SMI: Efficient Self-Supervised Learning via Mutual-Information-Inspired Dependency Optimization
Pith reviewed 2026-06-27 19:39 UTC · model grok-4.3
The pith
A mutual-information-inspired objective lets self-supervised models match state-of-the-art accuracy on ImageNet while cutting training complexity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
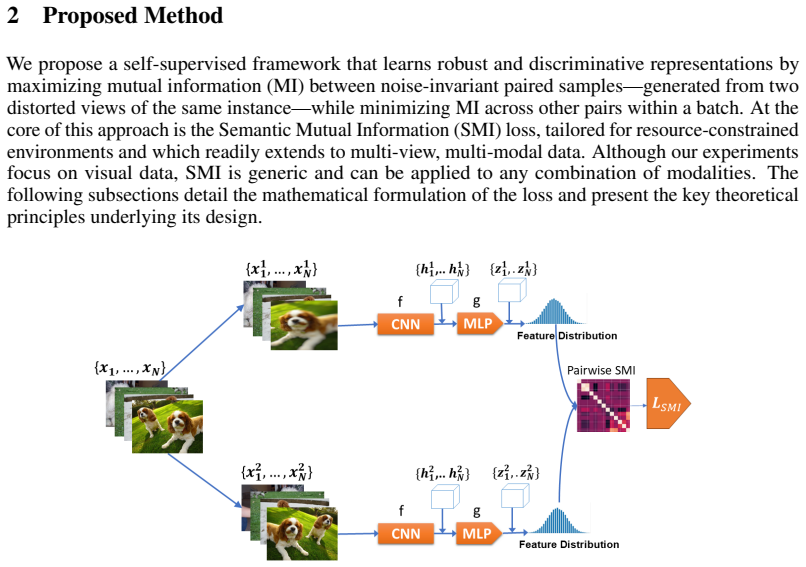
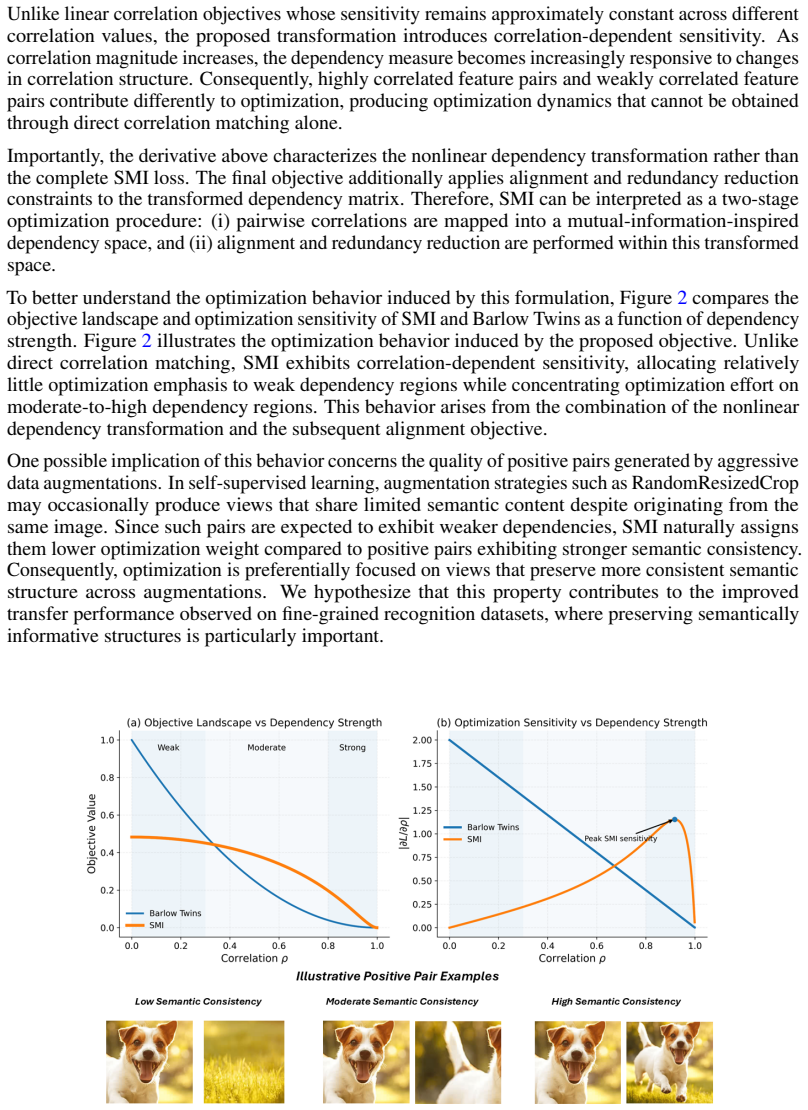
SMI is a lightweight self-supervised objective derived from a mutual-information-inspired dependency formulation under Gaussian assumptions. Unlike conventional correlation matching objectives that operate on high-dimensional feature correlation matrices, SMI performs optimization on a sample-level dependency matrix through a nonlinear transformation of pairwise correlations. This formulation induces distinct optimization dynamics that emphasize strongly dependent semantic pairs while