REVIEW 2 major objections 2 minor 1 cited by
TriAxialKV matches full-precision accuracy on agentic tasks while allowing 4.5 times larger KV cache and 30 percent higher throughput by tagging tokens along three axes.
Reviewed by Pith at T0; open to challenge. T0 means a machine referee read the full paper against a public rubric. the ladder, T0–T4 →
T0 review · grok-4.3
2026-05-20 14:27 UTC pith:VGB44FRF
load-bearing objection TriAxialKV tags KV tokens on temporal, modality, and role axes to pick INT2/INT4 widths per combo, claiming to match BF16 accuracy on an OSWorld agent run while cutting cache size and raising throughput. the 2 major comments →
TriAxialKV: Toward Extreme Low-Precision KV-Cache Quantization for Agentic Inference Tasks
The pith
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
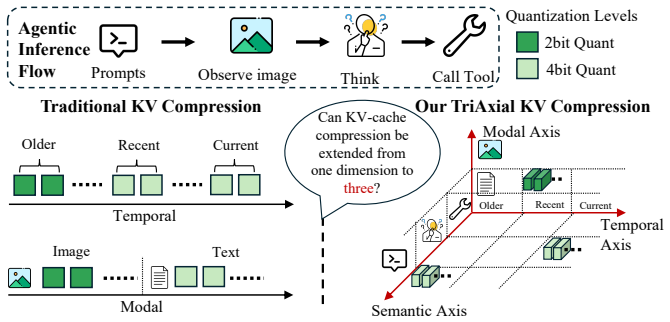
TriAxialKV is a mixed-precision KV-cache quantization scheme that assigns each token a triaxial tag based on temporal recency, modality, and semantic role, calibrates per-tag sensitivity, and allocates INT2 or INT4 bitwidths under a fixed memory budget, achieving the same accuracy as BF16 KV cache while supporting 4.5 times larger cache size and 30 percent higher end-to-end throughput on agentic inference workloads.
What carries the argument
The triaxial tag that combines temporal recency, modality, and semantic role to select a per-token quantization bit width after per-tag calibration.
Load-bearing premise
The three axes of temporal recency, modality, and semantic role capture the dominant sources of token-level sensitivity to quantization across agentic workloads.
What would settle it
A measurable drop in OSWorld task success rate when the same Qwen3-VL-32B-Thinking agent runs with the TriAxialKV cache instead of BF16 on identical prompts and environment states.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces TriAxialKV, a mixed-precision KV-cache quantization scheme for agentic LLM inference. Tokens receive triaxial tags along temporal recency, modality, and semantic role; per-tag sensitivity is calibrated to assign INT2/INT4 bit-widths under a fixed memory budget. The end-to-end system includes calibration, quantization, memory management, and custom fused Triton decode kernels. On the OSWorld benchmark with Qwen3-VL-32B-Thinking as a computer-use agent, the method is reported to match SGLang BF16 accuracy while supporting 4.5× KV-cache size and 30% higher end-to-end throughput.
Significance. If the empirical results hold under rigorous validation, the triaxial tagging approach could meaningfully advance efficient inference for long-context multimodal multi-turn agentic workloads by exploiting structured token heterogeneity. The complete serving-system implementation with optimized kernels is a concrete strength that aids reproducibility and deployment.
major comments (2)
- [Abstract] Abstract: the central claim that TriAxialKV matches BF16 accuracy on OSWorld is presented without any description of the calibration procedure, ablation of the three axes, error-bar reporting, or justification for the post-hoc tag definitions. These omissions are load-bearing for assessing whether the reported accuracy match is robust rather than an artifact of a particular calibration choice.
- [Method] Method (triaxial tagging and bit-width allocation): the premise that a single bit-width per tag combination suffices for all tokens sharing that tag is load-bearing for both the memory-reduction and accuracy claims, yet no measurement or bound on intra-tag variance in token sensitivity is reported. Outliers within a bucket such as 'recent image observation' or 'tool-call reasoning' could still accumulate errors across multi-turn interactions.
minor comments (2)
- [Abstract] The abstract would be clearer if it stated the concrete bit-width distribution or the exact memory budget used in the 4.5× scaling experiment.
