Fast and Parallel High-Rate STAR Architecture for Megaquop Quantum Simulation
Pith reviewed 2026-06-25 23:45 UTC · model grok-4.3
The pith
High-rate bicycle chain codes enable a 5.5-fold qubit reduction for fault-tolerant lattice simulation on neutral atoms.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A symmetry-driven co-design of algorithm, bicycle-chain quantum error-correcting code, and neutral-atom hardware yields a high-rate STAR architecture in which translation symmetries of the target lattice select self-dual bivariate bicycle codes that natively realize the Clifford gates needed for lattice simulation; disjoint logical representatives then permit parallel STAR injections on all k logical qubits, amortizing preparation cost and enabling practical post-selection while compiling logical operations to low-depth acousto-optic-deflector shifts.
What carries the argument
Bivariate bicycle chain codes selected by lattice translation symmetries, which natively implement Clifford gates and support parallel disjoint-representative STAR injections.
If this is right
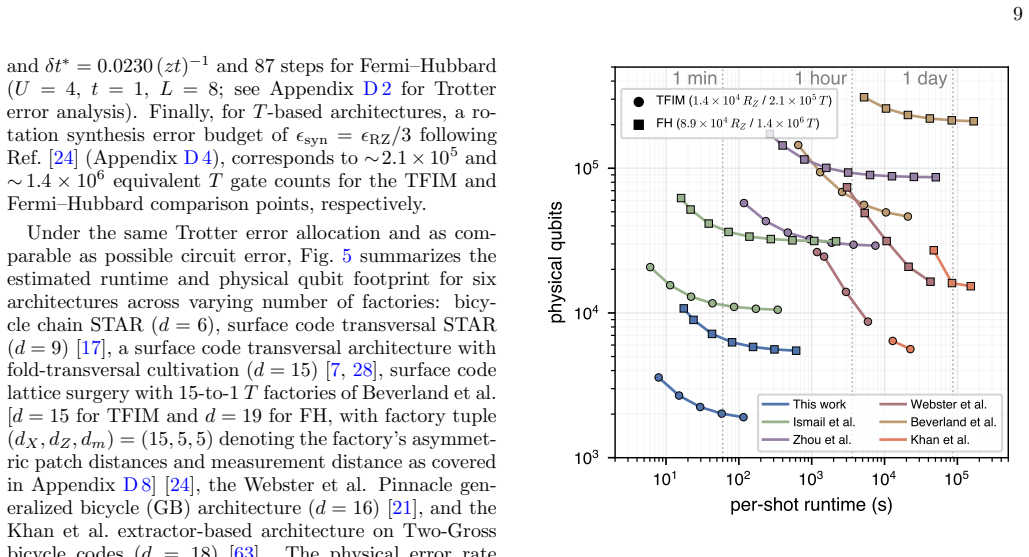
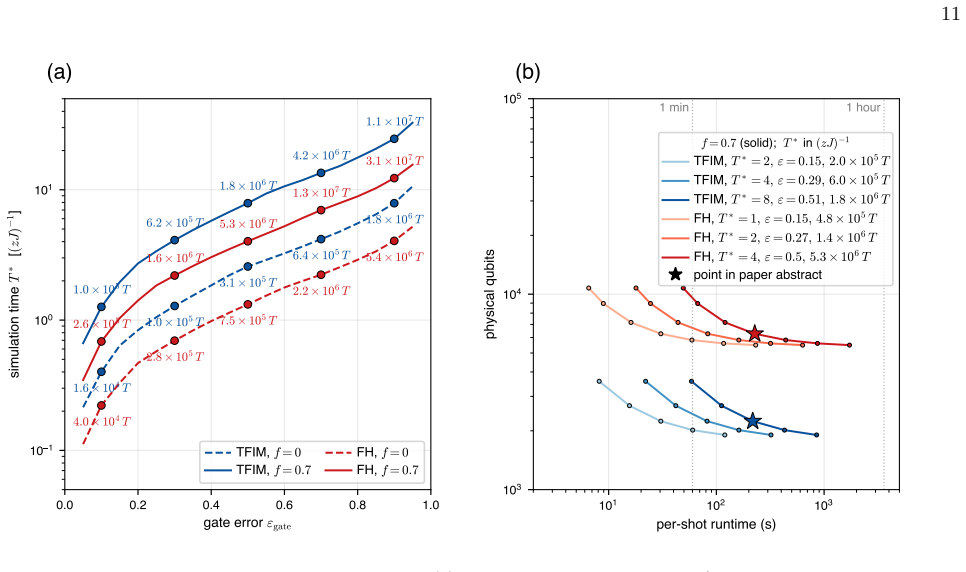
- An 8-by-8 transverse-field Ising simulation to T-star approximately 8 inverse zJ requires 2240 physical qubits and about 200 seconds per shot.
- Fermi-Hubbard dynamics to T-star approximately 4 inverse zt can be run with roughly 6300 physical qubits at similar per-shot time.