maintaining representation diversity. Experimental results on ImageNet using a ResNet-50 backbone demonstrate that SMI achieves competitive linear evaluation performance relative to state-of-the-art SSL approac
What carries the argument
The sample-level dependency matrix obtained via nonlinear transformation of pairwise correlations under the Gaussian mutual-information-inspired formulation.
If this is right
- SMI matches state-of-the-art linear evaluation on ImageNet with a ResNet-50 backbone while using substantially less computation than methods that rely on large batches or momentum encoders.
- Transfer performance improves over Barlow Twins across multiple low-resource benchmarks, with larger gains on fine-grained datasets.
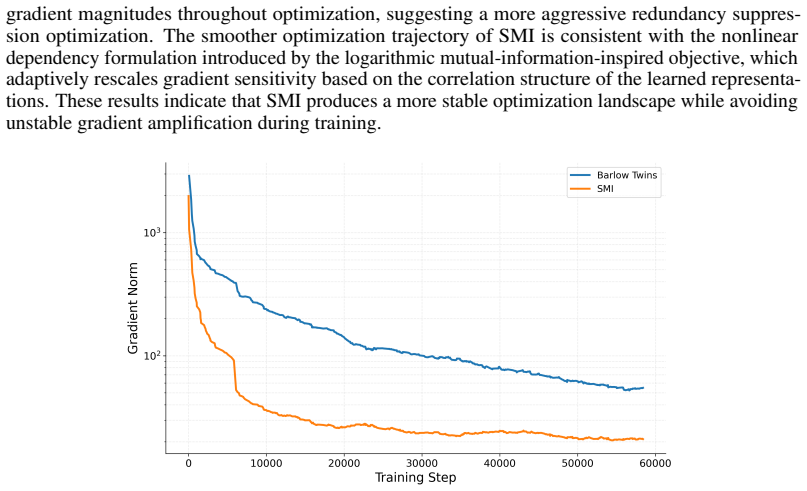
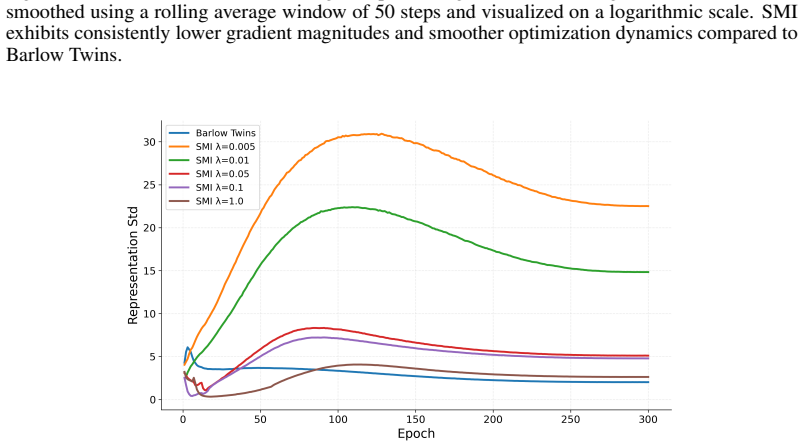
- Learned representations exhibit an improved alignment-redundancy balance together with greater feature diversity.