- [Experiments] Figure or table captions should explicitly define the triaxial tag combinations and the sensitivity metric used for calibration.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We have addressed each major comment below and revised the manuscript accordingly to strengthen the presentation of our calibration details, ablations, and analysis of token sensitivity.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that TriAxialKV matches BF16 accuracy on OSWorld is presented without any description of the calibration procedure, ablation of the three axes, error-bar reporting, or justification for the post-hoc tag definitions. These omissions are load-bearing for assessing whether the reported accuracy match is robust rather than an artifact of a particular calibration choice.
Authors: We agree that the abstract would benefit from additional context to support the central accuracy claim. In the revised manuscript we have expanded the abstract with a brief description of the per-tag calibration procedure and noted that full ablations of the three axes appear in Section 4.3. We also report error bars computed over three independent runs and provide justification for the tag definitions in Section 3.1, which are derived from empirical sensitivity measurements on representative agentic traces. These additions clarify that the reported accuracy match is supported by systematic calibration rather than a single ad-hoc choice. revision: yes
-
Referee: [Method] Method (triaxial tagging and bit-width allocation): the premise that a single bit-width per tag combination suffices for all tokens sharing that tag is load-bearing for both the memory-reduction and accuracy claims, yet no measurement or bound on intra-tag variance in token sensitivity is reported. Outliers within a bucket such as 'recent image observation' or 'tool-call reasoning' could still accumulate errors across multi-turn interactions.
Authors: We acknowledge the importance of quantifying intra-tag variance. Our calibration procedure assigns bit-widths according to the highest observed sensitivity within each tag combination, which provides a conservative bound that protects against outliers. In the revised manuscript we have added a new subsection (3.3) that reports measured intra-tag variance across OSWorld traces; the variance is modest for the majority of tags, and the conservative allocation prevents noticeable error accumulation, as confirmed by the sustained accuracy over extended multi-turn agent trajectories in our end-to-end experiments. revision: yes
Circularity Check
No significant circularity; results presented as empirical measurements
full rationale
The paper introduces TriAxialKV via triaxial tagging and per-tag calibration of sensitivity to allocate mixed INT2/INT4 precision under a memory budget, then reports measured accuracy matching BF16 KV cache and 30% higher throughput on the OSWorld benchmark with Qwen3-VL-32B-Thinking. These outcomes are framed as direct experimental results from the implemented serving system rather than any derived prediction that reduces tautologically to the calibration inputs. No equations, fitted quantities renamed as predictions, or load-bearing self-citations appear in the provided description to create circularity. The method is self-contained against the external OSWorld benchmark.
Axiom & Free-Parameter Ledger
free parameters (1)
- per-tag sensitivity thresholds
axioms (1)
- domain assumption Tokens sharing the same triaxial tag exhibit sufficiently similar sensitivity to low-precision storage that a uniform bit-width per tag is safe.
invented entities (1)
-
triaxial tag
no independent evidence
read the original abstract
Agentic workloads have emerged as a major workload for LLM inference. They differ significantly from chat-only workloads, requiring long-context processing, the ability to handle multimodal inputs, and structured multi-turn interactions with tool calling capabilities. As a result, their context exhibits structure that can carry different importance along three key axes: temporal recency to the current turn, modality such as text or image tokens, and semantic role such as user queries, tool calls, observations, or reasoning. These axes capture distinct token behaviors and lead to different sensitivities to KV-cache compression. However, existing KV-cache quantization methods are typically homogeneous or exploit only heterogeneity on a single dimension, such as temporal proximity or modality, overlooking the interactions among them. To this end, we introduce TriAxialKV, a novel mixed-precision KV-cache quantization scheme that assigns each token a triaxial tag, calibrates per-tag sensitivity, and allocates INT2/INT4 bitwidths under a fixed memory budget. We implement TriAxialKV as an end-to-end serving system, comprising calibration, mixed-precision quantization and memory management, and custom fused Triton decode kernels. When using Qwen3-VL-32B-Thinking as a computer-use agent operating the OSWorld, TriAxialKV matches the accuracy of SGLang with BF16 KV cache while supporting 4.5$\times$ KV cache size and achieving 30% higher end-to-end throughput, when running on real GPU systems.