- Disjoint logical representatives permit simultaneous STAR injections across every logical qubit inside a code block.
- Hardware-native acousto-optic-deflector shifts realize the logical operations at low depth on neutral-atom arrays.
Where Pith is reading between the lines
- The same symmetry-matching principle could be applied to other local lattice models whose interaction graph admits a compatible automorphism group.
- Parallel injection may allow post-selection to be used at larger code distances than surface-code STAR approaches typically support.
- The architecture's reliance on translation symmetry suggests it may extend naturally to periodic boundary conditions or toroidal lattices.
Load-bearing premise
Translation symmetries of the simulated lattice suffice to choose bicycle chain codes that implement the needed Clifford gates natively and allow parallel STAR injections on all logical qubits.
What would settle it
Explicit compilation and error-rate measurement of one full logical time step for the 8-by-8 Ising model on the proposed bicycle code, checking whether the claimed 5.5-fold space reduction at comparable wall-clock time is realized.
Figures



read the original abstract
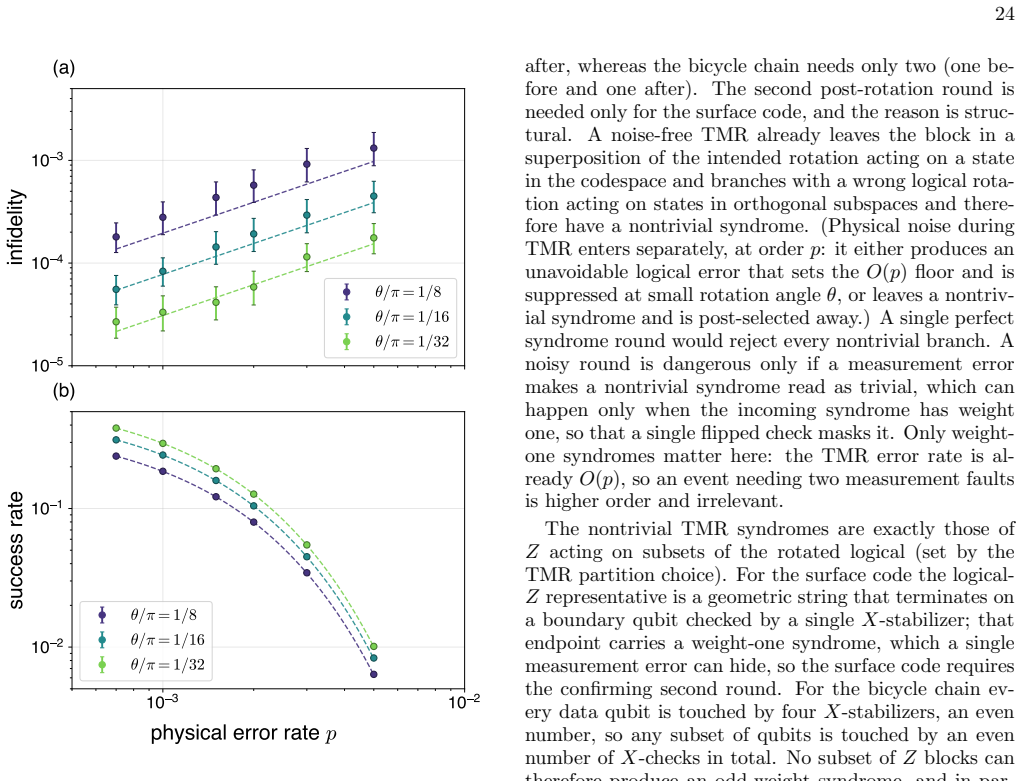
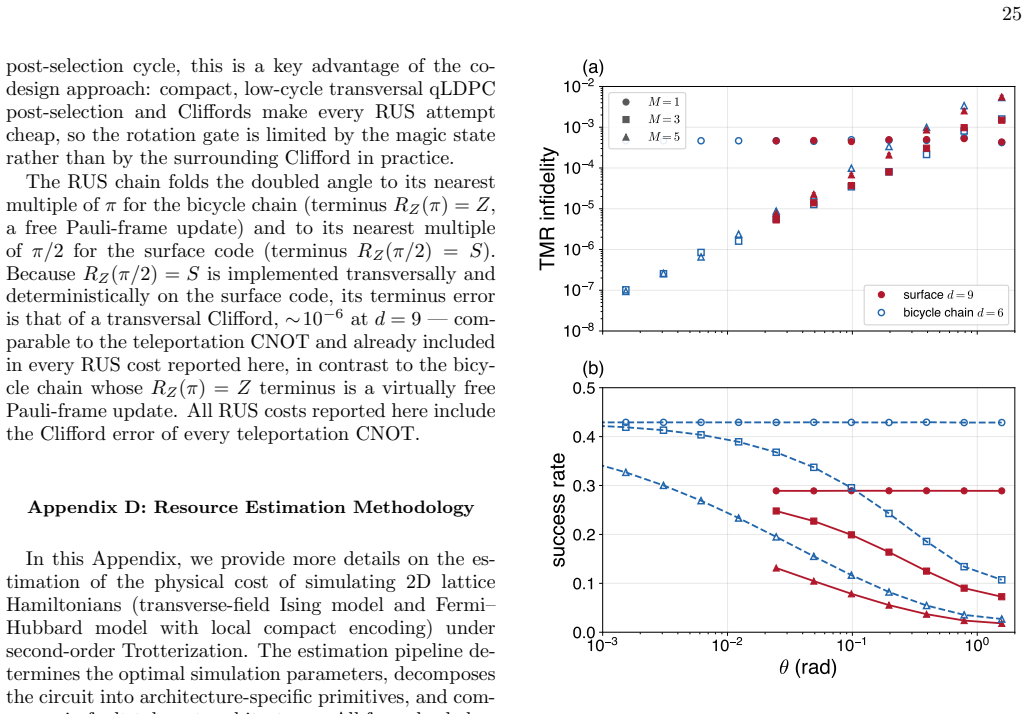
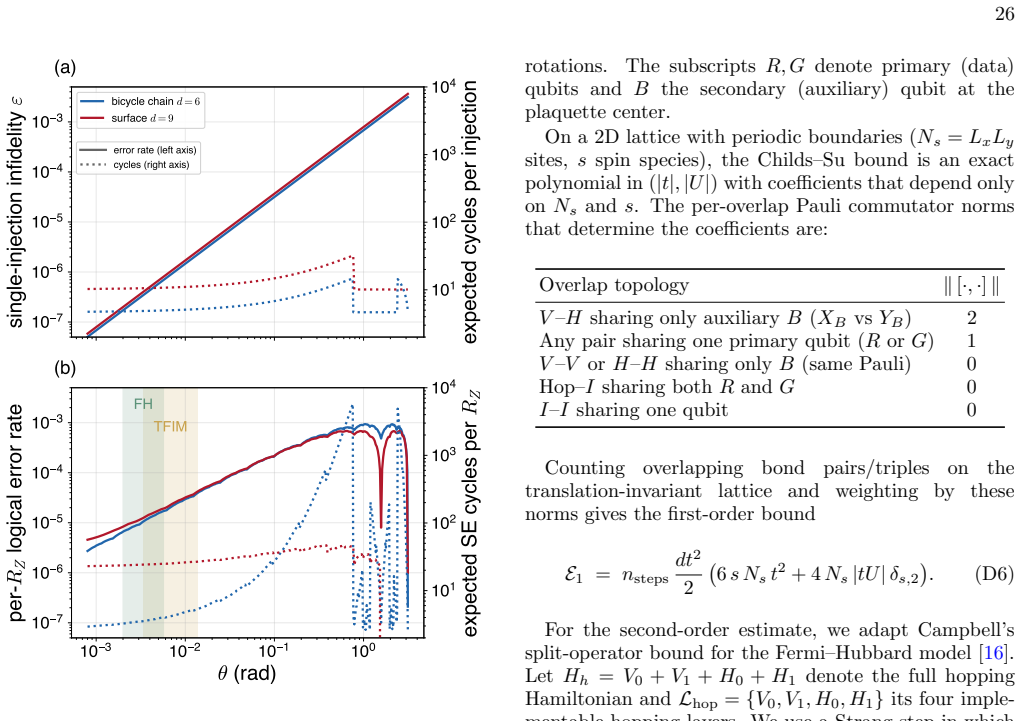
Fault-tolerant quantum simulation is approaching a phase where encoding overhead, logical Clifford operations, magic-state preparation, and rotation synthesis must be optimized together for efficient implementation. Space-Time efficient Analog Rotation (STAR) architectures reduce two of these costs by preparing small-angle rotation magic states directly, and the transversal STAR variant further lowers the Clifford overhead. Existing concrete implementations, however, largely inherit the low $O(1/d^2)$ encoding rate of the surface code, while high-rate codes have not yet been integrated into comparably explicit architectures. Here, we introduce a high-rate STAR architecture for