- Semantic features become more spatially localized than those produced by conventional correlation-based objectives.
Where Pith is reading between the lines
- The reduced memory footprint could let practitioners run high-quality SSL on single-GPU hardware that cannot accommodate large-batch baselines.
- The emphasis on strongly dependent pairs may translate to stronger performance on tasks where object categories are clearly separated.
- Replacing the Gaussian assumption with other distributional models would test whether the reported dynamics are specific to that choice.
- The same nonlinear dependency construction could be inserted into existing SSL pipelines that already use correlation losses.
Load-bearing premise
The mutual-information-inspired dependency formulation under Gaussian assumptions produces optimization dynamics that emphasize strongly dependent semantic pairs while maintaining representation diversity.
What would settle it
A side-by-side run of SMI and Barlow Twins on ImageNet with ResNet-50 that shows SMI either loses linear-probe accuracy or fails to reduce peak memory and batch-size requirements.
Figures
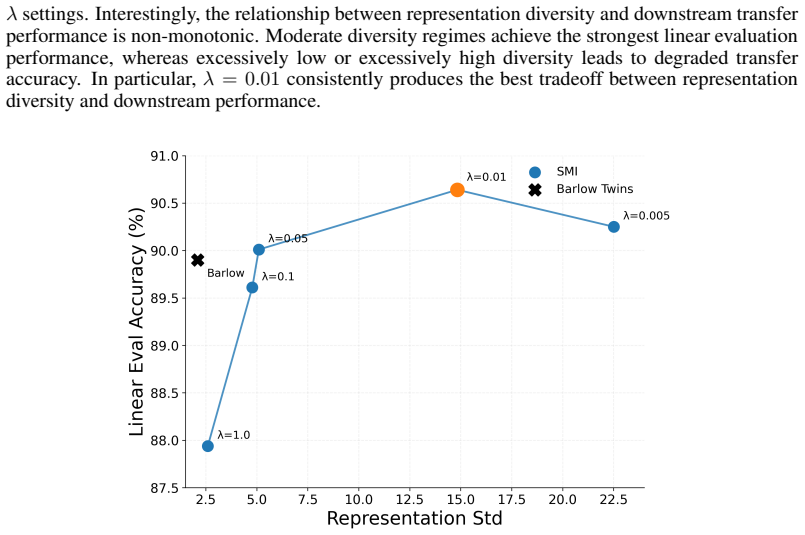
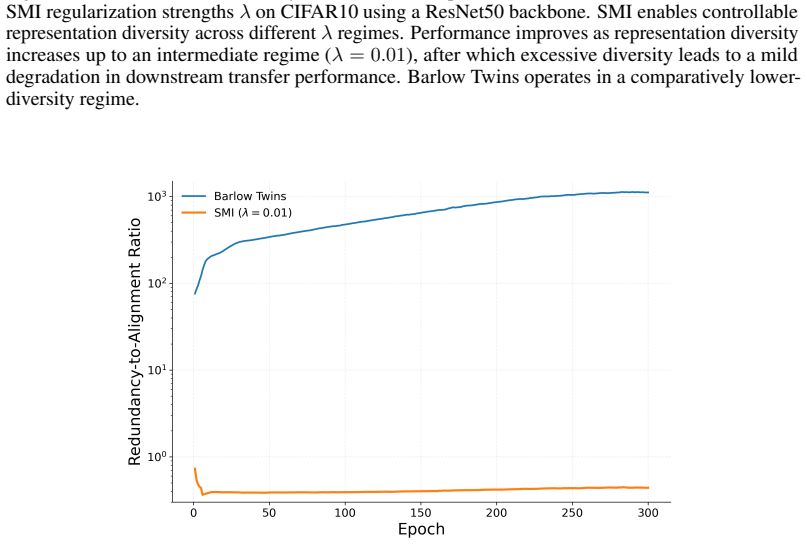
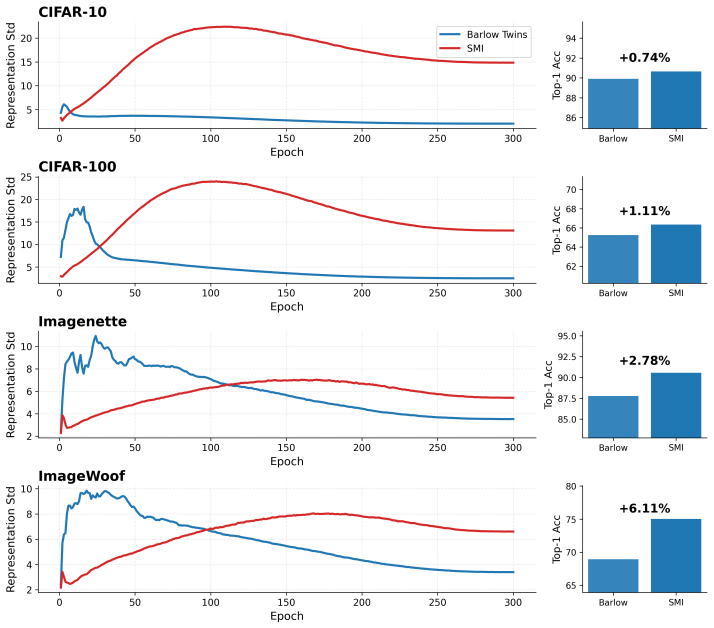
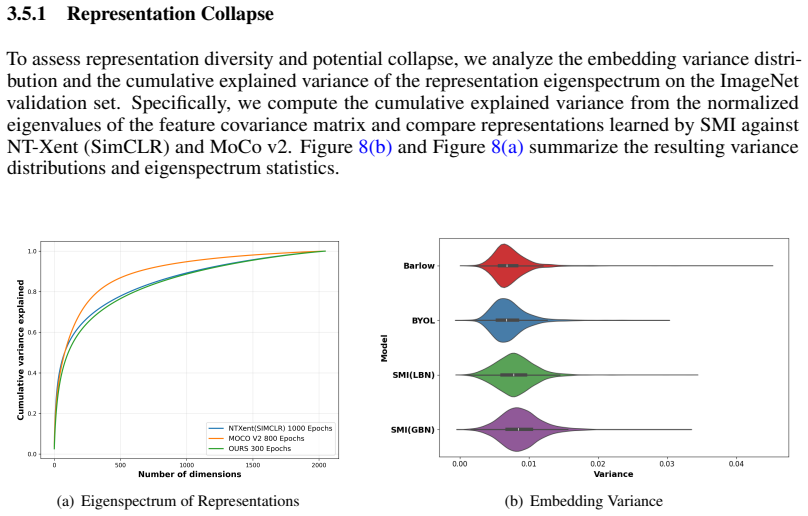
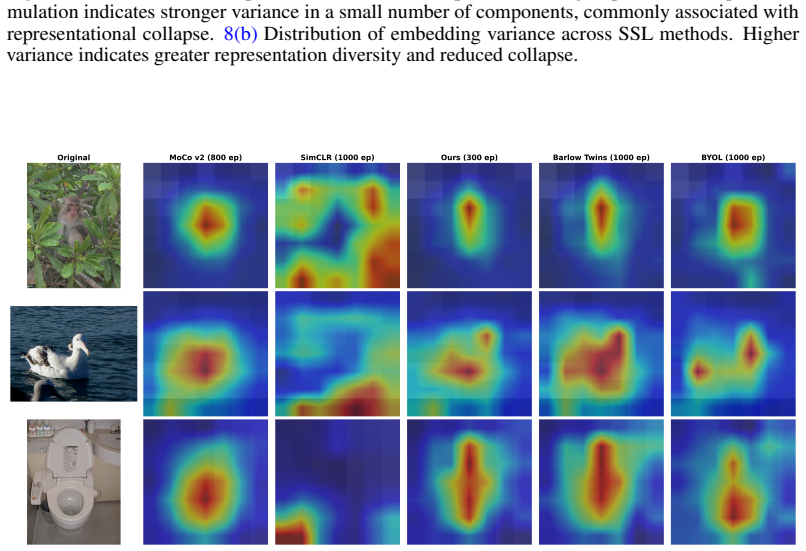
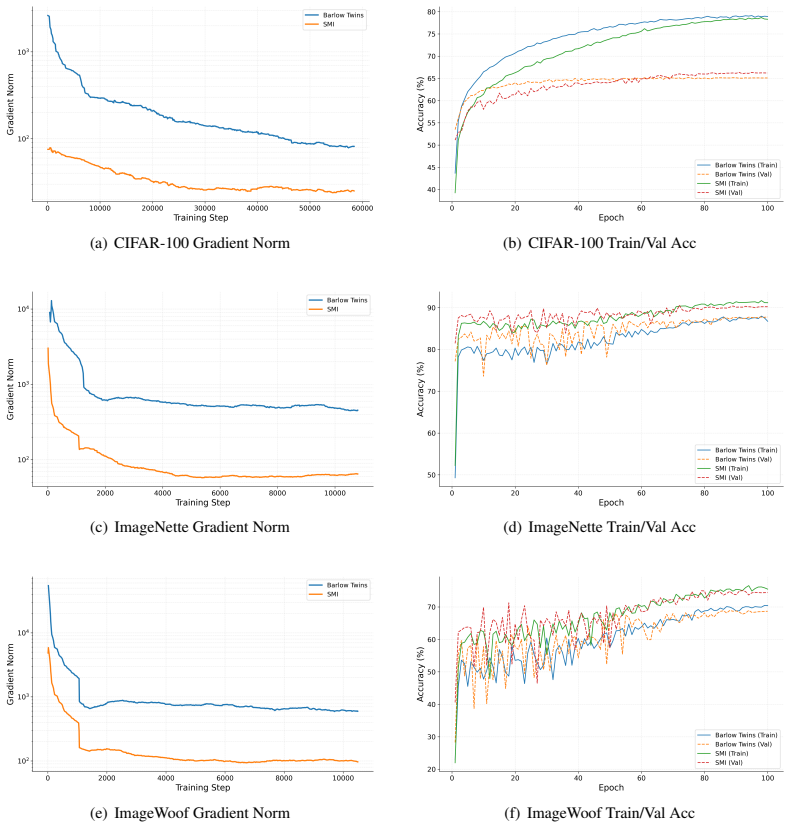
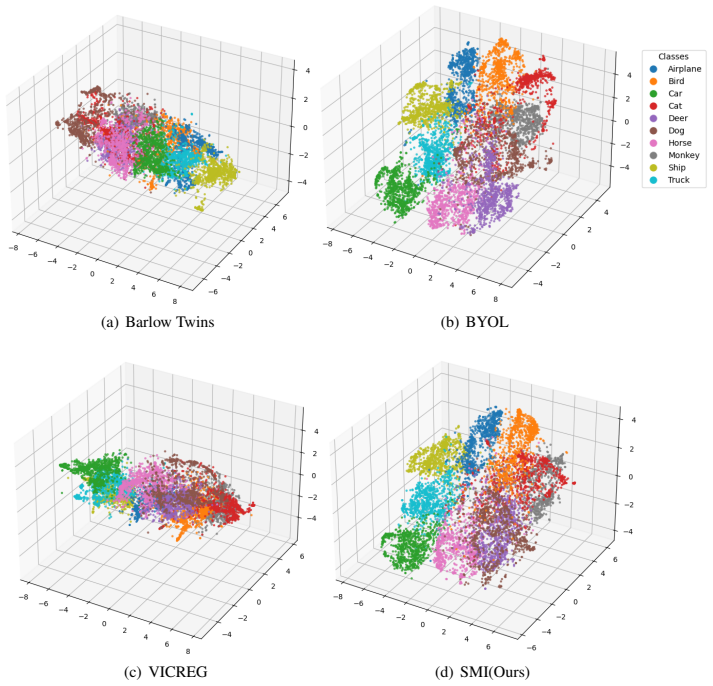
read the original abstract