Figures




Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
three key axes: temporal recency to the current turn, modality such as text or image tokens, and semantic role such as user queries, tool calls, observations, or reasoning. These axes capture distinct token behaviors
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
calibrates per-tag sensitivity, and allocates INT2/INT4 bitwidths under a fixed memory budget
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Seen, Said, or Forgotten? A Causal Audit of Visual KV Memory Across Dialog Turns
Current attention is not a safe-forgetting signal for visual KV memory; damage from eviction concentrates in visually dependent turns, and only explicitly verbalized facts are reliably rescued by assistant text.
Reference graph
Works this paper leans on
-
[1]
OSWorld-Human: Benchmarking the efficiency of computer-use agents
Reyna Abhyankar, Qi Qi, and Yiying Zhang. OSWorld-Human: Benchmarking the efficiency of computer-use agents. InICML Workshop on Computer Use Agents, 2025
work page 2025
-
[2]
Agent s2: A compositional generalist-specialist framework for computer use agents
Saaket Agashe, Kyle Wong, Vincent Tu, Jiachen Yang, Ang Li, and Xin Eric Wang. Agent s2: A compositional generalist-specialist framework for computer use agents. InCOLM, 2025
work page 2025
-
[3]
Taming throughput-latency tradeoff in llm inference with sarathi-serve
Amey Agrawal, Nitin Kedia, Ashish Panwar, Jayashree Mohan, Nipun Kwatra, Bhargav Gula- vani, Alexey Tumanov, and Ramachandran Ramjee. Taming throughput-latency tradeoff in llm inference with sarathi-serve. InOSDI, 2024
work page 2024
-
[4]
Croci, Bo Li, Pashmina Cameron, Martin Jaggi, Dan Alistarh, Torsten Hoefler, and James Hensman
Saleh Ashkboos, Amirkeivan Mohtashami, Maximilian L. Croci, Bo Li, Pashmina Cameron, Martin Jaggi, Dan Alistarh, Torsten Hoefler, and James Hensman. Quarot: Outlier-free 4-bit inference in rotated LLMs. InNeurIPS, 2024
work page 2024
-
[5]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
arXiv preprint arXiv:2308.04624 , year=
Debarag Banerjee, Pooja Singh, Arjun Avadhanam, and Saksham Srivastava. Benchmarking llm-powered chatbots: Methods and metrics.arXiv preprint arXiv:2308.04624, 2023
-
[7]
Don't Waste Bits! Adaptive KV-Cache Quantization for Lightweight On-Device LLMs
Sayed Pedram Haeri Boroujeni, Niloufar Mehrabi, Patrick Woods, Gabriel Hillesheim, and Abolfazl Razi. Don’t waste bits! adaptive KV-cache quantization for lightweight on-device llms.arXiv preprint arXiv:2604.04722, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[8]
Pyramidkv: Dynamic kv cache compression based on pyramidal information funneling
Zefan Cai, Yichi Zhang, Bofei Gao, Yuliang Liu, Yucheng Li, Tianyu Liu, Keming Lu, Wayne Xiong, Yue Dong, Junjie Hu, et al. Pyramidkv: Dynamic kv cache compression based on pyramidal information funneling. InCOLM, 2025
work page 2025
-
[9]
Web agents with world models: Learning and leveraging environment dynamics in web navigation
Hyungjoo Chae, Namyoung Kim, Kai Tzu-iunn Ong, Minju Gwak, Gwanwoo Song, Jihoon Kim, Sunghwan Kim, Dongha Lee, and Jinyoung Yeo. Web agents with world models: Learning and leveraging environment dynamics in web navigation. InICLR, 2025
work page 2025
-
[10]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[11]
FlashAttention-2: Faster attention with better parallelism and work partitioning
Tri Dao. FlashAttention-2: Faster attention with better parallelism and work partitioning. In ICLR, 2024
work page 2024
-
[12]
Fu, Stefano Ermon, Atri Rudra, and Christopher Ré