local lattice Hamiltonian simulation based on a symmetry-driven co-design of the algorithm, QEC code, and neutral-atom hardware. Translation symmetries of the target lattice determine the choice of bicycle chain codes, a tunable family of self-dual bivariate bicycle codes that natively implement Clifford gates required for lattice simulation. Disjoint logical representatives allow STAR injections to be performed in parallel on all $k$ logical qubits in a code block, amortizing resource state preparation and enabling practical post-selection rates. On neutral-atom platform, the same translation symmetry compiles the key logical operations into low-depth, hardware-native acousto-optic-deflector shifts. End-to-end estimates show that an $8 \times 8$ transverse-field Ising simulation to $T^* \approx 8 (zJ)^{-1}$ requires $2240$ physical qubits and $\sim 200$ s per shot, a $\sim 5.5\times$ space reduction relative to a surface code STAR baseline at comparable speed; for Fermi-Hubbard dynamics to $T^* \approx 4 (zt)^{-1}$, the corresponding estimates are $\sim 6300$ physical qubits and $\sim 200$ s per shot. These results provide a concrete route toward early fault-tolerant quantum simulation with high-rate codes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a symmetry-driven co-design for a high-rate STAR architecture targeting local lattice Hamiltonian simulation. Translation symmetries of the target model select bicycle chain codes (a family of self-dual bivariate bicycle codes) that natively realize the required Clifford gates; disjoint logical representatives then permit parallel STAR magic-state injections across all k logical qubits. On neutral-atom hardware the same symmetries compile logical operations to low-depth AOD shifts. End-to-end estimates are given for an 8×8 transverse-field Ising model to T*≈8(zJ)^{-1} (2240 physical qubits, ∼200 s/shot, 5.5× space reduction vs. surface-code STAR) and for Fermi-Hubbard dynamics to T*≈4(zt)^{-1} (∼6300 physical qubits, ∼200 s/shot).