Self-supervised learning (SSL) has achieved remarkable representation learning performance, but many existing methods rely on large batch sizes, memory banks, momentum encoders, or global synchronization mechanisms that substantially increase computational cost and training complexity. In this work, we propose Semantic Mutual Information (SMI), a lightweight self-supervised objective derived from a mutual-information-inspired dependency formulation under Gaussian assumptions. Unlike conventional correlation matching objectives that operate on high-dimensional feature correlation matrices, SMI performs optimization on a sample-level dependency matrix through a nonlinear transformation of pairwise correlations. This formulation induces distinct optimization dynamics that emphasize strongly dependent semantic pairs while maintaining representation diversity. Experimental results on ImageNet using a ResNet-50 backbone demonstrate that SMI achieves competitive linear evaluation performance relative to state-of-the-art SSL approaches while substantially reducing computational complexity. Across multiple low-resource benchmarks, SMI consistently improves transfer performance over Barlow Twins, particularly on fine-grained datasets. Furthermore, analyses of optimization dynamics and representation geometry suggest improved alignment--redundancy balance, greater feature diversity, and more spatially localized semantic representations. These results indicate that nonlinear dependency optimization provides an effective and computationally efficient alternative to conventional correlation-based self-supervised learning objectives.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Semantic Mutual Information (SMI), a lightweight self-supervised objective derived from a mutual-information-inspired dependency formulation under Gaussian assumptions. Unlike correlation-matrix