Tri Dao, Daniel Y . Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. FlashAttention: Fast and memory-efficient exact attention with IO-awareness. InNeurIPS, 2022
work page 2022
-
[13]
Liminal: Exploring the frontiers of llm decode performance.arXiv preprint arXiv:2507.14397, 2025
Michael Davies, Neal Crago, Karthikeyan Sankaralingam, and Christos Kozyrakis. Liminal: Exploring the frontiers of llm decode performance.arXiv preprint arXiv:2507.14397, 2025
-
[14]
The falcon 3 family of open models, 2024
Falcon-LLM Team. The falcon 3 family of open models, 2024
work page 2024
-
[15]
Ada-kv: Optimizing kv cache eviction by adaptive budget allocation for efficient llm inference
Yuan Feng, Junlin Lv, Yukun Cao, Xike Xie, and S Kevin Zhou. Ada-kv: Optimizing kv cache eviction by adaptive budget allocation for efficient llm inference. InNeurIPS, 2025
work page 2025
-
[16]
Model tells you what to discard: Adaptive kv cache compression for llms
Suyu Ge, Yunan Zhang, Liyuan Liu, Minjia Zhang, Jiawei Han, and Jianfeng Gao. Model tells you what to discard: Adaptive kv cache compression for llms. InICLR, 2024. 10
work page 2024
-
[17]
Webvoyager: Building an end-to-end web agent with large multimodal models
Hongliang He, Wenlin Yao, Kaixin Ma, Wenhao Yu, Yong Dai, Hongming Zhang, Zhenzhong Lan, and Dong Yu. Webvoyager: Building an end-to-end web agent with large multimodal models. InACL, 2024
work page 2024
-
[18]
Zipcache: Accurate and efficient kv cache quantization with salient token identification
Yefei He, Luoming Zhang, Weijia Wu, Jing Liu, Hong Zhou, and Bohan Zhuang. Zipcache: Accurate and efficient kv cache quantization with salient token identification. InNeurIPS, 2024
work page 2024
-
[19]
Kvquant: Towards 10 million context length llm inference with kv cache quantization
Coleman Hooper, Sehoon Kim, Hiva Mohammadzadeh, Michael W Mahoney, Yakun S Shao, Kurt Keutzer, and Amir Gholami. Kvquant: Towards 10 million context length llm inference with kv cache quantization. InNeurIPS, 2024
work page 2024
-
[20]
SAW-INT4: System-Aware 4-Bit KV-Cache Quantization for Real-World LLM Serving
Jinda Jia, Jisen Li, Zhongzhu Zhou, Jung Hwan Heo, Jue Wang, Tri Dao, Shuaiwen Leon Song, Ben Athiwaratkun, Chenfeng Xu, Tianyi Zhang, and Xiaoxia Wu. Saw-int4: System-aware 4-bit kv-cache quantization for real-world llm serving.arXiv preprint arXiv:2604.19157, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
Efficient memory management for large language model serving with pagedattention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. InSOSP, 2023
work page 2023
-
[22]
Snapkv: Llm knows what you are looking for before generation
Yuhong Li, Yingbing Huang, Bowen Yang, Bharat Venkitesh, Acyr Locatelli, Hanchen Ye, Tianle Cai, Patrick Lewis, and Deming Chen. Snapkv: Llm knows what you are looking for before generation. InNeurIPS, 2024
work page 2024
-
[23]
Channel-aware mixed-precision quantization for efficient long- context inference
Chengxi Liao and Zeyi Wen. Channel-aware mixed-precision quantization for efficient long- context inference. InICLR, 2026
work page 2026
-
[24]
Qserve: W4a8kv4 quantization and system co-design for efficient llm serving
Yujun Lin, Haotian Tang, Shang Yang, Zhekai Zhang, Guangxuan Xiao, Chuang Gan, and Song Han. Qserve: W4a8kv4 quantization and system co-design for efficient llm serving. InMLSys, 2025
work page 2025
-
[25]
PM-KVQ: Progressive mixed-precision KV cache quantization for long-cot LLMs
Tengxuan Liu, Shiyao Li, Jiayi Yang, Tianchen Zhao, Feng Zhou, Xiaohui Song, Guohao Dai, Shengen Yan, Huazhong Yang, and Yu Wang. PM-KVQ: Progressive mixed-precision KV cache quantization for long-cot LLMs. InICLR, 2026