Significance. If the native-gate and parallel-injection properties hold under realistic noise, the work supplies the first explicit high-rate STAR architecture with concrete megaquop-scale resource counts, demonstrating a concrete route to early fault-tolerant lattice simulation that exploits both code rate and hardware symmetry. The explicit hardware compilation and amortized injection rates are notable strengths.
major comments (1)
- [Resource estimation section (implied by abstract claims)] The central resource claims rest on the assertion that bicycle chain codes natively implement all Clifford gates needed for the lattice simulation circuit and that disjoint logical representatives survive the noise model used for the 2240-qubit and 6300-qubit estimates. No explicit verification (e.g., a table of logical error rates under circuit-level noise or a derivation showing that the chosen code parameters preserve the required transversal gates) is referenced in the abstract or high-level description; this is load-bearing for the 5.5× space-reduction claim.
minor comments (2)
- [Abstract] The abstract states “∼200 s per shot” for both models; clarify whether this includes or excludes the post-selection overhead of the parallel STAR injections.
- [Abstract] Notation for the target time T* and the coupling constants (zJ, zt) should be defined at first use and kept consistent with the Hamiltonian definitions later in the text.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and for recognizing the potential of our symmetry-co-designed high-rate STAR architecture. We address the single major comment below, agreeing that the abstract and high-level description would benefit from clearer pointers to the supporting derivations and data.
read point-by-point responses
-
Referee: [Resource estimation section (implied by abstract claims)] The central resource claims rest on the assertion that bicycle chain codes natively implement all Clifford gates needed for the lattice simulation circuit and that disjoint logical representatives survive the noise model used for the 2240-qubit and 6300-qubit estimates. No explicit verification (e.g., a table of logical error rates under circuit-level noise or a derivation showing that the chosen code parameters preserve the required transversal gates) is referenced in the abstract or high-level description; this is load-bearing for the 5.5× space-reduction claim.
Authors: We agree that the abstract and high-level summary do not explicitly reference the verification details, which could make the load-bearing claims harder to trace on first reading. The full manuscript derives the native Clifford-gate implementation from the self-dual structure and translation symmetry of the bicycle-chain codes in Section III, and Section V presents the circuit-level noise model together with the resulting logical error rates that confirm the disjoint representatives remain viable for parallel STAR injection. To address the referee's concern directly, we will revise the abstract to include a brief pointer to these sections and add a compact summary table of the relevant logical error rates (under the same depolarizing noise model used for the 2240- and 6300-qubit estimates) in the resource-estimation section of the revised manuscript. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's central estimates (2240 physical qubits, ~200 s per shot, 5.5× space reduction) are presented as outputs of an explicit symmetry-driven co-design architecture that selects bicycle chain codes for native Clifford gates and parallel STAR injections. No equations or resource counts are shown to reduce by construction to fitted parameters, self-defined quantities, or load-bearing self-citations from the same authors. The derivation remains self-contained against external benchmarks once the stated code properties hold, with no self-definitional loops, fitted-input predictions, or ansatz smuggling identified in the provided text.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Bicycle chain codes, tuned as self-dual bivariate bicycle codes via translation symmetries, natively implement the Clifford gates required for lattice simulation.
- domain assumption Disjoint logical representatives exist that allow STAR injections to be performed in parallel on all k logical qubits while maintaining practical post-selection rates.