objectives, SMI optimizes a sample-level dependency matrix via nonlinear transformation of pairwise correlations, claimed to produce dynamics that emphasize strongly dependent semantic pairs while preserving diversity. On ImageNet with a ResNet-50 backbone, SMI is reported to achieve competitive linear-evaluation performance relative to state-of-the-art SSL methods at substantially lower computational cost; it also shows improved transfer over Barlow Twins on multiple low-resource benchmarks. Additional analyses are said to indicate better alignment-redundancy balance, greater feature diversity, and more spatially localized representations.
Significance. If the Gaussian-derived formulation indeed yields distinct, reproducible optimization dynamics that deliver the claimed efficiency and performance without hidden post-hoc tuning, the work would supply a simpler alternative to batch-size- or momentum-heavy SSL methods, lowering the barrier to high-quality pretraining.
major comments (2)
- [Methods (Gaussian MI derivation)] The Gaussian-assumption derivation of the SMI objective (Methods section on mutual-information-inspired dependency formulation): because learned SSL representations are high-dimensional and typically non-Gaussian, it is unclear whether the closed-form nonlinear transform of pairwise correlations produces dynamics that differ meaningfully from existing correlation objectives such as Barlow Twins; this mechanistic claim is load-bearing for both the efficiency argument and the attribution of the reported ImageNet and transfer gains.
