvances in Neural Information Processing Systems, Vol. 37. 41826–41851. https://proceedings.neurips.cc/paper_files/paper/2024/hash/ 49c466ccc038f39b08b1980a2b06673c-Abstract-Conference.html
2024
-
[47]
Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, et al. 2026. A Survey of Large Language Models.Frontiers of Computer Science20, 12 (2026), 2012627. https://doi.org/10.1007/s11704-026-60308-3
-
[48]
S Kevin Zhou, Hayit Greenspan, Christos Davatzikos, James S Duncan, Bram Van Ginneken, Anant Madabhushi, Jerry L Prince, Daniel Rueckert, and Ronald M Summers. 2021. A review of deep learning in medical imaging: Imaging traits, technology trends, case studies with progress highlights, and future promises. Proc. IEEE109, 5 (2021), 820–838
2021
-
[49]
Yingxue Zhou, Zhiwei Steven Wu, and Arindam Banerjee. 2021. Bypassing the Ambient Dimension: Private SGD with Gradient Subspace Identification. In International Conference on Learning Representations. https://openreview.net/ forum?id=7dpmlkBuJFC
2021
-
[50]
Blaschko
Junyi Zhu and Matthew B. Blaschko. 2023. Improving Differentially Private SGD via Randomly Sparsified Gradients.Transactions on Machine Learning Research (2023). https://openreview.net/forum?id=sY35BAiIf4
2023
-
[51]
Ligeng Zhu, Zhijian Liu, and Song Han. 2019. Deep leakage from gradients. Advances in neural information processing systems32 (2019)
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.