Reference graph
Works this paper leans on
-
[1]
P. Selinger, Efficient Clifford+T approximation of single- qubit operators (2014), arXiv:1212.6253 [quant-ph]
Pith/arXiv arXiv 2014
-
[2]
V. Kliuchnikov, D. Maslov, and M. Mosca, Practical approximation of single-qubit unitaries by single-qubit quantum Clifford and T circuits, IEEE Transactions on Computers65, 161 (2016), arXiv:1212.6964 [quant-ph]
Pith/arXiv arXiv 2016
-
[3]
N. J. Ross and P. Selinger, Optimal ancilla-free Clifford+T approximation of z-rotations (2016), arXiv:1403.2975 [quant-ph]
Pith/arXiv arXiv 2016
-
[4]
Akahoshi, K
Y. Akahoshi, K. Maruyama, H. Oshima, S. Sato, and K. Fujii, Partially Fault-Tolerant Quantum Computing Architecture with Error-Corrected Clifford Gates and Space-Time Efficient Analog Rotations, PRX Quantum 5, 010337 (2024)
2024
-
[5]
E. T. Campbell, Early fault-tolerant simulations of the Hubbard model, Quantum Science and Technology7, 015007 (2022), arXiv:2012.09238 [quant-ph]
arXiv 2022
-
[6]
R. Ismail, I.-C. Chen, C. Zhao, R. Weiss, F. Liu, H. Zhou, S.-T. Wang, A. Sornborger, and M. Kornjaˇ ca, Transver- sal STAR architecture for megaquop-scale quantum sim- ulation with neutral atoms (2025), arXiv:2509.18294 [quant-ph]
Pith/arXiv arXiv 2025
-
[7]
C. Gidney and M. Eker˚ a, How to factor 2048 bit RSA in- tegers in 8 hours using 20 million noisy qubits, Quantum 5, 433 (2021), arXiv:1905.09749 [quant-ph]
arXiv 2048
-
[8]
C. Gidney, How to factor 2048 bit RSA integers with less than a million noisy qubits (2025), arXiv:2505.15917 [quant-ph]
Pith/arXiv arXiv 2048
-
[9]
M. Cain, Q. Xu, R. King, L. R. B. Picard, H. Levine, M. Endres, J. Preskill, H.-Y. Huang, and D. Bluvstein, Shor’s algorithm is possible with as few as 10,000 recon- figurable atomic qubits (2026), arXiv:2603.28627 [quant- ph]
Pith/arXiv arXiv 2026
-
[10]
P. Webster, L. Berent, O. Chandra, E. T. Hockings, N. Baspin, F. Thomsen, S. C. Smith, and L. Z. Cohen, The Pinnacle Architecture: Reducing the cost of break- ing RSA-2048 to 100 000 physical qubits using quantum LDPC codes (2026), arXiv:2602.11457 [quant-ph]
Pith/arXiv arXiv 2048
-
[11]
R. Babbush, A. Zalcman, C. Gidney, M. Broughton, T. Khattar, H. Neven, T. Bergamaschi, J. Drake, and D. Boneh, Securing Elliptic Curve Cryptocurrencies against Quantum Vulnerabilities: Resource Estimates and Mitigations (2026), arXiv:2603.28846 [quant-ph]
Pith/arXiv arXiv 2026
-
[12]
D. Litinski, How to compute a 256-bit elliptic curve private key with only 50 million Toffoli gates (2023), arXiv:2306.08585 [quant-ph]
arXiv 2023
-
[13]
M. E. Beverland, P. Murali, M. Troyer, K. M. Svore, T. Hoefler, V. Kliuchnikov, G. H. Low, M. Soeken, A. Sundaram, and A. Vaschillo, Assessing require- ments to scale to practical quantum advantage (2022), arXiv:2211.07629 [quant-ph]
Pith/arXiv arXiv 2022
- [14]
-
[15]
J. M. Koh, A. Gong, A. C. Diaconu, D. B. Tan, A. A. Geim, M. J. Gullans, N. Y. Yao, M. D. Lukin, and S. Ma- jidy, Entangling logical qubits without physical opera- tions (2026), arXiv:2601.20927 [quant-ph]
arXiv 2026
-
[16]
W. Yang, J. Chadwick, M. H. Teo, J. Viszlai, and F. Chong, Spacetime-efficient and hardware-compatible complex quantum logic units in qldpc codes (2026), arXiv:2602.14273 [quant-ph]
arXiv 2026
-
[17]
H. Zhou, C. Zhao, M. Cain, D. Bluvstein, N. Maskara, C. Duckering, H.-Y. Hu, S.-T. Wang, A. Kubica, and M. D. Lukin, Low-overhead transversal fault tolerance for 13 universal quantum computation, Nature646, 303 (2025)
2025
-
[18]
N. P. Breuckmann and J. N. Eberhardt, Quantum Low- Density Parity-Check Codes, PRX Quantum2, 040101 (2021), arXiv:2103.06309 [quant-ph]
arXiv 2021
-
[19]