- [Experiments (ImageNet results)] ImageNet linear-evaluation results (Experiments section, ResNet-50 table): competitive performance is asserted without reported standard deviations across runs, ablations isolating the nonlinear dependency transform, or direct comparison of the sample-level dependency matrix against the feature-correlation matrix used by baselines; without these, it is difficult to confirm that gains follow from the proposed formulation rather than implementation details.
minor comments (2)
- [Abstract] The abstract states that 'analyses of optimization dynamics and representation geometry suggest improved alignment-redundancy balance' but does not name the quantitative metrics or report the corresponding numerical values.
- [Methods] Notation for the sample-level dependency matrix and its nonlinear transform should be introduced with an explicit equation early in the Methods section to aid readability.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We address the two major comments below regarding the Gaussian MI derivation and the experimental results. We believe these points can be clarified and strengthened in a revised version.
read point-by-point responses
-
Referee: [Methods (Gaussian MI derivation)] The Gaussian-assumption derivation of the SMI objective (Methods section on mutual-information-inspired dependency formulation): because learned SSL representations are high-dimensional and typically non-Gaussian, it is unclear whether the closed-form nonlinear transform of pairwise correlations produces dynamics that differ meaningfully from existing correlation objectives such as Barlow Twins; this mechanistic claim is load-bearing for both the efficiency argument and the attribution of the reported ImageNet and transfer gains.