work page 2026
-
[26]
Kivi: A tuning-free asymmetric 2bit quantization for kv cache
Zirui Liu, Jiayi Yuan, Hongye Jin, Shaochen Zhong, Zhaozhuo Xu, Vladimir Braverman, Beidi Chen, and Xia Hu. Kivi: A tuning-free asymmetric 2bit quantization for kv cache. InICML, 2024
work page 2024
-
[27]
KernelCraft: Benchmarking for Agentic Close-to-Metal Kernel Generation on Emerging Hardware
Jiayi Nie, Haoran Wu, Yao Lai, Zeyu Cao, Cheng Zhang, Binglei Lou, Erwei Wang, Jianyi Cheng, Timothy M. Jones, Robert Mullins, Rika Antonova, and Yiren Zhao. Kernelcraft: Benchmarking for agentic close-to-metal kernel generation on emerging hardware.arXiv preprint arXiv:2603.08721, 2026
work page internal anchor Pith review arXiv 2026
-
[28]
Splitwise: Efficient generative llm inference using phase splitting
Pratyush Patel, Esha Choukse, Chaojie Zhang, Aashaka Shah, Íñigo Goiri, Saeed Maleki, and Ricardo Bianchini. Splitwise: Efficient generative llm inference using phase splitting. InISCA, 2024
work page 2024
-
[29]
Patil, Huanzhi Mao, Charlie Cheng-Jie Ji, Fanjia Yan, Vishnu Suresh, Ion Stoica, and Joseph E
Shishir G. Patil, Huanzhi Mao, Charlie Cheng-Jie Ji, Fanjia Yan, Vishnu Suresh, Ion Stoica, and Joseph E. Gonzalez. The berkeley function calling leaderboard (bfcl): From tool use to agentic evaluation of large language models. InICML, 2025
work page 2025
-
[30]
Ruoyu Qin, Zheming Li, Weiran He, Jialei Cui, Feng Ren, Mingxing Zhang, Yongwei Wu, Weimin Zheng, and Xinran Xu. Mooncake: Trading more storage for less computation — a KVCache-centric architecture for serving LLM chatbot. InFAST, 2025
work page 2025
-
[31]
Thinkv: Thought-adaptive kv cache compression for efficient reasoning models
Akshat Ramachandran, Marina Neseem, Charbel Sakr, Rangharajan Venkatesan, Brucek Khailany, and Tushar Krishna. Thinkv: Thought-adaptive kv cache compression for efficient reasoning models. InICLR, 2026
work page 2026
-
[32]
Longcodebench: Evaluating coding LLMs at 1m context windows
Stefano Rando, Luca Romani, Alessio Sampieri, Luca Franco, John Yang, Yuta Kyuragi, Fabio Galasso, and Tatsunori Hashimoto. Longcodebench: Evaluating coding LLMs at 1m context windows. InCOLM, 2025. 11
work page 2025
-
[33]
Flashattention-3: Fast and accurate attention with asynchrony and low-precision
Jay Shah, Ganesh Bikshandi, Ying Zhang, Vijay Thakkar, Pradeep Ramani, and Tri Dao. Flashattention-3: Fast and accurate attention with asynchrony and low-precision. InNeurIPS, 2024
work page 2024
-
[34]
Qian Tao, Wenyuan Yu, and Jingren Zhou. AsymKV: Enabling 1-bit quantization of KV cache with layer-wise asymmetric quantization configurations. InCOLING, 2025
work page 2025
-
[35]
Triton: an intermediate language and compiler for tiled neural network computations
Philippe Tillet and David Cox. Triton: an intermediate language and compiler for tiled neural network computations. InProceedings of the 3rd ACM SIGPLAN International Workshop on Machine Learning and Programming Languages, 2019
work page 2019
-
[36]
Dezhan Tu, Danylo Vashchilenko, Yuzhe Lu, and Panpan Xu. VL-cache: Sparsity and modality- aware KV cache compression for vision-language model inference acceleration. InICLR, 2025
work page 2025
-
[37]
LOOK-M: Look-once optimization in KV cache for efficient multimodal long-context inference
Zhongwei Wan, Ziang Wu, Che Liu, Jinfa Huang, Zhihong Zhu, Peng Jin, Longyue Wang, and Li Yuan. LOOK-M: Look-once optimization in KV cache for efficient multimodal long-context inference. InFindings of EMNLP, 2024
work page 2024
-