J.-P. Tillich and G. Zemor, Quantum LDPC codes with positive rate and minimum distance proportional to nˆ{1/2}, https://arxiv.org/abs/0903.0566v2 (2009)
Pith/arXiv arXiv 2009
-
[20]
P. Panteleev and G. Kalachev, Asymptotically Good Quantum and Locally Testable Classical LDPC Codes (2022), arXiv:2111.03654 [quant-ph]
arXiv 2022
-
[21]
A. Leverrier and G. Z´ emor, Quantum Tanner codes (2022), arXiv:2202.13641 [quant-ph]
arXiv 2022
-
[22]
Bravyi, A
S. Bravyi, A. W. Cross, J. M. Gambetta, D. Maslov, P. Rall, and T. J. Yoder, High-threshold and low- overhead fault-tolerant quantum memory, Nature627, 778 (2024)
2024
-
[23]
K. Kasai, Breaking the Orthogonality Barrier in Quan- tum LDPC Codes (2026), arXiv:2601.08824 [quant-ph]
arXiv 2026
-
[24]
C. Zhao, C. Duckering, A. Gu, N. Maskara, and H. Zhou, Towards Ultra-High-Rate Quantum Error Correction with Reconfigurable Atom Arrays (2026), arXiv:2604.16209 [quant-ph]
Pith/arXiv arXiv 2026
- [25]
-
[26]
Q. Xu, H. Zhou, D. Bluvstein, M. Cain, M. Kalinowski, J. Preskill, M. D. Lukin, and N. Maskara, Batched high- rate logical operations for quantum LDPC codes (2025), arXiv:2510.06159 [quant-ph]
arXiv 2025
-
[27]
Z. Liang and Y.-A. Chen, Self-dual bivariate bi- cycle codes with transversal Clifford gates (2025), arXiv:2510.05211 [quant-ph]
arXiv 2025
-
[28]
Derby, J
C. Derby, J. Klassen, J. Bausch, and T. Cubitt, Com- pact fermion to qubit mappings, Physical Review B104, 035118 (2021)
2021
-
[29]
Bluvstein, H
D. Bluvstein, H. Levine, G. Semeghini, T. T. Wang, S. Ebadi, M. Kalinowski, A. Keesling, N. Maskara, H. Pichler, M. Greiner, V. Vuleti´ c, and M. D. Lukin, A quantum processor based on coherent transport of en- tangled atom arrays, Nature604, 451 (2022)
2022
-
[30]
D. Bluvstein, S. J. Evered, A. A. Geim, S. H. Li, H. Zhou, T. Manovitz, S. Ebadi, M. Cain, M. Kalinowski, D. Hangleiter, J. P. B. Ataides, N. Maskara, I. Cong, X. Gao, P. S. Rodriguez, T. Karolyshyn, G. Semeghini, M. J. Gullans, M. Greiner, V. Vuleti´ c, and M. D. Lukin, Logical quantum processor based on reconfigurable atom arrays, Nature 10.1038/s41586-...
-
[31]
Sales Rodriguez, J
P. Sales Rodriguez, J. M. Robinson, P. N. Jepsen, Z. He, C. Duckering, C. Zhao, K.-H. Wu, J. Campo, K. Bagnall, M. Kwon, T. Karolyshyn, P. Weinberg, M. Cain, S. J. Evered, A. A. Geim, M. Kalinowski, S. H. Li, T. Manovitz, J. Amato-Grill, J. I. Basham, L. Bernstein, B. Braverman, A. Bylinskii, A. Choukri, R. J. DeAngelo, F. Fang, C. Fieweger, P. Frederick,...
2025
-
[32]
A. Jafarizadeh, F. Pollmann, and A. Gammon-Smith, A recipe for local simulation of strongly-correlated fermionic matter on quantum computers: The 2D Fermi- Hubbard model (2024), arXiv:2408.14543 [quant-ph]
arXiv 2024
-
[33]
Gottesman, Stabilizer Codes and Quantum Error Cor- rection (1997), arXiv:quant-ph/9705052
D. Gottesman, Stabilizer Codes and Quantum Error Cor- rection (1997), arXiv:quant-ph/9705052
Pith/arXiv arXiv 1997
-
[34]
A. R. Calderbank, E. M. Rains, P. W. Shor, and N. J. A. Sloane, Quantum Error Correction via Codes over GF(4) (1997), arXiv:quant-ph/9608006
Pith/arXiv arXiv 1997
-
[35]
B. Zeng, A. Cross, and I. L. Chuang, Transversality ver- sus Universality for Additive Quantum Codes (2007), arXiv:0706.1382 [quant-ph]
Pith/arXiv arXiv 2007
-
[36]
B. Gu, A. Z. Liu, A. O. Quintavalle, Q. Xu, J. Eisert, and J. Roffe, QGPU: Parallel logic in quantum LDPC codes (2026), arXiv:2603.05398 [quant-ph]
arXiv 2026
-
[37]
J. Haah, Algebraic Methods for Quantum Codes on Lattices, Revista Colombiana de Matem´ aticas50, 299 (2017), arXiv:1607.01387 [quant-ph]
Pith/arXiv arXiv 2017
- [38]
-
[39]
Gidney, Stim: A fast stabilizer circuit simulator, Quantum5, 497 (2021)
C. Gidney, Stim: A fast stabilizer circuit simulator, Quantum5, 497 (2021)