Authors: We appreciate this insightful comment. The Gaussian assumption is used to derive a closed-form expression for the dependency measure, leading to a specific nonlinear transformation applied to the pairwise correlations in the sample-level matrix. This is distinct from Barlow Twins, which operates on the feature correlation matrix with a different objective (redundancy reduction via off-diagonal terms). Our formulation optimizes a dependency matrix at the sample level, which we argue induces different dynamics by emphasizing semantic pairs. To address the concern, we will add a new subsection in the Methods with a theoretical comparison of the gradients and optimization behavior under the two formulations. Additionally, we will include empirical evidence from toy experiments showing divergent behavior when using the nonlinear transform versus direct correlation matching. We maintain that the sample-level approach is the core innovation enabling efficiency. revision: partial
-
Referee: [Experiments (ImageNet results)] ImageNet linear-evaluation results (Experiments section, ResNet-50 table): competitive performance is asserted without reported standard deviations across runs, ablations isolating the nonlinear dependency transform, or direct comparison of the sample-level dependency matrix against the feature-correlation matrix used by baselines; without these, it is difficult to confirm that gains follow from the proposed formulation rather than implementation details.
Authors: We agree with the referee that additional statistical reporting and ablations would improve the manuscript. In the revised version, we will report results with standard deviations from three independent runs for the main ImageNet table. We will also add an ablation study that isolates the effect of the nonlinear transformation by comparing SMI with a variant that uses linear correlation matching on the sample-level matrix. Furthermore, we will include a direct comparison experiment visualizing or quantifying the differences between the sample-level dependency matrix and the feature-correlation matrix in terms of the learned representations and optimization paths. These additions should help attribute the gains to the proposed formulation. revision: yes
Circularity Check
No circularity: Gaussian MI derivation is first-principles and independent of evaluation
full rationale
The provided abstract describes SMI as derived from a mutual-information-inspired dependency formulation under Gaussian assumptions, yielding a nonlinear transformation of pairwise correlations on a sample-level matrix. This is presented as a closed-form derivation producing distinct dynamics, with ImageNet experiments serving as separate empirical validation rather than inputs to the derivation. No equations, self-citations, fitted parameters renamed as predictions, or self-definitional steps are quoted that would reduce the claimed objective to its own outputs by construction. The Gaussian MI step is a standard analytic assumption (not fitted on target data), and the paper's central claim remains mechanistically independent of the reported linear evaluation results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Gaussian assumptions underpin the mutual-information-inspired dependency formulation
Reference graph
Works this paper leans on
-
[1]
A simple framework for contrastive learning of visual representations,
T. Chen, S. Kornblith, M. Norouzi, and G. Hinton, “A simple framework for contrastive learning of visual representations,” inInternational conference on machine learning. PMLR, 2020, pp. 1597–1607
2020
-
[2]
Momentum contrast for unsupervised visual representation learning,
K. He, H. Fan, Y . Wu, S. Xie, and R. Girshick, “Momentum contrast for unsupervised visual representation learning,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 9729–9738
2020
-
[3]
Trim: A self-supervised video summarization framework maximizing temporal relative information and representativeness,
P. Mishra, C. Ballester, and D. Karatzas, “Trim: A self-supervised video summarization framework maximizing temporal relative information and representativeness,” inICASSP 2026- 2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2026, pp. 10 717–10 721
2026
-
[4]
TRIMMER: A New Paradigm for Video Summarization through Self-Supervised Reinforcement Learning
——, “Trimmer: A new paradigm for video summarization through self-supervised reinforce- ment learning,”arXiv preprint arXiv:2605.01659, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[5]