[38]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3.5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Haoran Wu, Can Xiao, Jiayi Nie, Xuan Guo, Binglei Lou, Jeffrey T. H. Wong, Zhiwen Mo, Cheng Zhang, Przemyslaw Forys, Chengyang Ai, Timi Adeniran, Wayne Luk, Hongxiang Fan, Jianyi Cheng, Timothy M. Jones, Rika Antonova, Robert Mullins, and Aaron Zhao. Combating the memory walls: Optimization pathways for long-context agentic llm inference.arXiv preprint ar...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[40]
Efficient streaming language models with attention sinks
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks. InICLR, 2024
work page 2024
-
[41]
Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh Jing Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, Yitao Liu, Yiheng Xu, Shuyan Zhou, Silvio Savarese, Caiming Xiong, Victor Zhong, and Tao Yu. Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments. InNeurIPS, 2024
work page 2024
-
[42]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Flashinfer: Efficient and customizable attention engine for llm inference serving.MLSys, 2025
Zihao Ye, Lequn Chen, Ruihang Lai, Wuwei Lin, Yineng Zhang, Stephanie Wang, Tianqi Chen, Baris Kasikci, Vinod Grover, Arvind Krishnamurthy, et al. Flashinfer: Efficient and customizable attention engine for llm inference serving.MLSys, 2025
work page 2025
-
[44]
Orca: A distributed serving system for transformer-based generative models
Gyeong-In Yu, Joo Seong Jeong, Geon-Woo Kim, Soojeong Kim, and Byung-Gon Chun. Orca: A distributed serving system for transformer-based generative models. InOSDI, 2022
work page 2022
-
[45]
Flashattention-4: Algorithm and kernel pipelining co-design for asymmetric hardware scaling
Ted Zadouri, Markus Hoehnerbach, Jay Shah, Timmy Liu, Vijay Thakkar, and Tri Dao. Flashattention-4: Algorithm and kernel pipelining co-design for asymmetric hardware scaling. InMLSys, 2026
work page 2026
-
[46]
MR-GSM8K: A meta-reasoning benchmark for large language model evaluation
Zhongshen Zeng, Pengguang Chen, Shu Liu, Haiyun Jiang, and Jiaya Jia. MR-GSM8K: A meta-reasoning benchmark for large language model evaluation. InICLR, 2025
work page 2025
-
[47]
H2o: Heavy-hitter oracle for efficient generative inference of large language models
Zhenyu Zhang, Ying Sheng, Tianyi Zhou, Tianlong Chen, Lianmin Zheng, Ruisi Cai, Zhao Song, Yuandong Tian, Christopher Ré, Clark Barrett, et al. H2o: Heavy-hitter oracle for efficient generative inference of large language models. InNeurIPS, 2023
work page 2023
-
[48]
Smallkv: Small model assisted compensation of kv cache compression for efficient llm inference
Yi Zhao, Yajuan Peng, Nguyen Cam-Tu, Zuchao Li, Wang Xiaoliang, Xiaoming Fu, et al. Smallkv: Small model assisted compensation of kv cache compression for efficient llm inference. InNeurIPS, 2025. 12
work page 2025
-
[49]
Sglang: Efficient execution of structured language model programs
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Livia Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E Gonzalez, et al. Sglang: Efficient execution of structured language model programs. InNeurIPS, 2024
work page 2024
-
[50]
Distserve: Disaggregating prefill and decoding for goodput-optimized large language model serving
Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xuanzhe Liu, Xin Jin, and Hao Zhang. Distserve: Disaggregating prefill and decoding for goodput-optimized large language model serving. InOSDI, 2024. 13 A Greedy Bitwidth Allocation Algorithm 1Semantic-aware bit allocation Require:Tag setS; counts{N s}; distortions{D s(2), Ds(4)}; budgetB. Ensure...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.