2021
-
[40]
B. A. Chase and F. Labib, Clifft: Fast Exact Sim- ulation of Near-Clifford Quantum Circuits (2026), arXiv:2604.27058 [quant-ph]
Pith/arXiv arXiv 2026
-
[41]
T. M¨ uller, T. Alexander, M. E. Beverland, M. B¨ uhler, B. R. Johnson, T. Maurer, and D. Vandeth, Improved belief propagation is sufficient for real-time decoding of quantum memory (2025), arXiv:2506.01779 [quant-ph]
arXiv 2025
-
[42]
M. Cain, C. Zhao, H. Zhou, N. Meister, J. P. B. Ataides, A. Jaffe, D. Bluvstein, and M. D. Lukin, Correlated De- coding of Logical Algorithms with Transversal Gates, Physical Review Letters133, 240602 (2024)
2024
-
[43]
A. J. Landahl, J. T. Anderson, and P. R. Rice, Fault- tolerant quantum computing with color codes (2011), arXiv:1108.5738 [quant-ph]
Pith/arXiv arXiv 2011
-
[44]
Takada, Y
Y. Takada, Y. Takeuchi, and K. Fujii, Ising model for- mulation for highly accurate topological color codes de- coding, Physical Review Research6, 013092 (2024)
2024
-
[45]
Gurobi Optimization, LLC, Gurobi Optimizer Reference Manual (2026)
2026
-
[46]
S. Ma, G. Liu, P. Peng, B. Zhang, S. Jandura, J. Claes, A. P. Burgers, G. Pupillo, S. Puri, and J. D. Thompson, High-fidelity gates and mid-circuit erasure conversion in an atomic qubit, Nature622, 279–284 (2023)
2023
-
[47]
Scholl, A
P. Scholl, A. L. Shaw, R. B.-S. Tsai, R. Finkelstein, J. Choi, and M. Endres, Erasure conversion in a high- fidelity rydberg quantum simulator, Nature622, 273–278 (2023)
2023
-
[48]
M. N. H. Chow, V. Buchemmavari, S. Omanakut- tan, B. J. Little, S. Pandey, I. H. Deutsch, and Y.- Y. Jau, Circuit-based leakage-to-erasure conversion in a neutral-atom quantum processor, PRX Quantum5, 10.1103/prxquantum.5.040343 (2024)
-
[49]
H. Choi, F. T. Chong, D. Englund, and Y. Ding, Fault tolerant non-clifford state preparation for arbitrary rota- tions (2023), arXiv:2303.17380 [quant-ph]
arXiv 2023
-
[50]
Y. Wu, B. Li, K. Chang, S. Puri, and L. Zhong, Minimum-weight parity factor decoder for quantum error correction (2025), arXiv:2508.04969 [quant-ph]
arXiv 2025
-
[51]
S. J. Evered, M. Xu, S. H. Li, A. A. Geim, J. P. B. Ataides, M. Kalinowski, D. Bluvstein, N. Maskara, 14 C. Kokail, M. Greiner, V. Vuleti´ c, and M. D. Lukin, High-fidelity entangling gates and nonlocal circuits with neutral atoms (2026), arXiv:2604.25987 [quant-ph]
Pith/arXiv arXiv 2026
-
[52]
S. Khan, S. Sethi, K. Sahay, Y. Lin, J. Alnas, S. Kurap- ati, A. Anand, J. M. Baker, and K. R. Brown, Architect- ing Early Fault Tolerant Neutral Atoms Systems with Quantum Advantage (2026), arXiv:2604.19735 [quant- ph]
Pith/arXiv arXiv 2026
-
[53]
M.-Z. Chung, A. H. Z. Kavaki, A. Scherer, A. Khalid, X. Kong, T. Kawakubo, N. Anand, G. A. Dagnew, Z. Webb, A. Silva, G. Gyawali, T. Yan, K. Fujii, A. Ho, M. Mohseni, P. Ronagh, and J. Martinis, Partially fault- tolerant quantum computation for megaquop applica- tions (2026), arXiv:2603.13093 [quant-ph]
arXiv 2026
- [54]
-
[55]
J. P. Bonilla Ataides, D. K. Tuckett, S. D. Bartlett, S. T. Flammia, and B. J. Brown, The XZZX surface code, Na- ture Communications12, 2172 (2021)
2021
-
[56]
G. Baranes, M. Cain, J. P. B. Ataides, D. Bluvstein, J. Sinclair, V. Vuletic, H. Zhou, and M. D. Lukin, Lever- aging Atom Loss Errors in Fault Tolerant Quantum Al- gorithms (2025), arXiv:2502.20558 [quant-ph]
arXiv 2025
-
[57]
C.-C. Yu, Y.-H. Deng, M.-C. Chen, C.-Y. Lu, and J.- W. Pan, Locating Rydberg Decay Error in SWAP-LRU (2025), arXiv:2503.01649 [quant-ph]
Pith/arXiv arXiv 2025
-
[58]
C.-C. Yu, Z.-H. Chen, Y.-H. Deng, M.-C. Chen, C.-Y. Lu, and J.-W. Pan, Processing and Decoding Rydberg Decay Error with MBQC (2025), arXiv:2411.04664 [quant-ph]