Barlow twins: Self-supervised learning via redundancy reduction,
J. Zbontar, L. Jing, I. Misra, Y . LeCun, and S. Deny, “Barlow twins: Self-supervised learning via redundancy reduction,” inInternational conference on machine learning. PMLR, 2021, pp. 12 310–12 320
2021
-
[6]
Vicreg: Variance-invariance-covariance regularization for self-supervised learning,
A. Bardes, J. Ponce, and Y . Lecun, “Vicreg: Variance-invariance-covariance regularization for self-supervised learning,” inICLR 2022-International Conference on Learning Representations, 2022
2022
-
[7]
Bootstrap your own latent-a new ap- proach to self-supervised learning,
J.-B. Grill, F. Strub, F. Altché, C. Tallec, P. Richemond, E. Buchatskaya, C. Doersch, B. Avila Pires, Z. Guo, M. Gheshlaghi Azaret al., “Bootstrap your own latent-a new ap- proach to self-supervised learning,”Advances in neural information processing systems, vol. 33, pp. 21 271–21 284, 2020
2020
-
[8]
Exploring simple siamese representation learning,
X. Chen and K. He, “Exploring simple siamese representation learning,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 15 750–15 758
2021
-
[9]
On variational bounds of mutual information,
B. Poole, S. Ozair, A. Van Den Oord, A. Alemi, and G. Tucker, “On variational bounds of mutual information,” inInternational Conference on Machine Learning. PMLR, 2019, pp. 5171–5180
2019
-
[10]
Mutual information neural estimation,
M. I. Belghazi, A. Baratin, S. Rajeshwar, S. Ozair, Y . Bengio, A. Courville, and D. Hjelm, “Mutual information neural estimation,” inInternational conference on machine learning. PMLR, 2018, pp. 531–540
2018
-
[11]
Random variables, joint distribution functions, and copulas,
A. Sklar, “Random variables, joint distribution functions, and copulas,”Kybernetika, vol. 9, no. 6, pp. 449–460, 1973
1973
-
[12]
Imagenet: A large-scale hierar- chical image database,
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierar- chical image database,” in2009 IEEE conference on computer vision and pattern recognition. Ieee, 2009, pp. 248–255
2009
-
[13]
Emerging properties in self-supervised vision transformers,
M. Caron, H. Touvron, I. Misra, H. Jégou, J. Mairal, P. Bojanowski, and A. Joulin, “Emerging properties in self-supervised vision transformers,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 9650–9660
2021
-
[14]
Unsupervised learning of visual features by contrasting cluster assignments,
M. Caron, I. Misra, J. Mairal, P. Goyal, P. Bojanowski, and A. Joulin, “Unsupervised learning of visual features by contrasting cluster assignments,”Advances in neural information processing systems, vol. 33, pp. 9912–9924, 2020
2020
-
[15]
Self-supervised learning of pretext-invariant representations,
I. Misra and L. v. d. Maaten, “Self-supervised learning of pretext-invariant representations,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 6707–6717
2020
-
[16]
Improved Baselines with Momentum Contrastive Learning
X. Chen, H. Fan, R. Girshick, and K. He, “Improved baselines with momentum contrastive learning,”arXiv preprint arXiv:2003.04297, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2003
-
[17]
Learning multiple layers of features from tiny images,
A. Krizhevsky, G. Hintonet al., “Learning multiple layers of features from tiny images,” Technical Report, University of Toronto, 2009
2009
-
[18]
Imagenette: A smaller subset of 10 easily classified classes from imagenet,
Fastai, “Imagenette: A smaller subset of 10 easily classified classes from imagenet,” 2019. [Online]. Available: https://github.com/fastai/imagenette 14
2019
-
[19]
Imagewoof: A subset of 10 classes from imagenet that are hard to classify,
——, “Imagewoof: A subset of 10 classes from imagenet that are hard to classify,” 2019. [Online]. Available: https://github.com/fastai/imagenette
2019
-
[20]
Large Batch Training of Convolutional Networks
Y . You, I. Gitman, and B. Ginsburg, “Large batch training of convolutional networks,”arXiv preprint arXiv:1708.03888, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[21]
An analysis of single-layer networks in unsupervised feature learning,
A. Coates, A. Ng, and H. Lee, “An analysis of single-layer networks in unsupervised feature learning,” inProceedings of the fourteenth international conference on artificial intelligence and statistics. JMLR Workshop and Conference Proceedings, 2011, pp. 215–223. 15 A Appendix A.1 Implementation Details A.1.1 Large-scale Training Image Augmentations:Our i...
2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.