Pith/arXiv arXiv 2025
-
[59]
P. Liu, S. J. S. Tan, E. Huang, U. A. Acar, H. Zhou, and C. Zhao, Achieving Optimal-Distance Atom-Loss Correc- tion via Pauli Envelope (2026), arXiv:2603.04156 [quant- ph]
Pith/arXiv arXiv 2026
- [60]
-
[61]
J. P. B. Ataides, A. Gu, S. F. Yelin, and M. D. Lukin, Neural Decoders for Universal Quantum Algo- rithms (2025), arXiv:2509.11370 [quant-ph]
arXiv 2025
-
[62]
A. Gu, J. P. B. Ataides, M. D. Lukin, and S. F. Yelin, Scalable Neural Decoders for Practical Fault-Tolerant Quantum Computation (2026), arXiv:2604.08358 [quant- ph]
Pith/arXiv arXiv 2026
-
[63]
A. M. Childs, A. Ostrander, and Y. Su, Faster quantum simulation by randomization, Quantum3, 182 (2019), arXiv:1805.08385 [quant-ph]
arXiv 2019
-
[64]
E. Campbell, A random compiler for fast hamiltonian simulation, Physical Review Letters123, 070503 (2019), arXiv:1811.08017 [quant-ph]
arXiv 2019
-
[65]
D. Wecker, M. B. Hastings, N. Wiebe, B. K. Clark, C. Nayak, and M. Troyer, Solving strongly correlated electron models on a quantum computer, Physical Re- view A92, 062318 (2015), arXiv:1506.05135 [quant-ph]
Pith/arXiv arXiv 2015
- [66]
-
[67]
A. Y. Kitaev, Quantum measurements and the Abelian Stabilizer Problem, https://arxiv.org/abs/quant- ph/9511026v1 (1995)
arXiv 1995
-
[68]
S. Lu, M. C. Ba˜ nuls, and J. I. Cirac, Algorithms for Quantum Simulation at Finite Energies, PRX Quantum 2, 020321 (2021)
2021
-
[69]
Lin and Y
L. Lin and Y. Tong, Heisenberg-limited ground-state en- ergy estimation for early fault-tolerant quantum comput- ers, PRX Quantum3, 010318 (2022)
2022
-
[70]
K. Wan, M. Berta, and E. T. Campbell, Randomized quantum algorithm for statistical phase estimation, Phys. Rev. Lett.129, 030503 (2022)
2022
-
[71]
E. N. Epperly, L. Lin, and Y. Nakatsukasa, A the- ory of quantum subspace diagonalization, SIAM Journal on Matrix Analysis and Applications43, 1263 (2022), https://doi.org/10.1137/21M145954X
-
[72]
J. Robledo-Moreno, M. Motta, H. Haas, A. Javadi- Abhari, P. Jurcevic, W. Kirby, S. Martiel, K. Sharma, S. Sharma, T. Shirakawa, I. Sitdikov, R.-Y. Sun, K. J. Sung, M. Takita, M. C. Tran, S. Yunoki, and A. Mezzacapo, Chemistry beyond the scale of exact diagonalization on a quantum-centric su- percomputer, Science Advances11, eadu9991 (2025), https://www.sc...
-
[73]
Yoshioka, M
N. Yoshioka, M. Amico, W. Kirby, P. Jurcevic, A. Dutt, B. Fuller, S. Garion, H. Haas, I. Hamamura, A. Ivrii, R. Majumdar, Z. Minev, M. Motta, B. Pokharel, P. Rivero, K. Sharma, C. J. Wood, A. Javadi-Abhari, and A. Mezzacapo, Krylov diagonalization of large many- body hamiltonians on a quantum processor, Nature Com- munications16, 5014 (2025)
2025
- [74]
- [75]
-
[76]
G. Zhang and Y. Li, Time-Efficient Logical Operations on Quantum Low-Density Parity Check Codes, Physi- cal Review Letters134, 070602 (2025), arXiv:2408.01339 [quant-ph]
arXiv 2025
- [77]
-
[78]
Flannigan, N
S. Flannigan, N. Pearson, G. H. Low, A. Buyskikh, I. Bloch, P. Zoller, M. Troyer, and A. J. Daley, Propaga- tion of errors and quantitative quantum simulation with quantum advantage, Quantum Science and Technology 7, 045025 (2022)
2022
-
[79]
V. Menon, J. P. Bonilla-Ataides, R. Mehta, D. B. Tan, and M. D. Lukin, Magic tricycles: Efficient magic state generation with finite block-length quantum LDPC codes (2025), arXiv:2508.10714 [quant-ph]
Pith/arXiv arXiv 2025
-
[80]
I. D. Kivlichan, C. Gidney, D. W. Berry, N. Wiebe, J. McClean, W. Sun, Z. Jiang, N. Rubin, A. Fowler, A. Aspuru-Guzik, H. Neven, and R. Babbush, Improved Fault-Tolerant Quantum Simulation of Condensed- Phase Correlated Electrons via Trotterization, Quantum 4, 296 (2020)
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.